本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
# 了解 Lambda 函數擴展
**並行**是 AWS Lambda 函數同時處理的傳輸中請求數量。Lambda 會針對每個並行請求佈建個別的執行環境執行個體。函數收到更多請求時,Lambda 會自動處理執行環境的擴展數量,直到達到帳戶的並行上限為止。根據預設,Lambda 會為您的帳戶提供一個 AWS 區域中所有函數的總並行上限 1,000 個並行執行數。為了支援您的特定帳戶需求,您可以[請求提高配額](https://aws.amazon.com/premiumsupport/knowledge-center/lambda-concurrency-limit-increase/),並設定函數層級並行控制項,讓您的重要函數不會發生限流。
本主題說明 Lambda 中的並行和函數擴展。本主題結束時,您將能了解如何計算並行、視覺化兩個主要並行控制選項 (預留和佈建)、預估適當的並行控制設定,以及檢視指標以進一步最佳化。
**Topics**
+ [了解和視覺化並行](#understanding-concurrency)
+ [計算函數的並行](#calculating-concurrency)
+ [了解預留並行和佈建並行](#reserved-and-provisioned)
+ [了解並行和每秒請求數](#concurrency-vs-requests-per-second)
+ [並行配額](#concurrency-quotas)
+ [設定函數的預留並行](configuration-concurrency.md)
+ [設定函數的佈建並行](provisioned-concurrency.md)
+ [Lambda 擴展行為](scaling-behavior.md)
+ [監控並行](monitoring-concurrency.md)
## 了解和視覺化並行
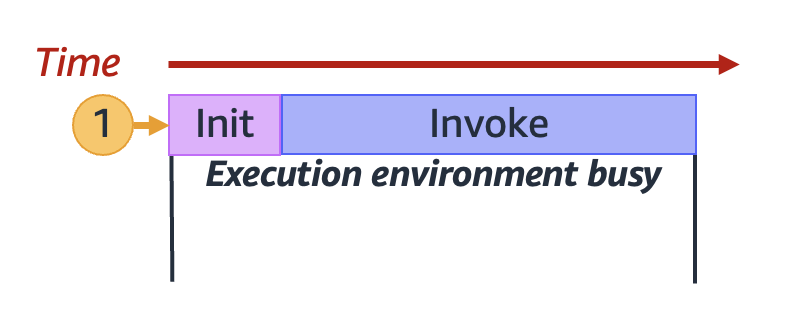
Lambda 會在安全且隔離的[執行環境](lambda-runtime-environment.md)中調用函數。為了處理請求,Lambda 必須先初始化執行環境 ([初始化階段](lambda-runtime-environment.md#runtimes-lifecycle-ib)),然後才能用它來調用函數 ([調用階段](lambda-runtime-environment.md#runtimes-lifecycle-invoke)):
**注意**
實際初始化和調用持續時間可能因許多因素而異,例如您選擇的執行階段和 Lambda 函數程式碼。上圖表的用意並非表示初始化和調用階段持續時間的確切比例。
上圖使用矩形來代表單一執行環境。當函數收到第一個請求 (以帶有 `1` 標籤的黃色圓圈表示),Lambda 會建立一個新的執行環境,並在初始化階段於主處理常式之外執行程式碼。接著 Lambda 會在調用階段執行函數的主要處理常式程式碼。在整個過程中,此執行環境會處於忙碌狀態,無法處理其他請求。
Lambda 完成處理第一個請求後,此執行環境就可以處理同一個函數的其他請求。Lambda 不需要為後續請求重新初始化環境。
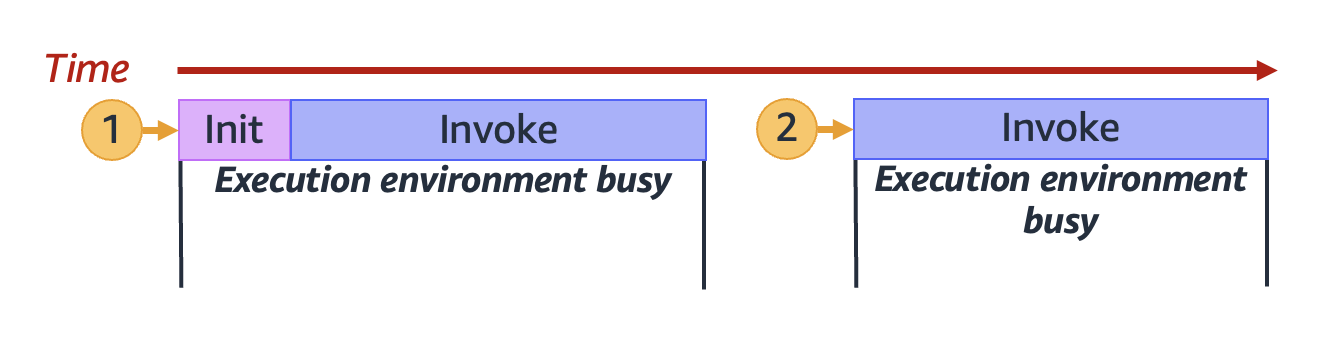
在上圖中,Lambda 重複使用執行環境來處理第二個請求 (以帶 `2` 標籤的黃色圓圈表示)。
目前為止,我們只將注意力放在執行環境的單一執行個體 (即並行 1)。實際上,Lambda 可能需要平行佈建多個執行環境執行個體,以便處理所有傳入的請求。當函數收到新請求,可能會發生的情況有以下兩種:
+ 如果預先初始化的執行環境執行個體可用,Lambda 會用它來處理請求。
+ 若不可用,Lambda 便會建立新的執行環境執行個體來處理請求。
例如,我們來看看當函數收到 10 個請求時會發生什麼情形:
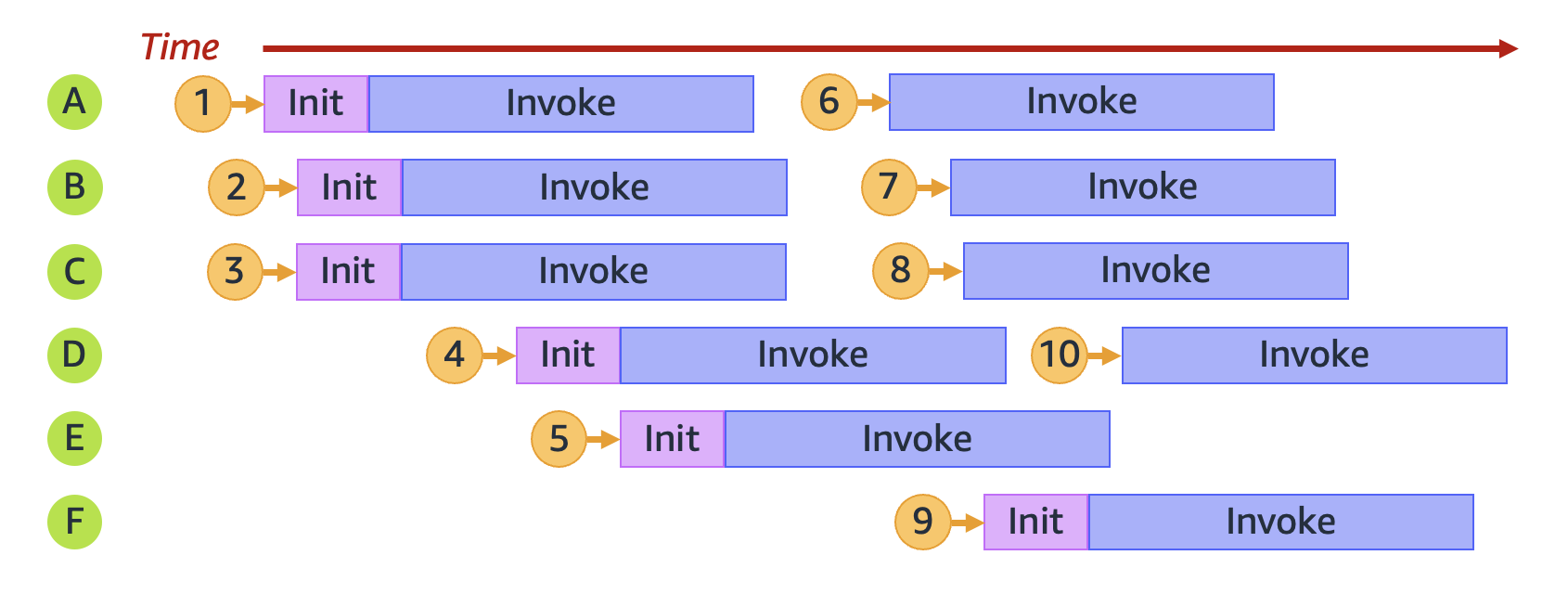
在上圖中,每個水平平面都代表單一執行環境執行個體 (以 `A` 至 `F` 標記)。以下是 Lambda 處理每個請求的方式:
| 請求 | Lambda 行為 | 推理 |
| --- | --- | --- |
| 1 | 佈建新環境 **A** | 這是第一個請求;沒有可用的執行環境執行個體。 |
| 2 | 佈建新環境 **B** | 現有的執行環境執行個體 **A** 忙碌中。 |
| 3 | 佈建新環境 **C** | 現有的執行環境執行個體 **A** 和 **B** 都忙碌中。 |
| 4 | 佈建新環境 **D** | 現有的執行環境執行個體 **A**、**B** 和 **C** 都忙碌中。 |
| 5 | 佈建新環境 **E** | 現有的執行環境執行個體 **A**、**B**、**C** 和 **D** 都忙碌中。 |
| 6 | 重複使用環境 **A** | 執行環境執行個體 **A** 已完成處理請求 **1**,現在可供使用。 |
| 7 | 重複使用環境 **B** | 執行環境執行個體 **B** 已完成處理請求 **2**,現在可供使用。 |
| 8 | 重複使用環境 **C** | 執行環境執行個體 **C** 已完成處理請求 **3**,現在可供使用。 |
| 9 | 佈建新環境 **F** | 現有的執行環境執行個體 **A**、**B**、**C**、**D** 和 **E** 都忙碌中。 |
| 10 | 重複使用環境 **D** | 執行環境執行個體 **D** 已完成處理請求 **4**,現在可供使用。 |
當函數收到更多並行請求時,Lambda 會擴展執行環境執行個體的數量做為回應。以下動畫追蹤一段時間內並行請求的數目:
將上方動畫凍結在六個不同的時間點,我們可以得到下圖:
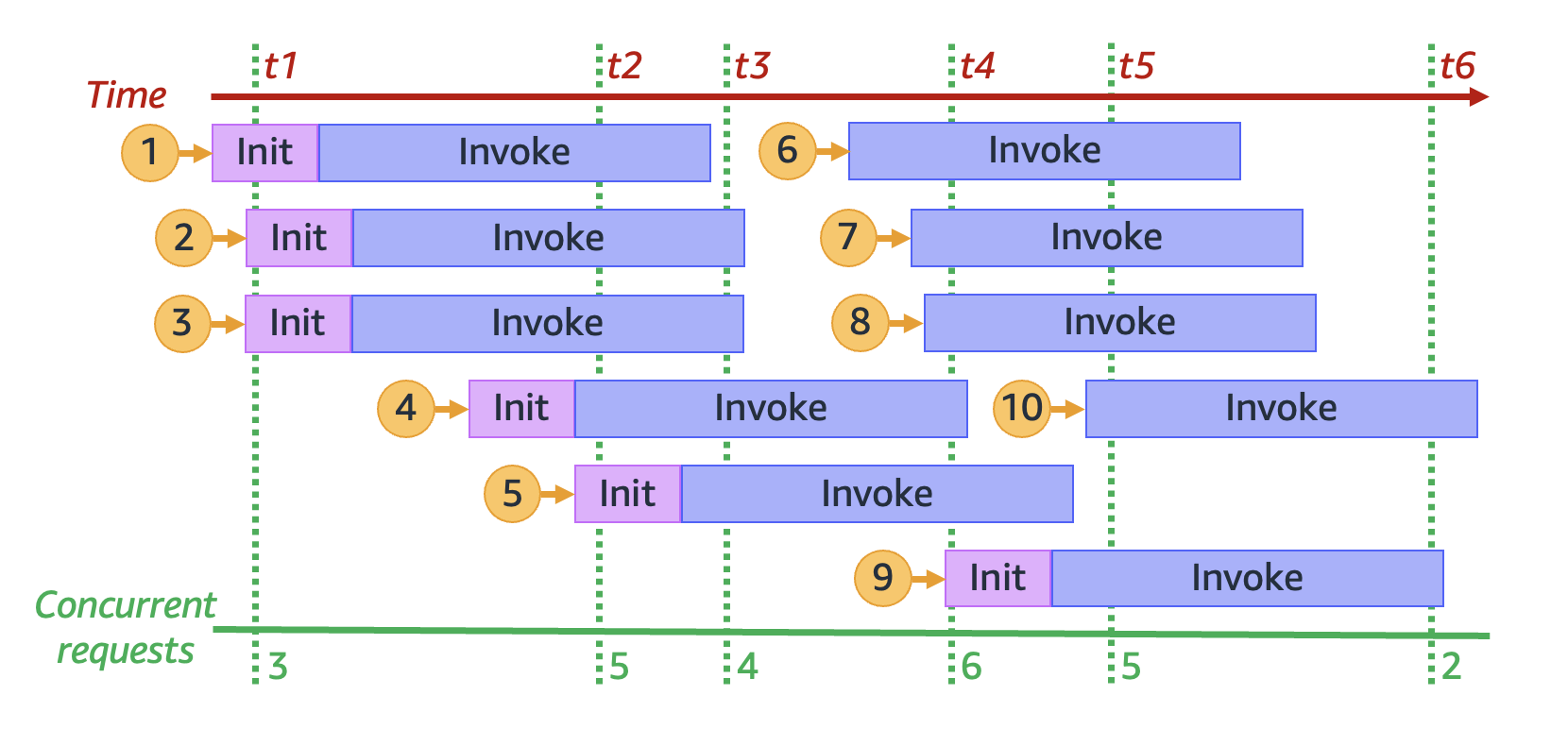
在上圖中,我們可以在任何時間點繪製一條垂直線,並計算與此線相交的環境數量。這可以得出該時間點並行請求的數量。例如,在 `t1` 時間點,有三個作用中環境可以處理三個並行請求。在 `t4` 時間點有六個作用中環境可處理六個並行請求,達到此模擬中的並行請求數上限。
總之,函數的並行就是代表函數同時處理的請求數目。為了回應函數並行的增加,Lambda 會佈建更多執行環境執行個體以滿足請求的需求。
## 計算函數的並行
在一般情況下,一個系統的並行是同時處理多個任務的能力。在 Lambda 中,並行是函數可同時處理的傳輸中請求數目。測量 Lambda 函數並行的快速實用方法是使用以下公式:
```
Concurrency = (average requests per second) * (average request duration in seconds)
```
**並行與每秒請求數不同。**例如,假設函數平均每秒收到 100個請求。如果平均請求持續時間為一秒,那麼並行也會是 100:
```
Concurrency = (100 requests/second) * (1 second/request) = 100
```
但是,如果平均請求持續時間為 500 毫秒,則並行為 50:
```
Concurrency = (100 requests/second) * (0.5 second/request) = 50
```
在實務中並行 50 代表什麼意思? 如果平均請求持續時間為 500 毫秒,則可以將函數的一個執行個體視為每秒能處理兩個請求。如此一來,函數需要 50 個執行個體來處理每秒 100 個請求的負載。並行 50 表示 Lambda 必須佈建 50 個執行環境執行個體,才能有效率地處理此工作負載,而不需要進行限流。底下以方程式的形式表示:
```
Concurrency = (100 requests/second) / (2 requests/second) = 50
```
如果函數收到的請求數量是兩倍 (每秒 200 個請求),但處理每個請求只需要一半的時間 (250 毫秒),則並行仍然是 50:
```
Concurrency = (200 requests/second) * (0.25 second/request) = 50
```
### 測驗您對並行的理解
假設您有一個函數,執行時間平均需要 200 毫秒。在峰值負載期間,您觀察到每秒有 5,000 個請求。峰值負載期間函數的並行為何?
#### 答案
平均函數持續時間為 200 毫秒或 0.2 秒。使用並行公式,您可以插入數字來得出並行為 1,000:
```
Concurrency = (5,000 requests/second) * (0.2 seconds/request) = 1,000
```
或者,平均函數持續時間為 200 毫秒表示函數每秒可以處理 5 個請求。若要處理每秒 5,000 個請求的工作負載,您需要 1,000 個執行環境執行個體。因此並行為 1,000:
```
Concurrency = (5,000 requests/second) / (5 requests/second) = 1,000
```
## 了解預留並行和佈建並行
根據預設,您帳戶設有一個區域中所有函數的並行執行數上限 1,000。您的函數會隨需共用此 1,000 並行的集區。如果您用完可用的並行,您的函數會遇到限流 (也就是,它們開始捨棄請求)。
某些函數的重要性可能高於其他函數。因此,您可能會想配置並行設定,確保重要函數可獲得所需的並行。並行控制項有兩種:預留並行和佈建並行。
+ 使用**預留並行**即可設定並行執行個體數量上限與下限,為函式保留帳戶中的一部分並行配額。如果您不希望其他函數占用所有可用的未預留並行,此功能非常有用。當某個函數具有預留並行時,其他函數都無法使用該並行。
+ 使用**佈建並行**為函數預先初始化多個環境執行個體。這對於縮短冷啟動延遲很有幫助。
### 預留並行
如果您想要保證函數隨時可以使用一定數量的並行,請使用預留並行。
預留並行會設定要配置給函式的並行執行個體數量上限與下限。將預留並行專門留給某個函數時,其他函數都無法使用該並行。換句話說,設定預留並行可能會影響其他函數可用的並行集區。沒有預留並行的函數會共用未預留剩餘的並行集區。
設定預留並行會計入您的整體帳戶並行上限。設定函數的預留並行不收費。
為了更清楚理解預留並行,請參考下圖:
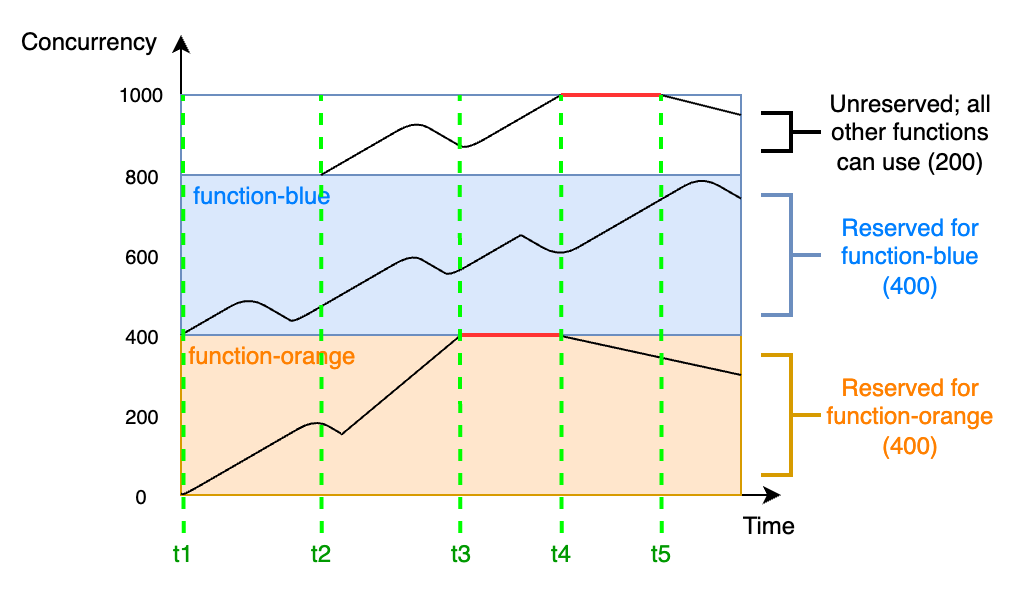
在本圖中,您的帳戶在此區域中所有函數的並行上限為預設值 1,000。假設您有兩個重要函數 `function-blue` 和 `function-orange`,且經常預期出現高調用量。您決定將 400個單位的預留並行提供給 `function-blue`,並為 `function-orange` 提供 400 單位的預留並行。在此範例中,您帳戶中的所有其他函數必須共用剩餘 200 單位的未預留並行。
本圖有五個特點:
+ 在 `t1`,`function-orange` 和 `function-blue` 都開始接收請求。每個函數開始使用自己分配到的預留並行單元。
+ 在 `t2`,`function-orange` 和 `function-blue` 穩定接收更多的請求。同時,您部署了一些其他 Lambda 函數,且這些函數開始接收請求。您沒有將預留並行分配給這些函數。這些函數開始使用剩餘 200 單位的未預留並行。
+ 在 `t3`,`function-orange` 達到並行上限 400。雖然您帳戶中的其他地方存在未使用的並行,但 `function-orange` 無法存取。紅線表示 `function-orange` 正在進行限流,且 Lambda 可能會捨棄請求。
+ 在 `t4`,`function-orange` 接收的請求開始變少,而且不再限流。但是,其他函數出現流量尖峰並開始限流。雖然您帳戶中的其他地方存在未使用的並行,但這些其他函數無法存取。紅線表示其他函數正在進行限流。
+ 在 `t5`,其他函數接收的請求開始變少,而且不再限流。
在此範例中,請注意預留並行產生了下列影響:
+ **函數可以獨立於帳戶中的其他函數進行擴展。**您的帳戶下相同區域中沒有預留並行的所有函數,都會共用未預留的並行集區。如果沒有預留並行,其他函數可能會用盡所有可用的並行。這可以視需要防止您的重要數擴展。
+ **您的函數無法無止盡擴展。**預留並行會對函式的並行上下限設定限制。這表示函數不能使用為其他函數預留的並行,也不能使用未預留集區中的並行。此外,預留並行兼具下限與上限作用:會預留指定的容量專用於您的函式,也會防止容量擴展超過上限。您可以預留並行以防止函數用完帳戶中的所有可用並行,或過載下游資源。
+ **您可能無法使用帳戶可用的所有並行。**預留並行會計入您帳戶的並行上限,但這也表示其他函數無法使用該部分預留並行。如果函數沒有用盡您為它預留的所有並行,那麼實際上就浪費了這些並行。除非浪費的並行可讓您帳戶中的其他函數獲益,這才不會成為問題。
若要管理函數的預留並行設定,請參閱:[設定函數的預留並行](configuration-concurrency.md)。
### 佈建並行
您可以使用預留並行來定義為 Lambda 函數預留的執行環境數目上限。不過,這些環境都不會預先初始化。因此,函數調用可能需要花更長的時間,因為 Lambda 必須先初始化新環境,才能用來調用函數。當 Lambda 必須初始化新環境才能執行調用時,就稱為[冷啟動](lambda-runtime-environment.md#cold-start-latency)。若要緩解冷啟動情形,您可以使用佈建並行。
佈建並行是您要分配給函數的預先初始化執行環境數。如果您為函數設定了佈建並行,Lambda 便會初始化該數量的執行環境,以便立即回應函數請求。
**注意**
設定佈建並行時,您的帳戶會產生額外費用。如果您使用 Java 11 或 Java 17 執行期,您也可以使用 Lambda SnapStart 來解決冷啟動問題,而無需額外付費。SnapStart 會使用執行環境的快取快照來顯著改善啟動效能。您無法對相同的函數版本同時使用 SnapStart 和佈建並行。如需有關 SnapStart 功能、限制和支援區域的詳細資訊,請參閱 [使用 Lambda SnapStart 改善啟動效能](snapstart.md)。
使用佈建並行時,Lambda 仍會在背景回收執行環境。例如,[調用失敗後](lambda-runtime-environment.md#runtimes-lifecycle-invoke-with-errors)可能會發生這種情況。但是在任何給定時間,Lambda 總是會確保預先初始化的環境數量等於函數佈建並行設定的值。重要的是,即使您使用的是佈建並行,如果 Lambda 必須重設執行環境,您仍然可能會遇到冷啟動延遲。
與之相反,如果使用的是預留並行,Lambda 可能會在閒置一段時間後完全終止環境。下圖說明這一點,比較為函數設定預留並行和佈建並行的情況下,單一執行環境的生命週期有何差異。
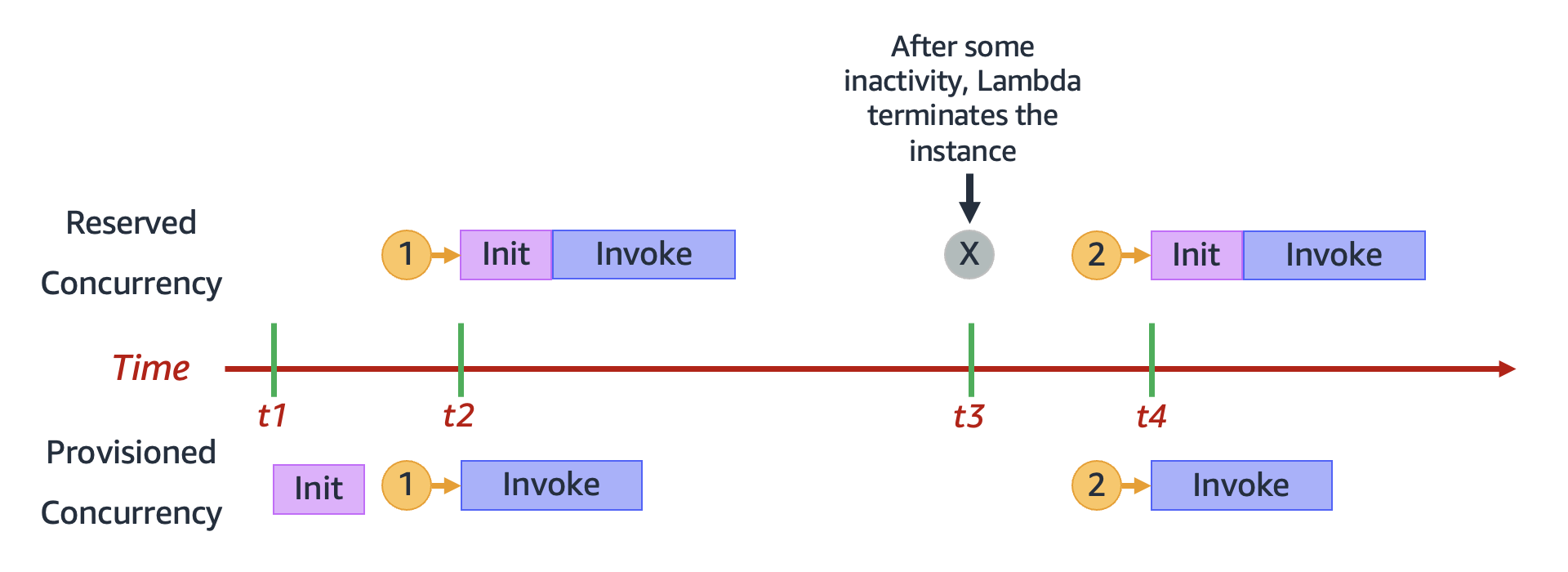
本圖有四個特點:
| 時間 | 預留並行 | 佈建並行 |
| --- | --- | --- |
| t1 | 什麼都沒發生。 | Lambda 會預先初始化執行環境執行個體。 |
| t2 | 請求 1 傳入。Lambda 必須初始化新的執行環境執行個體。 | 請求 1 傳入。Lambda 使用預先初始化的環境執行個體。 |
| t3 | 閒置一段時間後,Lambda 會終止作用中環境執行個體。 | 什麼都沒發生。 |
| t4 | 請求 2 傳入。Lambda 必須初始化新的執行環境執行個體。 | 請求 2 傳入。Lambda 使用預先初始化的環境執行個體。 |
為了更清楚理解佈建並行,請參考下圖:
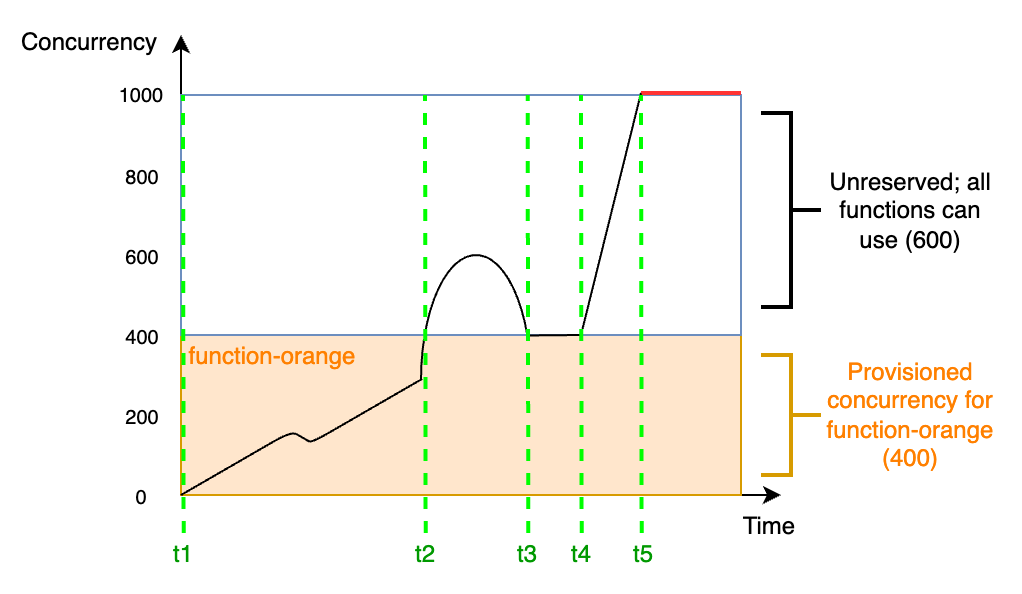
在此圖中,您的帳戶並行上限為 1,000。您決定將 400 單位的佈建並行提供給 `function-orange`。您帳戶中*包括* `function-orange` 在內的所有函數,都可以使用剩餘 600 單位的未預留並行。
本圖有五個特點:
+ 在 `t1`,`function-orange` 開始接收請求。由於 Lambda 已預先初始化 400 個執行環境執行個體,因此 `function-orange` 已準備好立即進行調用。
+ 在 `t2`,`function-orange` 達到 400 個並行請求。因此,`function-orange` 用盡了佈建並行。但是由於仍有未預留並行可用,Lambda 還是可以用來處理 `function-orange` 的其他請求 (沒有限流)。Lambda 必須建立新的執行個體來處理這些請求,而且函數可能會發生冷啟動延遲。
+ 在 `t3`,流量短暫達到峰值後 `function-orange` 回到 400 個並行請求。Lambda 再度能在沒有冷啟動延遲的情況下處理所有請求。
+ 在 `t4`,帳戶中的函數發生流量暴增情形。此暴增可能來自 `function-orange` 或帳戶中的任何其他函數。Lambda 使用未預留並行處理這些請求。
+ 在 `t5`,帳戶中的函數達到最大並行上限 1,000,並且發生限流。
上一個範例只考慮了佈建並行。實際上,您可以對函數同時設定佈建並行和預留並行。如果您有一個函數在工作日期間負責處理調用的一致性負載,但週末期間經常會遇到流量峰值,便可以這麼做。在這種情況下,您可以使用佈建並行設定環境的基準數量來處理平日的請求,並使用預留並行處理週末峰值流量。請思考下圖情形:
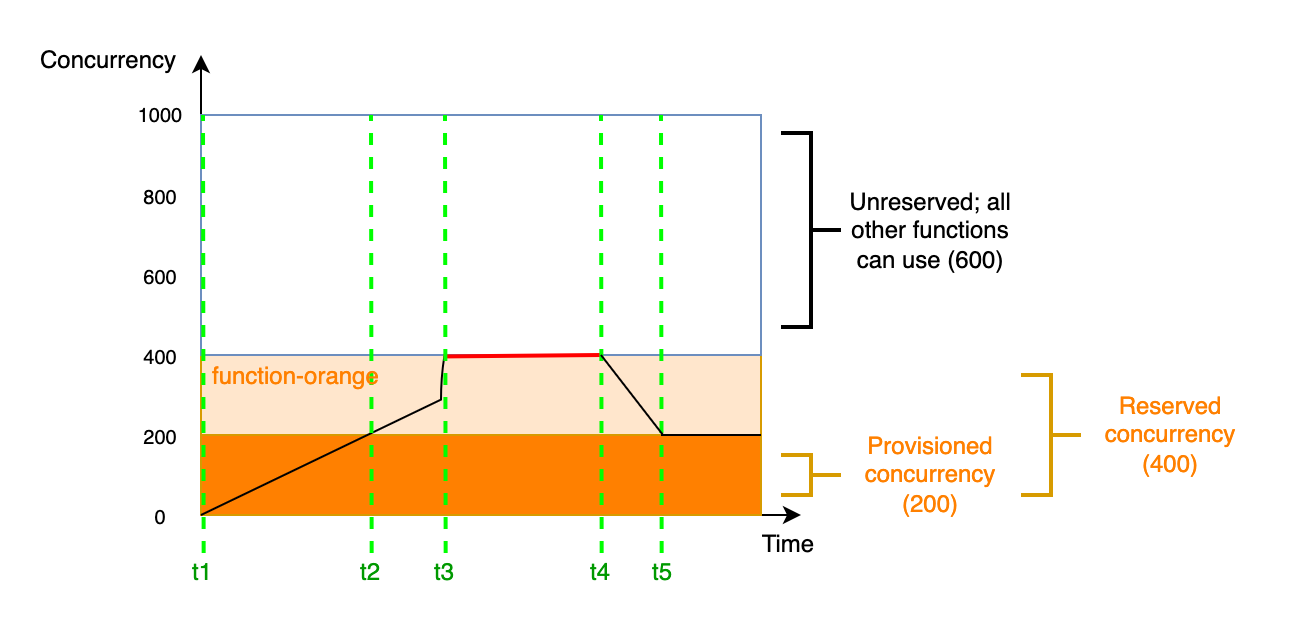
在此圖中,假設您為 `function-orange` 設定了 200 單位的佈建並行,以及 400 單位的預留並行。因為您已設定預留並行,因此 `function-orange` 完全無法使用 600 單位的未預留並行。
此圖有 5 個特點:
+ 在 `t1`,`function-orange` 開始接收請求。由於 Lambda 已預先初始化 200 個執行環境執行個體,因此 `function-orange` 已準備好立即進行調用。
+ 在 `t2`,`function-orange` 用盡了所有佈建並行。`function-orange` 可以使用預留並行繼續處理請求,但這些請求可能會遇到冷啟動延遲。
+ 在 `t3`,`function-orange` 達到 400 個並行請求。因此,`function-orange` 用盡了所有預留並行。由於 `function-orange` 不能使用未預留並行,因此請求開始限流。
+ 在 `t4`,`function-orange` 接收的請求開始變少,而且不再限流。
+ 在 `t5`,`function-orange` 下降到 200 個並行請求,因此所有請求都能再次使用佈建並行 (即無冷啟動延遲)。
預留並行和佈建並行都會計入您的帳戶並行上限和[區域配額](gettingstarted-limits.md)中。換句話說,分配預留和佈建並行可能會影響其他函數可用的並行集區。設定佈建並行會產生 費用 AWS 帳戶。
**注意**
如果在函數版本與別名功能上佈建的並行數量加到函數的預留並行,則所有呼叫都會在佈建的並行上執行。此組態也有對未發佈版本函數 (`$LATEST`) 進行節流的效果,以防止其執行。您無法配置多於函數預留並行的佈建並行。
若要管理函數的佈建並行設定,請參閱 [設定函數的佈建並行](provisioned-concurrency.md)。若要根據排程或應用程式使用率自動佈建並行擴展,請參閱 [使用 Application Auto Scaling 自動化佈建並行管理](provisioned-concurrency.md#managing-provisioned-concurency)。
### Lambda 如何配置佈建並行
佈建並行不會在設定後立即上線。Lambda 會在準備一兩分鐘後,開始配置佈建的並行。對於每個函數,Lambda 每分鐘最多可以佈建 6,000 個執行環境,無論如何 AWS 區域。這與函數的[並行擴展率](scaling-behavior.md#scaling-rate)完全相同。
當您提交配置佈建並行的請求時,在 Lambda 完全配置完成之前,您無法存取任何這些環境。例如,如果您請求 5,000 個佈建並行,在 Lambda 完全完成分配 5,000 個執行環境之前,您的請求都無法使用佈建並行。
### 比較預留並行和佈建並行
下表總結並比較預留和佈建並行。
| 主題 | 預留並行 | 佈建並行 |
| --- | --- | --- |
| 定義 | 函數的執行環境執行個體數目上限。 | 為函數設定預先佈建的執行環境執行個體數目。 |
| 佈建行為 | Lambda 會隨需佈建新的執行個體。 | Lambda 會預先佈建執行個體 (即在函數開始接收請求之前)。 |
| 冷啟動行為 | 由於 Lambda 必須隨需建立新執行個體,因此可能會發生冷啟動延遲。 | 由於 Lambda 不需要隨需建立執行個體,因此不可能會冷啟動延遲。 |
| 限流行為 | 達到預留並行上限時,會對函數限流。 | 如果沒有設定預留並行:達到佈建並行上限時,函數會使用未預留的並行。
如果有設定預留並行:達到預留並行上限時,會對函數限流。 |
| 未設定情況下的預設行為 | 函數會使用帳戶中可用的未預留並行。 | Lambda 不會預先佈建任何執行個體。反之,如果沒有設定預留並行:函數會使用帳戶中可用的未預留並行。
如果有設定預留並行:函數會使用預留並行。 |
| 定價 | 不收取額外費用。 | 會產生額外費用。 |
## 了解並行和每秒請求數
如前一節所述,並行與每秒請求數不同。這是使用平均請求持續時間小於 100 毫秒的函數時特別重要的區別。
對於帳戶中的所有函數,Lambda 會強制執行每秒請求數限制,等於帳戶並行的 10 倍。例如,由於預設帳戶並行限制為 1,000,因此您帳戶中的函數每秒最多可處理 10,000 個請求。
例如,假設有一個平均請求持續時間為 50 毫秒的函數。在每秒 20,000 個請求時,此函數的並行如下:
```
Concurrency = (20,000 requests/second) * (0.05 second/request) = 1,000
```
根據此結果,您可能會預期帳戶並行限制為 1,000 就足以處理此負載。不過,由於每秒 10,000 個請求的限制,您的函數每秒只能處理 20,000 個請求總數中的 10,000 個。此函數遇到了限流。
因此,在為函數配置並行設定時,您必須同時考慮並行和每秒請求數。這種情況下,您需要請求將帳戶並行限制提高到 2,000,因為這會將每秒請求總數限制提高到 20,000。
**注意**
根據此每秒請求數限制,假設每個 Lambda 執行環境每秒最多只能處理 10 個請求是不正確的。計算配額時,Lambda 不會觀察任何個別執行環境的負載,而只會考慮整體並行情況和每秒的整體請求數。
### 測試您對並行的理解 (低於 100 毫秒函數)
假設您有一個函數,執行時間平均需要 20 毫秒。在峰值負載期間,您觀察到每秒有 30,000 個請求。峰值負載期間函數的並行為何?
#### 答案
平均函數持續時間為 20 毫秒或 0.02 秒。使用並行公式,您可以插入數字來得出並行為 600:
```
Concurrency = (30,000 requests/second) * (0.02 seconds/request) = 600
```
依預設,1,000 的帳戶並行限制似乎足以處理此負載。不過,每秒 10,000 個請求的限制不足以應對每秒 30,000 個傳入請求的狀況。若要完全容納 30,000 個請求,您需要請求將帳戶並行限制提高到 3,000 或更高。
每秒請求數限制適用於 Lambda 中涉及並行的所有配額。換句話說,它適用於同步隨需函數、使用佈建並行的函數,以及[並行擴展行為](scaling-behavior.md)。例如,在以下幾種情況中,您必須仔細考慮並行和每秒請求數限制:
+ 使用隨需並行的函數每 10 秒的並行可能爆增 500,或每 10 秒內的每秒請求數增加 5,000,以先發生者為準。
+ 假設您有一個函數,其佈建並行分配為 10。此函數會在 10 個並行或每秒 100 個請求後 (以先發生者為準) 溢出到隨需並行。
## 並行配額
Lambda 會針對區域中所有函數可用的並行總量設定配額。這些配額存在於兩個層級:
+ **帳戶層級**,預設情況下,函數最多可有 1,000 單位的並行。若要提升配額,請參閱《Service Quotas 使用者指南》**中的[請求提升配額](https://docs.aws.amazon.com/servicequotas/latest/userguide/request-quota-increase.html)。
+ **函數層級**,預設情況下,您可在所有函數間保留最多 900 單位的並行。無論您的總帳戶並行限制為何,Lambda 一律會為未明確保留並行保留的函數保留 100 個並行單位。例如,如果您將帳戶並行上限增加到 2,000,就可以在函數層級預留最多 1,900 單位的並行。
+ 在帳戶層級和函數層級,Lambda 也會強制執行每秒 10 倍於對應並行配額的請求限制。例如,這適用於帳戶層級並行、使用隨需並行的函數、使用佈建並行的函數,以及[並行擴展行為](scaling-behavior.md)。如需詳細資訊,請參閱[了解並行和每秒請求數](#concurrency-vs-requests-per-second)。
若要檢查目前的帳戶層級並行配額,請使用 AWS Command Line Interface (AWS CLI) 執行下列命令:
```
aws lambda get-account-settings
```
您應該會看到類似以下的輸出:
```
{
"AccountLimit": {
"TotalCodeSize": 80530636800,
"CodeSizeUnzipped": 262144000,
"CodeSizeZipped": 52428800,
"ConcurrentExecutions": 1000,
"UnreservedConcurrentExecutions": 900
},
"AccountUsage": {
"TotalCodeSize": 410759889,
"FunctionCount": 8
}
}
```
`ConcurrentExecutions` 是您的帳戶層級並行配額總計。`UnreservedConcurrentExecutions` 是您仍可配置給函數的保留並行數量。
函數收到更多請求時,Lambda 會自動提高執行環境的數量來處理這些請求,直到您的帳戶達到並行配額為止。但是,為了防止因應突然爆發的流量而過度擴展,Lambda 限制了函數擴展的速度。此**並行擴展速率**是您帳戶中的函數可擴展以因應增加的請求的最高速率。(也就是說,Lambda 建立新執行環境的速度可以有多快。) 並行擴展速率與帳戶層級並行限制不同,後者是您的函數可用的並行總量。
**在每個 AWS 區域和每個函數中,您的並行擴展速率為每 10 秒 1,000 個執行環境執行個體 (或每 10 秒每秒 10,000 個請求)。**換句話說,Lambda 每隔 10 秒就可以為每個函數配置最多 1,000 個額外執行環境的執行個體,或者每秒容納 10,000 個額外請求。
通常情況下,您不需要擔心此限制。對於大多數使用案例,Lambda 的擴展速率已足夠。
重要的是,並行擴展速率是函數層級限制。這意味著帳戶中的每個函數都可以獨立於其他函數進行擴展。
如需擴展行為的詳細資訊,請參閱 [Lambda 擴展行為](scaling-behavior.md)。