本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
軟體代理程式的核心建置區塊
下圖顯示大多數智慧型代理程式中發現的主要功能模組。每個元件都有助於代理程式在複雜環境中自動操作的能力。
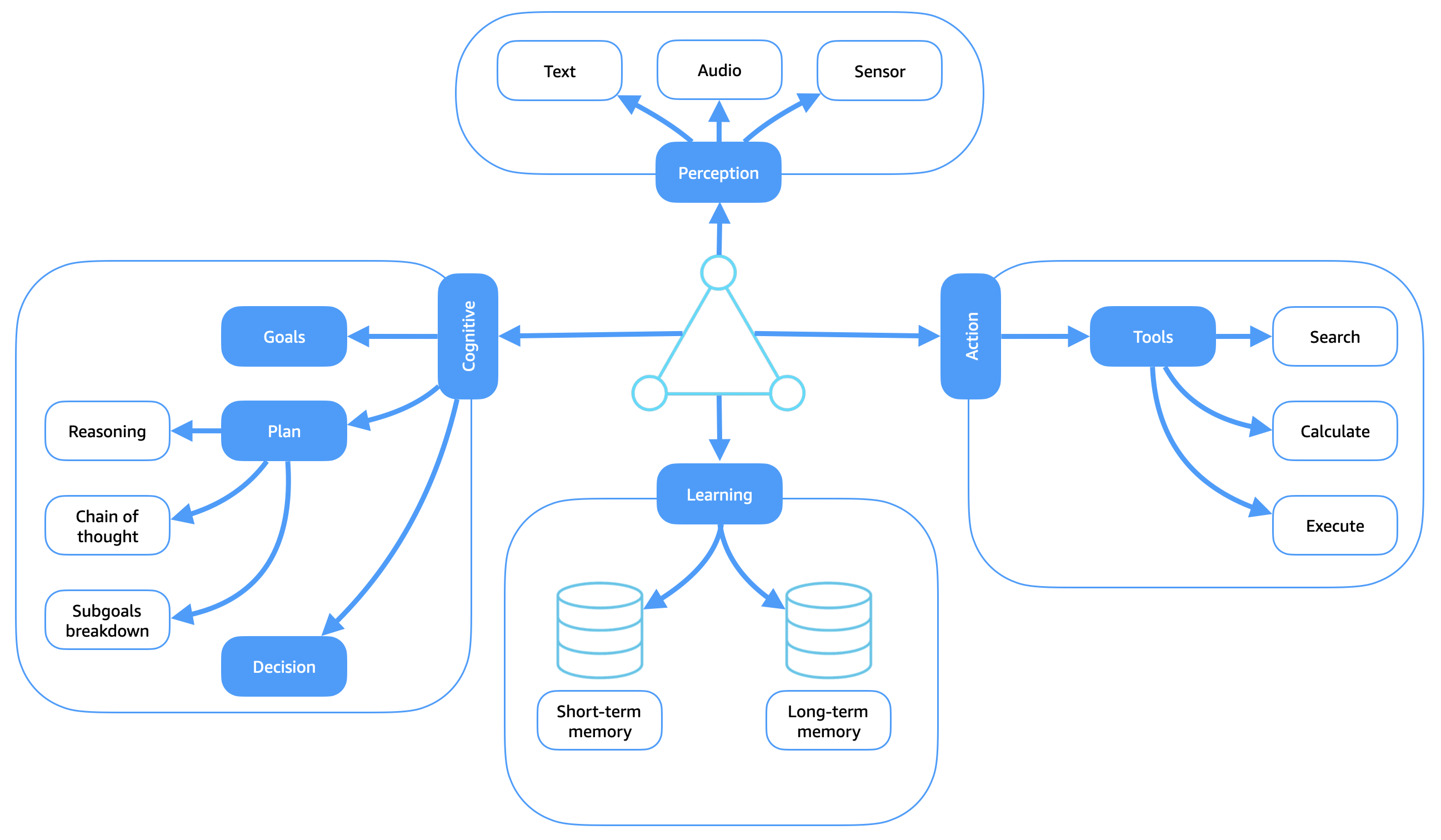
在感知、原因、動作迴圈的情況下,代理程式的推理功能會分佈在其認知和學習模組中。透過整合記憶體和學習,客服人員開發以過去經驗為基礎的適應性推理。當代理程式在其環境中運作時,會建立緊急意見回饋迴圈:每個動作都會影響未來的感知,而產生的體驗會透過學習模組整合到記憶體和內部模型中。這種持續的感知、推理和動作迴圈,可讓代理程式隨著時間改善,並完成完整的感知、原因、動作週期。
感知模組
感知模組可讓代理程式透過文字、音訊和感應器等各種輸入方式與其環境互動。這些輸入會形成所有推理和動作所依據的原始資料。文字輸入可能包含自然語言提示、結構化命令或文件。音訊輸入包含語音指示或環境聲音。感應器輸入包括實體資料,例如視覺摘要、動作訊號或 GPS 座標。感知的核心功能是從此原始資料中擷取有意義的特徵和表示。這可讓代理程式建構對其目前內容的準確且可行的理解。此程序可能涉及特徵擷取、物件或事件辨識,以及語意解釋,並構成感知、原因、行為迴圈中的關鍵第一步。有效的感知可確保下游推理和決策是以相關up-to-date情境感知為基礎。
認知模組
認知模組做為軟體代理程式的刻意核心。它負責解釋感知、形成意圖,並透過目標驅動的規劃和決策來引導有目的的行為。此模組會將輸入轉換為結構化推理程序,讓代理程式能夠刻意操作,而非被動操作。這些程序是透過三個關鍵子模組進行管理:目標、規劃和決策。
目標子模組
目標子模組定義代理程式的意圖和方向。目標可以是明確 (例如,「導覽至位置」或「提交報告」) 或隱含 (例如,「最大化使用者參與度」或「最小化延遲」)。它們是客服人員推理週期的核心,並為其規劃和決策提供目標狀態。
代理程式會持續評估其目標的進度,並根據新的感知或學習,重新排定目標的優先順序或重新產生目標。此目標意識可讓代理程式在動態環境中適應。
規劃子模組
規劃子模組會建構策略,以達成代理程式目前的目標。它會產生動作序列、以階層方式分解任務,並從預先定義或動態產生的計劃中選取。
若要在非確定性或不斷變化的環境中有效操作,規劃不是靜態的。現代客服人員可以產生chain-of-thought序列、將子目標引入中繼步驟,並在條件轉移時即時修訂計畫。
此子模組與記憶體和學習緊密連接,並允許代理程式根據過去的結果隨著時間改進其規劃。
決策子模組
決策子模組會評估可用的計劃和動作,以選取最適合的下一個步驟。它整合了感知、目前計劃、客服人員的目標和環境內容的輸入。
決策考量:
-
衝突目標之間的權衡
-
可信度閾值 (例如,感知中的不確定性)
-
動作的後果
-
客服人員的學習經驗
根據架構,客服人員可能會依賴符號推理、啟發式、強化學習或語言模型 (LLMs) 做出明智的決策。此程序會保持代理程式的行為內容感知、目標一致和適應性。
動作模組
動作模組負責執行客服人員選取的決策,並與外部世界或內部系統互動,以產生有意義的效果。它代表感知、原因、動作迴圈的動作階段,其中意圖轉換為行為。
當認知模組選取動作時,動作模組會透過特殊的子模組協調執行,其中每個子模組都與代理程式的整合環境一致:
-
實體致動:對於內嵌在機器人系統或 IoT 裝置的代理程式,此子模組會將決策轉換為實際的實體移動或硬體層級指示。
範例:轉向機器人、觸發閥、開啟感應器。
-
整合互動:此子模組會處理非實體但外部可見的動作,例如與軟體系統、平台或 APIs 互動。
範例:將命令傳送至雲端服務、更新資料庫、呼叫 API 提交報告。
-
工具調用:客服人員通常會使用專門的工具來完成子任務,以擴展其功能,如下所示:
-
搜尋:查詢結構化或非結構化的知識來源
-
摘要:將大型文字輸入壓縮為高階概觀
-
計算:執行邏輯、數值或符號運算
工具調用可透過模組化、可呼叫的技能來實現複雜的行為合成。
-
學習模組
學習模組可讓客服人員根據經驗調整、一般化和改善一段時間。它使用感知和動作的意見回饋,持續精簡客服人員的內部模型、策略和決策政策,以支援推理程序。
此模組會與短期和長期記憶體協調運作:
-
短期記憶體:儲存暫時性內容,例如對話狀態、目前任務資訊和最近的觀察。它有助於客服人員在互動和任務中維持持續性。
-
長期記憶體:編碼過去經驗的持久性知識,包括先前遇到的目標、動作結果和環境狀態。長期記憶體可讓代理程式辨識模式、重複使用策略,並避免重複錯誤。
學習模式
學習模組支援一系列範例,例如監督式、非監督式和強化式學習,其支援不同的環境和客服人員角色:
-
監督式學習:根據標記的範例更新內部模型,通常是來自人工意見回饋或訓練資料集。
範例:學習根據先前的對話分類使用者意圖。
-
非監督式學習:在沒有明確標籤的情況下識別資料中的隱藏模式或結構。
範例:叢集環境訊號以偵測異常。
-
強化學習:透過在互動式環境中最大化累積獎勵,透過試驗和錯誤來最佳化行為。
範例:了解哪些策略導致最快的任務完成。
Learning 與代理程式的認知模組緊密整合。它根據過去的結果精簡規劃策略,透過評估歷史成功來增強決策能力,並持續改善感知和動作之間的映射。透過此封閉式學習和意見回饋迴圈,客服人員會超越被動執行,成為能夠隨著時間適應新目標、條件和內容的自我改善系統。
