本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
透過 Lambda 建立事件驅動型架構
事件是指能夠觸發 Lambda 函式執行的任何事物。事件可以透過兩種方式觸發 Lambda 函數:透過直接調用 (推送) 和事件來源映射 (提取)。
許多 AWS 服務可以直接叫用您的 Lambda 函數。這些服務會將事件推送至您的 Lambda 函式。觸發函數的事件幾乎可以是任何事件,從透過 API Gateway 的 HTTP 請求、由 EventBridge 規則管理的排程、 AWS IoT 事件或 Amazon S3 事件。透過事件來源映射,Lambda 會主動從佇列或串流擷取 (或拉取) 事件。您僅需設定 Lambda 檢查來自支援服務的事件,Lambda 便會自動處理輪詢與函式調用作業。
事件在傳遞至函式時,會以 JSON 格式結構化呈現。JSON 結構會因事件來源服務與類型而異。雖然標準 Lambda 函數調用最多可持續 15 分鐘,但 Lambda 最適合持續一秒或更短的短調用。此特性在事件驅動型架構中尤為明顯:在這種架構中,每個 Lambda 函式都被視為一個微服務,負責執行一組精簡的特定指令。
注意
事件驅動型架構使用網路跨不同系統進行通訊,這會引入可變延遲。對於需要極低延遲的工作負載,例如即時交易系統,此設計可能不是最佳選擇。但是,對於高度可擴展和可用的工作負載,或是具有不可預測流量模式的工作負載,事件驅動型架構可以提供有效的方式來符合這些需求。
事件驅動型架構的優勢
在事件驅動型架構中,Lambda 支援兩種調用方法:
-
直接調用 (推送方法): AWS 服務會直接觸發 Lambda 函數。例如:
-
Amazon S3 於檔案上傳時觸發函式
-
API Gateway 於接收 HTTP 請求時觸發函式
-
-
事件來源映射 (拉取方法):Lambda 會擷取事件並調用函式。例如:
-
Lambda 從 Amazon SQS 佇列擷取訊息後調用函式
-
Lambda 從 DynamoDB 串流讀取記錄後調用函式
-
如下文所述,這兩種方法共同實現了事件驅動型架構的優勢。
將輪詢和 Webhook 取代為事件
許多傳統架構會透過輪詢與 Webhook 機制,在不同元件之間傳達狀態資訊。輪詢在擷取更新時的效率可能非常低,因為新資料變得可用和與下游服務同步之間存在延遲。您想要整合的其他微服務並非總是支援 Webhook。它們也可能需要自訂授權和身分驗證組態。在這兩種情況下,如果沒有開發團隊的額外工作,這些整合方法難以隨需擴展。
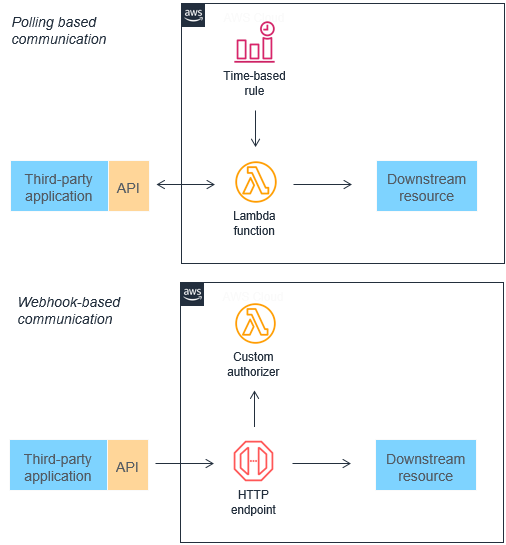
這兩種機制都可以取代為事件,這些事件可以篩選、路由並推送至下游使用微服務。此方法可能會導致頻寬耗用減少、CPU 使用率降低,並可能降低成本。這些架構還可以降低複雜性,因為每個功能單元都較小,而且程式碼通常較少。
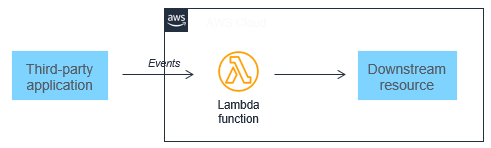
事件驅動型架構也可以更輕鬆地設計近乎即時的系統,協助組織遠離批次型處理。事件會在應用程式中的狀態變更時產生,因此微服務的自訂程式碼應設計為處理單一事件。由於擴展由 Lambda 服務處理,因此該架構無需變更自訂程式碼,即可應對流量的顯著增加。隨著事件向上擴展,處理事件的運算層也隨之擴展。
降低複雜性
微服務可讓開發人員和架構師簡化複雜的工作流程。例如,電子商務整體可以分為訂單接受和付款程序,以及單獨的庫存、履行和會計服務。在整體中管理和協調可能很複雜,會成為一系列與事件非同步通訊的解耦服務。
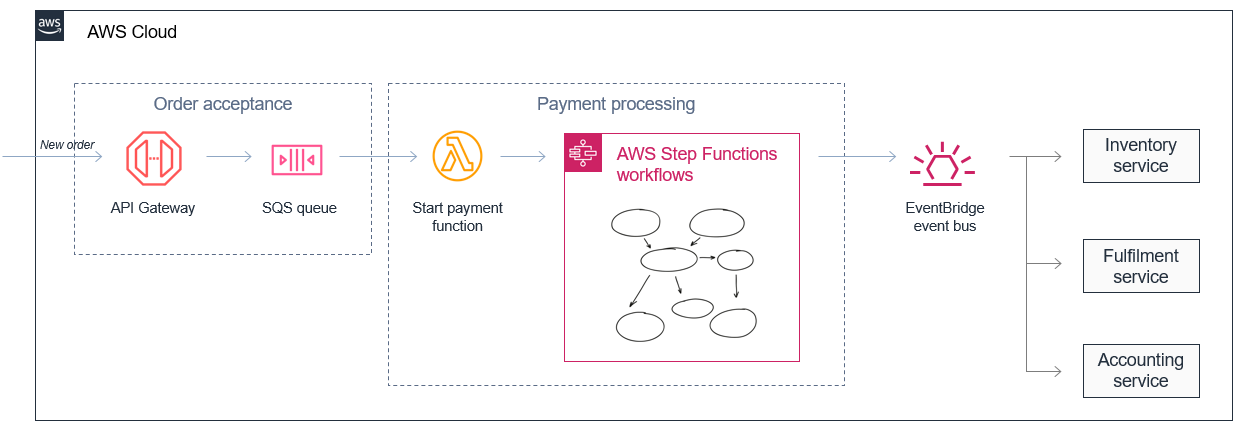
此方法也可讓您組合以不同速率處理資料的服務。在這種情況下,訂單接受微型服務可以透過緩衝 Amazon SQS 佇列中的訊息來存放大量傳入訂單。
由於處理付款的複雜性,付款處理服務通常較慢,因此可以從 Amazon SQS 佇列取得穩定的訊息串流。它可以使用 協調複雜的重試和錯誤處理邏輯 AWS Step Functions,並為數十萬個訂單協調作用中的付款工作流程。
替代方法:對於使用標準程式設計語言的協同運作,您可以使用 Lambda 耐久函數。耐用的函數可讓您使用自動檢查點和重試,以程式碼撰寫訂單接受、付款處理和通知邏輯。當工作流程主要涉及 Lambda 函數,而且您偏好在程式碼中保留協同運作邏輯時,此方法運作良好。
改善可擴展性和可擴充性
微服務產生的事件通常會發布至 Amazon SNS 和 Amazon SQS 等傳訊服務。這些行為就像微服務之間的彈性緩衝,有助於在流量增加時處理擴展。然後,Amazon EventBridge 之類的服務可以根據事件的內容篩選和路由訊息,如規則中所定義。因此,事件型應用程式可能比單體式應用程式更具可擴展性,並提供更大的備援。
此系統也具有高度可擴展性,允許其他團隊擴展特性並新增功能,而不會影響訂單處理和付款處理微服務。透過使用 EventBridge 發布事件,此應用程式可與庫存微服務等現有系統整合,但也可讓任何未來應用程式以事件取用者身分整合。事件的生產者不了解事件取用者,這有助於簡化微服務邏輯。
事件驅動型架構的權衡
可變延遲
與單一裝置上可能處理相同記憶體空間內一切的單體應用程式不同,事件驅動型應用程式會跨網路進行通訊。此設計引入了可變延遲。雖然可以設計應用程式以將延遲降至最低,但單體式應用程式幾乎總是可以最佳化來降低延遲,而犧牲可擴展性和可用性。
需要穩定低延遲效能的工作負載 (例如銀行中的高頻交易應用程式,或倉儲中低於一毫秒的機器人自動化),並非事件驅動型架構的理想候選項目。
最終一致性
事件代表狀態變更,許多事件在任何指定時間點流經架構中的不同服務,此類工作負載通常最終會一致
某些工作負載包含最終一致 (例如,目前小時內的總訂單數) 或高度一致 (例如,目前庫存) 的要求組合。對於那些需要高度資料一致性的工作負載,有架構模式可支援此作業。例如:
-
DynamoDB 可以提供高度一致性讀取,有時延遲較高,會耗用比預設模式更高的輸送量。DynamoDB 也能支援交易,可協助維持資料一致性。
-
您可以使用 Amazon RDS 來實現需要 ACID 屬性
的功能,但關聯式資料庫的可擴展性一般低於 DynamoDB 等 NoSQL 資料庫。Amazon RDS Proxy 可協助管理 Lambda 函數等暫時性取用者的連線集區和擴展。
事件型架構通常以個別事件為基礎設計,而非大批次資料。通常,工作流程旨在管理個別事件或執行流程的步驟,而不是同時在多個事件上操作。在無伺服器架構中,即時事件處理優先於批次處理:應以多次小規模增量更新取代批次作樂。雖然這可以提高工作負載的可用性和可擴展性,但也讓事件更難以感知其他事件。
將值傳回給呼叫者
在許多情況下,事件型應用程式是非同步的。這意味著呼叫者服務不會等待來自其他服務的請求,然後再繼續其他工作。這是事件驅動型架構的基本特性,可實現可擴展性和彈性。這意味著傳遞傳回值或工作流程的結果會比同步執行流程更複雜。
生產系統中的大多數 Lambda 調用都是非同步的,可回應來自 Amazon S3 或 Amazon SQS 等服務的事件。在這些情況下,處理事件的成功或失敗通常比傳回值更重要。在 Lambda 中提供無效字母佇列 (DLQ) 等功能,以確保您可以識別和重試失敗的事件,而無需通知呼叫者。
跨服務和函數進行偵錯
與單體式應用程式相比,偵錯事件驅動型系統的方式也有所不同。由於傳遞事件的系統和服務不同,因此無法在發生錯誤時記錄和重現多個服務的確切狀態。由於每個服務和函數調用都具有單獨的日誌檔案,因此確定導致錯誤的特定事件發生的情況可能更複雜。
在事件驅動型系統中成功建置偵錯方法有三個重要要求。首先,強大的記錄系統至關重要,這由 Amazon CloudWatch 跨 AWS 服務提供,並內嵌在 Lambda 函數中。其次,在這些系統中,請務必確保每個事件都具有一個交易識別碼,該識別碼在整個交易的每個步驟中都會記錄下來,以在搜尋日誌時提供協助。
最後,強烈建議使用偵錯和監控服務 (例如 AWS X-Ray) 來自動化日誌的剖析和分析。這可以跨多個 Lambda 調用和服務取用日誌,讓您更輕鬆地找出問題的根本原因。如需有關使用 X-Ray 進行疑難排解的深度資訊,請參閱疑難排解演練。
基於 Lambda 的事件驅動型應用程式反模式
使用 Lambda 建置事件驅動型架構時,請避免下列常見的反模式。這些模式有效,但可能會增加成本和複雜性。
Lambda 單體
在許多從傳統伺服器 (例如 Amazon EC2 執行個體或 Elastic Beanstalk 應用程式) 遷移而來的應用程式中,開發人員通常會採用「直接移轉」的方式沿用現有程式碼。通常,這會產生單一 Lambda 函數,其中包含針對所有事件觸發的所有應用程式邏輯。對於基本 Web 應用程式,單體式 Lambda 函數會處理所有 API Gateway 路由,並與所有必要的下游資源整合。
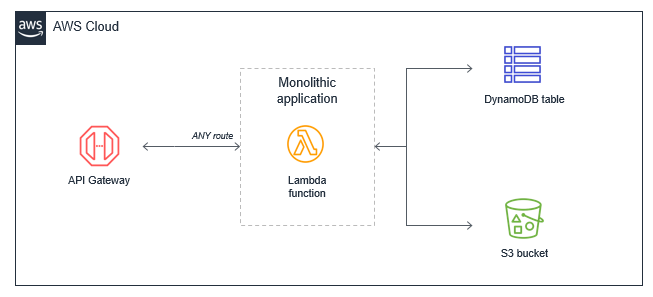
此方法有數個缺點:
-
套件大小 – Lambda 函數可能較大,因為它包含所有路徑的所有可能程式碼,這使得 Lambda 服務執行速度變慢。
-
難以強制執行最低權限:函式的執行角色必須允許所有路徑所需的所有資源的許可,導致許可範圍非常廣泛。這是一個安全隱患題。功能單體中的許多路徑不需要所有已授予的許可。
-
更難升級:在生產系統中,對單一函式的任何升級風險都較大,可能導致整個應用程式中斷運作。升級 Lambda 函數中的單一路徑就是對整個函數的升級。
-
更難維護:由於程式碼儲存庫為單體架構,多位開發人員協同處理服務時會面臨更多困難。它也會增加開發人員的認知負擔,並使為程式碼建立適當的測試涵蓋範圍變得更加困難。
-
更難重複使用程式碼:更加難以將可重複使用的程式庫與單體分隔,導致程式碼重複使用變得更加困難。當您開發和支援更多專案時,這可能會讓支援程式碼和擴展團隊速度變得更加困難。
-
更難測試:隨著程式碼行數的增加,對程式碼庫中所有可能的輸入和進入點組合進行單元測試會更加困難。對於程式碼較少的小型服務,實作單元測試通常更容易。
首選的替代方案是將單體 Lambda 函數分解為個別微服務,將單一 Lambda 函數映射至單一定義良好的任務。在這個具有幾個 API 端點的簡易 Web 應用程式中,產生的微服務型架構可以基於 API Gateway 路由。
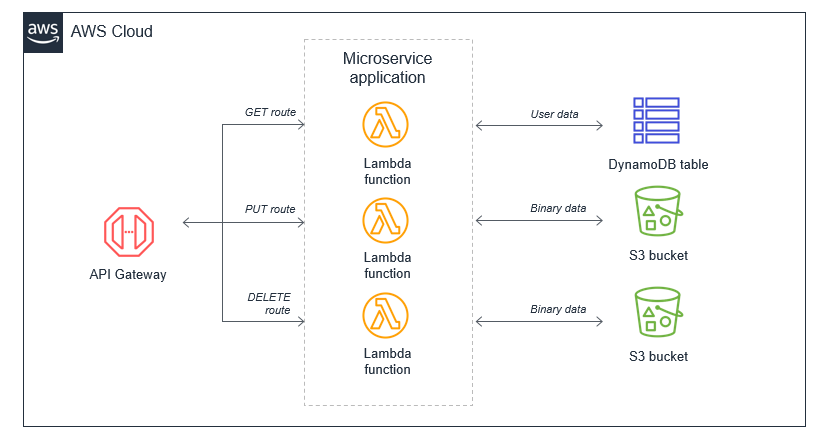
導致 Lambda 函數失控的遞迴模式
AWS 服務會產生叫用 Lambda 函數的事件,而 Lambda 函數可以將訊息傳送到 AWS 服務。通常,調用 Lambda 函數的服務或資源應與函數輸出至的服務或資源不同。如果不進行管理,可能會導致無限迴圈。
例如,Lambda 函式會將物件寫入 Amazon S3 物件,進而透過 put 事件調用同一個 Lambda 函式。調用會導致第二個物件寫入儲存貯體,這會調用相同的 Lambda 函數:
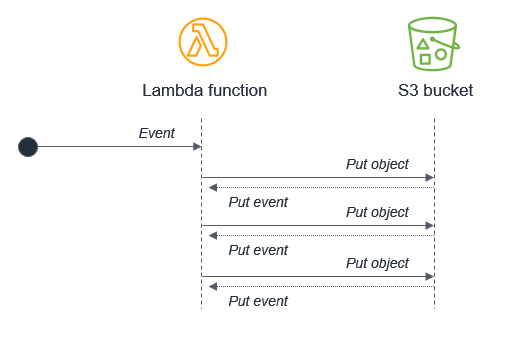
雖然大多數程式設計語言都存在無限迴圈的可能性,但此反模式有可能在無伺服器應用程式中取用更多資源。Lambda 和 Amazon S3 都會根據流量自動擴展,因此迴圈可能會導致 Lambda 擴展以使用所有可用的並行,Amazon S3 將繼續寫入物件並為 Lambda 產生更多事件。
此範例以 S3 為例,但 Amazon SNS、Amazon SQS、DynamoDB 及其他服務中也存在遞迴迴圈的風險。您可以使用遞迴迴圈偵測功能,找出並避免此反模式。
呼叫 Lambda 函數的 Lambda 函數
函數支援封裝和程式碼重複使用。大多數程式設計語言都支援程式碼同步呼叫程式碼庫中的函數的概念。在此情況下,呼叫者會等到函數傳回回應。
注意
雖然 Lambda 函數因為成本和複雜性問題而直接呼叫其他 Lambda 函數通常是反模式函數,但這不適用於耐用函數,其專門設計來透過調用其他函數來協調多步驟工作流程。
當傳統伺服器或虛擬執行個體發生這種情況時,作業系統排程器會切換至其他可用的工作。CPU 以 0% 還是 100% 執行並不影響應用程式的整體成本,因為您要支付擁有和營運伺服器的固定成本。
此模型通常無法很好地適應無伺服器開發。例如,請考慮一個由三個處理訂單的 Lambda 函數組成的簡易電子商務應用程式:
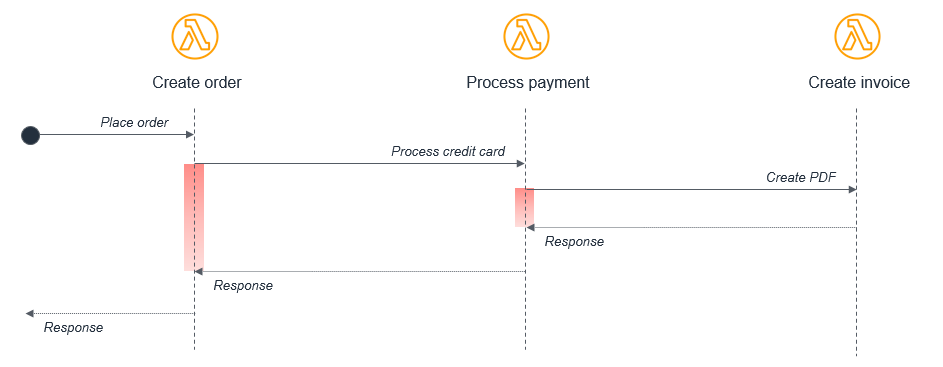
在此案例中,Create order 函數會呼叫 Process payment 函數,進而呼叫 Create invoice 函數。雖然此同步流程可能在伺服器上的單一應用程式內運作,但在分散式無伺服器架構中引入了幾個可避免的問題:
-
成本:使用 Lambda 時,您需要支付調用期間的費用。在此範例中,當 Create invoice 函式執行時,其他兩個函式也會在等待狀態下執行,在圖表上以紅色顯示。
-
錯誤處理:在巢狀調用中,錯誤處理可能會變得更複雜。例如,建立發票中的錯誤可能需要程序付款函數來撤銷費用,或者可能改為重試建立發票程序。
-
緊耦合:處理付款通常比建立發票需要更長時間。在此模型中,整個工作流程的可用性受最慢函數限制。
-
擴展:所有三個函式的並行必須相等。在忙碌的系統中,這會使用比其他方式需要更多的並行。
在無伺服器應用程式中,有兩種常見方法可以避免此模式。首先,在 Lambda 函式之間使用 Amazon SQS 佇列。如果下游程序比上游程序更慢,佇列會長期保留訊息,並解耦這兩個函數。在此範例中,建立訂單函數會將訊息發佈至 Amazon SQS 佇列,而程序付款函數會使用來自佇列的訊息。
第二個方法是使用 AWS Step Functions。對於具有多種類型的故障和重試邏輯的複雜程序,Step Functions 有助於減少協調工作流程所需的自訂程式碼數量。因此,Step Functions 會協調工作並穩健地處理錯誤和重試,而 Lambda 函數僅包含商業邏輯。
在單一 Lambda 函數內的同步等待
請確定未在單一 Lambda 函數中同步排程任何可能並行的活動。例如,Lambda 函數可能會寫入 S3 儲存貯體,然後寫入 DynamoDB 資料表:
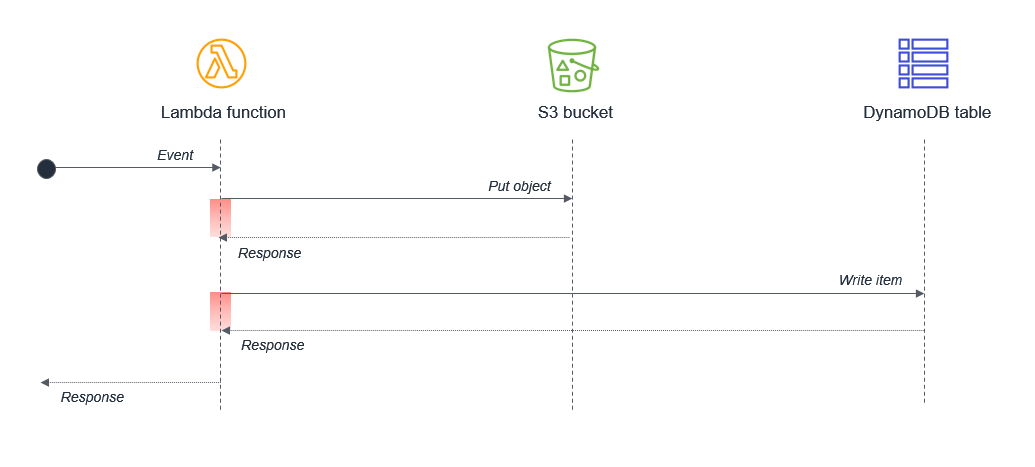
在此設計中,由於各項互動採取循序執行方式,等待時間會逐漸累積放大。若第二個任務需依賴第一個任務完成,您可透過兩個獨立的 Lambda 函式來減少總等待時間與執行成本:
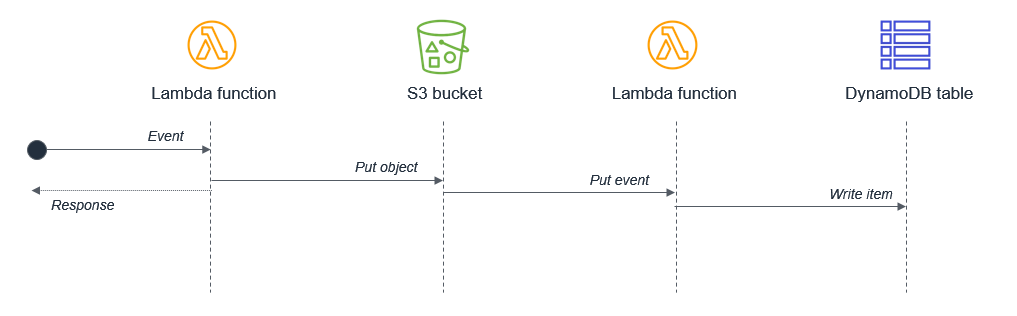
在此設計中,第一個 Lambda 函式會在將物件放入 Amazon S3 儲存貯體之後立即回應。S3 服務會調用第二個 Lambda 函數,然後將資料寫入至 DynamoDB 資料表。此方法可將 Lambda 函數執行的總等待時間降至最低。
