本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
設計 Lambda 應用程式
架構良好的事件驅動應用程式使用 AWS 服務和自訂程式碼的組合來處理和管理請求和資料。本章著重介紹應用程式設計中與 Lambda 相關的主題。在為忙碌的生產系統設計應用程式時,無伺服器架構師有許多重要的考量。
許多適用於軟體開發和分散式系統的最佳實務,也適用於無伺服器應用程式開發。整體目標是開發符合下列條件的工作負載:
-
可靠 – 為您的最終使用者提供高水準的可用性。 AWS 無伺服器服務是可靠的,因為其亦專為解決故障而設計。
-
耐久 – 提供符合工作負載耐久性需求的儲存選項。
-
安全 – 遵循最佳實務,並使用提供的工具來保護對工作負載的存取,並在發生任何問題時限制影響範圍。
-
高效能 – 有效率地使用運算資源,並滿足最終使用者的效能需求。
-
具成本效益 – 設計可避免不必要的成本的架構,這些架構可以在不超支的情況下進行擴展及除役,而不會產生大量開銷。
下列設計原則可協助您建置符合這些目標的工作負載。並非每一項原則都適用於所有架構,但這些原則應能為您的總體架構決策提供指引。
使用服務而非自訂程式碼
無伺服器應用程式通常包含數個 AWS 服務,與 Lambda 函數中執行的自訂程式碼整合。雖然 Lambda 可以與大多數 AWS 服務整合,但無伺服器應用程式中最常使用的服務如下:
| Category | AWS 服務 |
|---|---|
|
運算 |
AWS Lambda |
|
資料儲存 |
Amazon S3 Amazon DynamoDB Amazon RDS |
|
API |
Amazon API Gateway |
|
應用程式整合 |
Amazon EventBridge Amazon SNS Amazon SQS |
|
協調 |
Lambda 耐用函數 AWS Step Functions |
|
串流資料和分析 |
Amazon Data Firehose |
注意
許多無伺服器服務皆提供資料複寫功能與多區域支援,包括 DynamoDB 與 Amazon S3。Lambda 函數可以作為部署管道的一部分部署在多個區域中,並且可以將 API Gateway 設定為支援此組態。請參閱此範例架構
您可以在分散式架構中建立或使用 AWS 服務實作許多建立良好的常見模式。對於大多數客戶,投資時間從頭開始開發這些模式幾乎沒有商業價值。當您的應用程式需要其中一個模式時,請使用對應的 AWS 服務:
| 模式 | AWS 服務 |
|---|---|
|
佇列 |
Amazon SQS |
|
事件匯流排 |
Amazon EventBridge |
|
發布/訂閱 (扇出) |
Amazon SNS |
|
協調 |
Lambda 耐用函數 AWS Step Functions |
|
API |
Amazon API Gateway |
|
事件串流 |
Amazon Kinesis |
這些服務旨在與 Lambda 整合,您可以使用基礎設施即程式碼 (IaC) 來建立和捨棄服務中的資源。您可以透過 AWS SDK
了解 Lambda 抽象層級
Lambda 服務會限制您對執行 Lambda 函數和基礎作業系統、Hypervisor 和硬體的存取。此服務會持續改善和變更基礎設施,以新增功能、降低成本,並提高服務效能。您的程式碼應假設不了解 Lambda 的架構方式,且假設沒有硬體親和性。
同樣地,Lambda 與其他 服務的整合是由 管理 AWS,只有少量組態選項會公開給您。例如,API Gateway 與 Lambda 互動時無需考慮負載平衡,因為這項功能已完全由服務本身管理。您也無法直接控制服務在任何時間點調用函式時所使用的可用區域
此抽象概念可協助您專注於應用程式的整合層面、資料流程,以及工作負載為最終使用者提供價值的商業邏輯。允許服務管理基礎機制可協助您更快速地開發應用程式,同時減少要維護的自訂程式碼。
在函式中實作無狀態
對於標準 Lambda 函數,您應該假設環境僅存在於單一調用中。函式應在首次啟動時初始化任何必要的狀態。例如,函式可能需要從 DynamoDB 資料表擷取資料。在結束前,函式應將所有永久性資料變更提交至 Amazon S3、DynamoDB 或 Amazon SQS 等耐久存放區。其不應依賴任何現有的資料結構或暫存檔案,或任何需要多次調用才能管理的內部狀態。
若要初始化資料庫連線與程式庫,或是載入狀態資訊,您可以使用靜態初始化功能。由於執行環境會盡可能重複使用以改善效能,因此您可以在多次調用中分攤初始化這些資源所花費的時間。但是,您不應在此全域範圍內儲存函數中使用的任何變數或資料。
最小化耦合度
大多數架構應偏好許多、較短的函數,而不是較少、較大的函數。每個函數的用途應該是處理傳遞到函數的事件,而無需了解或預期整個工作流程或交易量。這使得此函數與事件來源無關,且與其他服務的耦合最少。
任何不常變更的全域範圍常數都應作為環境變數實作,以允許在不部署的情況下進行更新。任何機密或敏感資訊都應儲存在 AWS Systems Manager Parameter Store 或 AWS Secrets Manager
針對隨選資料而非批次處理進行建置
許多傳統系統旨在定期執行並處理隨著時間累積的交易批次。例如,銀行應用程式可能每小時執行一次,以處理中央分類帳中的 ATM 交易。在 Lambda 型應用程式中,每個事件都應觸發自訂處理,從而允許服務視需要向上擴展並行,以提供近乎即時的交易處理。
雖然標準 Lambda 函數的執行時間限制為 15 分鐘,但耐用函數最多可執行一年,因此適合長時間執行的處理需求。不過,您仍然應該盡可能偏好事件驅動型處理,而不是批次處理。
雖然您可以透過使用 Amazon EventBridge 中規則的排程表達式,在無伺服器應用程式中執行 cron
例如,使用批次程序觸發 Lambda 函式來擷取新的 Amazon S3 物件清單並非最佳實務。這是因為服務在批次之間接收到的新物件可能多於 15 分鐘 Lambda 函數內可以處理的物件。
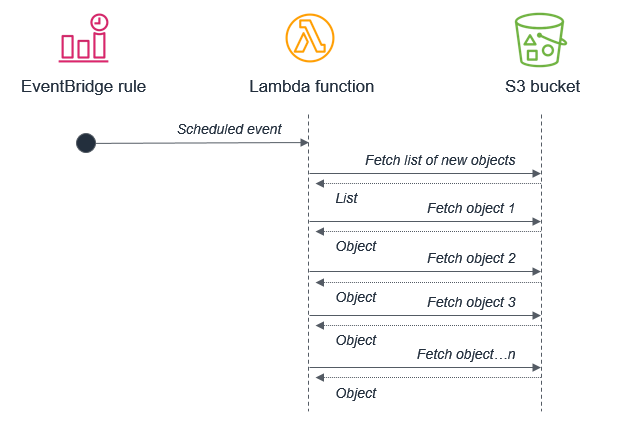
相反,Amazon S3 儲存貯體應在每次有新物件放入其中時都調用 Lambda 函式。此方法的可擴展性顯著提高,並且可以近乎即時地進行處理。
選擇複雜工作流程的協同運作選項
涉及分支邏輯、不同類型故障模型與重試邏輯的工作流程,通常會使用協調器來追蹤整體執行的狀態。請勿在標準 Lambda 函數中建置臨機操作協同運作。這會導致緊密耦合、複雜的路由代碼,而且沒有自動狀態復原。
請改用下列其中一個專用協同運作選項:
-
Lambda 耐久函數:以應用程式為中心的協同運作,使用標準程式設計語言搭配自動檢查點、內建重試和執行復原。非常適合偏好將工作流程邏輯與 Lambda 內的商業邏輯一起保存在程式碼中的開發人員。
-
AWS Step Functions:視覺化工作流程協同運作與 220 多種 AWS 服務的原生整合。非常適合用於多服務協調、零維護基礎設施和視覺化工作流程設計。
如需在這些選項之間進行選擇的指引,請參閱耐用函數或 Step Functions。
透過 Step Functions
Lambda 函式中的簡易工作流程,往往會隨著時間推移逐漸變得更加複雜。操作生產無伺服器應用程式時,請務必識別何時發生這種情況,以便將此邏輯遷移至狀態機器或耐用函數。
實作冪等性
AWS 包括 Lambda 在內的無伺服器服務具有容錯能力,旨在處理故障。例如,若某項服務調用 Lambda 函式時發生服務中斷,Lambda 會自動在另一個可用區域中調用您的函式。如果您的函式擲回錯誤,Lambda 會重試此調用請求。
由於同一事件可能會被多次接收,因此函數應設計為等冪
您可在 Lambda 函式中實作冪等性:透過 DynamoDB 資料表追蹤近期處理過的識別碼,藉此判斷該交易先前是否已處理完畢。DynamoDB 資料表通常實作存留時間 (TTL) 值來使項目過期,以限制所使用的儲存空間。
使用多個 AWS 帳戶來管理配額
中的許多服務配額 AWS 是在帳戶層級設定。這表示隨著您新增更多工作負載,可能會快速用盡配額上限。
解決此問題的有效方法是使用多個 AWS 帳戶,將每個工作負載分配到自己的 帳戶。這樣可防止與其他工作負載或非生產資源共用配額。
此外,您可以透過 AWS Organizations
一種常見的方法是為每個開發人員提供 AWS 帳戶,然後針對 Beta 部署階段和生產環境使用不同的帳戶:
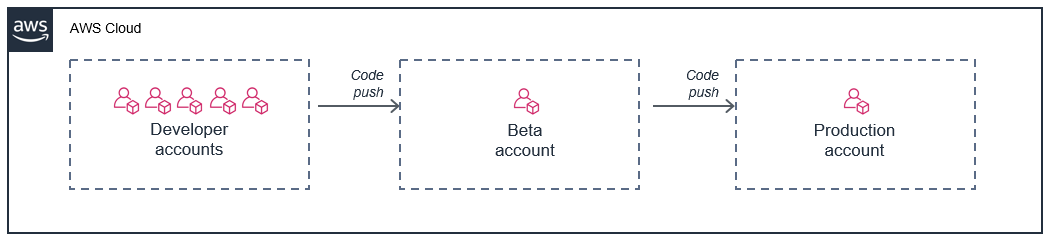
在此模型中,每位開發人員的帳戶都具備獨立的配額限制,因此其資源使用行為不會影響您的生產環境。此做法還能讓開發人員在本機開發環境中測試 Lambda 函式,並直接對接其個人帳戶中的真實雲端資源。
