本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
對 Lambda 中的組態問題進行疑難排解
函式組態設定可能會影響 Lambda 函式的整體效能和行為。這些設定可能不會造成實際的函式錯誤,但可能會導致意外的逾時和結果。
下列主題針對您可能遇到的與 Lambda 函式組態設定相關的常見問題,提供疑難排解建議。
記憶體組態
您可以將 Lambda 函式設定為使用 128 MB 至 10,240 MB 記憶體。依預設,在主控台中建立的任何函數都會被指派最小數量的記憶體。許多 Lambda 函式在此設定下限下仍具有效能。但是,若要匯入大型程式庫或完成記憶體密集型任務,128 MB 並不足夠。
如果函式的執行速度比預期慢得多,則首先應增大記憶體設定。對於記憶體受限的函數,這將解決瓶頸問題,並可能改善函數的效能。
CPU 受限的組態
對於運算密集型操作,如果函式效能慢於預期,這可能是由於函式屬於 CPU 密集型。在這種情況下,函數的運算容量跟不上工作的速度。
雖然 Lambda 不允許您直接修改 CPU 組態,但 CPU 可以透過記憶體設定間接控制。當您配置更多記憶體時,Lambda 服務會按比例配置更多虛擬 CPU。當記憶體設定為 1.8 GB 時,Lambda 函式會配置一個完整的 vCPU;超過此數值後,函式將可使用多個 vCPU 核心。檔記憶設定為 10,240 MB 時,將有 6 個 vCPU 可供使用。換言之,您可以透過增加記憶體配置來改善效能,即使函式並未用完所有記憶體。
逾時
Lambda 函式的逾時可設定為 1 至 900 秒 (15 分鐘)。依預設,Lambda 主控台會將此設定為 3 秒。逾時值是一種安全閥,可確保函式不會無限期執行。達到逾時值後,Lambda 會停止函式調用。
將逾時值設定為接近函數的平均持續時間會提高函數意外逾時的風險。函數的持續時間會有所不同,這取決於資料傳輸和處理量,以及函數與之互動的任何服務的延遲。逾時的常見原因包括:
-
從 S3 儲存貯體或其他資料存放區下載資料時,下載量較大或下載時間較平均時間長。
-
函數會向另一個服務提出請求,這需要更長的時間才能回應。
-
提供給函數的參數要求函數具有更高的運算複雜性,這會導致調用時間更長。
測試應用程式時,請確保測試可準確反映資料的大小和數量以及真實的參數值。重要的是,使用工作負載合理預期上限的資料集。
此外,只要可行,就在工作負載中實作上限限制。在本範例中,應用程式可以使用每種檔案類型的大小上限。然後,您可以測試應用程式在一系列預期檔案大小 (最高可達並包括上限) 下的效能。
調用之間的記憶體外洩
Lambda 調用 INIT 階段儲存的全域變數和物件會在暖調用之間保留其狀態。它們只會在執行環境第一次執行 (也稱為「冷啟動」) 時完全重設。處理常式結束時,儲存在處理常式中的變數都會銷毀。最佳實務是使用 INIT 階段設定資料庫連線、載入程式庫、建立快取,以及載入不可變的資產。
在同一執行環境中跨多個調用使用第三方程式庫時,需要查閱其在無伺服器運算環境中的使用說明文件。有些資料庫連線和日誌記錄程式庫可能會儲存中繼調用結果和其他資料。這會導致這些程式庫的記憶體使用量隨著後續暖調用而增加。在此情況下,您可能會發現 Lambda 函式耗盡記憶體,即使自訂程式碼正確處理變數也是如此。
此問題會影響暖執行環境中發生的調用。例如,下列程式碼會在調用之間造成記憶體外洩。Lambda 函數透過增加全域陣列的大小,在每次調用時使用額外的記憶體:
let a = []
exports.handler = async (event) => {
a.push(Array(100000).fill(1))
}
使用 128 MB 的記憶體設定,在調用此函式 1000 次之後,Lambda 函式的監控索引標籤會顯示發生記憶體外洩時典型的調用、持續時間和錯誤計數變更:
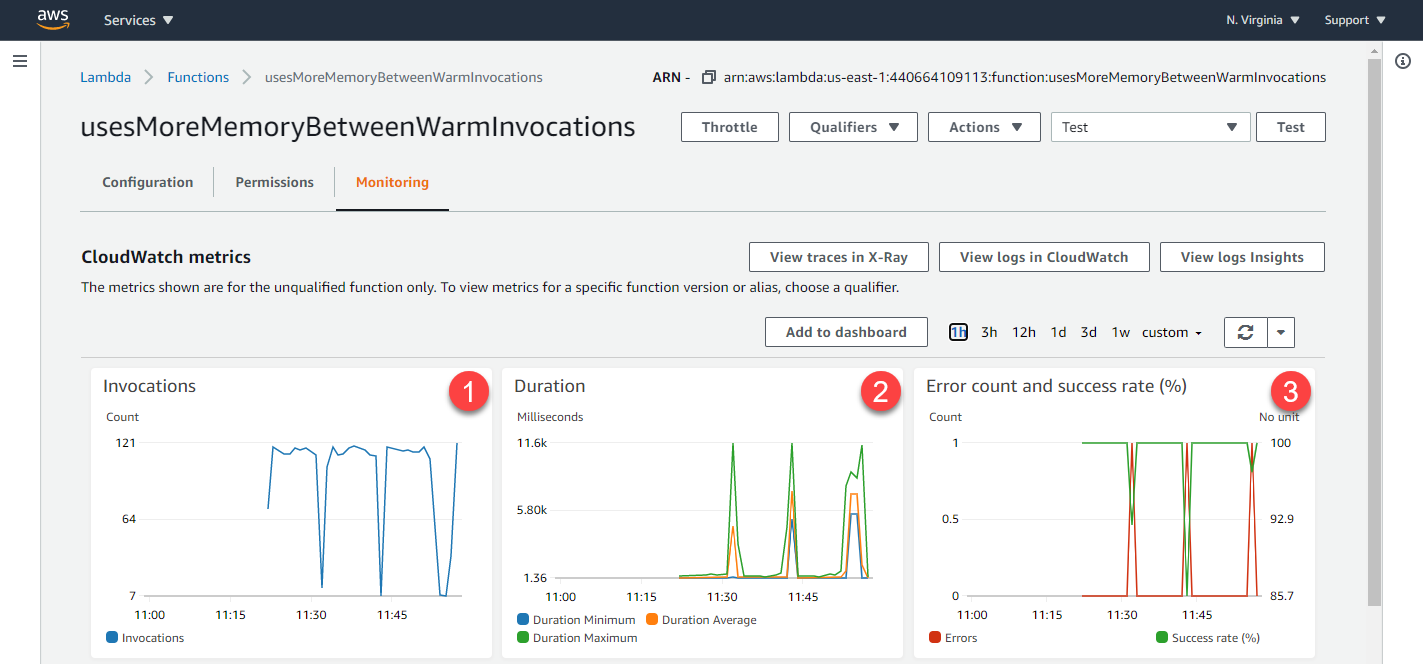
-
調用:由於調用需要更長的時間才能完成,因此穩定的交易速率會定期中斷。狀態穩定時,記憶體外洩不會耗用函數配置的所有記憶體。隨著效能降低,作業系統正在對本機儲存體進行分頁,以容納函數所需的不斷增長的記憶體,這會導致完成的交易數減少。
-
持續時間:在函式耗盡記憶體之前,會穩定地以兩位數毫秒速率完成調用。分頁發生時,持續時間會增加一個數量級。
-
錯誤計數:因為記憶體外洩超過配置的記憶體,最終函式因運算超過逾時而出錯,或是執行環境終止函式。
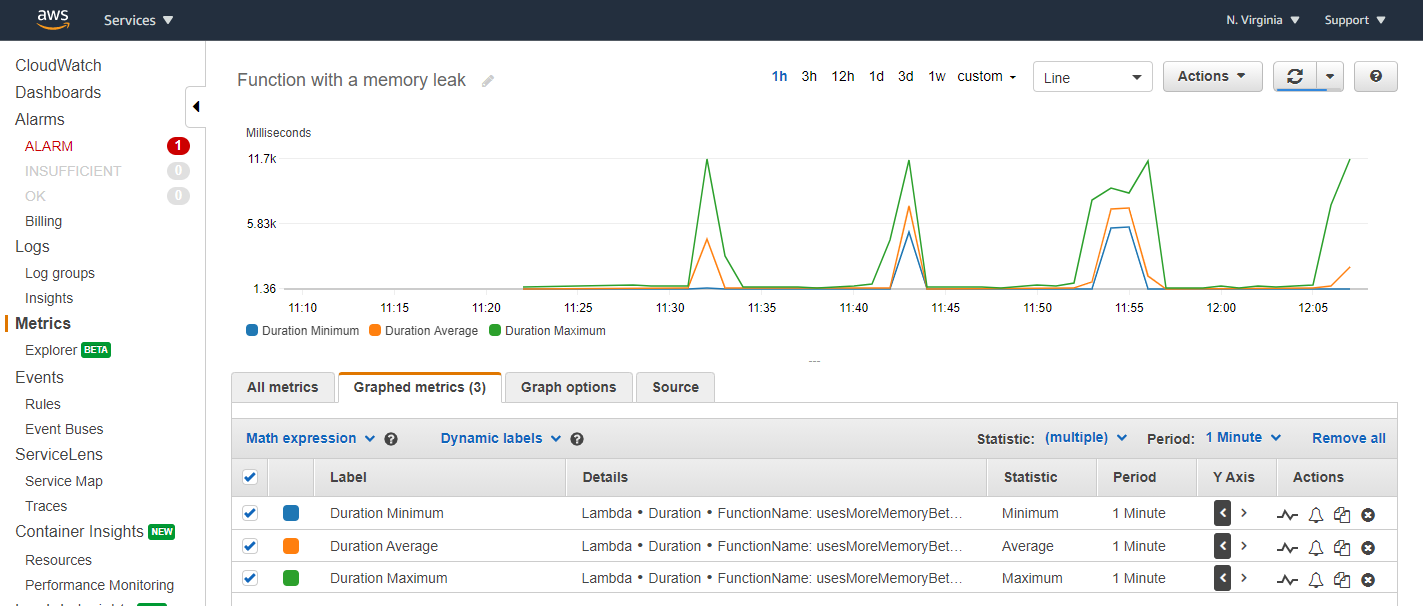
出錯後,Lambda 會重新啟動執行環境,這解釋了為什麼在全部三個圖形中會回到原始狀態。展開 CloudWatch 的持續時間指標可提供最短、最長和平均持續時間統計資料的更多詳細資訊:
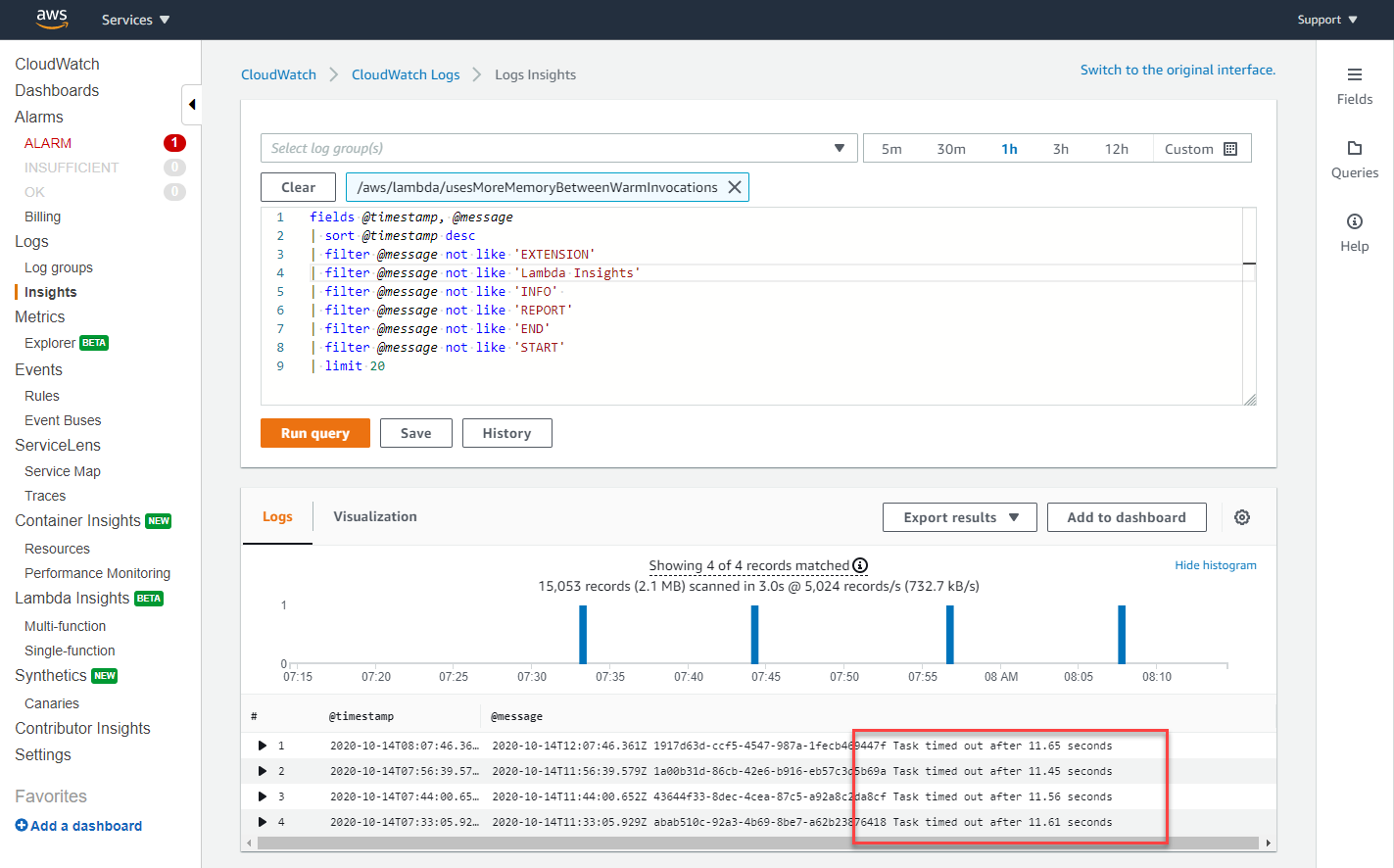
若要尋找 1000 個調用中產生的錯誤,可以使用 CloudWatch Insights 查詢語言。下列查詢會排除資訊日誌,僅報告錯誤:
fields @timestamp, @message | sort @timestamp desc | filter @message not like 'EXTENSION' | filter @message not like 'Lambda Insights' | filter @message not like 'INFO' | filter @message not like 'REPORT' | filter @message not like 'END' | filter @message not like 'START'
在針對此函數的日誌群組執行時,這表示週期性錯誤是逾時造成的:
非同步結果傳回至稍後的調用
對於使用非同步模式的函數程式碼,一次調用的回呼結果可能在未來的調用中傳回。此範例使用了 Node.js,但相同的邏輯可套用至使用非同步模式的其他執行時期。函數使用 JavaScript 中的傳統回呼語法。它會呼叫一個非同步函數,該函數具有增量計數器,可追蹤調用次數:
let seqId = 0 exports.handler = async (event, context) => { console.log(`Starting: sequence Id=${++seqId}`) doWork(seqId, function(id) { console.log(`Work done: sequence Id=${id}`) }) } function doWork(id, callback) { setTimeout(() => callback(id), 3000) }
連續調用多次時,回呼的結果會出現在後續調用中:
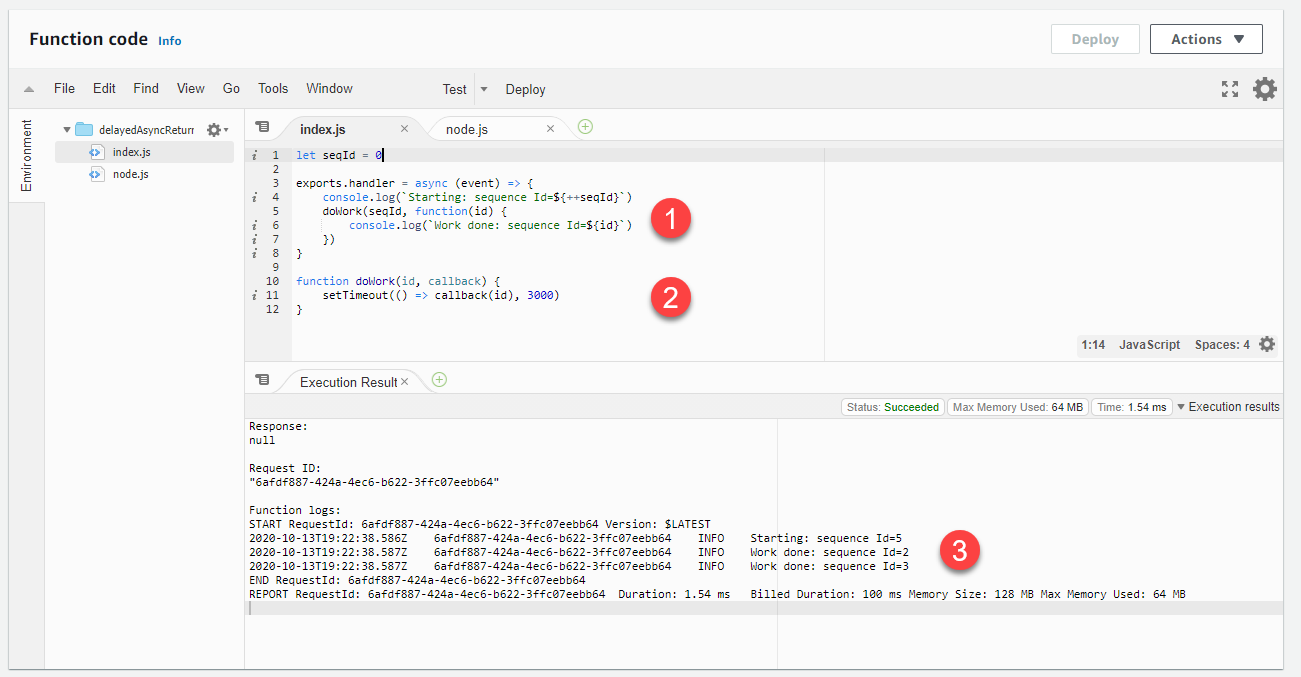
-
程式碼呼叫
doWork函式,將回呼函式最為最後一個參數傳入。 -
doWork函式需要一段時間才能完成,然後才會調用回呼。 -
函式的日誌記錄指出調用在
doWork函式完成執行之前結束。此外,在開始反覆運算後,正在處理先前反覆運算的回呼,如日誌中所示。
在 JavaScript 中,非同步回呼會使用事件迴圈
這會造成前一次調用的隱私資料可能出現在後續的調用中。有兩種方法可以防止或偵測到此行為。首先,JavaScript 提供非同步和等待關鍵字
let seqId = 0 exports.handler = async (event) => { console.log(`Starting: sequence Id=${++seqId}`) const result = await doWork(seqId) console.log(`Work done: sequence Id=${result}`) } function doWork(id) { return new Promise(resolve => { setTimeout(() => resolve(id), 4000) }) }
使用此語法可防止處理常式在非同步函數完成之前結束。在這種情況下,如果回呼花費的時間超過 Lambda 函數的逾時時間,函數會擲回錯誤,而不是在稍後的調用中傳回回呼結果:
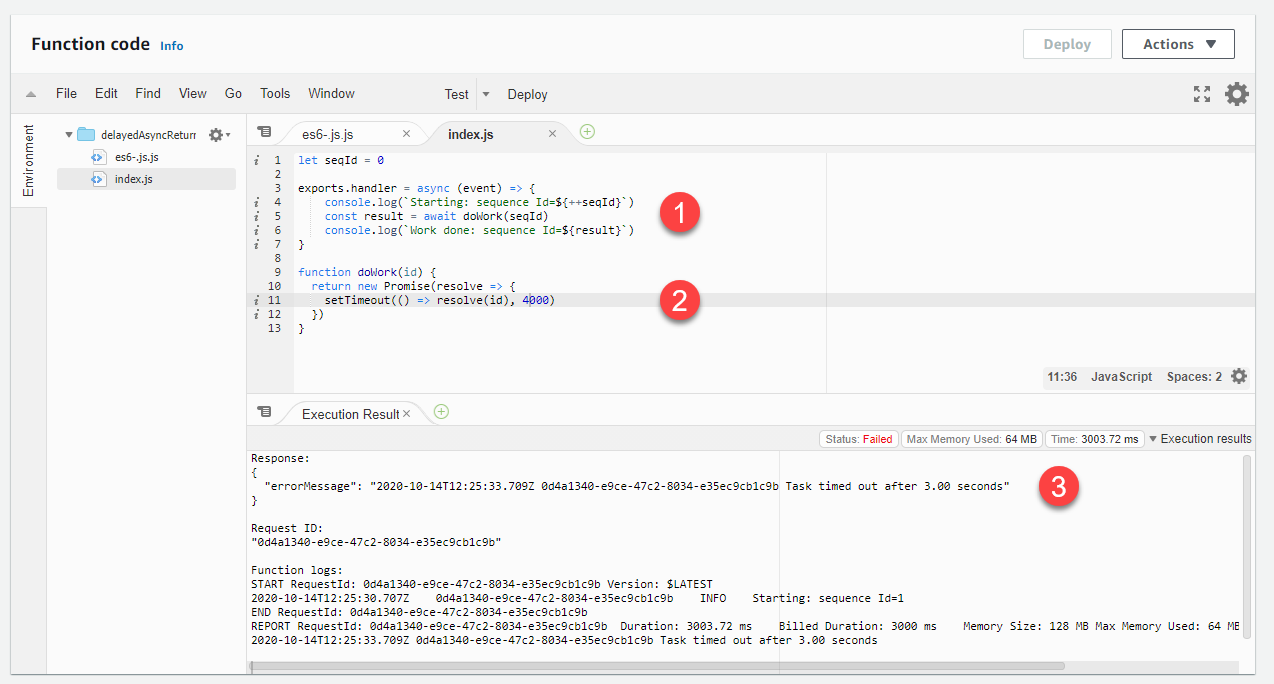
-
程式碼會使用處理常式中的等待關鍵字呼叫非同步
doWork函式。 -
doWork函式需要一段時間才能完成,然後才會解析承諾。 -
函式會逾時,因為
doWork耗費的時間超過逾時限制允許的時間,而且回呼結果不會在稍後的調用中傳回。
一般而言,您應該確定程式碼中的任何背景程序或回呼在程式碼結束前完成。如果這在您的使用案例中無法做到,可以使用識別符來確定回呼屬於目前的調用。為此,可以使用內容物件提供的 awsRequestId。透過將此值傳遞至非同步回呼,您可以將傳遞的值與目前的值進行比較,以偵測回呼是否來自另一個調用:
let currentContext exports.handler = async (event, context) => { console.log(`Starting: request id=$\{context.awsRequestId}`) currentContext = context doWork(context.awsRequestId, function(id) { if (id != currentContext.awsRequestId) { console.info(`This callback is from another invocation.`) } }) } function doWork(id, callback) { setTimeout(() => callback(id), 3000) }
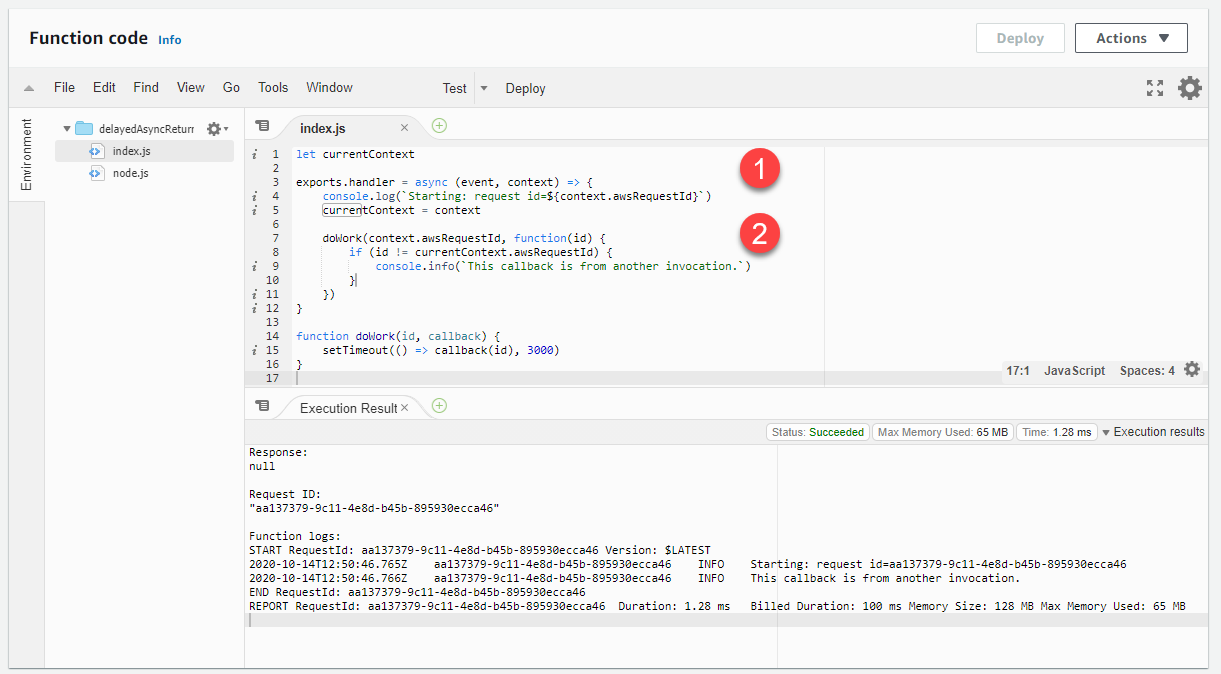
-
Lambda 函數處理常式採用內容參數,提供對唯一調用請求 ID 的存取權。
-
awsRequestId會傳遞至 doWork 函式。在回呼中,ID 會與目前調用的awsRequestId進行比較。如果這些值不同,程式碼可以採取相應的動作。
