本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Serverless 的自動語意擴充
概觀
相較於語義搜尋,自動語意擴充功能可協助將搜尋相關性提高高達 20%。自動語意擴充可免除管理您自己的 ML (機器學習) 模型基礎設施以及與搜尋引擎整合的繁重工作。此功能適用於所有三種無伺服器集合類型:搜尋、時間序列和向量。
語意搜尋概念
傳統搜尋引擎依賴word-to-word字比對 (稱為語彙搜尋) 來尋找查詢的結果。雖然這適用於電視型號等特定查詢,但可能不會傳回更多抽象搜尋的相關結果。例如,在搜尋 "shoes for the Beach" 時,語彙搜尋只會比對目錄項目中的個別單字 "shoes"、"beach"、"for" 和 "the",可能會缺少不包含確切搜尋詞彙的相關產品,例如 "water-resistantss" 或 "surf shoes"。
語意搜尋會傳回查詢結果,不僅包含關鍵字比對,還包含使用者搜尋的意圖和內容意義。例如,如果使用者搜尋「如何治療問題」,語意搜尋系統可能會傳回下列結果:
-
Migraine 補救措施
-
疼痛管理技巧
-
Over-the-counter止痛藥
模型詳細資訊和效能基準
雖然此功能可處理幕後的技術複雜性,而不會公開基礎模型,但下列模型描述和基準結果可協助您在關鍵工作負載中做出採用特徵的明智決策。
自動語意擴充使用服務受管、預先訓練的稀疏模型,可有效運作,而無需自訂微調。模型會分析您指定的欄位,並根據從各種訓練資料中學到的關聯將它們擴展到稀疏向量。展開的詞彙及其重要性權重會以原生 Lucene 索引格式存放,以便有效擷取。我們已使用僅限文件模式
功能開發期間的效能驗證使用 MS MARCO
-
英文 - 相較於語彙搜尋,相關性改善 20%。它也比語義搜尋降低了 7.7% 的 P90 搜尋延遲 (BM25 為 26 毫秒,而自動語意擴充為 24 毫秒)。
-
多語言 - 相較於語意搜尋,相關性改善 105%,而相較於語意搜尋,P90 搜尋延遲增加 38.4% (BM25 為 26 毫秒,自動語意擴充為 36 毫秒)。
鑑於每個工作負載的獨特性質,您可以在制定實作決策之前,使用自己的基準標準在開發環境中評估此功能。
支援的語言
此功能支援英文。此外,模型也支援阿拉伯文、孟加拉文、中文、芬蘭文、法文、印地文、印尼文、日文、韓文、波斯文、俄文、西班牙文、斯瓦希里文和特拉古文。
為無伺服器集合設定自動語意擴充索引
您可以在新索引建立期間,透過主控台、APIs 和 CloudFormation 範本,為文字欄位設定已啟用自動語意擴充的索引。若要為現有索引啟用它,您必須為文字欄位重新建立已啟用自動語意擴充的索引。
使用 AWS 主控台,您可以建立具有自動語意擴充欄位的索引。選取集合之後,您可以在主控台頂端找到建立索引按鈕。選擇建立索引後,主控台會提供選項來定義自動語意擴充欄位。在一個索引中,您可以結合英文和多語言的自動語意擴充,以及語彙欄位。
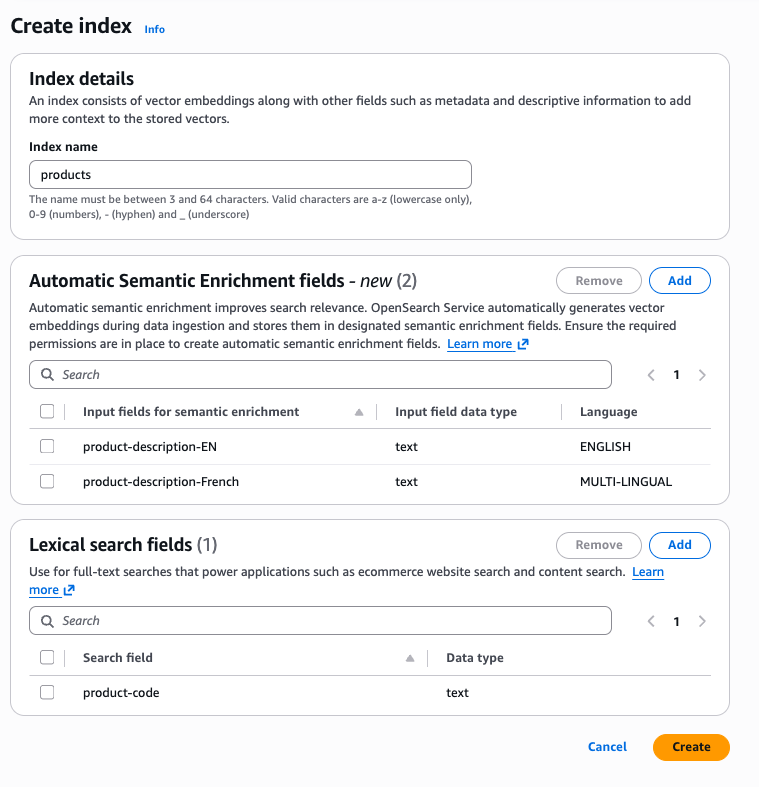
若要使用 AWS 命令列界面 (AWS CLI) 建立自動語意擴充索引,請使用 create-index 命令:
aws opensearchserverless create-index \ --id [collection_id] \ --index-name [index_name] \ --index-schema [index_body] \
在下列索引結構描述範例中, title_semantic 欄位的欄位類型設定為 text,參數semantic_enrichment設定為狀態 ENABLED。設定 semantic_enrichment 參數會在 title_semantic 欄位上啟用自動語意擴充。您可以使用 language_options 欄位來指定 english或 multi-lingual。
aws opensearchserverless create-index \ --id XXXXXXXXX \ --index-name 'product-catalog' \ --index-schema '{ "mappings": { "properties": { "product_id": { "type": "keyword" }, "title_semantic": { "type": "text", "semantic_enrichment": { "status": "ENABLED", "language_options": "english" } }, "title_non_semantic": { "type": "text" } } } }'
若要描述建立的索引,請使用下列命令:
aws opensearchserverless get-index \ --id [collection_id] \ --index-name [index_name] \
您也可以使用 CloudFormation 範本 (Type:AWS::OpenSearchServerless::CollectionIndex),在集合佈建期間和建立集合之後建立語意搜尋。
更新現有的索引
您可以更新現有索引以新增語意擴充欄位、啟用或停用現有欄位的語意擴充,或新增非語意文字欄位。使用 update-index命令,並僅提供您要在 中變更的欄位index-schema。請求中未包含的欄位保持不變。
注意
settings 無法更新索引。如果您在請求中包含settings區塊,操作會傳回驗證錯誤。若要變更索引設定,您必須刪除並重新建立索引。
若要使用 更新索引 AWS CLI,請使用 update-index命令:
aws opensearchserverless update-index \ --id [collection_id] \ --index-name [index_name] \ --index-schema [index_body]
新增語意擴充欄位
您可以將啟用語意擴充的新text欄位新增至現有索引。服務會自動設定所需的 ML 模型、擷取管道和搜尋管道。更新後編製索引的新文件會自動擴充。
重要
現有文件不會回填。若要在現有文件上填入語意擴充欄位,您必須在更新後重新擷取它們。在重新擷取之前,現有文件將不會受益於新欄位上的語意搜尋。
aws opensearchserverless update-index \ --id my-collection-id \ --index-name product-catalog \ --index-schema '{ "mappings": { "properties": { "description": { "type": "text", "semantic_enrichment": { "status": "ENABLED", "language_options": "english" } } } } }'
在欄位上停用語意擴充
若要在目前已啟用它的欄位上停用語意擴充,請將 status設定為 DISABLED。欄位會從擷取和搜尋管道中移除。基礎文字欄位及其內嵌欄位會保留在索引中,但不再富集。
aws opensearchserverless update-index \ --id my-collection-id \ --index-name product-catalog \ --index-schema '{ "mappings": { "properties": { "title_semantic": { "type": "text", "semantic_enrichment": { "status": "DISABLED" } } } } }'
更新限制
不支援下列操作,update-index並要求您刪除並重新建立索引:
-
變更
language_options目前已啟用語意擴充的欄位。首先停用 欄位,然後使用新語言選項重新啟用它。 -
更新巢狀欄位。只有最上層
text欄位才支援語意擴充。 -
更新索引
settings。
注意
如果索引具有不是由自動語意擴充建立的自訂擷取或搜尋管道,則更新操作會遭到封鎖。在新增語意擴充欄位之前,請先移除自訂管道。
資料擷取和搜尋
建立啟用自動語意擴充的索引後,此功能會在資料擷取程序期間自動運作,不需要額外的組態。
資料擷取:當您將文件新增至索引時,系統會自動:
-
分析您為語意擴充指定的文字欄位
-
使用 OpenSearch Service 受管稀疏模型產生語意編碼
-
將這些豐富的表示與原始資料一起存放
此程序使用 OpenSearch 的內建 ML 連接器和擷取管道,這些管道會在幕後自動建立和管理。
搜尋:語意擴充資料已編製索引,因此查詢會有效率地執行,而不會再次叫用 ML 模型。這表示您可以改善搜尋相關性,而不需要額外的搜尋延遲額外負荷。
設定自動語意擴充的許可
在建立自動語意擴充索引之前,您必須設定必要的許可。本節說明所需的許可,以及如何設定這些許可。
IAM 政策許可
使用下列 AWS Identity and Access Management (IAM) 政策授予使用自動語意擴充的必要許可:
- 金鑰許可
-
-
aoss:*Index許可啟用索引管理 -
aoss:APIAccessAll許可允許 OpenSearch API 操作 -
若要限制特定集合的許可,請將 取代
"Resource": "*"為集合的 ARN
-
設定資料存取許可
若要設定自動語意擴充的索引,您必須擁有適當的資料存取政策,以授予存取索引、管道和模型收集資源的許可。如需資料存取政策的詳細資訊,請參閱 Amazon OpenSearch Serverless 的資料存取控制。如需設定資料存取政策的程序,請參閱 建立資料存取政策 (主控台)。
資料存取許可
[ { "Description": "Create index permission", "Rules": [ { "ResourceType": "index", "Resource": ["index/collection_name/*"], "Permission": [ "aoss:CreateIndex", "aoss:DescribeIndex", "aoss:UpdateIndex", "aoss:DeleteIndex" ] } ], "Principal": [ "arn:aws:iam::account_id:role/role_name" ] }, { "Description": "Create pipeline permission", "Rules": [ { "ResourceType": "collection", "Resource": ["collection/collection_name"], "Permission": [ "aoss:CreateCollectionItems", "aoss:DescribeCollectionItems" ] } ], "Principal": [ "arn:aws:iam::account_id:role/role_name" ] }, { "Description": "Create model permission", "Rules": [ { "ResourceType": "model", "Resource": ["model/collection_name/*"], "Permission": ["aoss:CreateMLResource"] } ], "Principal": [ "arn:aws:iam::account_id:role/role_name" ] }, ]
網路存取許可
若要允許服務 APIs 存取私有集合,您必須設定允許服務 API 與集合之間必要存取的網路政策。如需網路政策的詳細資訊,請參閱 Amazon OpenSearch Serverless 的網路存取。
[ { "Description":"Enable automatic semantic enrichment in a private collection", "Rules":[ { "ResourceType":"collection", "Resource":[ "collection/collection_name" ] } ], "AllowFromPublic":false, "SourceServices":[ "aoss.amazonaws.com" ], } ]
設定私有集合的網路存取許可
-
登入 OpenSearch Service 主控台,網址為 https://https://console.aws.amazon.com/aos/home
。 -
在左側導覽窗格中,選擇網路政策。然後執行下列其中一項:
-
選擇現有的政策名稱,然後選擇編輯
-
選擇建立網路政策並設定政策詳細資訊
-
-
在存取類型區域中,選擇私有 (建議),然後選取AWS 服務私有存取。
-
在搜尋欄位中,選擇服務,然後選擇 aoss.amazonaws.com。
-
在資源類型區域中,選取啟用對 OpenSearch 端點的存取核取方塊。
-
在搜尋集合 (搜尋) 或輸入特定字首字詞 (搜尋) 欄位中,選取集合名稱。然後輸入或選取要與網路政策建立關聯的集合名稱。
-
針對新網路政策選擇建立,或針對現有網路政策選擇更新。
查詢重寫
自動語意擴充會自動將您現有的「比對」查詢轉換為語意搜尋查詢,而不需要修改查詢。如果比對查詢是複合查詢的一部分,系統會周遊您的查詢結構、尋找比對查詢,並將它們取代為神經稀疏查詢。目前,此功能僅支援取代「比對」查詢,無論是獨立查詢還是複合查詢的一部分。不支援「多重_比對」。此外,此功能支援所有複合查詢來取代其巢狀比對查詢。複合查詢包括:bool、Boosting、 constant_score、dis_max、 function_score 和 hybrid。
自動語意擴充的限制
當套用至包含自然語言內容small-to-medium欄位時,自動語意搜尋最有效,例如電影標題、產品描述、評論和摘要。雖然語意搜尋增強了大多數使用案例的相關性,但它可能不適用於某些案例。在決定是否為特定使用案例實作自動語意擴充時,請考慮下列限制。
-
非常長的文件 – 目前的稀疏模型只會處理每個英文文件的前 8,192 個字符。對於多語言文件,它是 512 個字符。對於冗長的文章,請考慮實作文件區塊,以確保完整的內容處理。
-
日誌分析工作負載 – 語意擴充會大幅增加索引大小,這對於日誌分析而言可能不必要,其中完全相符通常就足夠。其他語意內容很少改善日誌搜尋的有效性,足以證明增加的儲存需求。
-
自動語意擴充與衍生來源功能不相容。
定價
Amazon OpenSearch Service 會根據索引時間產生稀疏向量期間消耗的 OpenSearch Compute Units (OCUs) 來計費自動語意擴充。只有在啟用自動語意擴充的文字欄位編製索引期間,才會向您收取實際用量的費用。一個語意搜尋 OCU 可以處理 1,110 萬個英文內容字符。若要處理 24 億個字符,您需要大約 216 個語意搜尋 OCU 小時 (24 億/1,110 萬)。每個語意搜尋 OCU 小時的價格為 0.24 USD,處理 10 GB 資料以進行自動語意搜尋的成本為 51 USD (216 OCU 小時 x 0.24 USD/OCU 小時)。在搜尋操作或資料儲存期間,不需要支付額外的語意搜尋 OCU 費用。
您可以使用 Amazon CloudWatch 指標 來監控此耗用量SemanticSearchOCU。如需模型字符限制的特定詳細資訊、每個 OCU 的磁碟區輸送量,以及範例計算範例,請造訪 OpenSearch Service 定價
