本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
災難復原規劃
災難復原 (DR) 是企業業務持續性和合規的關鍵服務。AMS 會與您合作,協助您規劃、實作和維護 AMS 上的 DR 策略。
AMS 登陸區域 (LZ)、多帳戶和單一帳戶,可為符合大多數災難保護案例的 AMS 基礎設施元件提供原生、多可用區域、高可用性。不過,視您企業的地理覆蓋範圍而定,您可能需要區域保護。對於跨區域可用性和 DR,不同區域需要另一個 AMS 帳戶 (多帳戶登陸區域和單一帳戶登陸區域都是如此)。
AMS 符合本部落格中所述的 AWS DR 指引、在災難中快速復原關鍵任務系統
多站台 (或高可用性)
暖待命
指示燈
備份與還原
這些選項及其 AMS 支援會在下列各節中說明。
多站台或高可用性 (HA)
HA 解決方案通常由應用程式的內建功能提供,例如叢集或同步複寫。使用者會導向至 Prod 和 HA/DR 節點。DNS 會直接指向節點,或透過彈性負載平衡器 (ELB) 指向節點。
您的 AMS 雲端架構師 (CA) 將與您合作,作為 Well-Architected-Review 和 DR 規劃的一部分。
HA DR 利用應用程式和 AWS原生服務和功能,如下圖所示:
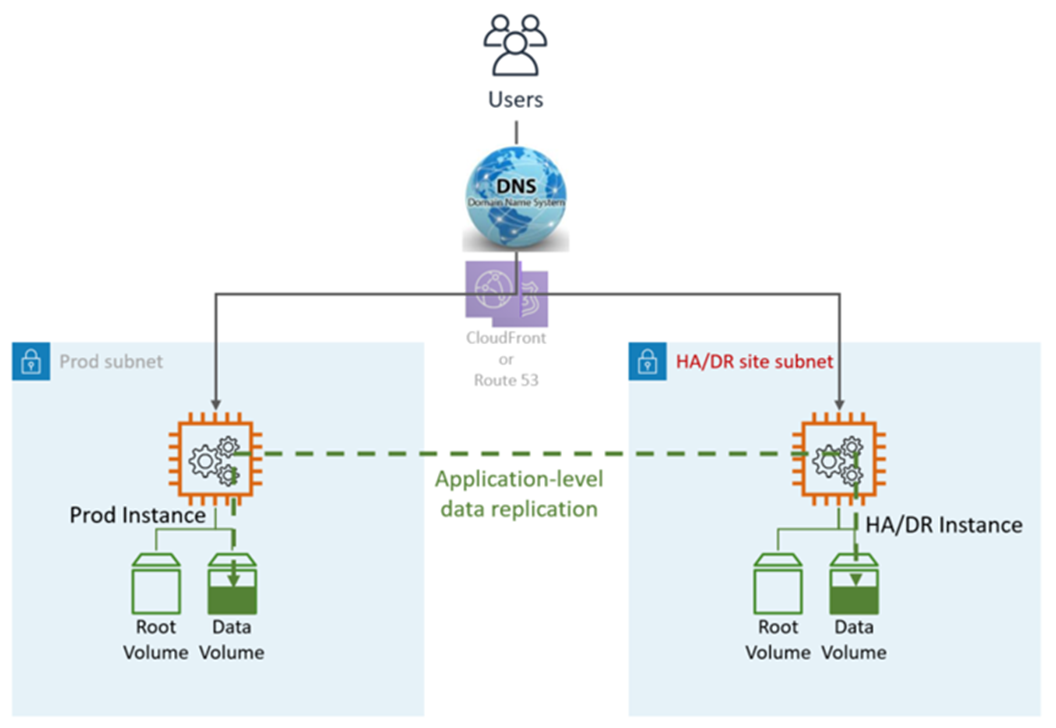
DR 網站可以位於相同或不同位置 AWS 區域。
注意
不同的區域 (跨區域) 會有不同的 Active Directory 環境。
DR (容錯移轉) 步驟:自動容錯移轉,不需要手動步驟。如果主要 LZ 發生故障,使用者會自動重新路由至 DR/HA 節點。這可透過 DNS 和應用程式組態達成。
HA DR 指標:
復原點目標 (RPO):<5 分鐘
復原時間目標和 (RTO):<5 分鐘
維護:高 (兩個環境都需要同步變更,例如應用程式組態、修補、SG 或 ALB、憑證等)。
成本:高
暖待命
「暖待命」一詞用於描述災難復原 (DR) 案例,其中環境的縮減版本正在雲端中執行。
資料複寫通常由應用程式層非同步處理到線上執行個體,而其餘執行個體 (例如應用程式和 Web 層) 可能會關閉以節省成本。使用者只會導向生產網站。也可以在 DR 網站中預先佈建其他 AWS 資源,例如彈性負載平衡器 (ELB)。
您的 AMS Cloud Architect (CA) 將與您合作,作為 Well-Architected-Review 和 DR 規劃的一部分。
Warm Standby DR 會利用應用程式和 AWS原生服務和功能,如下圖所示:
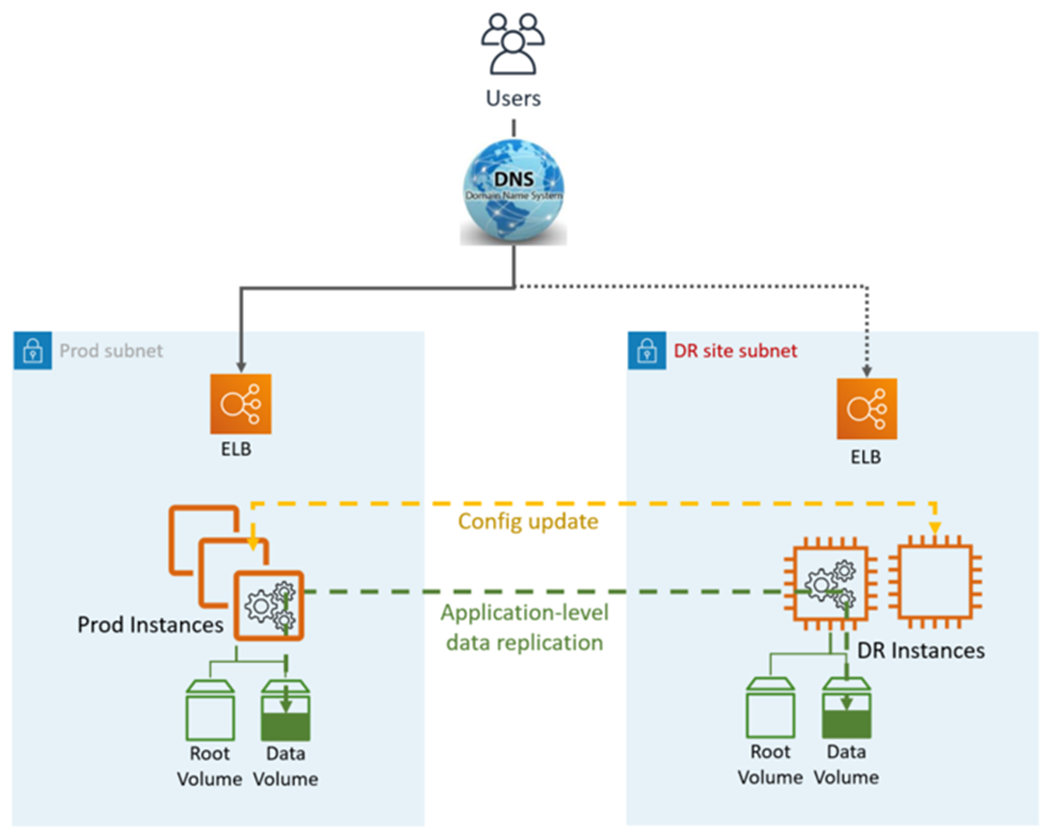
DR 網站可以位於相同或不同位置 AWS 區域。
注意
不同的區域 (跨區域) 會有不同的 Active Directory 環境。
DR (容錯移轉) 步驟:
啟動資料複寫,並將 DR 站點中的資料執行個體設為主要執行個體
視需要更新應用程式組態 (新的 IP、伺服器名稱等)
將 DNS 重新導向至 DR 網站 (ELB)
必要時的 AD 相依性 (服務帳戶、SPNs、GPOs等)
HA DR 指標:
復原點目標 (RPO):<1 小時
復原時間目標和 (RTO):<1 小時 (取決於執行個體數量和協同運作)
維護:高 (兩個環境都需要同步變更,例如應用程式組態、修補、安全群組 (SG) 或應用程式負載平衡器 (ALB)、憑證等)。
成本:中型
指示燈
在此災難復原 (DR) 方法中,您會針對一組有限的核心服務複寫部分 Prod 環境。您的基礎設施的一小部分始終在執行中,同時同步可變資料 (例如資料庫或文件),而基礎設施的其他部分僅在測試期間關閉和使用。與備份和復原方法不同,您必須確保最重要的核心元素已在 DR 登陸區域 (指示燈) 中設定並執行。
您的 AMS Cloud Architect 將與您合作,作為 Well-Architected-Review 和 DR 規劃的一部分。
Pilot Light DR 利用應用程式和 AWS原生服務和功能,如下圖所示:
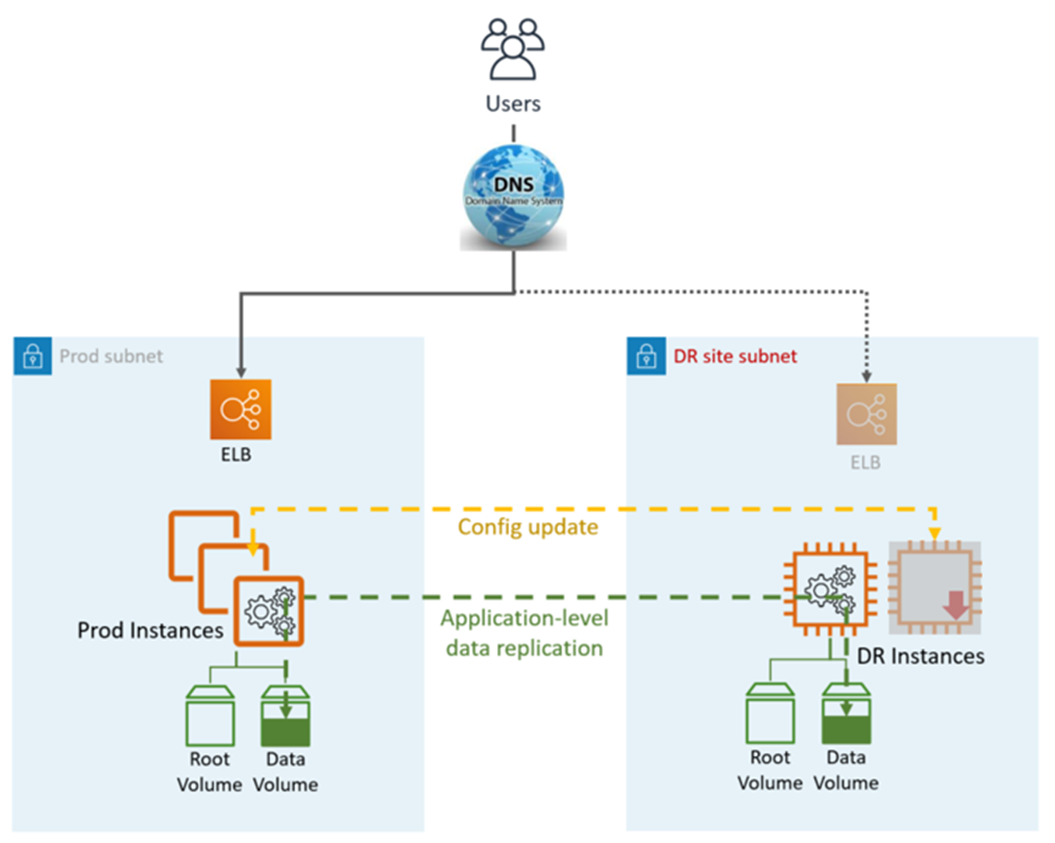
DR 網站可以位於相同或不同位置 AWS 區域。
注意
不同的區域 (跨區域) 會有不同的 Active Directory 環境。
DR (容錯移轉) 步驟:
啟動資料複寫,並將 DR 站點中的資料執行個體設為主要執行個體
啟動已關閉的執行個體和基礎設施
視需要更新應用程式組態 (新的 IP、伺服器名稱等)
視需要將執行個體新增至 ELB
將 DNS 重新導向至 DR 網站 (ELB)
視需要的 AD 相依性 (服務帳戶、SPNs、GPOs等)
指示燈 DR 指標:
復原點目標 (RPO):<1 小時
復原時間目標和 (RTO):~1 小時 (取決於執行個體數量和協同運作)
維護:中
成本:中型
備份與還原
這種簡單且低成本的災難復原 (DR) 方法可將您的資料和應用程式從任何地方備份到 DR 登陸區域,以便在從災難復原期間使用。
您的 AMS Cloud Architect 會與您合作,做為備份和 DR 規劃的一部分。
備份和還原 DR 使用 AMS 自動化工具和程序,如下圖所示:
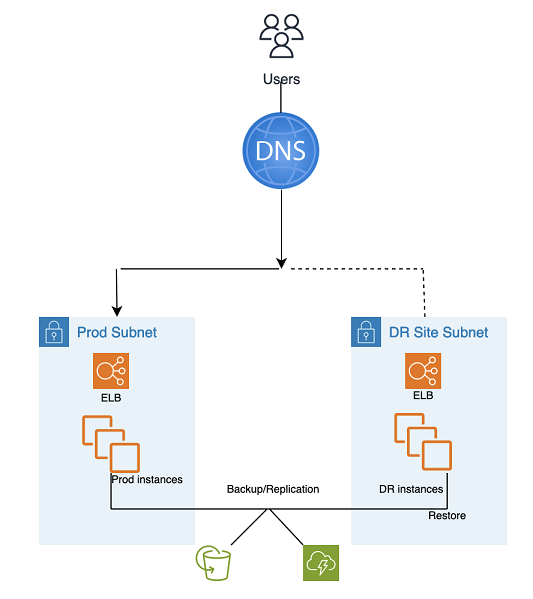
可以使用兩種備份和複寫方法:
EBS 快照 (復原點目標 (RPO) > 1 小時),稱為「EBS」
AWS 彈性災難復原 (復原點目標 (RPO) ~ 0.25 小時),稱為「DRS」
DR 網站可以位於相同 或不同 AWS 區域。
注意
不同的區域 (跨區域) 具有不同的 Active Directory 環境。
DR (容錯移轉) 步驟:
從快照還原執行個體 (以預留位置執行個體為先的兩步驟程序)
更新應用程式組態 (新的 IP、伺服器名稱等)
視需要設定其他基礎設施 (SG、ELB 等)
將 DNS 重新導向至 DR 網站 (ELB)
視需要更新或還原 AD 相依性 (服務帳戶、服務主體名稱 SPNs)、群組政策物件 GPOs) 等)
備份和還原 DR 指標:
復原點目標 (RPO):>1 小時或 ~0.25 小時 (取決於所選的解決方案 - EBS 或 DRE)
復原時間目標和 (RTO):~1 小時 (取決於執行個體數量和協同運作)
維護:高 (兩個環境都需要同步變更,例如應用程式組態、修補、安全群組或應用程式負載平衡器、憑證等。
成本:中型
在 AMS 上使用 EBS 快照保護 EC2 的災難
事前準備:
AMS 產品登陸區域 (來源)
AMS DR 登陸區域 (DR 目標)
EC2 執行個體已啟用 EBS 快照 (AWS Backup)
快照複寫解決方案:
跨可用區域:不適用 - 依設計,EBS 快照在區域中高度可用
跨區域: AWS Backup
下圖代表 AMS 上 EBS 快照的 EC2 還原程序:
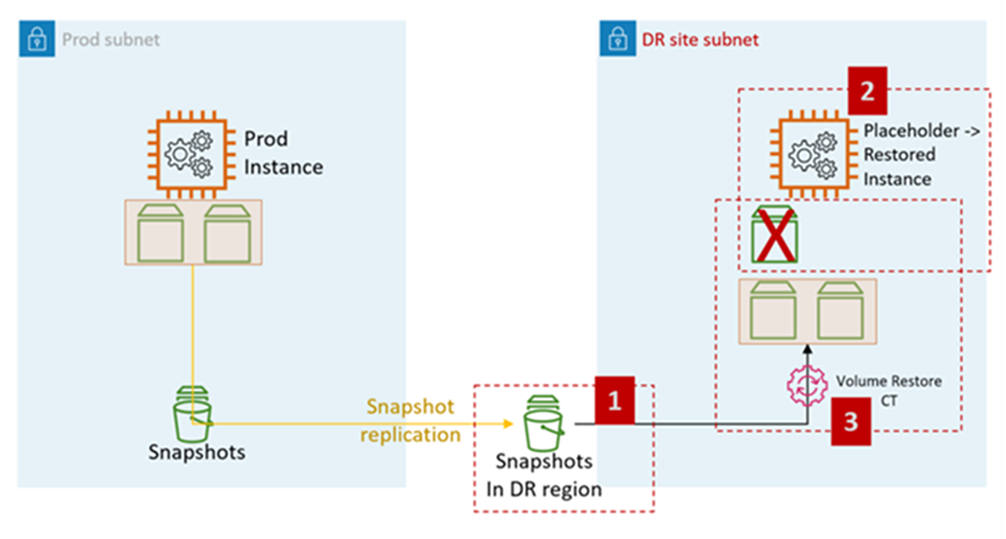
AMS 上的 EC2 DR 步驟:
提出 RFC 以與目標帳戶共用 EBS 快照 (跨區域 DR 需要)。
:管理、進階堆疊元件、EBS 快照、共用
在目的地子網路 (DR 站點子網路) 中建立預留位置 EC2 AMS 堆疊。建議使用 CFN 擷取來建立堆疊,因為客戶可以在相同的堆疊中結合指派安全群組和其他 (例如將執行個體新增至 ELB) 的步驟。
變更類型:部署、擷取、CloudFormation 範本的堆疊、建立
引發 RFC 以執行 EC2 堆疊磁碟區還原。
變更類型:管理、進階堆疊元件、EC2 執行個體堆疊、還原磁碟區。
CT 會從步驟 1 中共用的快照還原磁碟區,並連接至步驟 2 中建立的預留位置執行個體。
磁碟區還原 CT 功能:
關閉預留位置執行個體
從快照還原磁碟區
交換磁碟區
啟動執行個體
離開舊網域
變更主機名稱
重新啟動。AMS 引導指令碼會在啟動時將執行個體加入目標 (DR) 網域
磁碟區還原 CT 輸入:
InstanceId (預留位置執行個體 ID)
RootDeviceSnapshotId,還原根磁碟區的 EBS 快照
KMSKeyId、KMS 金鑰識別符或 ARN,用於加密 EC2 執行個體上所有還原的磁碟區
DeviceNames,最多 25 個 (選用)
SnapshotIds,最多 25 個 (選用)。要還原之磁碟區的快照清單
在 AMS 上使用彈性災難復原來保護 EC2 的災難
事前準備:
AMS 產品登陸區域 (來源)
AMS DR 登陸區域 (DR 目標)
您必須先為計劃使用的所有 初始化 Elastic Disaster Recovery AWS 區域 服務。
在 DR 登陸區域 (LZ) 中建立 IAM 角色,以存取 Elastic Disaster Recovery 主控台。
重要:SSM 文件會在 DRS 中建立為啟動後動作。此動作必須在 PostLaunch 設定的所有伺服器上啟用。
目的地 (預留位置) 執行個體必須具有標籤索引鍵:"AWSDRS",值:"AllowLaunchingIntoThisInstance"。預留位置執行個體必須處於停止狀態。否則,AMS 無法在啟動設定下選取預留位置執行個體,且 Elastic Disaster Recovery 無法在預留位置執行個體上還原。
如需 AMS 上 EC2 彈性災難復原設定和還原程序的圖表,請參閱 AWS 彈性災難復原 (AWS DRS) 一般架構。
在 AMS 上使用彈性災難復原的 EC2 DR 步驟:
在具有適當標籤的目的地子網路 (DR 站點子網路) 中建立預留位置 EC2 AMS 堆疊,如需詳細資訊,請參閱上一節。我們建議您使用 CFN 擷取來建立堆疊,因為您可以結合在相同堆疊中指派安全群組和標記執行個體、EBS 磁碟區和其他 (例如將執行個體新增至 ELB) 的步驟。
變更類型:部署、擷取、CloudFormation 範本的堆疊、建立
停止預留位置執行個體。
變更類型:管理、進階堆疊元件、EC2 執行個體、停止
如果未在步驟 1 中完成,請使用索引鍵標記預留位置執行個體及其 EBS 磁碟區:"AWSDRS",值:"AllowLaunchingIntoThisInstance"。
變更類型:管理、進階堆疊元件、標籤、更新。
在啟動至執行個體 ID、來源伺服器的 DRS 啟動設定下,使用步驟 1 的預留位置執行個體做為目標。 從來源伺服器的 Elastic Disaster Recovery 主控台啟動執行個體復原演練。
注意
預留位置執行個體磁碟區會保留在帳戶中。若要刪除這些磁碟區,請在災難復原操作結束時提交管理 | 進階堆疊元件 | EBS 磁碟區 | 刪除變更類型 (ct-3e3h8u0sp5z80)。
彈性災難復原還原工作流程:
目標 (預留位置) 執行個體必須處於停止狀態
交換磁碟區並刪除來源 (預留位置) 根磁碟區
啟動執行個體
執行啟動後動作以完成下列項目:
啟用 SSM 代理程式。
交換磁碟區並刪除來源 (預留位置) 根磁碟區。
啟動執行個體
執行 PostLaunchScript SSM 文件。本文件執行下列動作:
離開舊網域。
變更主機名稱。
重新啟動。AMS 引導指令碼會在啟動期間將執行個體加入目標 (DR) 網域。
