本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
建立遷移計畫,以從 Apache Cassandra 遷移至 Amazon Keyspaces
若要成功從 Apache Cassandra 遷移至 Amazon Keyspaces,我們建議您檢閱適用的遷移概念和最佳實務,以及比較可用的選項。
本主題概述遷移程序如何運作,方法是介紹幾個關鍵概念,以及您可以使用的工具和技術。您可以評估不同的遷移策略,以選取最符合您需求的遷移策略。
主題
功能相容性
在遷移之前,請仔細考慮 Apache Cassandra 和 Amazon Keyspaces 之間的功能差異。Amazon Keyspaces 支援所有常用的 Cassandra 資料平面操作,例如建立金鑰空間和資料表、讀取資料和寫入資料。
不過,Amazon Keyspaces 不支援一些 Cassandra APIs。如需支援 APIs的詳細資訊,請參閱 支援的 Cassandra APIs、操作、函數和資料類型。如需 Amazon Keyspaces 和 Apache Cassandra 之間所有功能差異的概觀,請參閱 功能差異:Amazon Keyspaces 與 Apache Cassandra。
若要將您正在使用的 Cassandra APIs 和結構描述與 Amazon Keyspaces 中支援的功能進行比較,您可以執行 GitHub
如何使用相容性指令碼
從 GitHub
下載相容性 Python 指令碼,並將其移至可存取現有 Apache Cassandra 叢集的位置。 相容性指令碼使用與 類似的參數
CQLSH。針對--host和--port輸入 IP 地址,以及您用來連接和執行查詢到叢集中其中一個 Cassandra 節點的連接埠。如果您的 Cassandra 叢集使用身分驗證,您也需要提供
-username和-password。若要執行相容性指令碼,您可以使用下列命令。python toolkit-compat-tool.py --hosthostname or IP-u "username" -p "password" --portnative transport port
預估 Amazon Keyspaces 定價
本節提供從 Apache Cassandra 資料表收集所需資訊的概觀,以計算 Amazon Keyspaces 的預估成本。每個資料表都需要不同的資料類型、需要支援不同的 CQL 查詢,並維護獨特的讀取/寫入流量。
根據資料表來考慮您的需求,符合 Amazon Keyspaces 資料表層級的資源隔離和讀取/寫入輸送量容量模式。使用 Amazon Keyspaces,您可以獨立定義資料表的讀取/寫入容量和自動擴展政策。
了解資料表需求可協助您根據功能、成本和遷移工作來排定遷移資料表的優先順序。
在遷移之前收集下列 Cassandra 資料表指標。此資訊有助於估算 Amazon Keyspaces 上的工作負載成本。
資料表名稱 – 完整金鑰空間和資料表名稱的名稱。
描述 – 資料表的描述,例如其使用方式,或其中存放的資料類型。
每秒平均讀取次數 – 在大型時間間隔內,相對於資料表的平均座標層級讀取次數。
每秒平均寫入次數 – 在大型時間間隔內,針對資料表的平均座標層級寫入次數。
以位元組為單位的平均資料列大小 – 以位元組為單位的平均資料列大小。
以 GBs為單位的儲存大小 – 資料表的原始儲存大小。
讀取一致性明細 – 使用最終一致性 (
LOCAL_ONE或ONE) 與強式一致性 () 的讀取百分比LOCAL_QUORUM。
此資料表顯示您在規劃遷移時需要彙整的資料表相關資訊範例。
| 資料表名稱 | Description | 每秒平均讀取數 | 每秒平均寫入數 | 平均資料列大小,以位元組為單位 | 儲存體大小,以 GBs為單位 | 讀取一致性明細 |
|---|---|---|---|---|---|---|
|
mykeyspace.mytable |
用來存放購物車歷史記錄 |
10,000 |
5,000 |
2,200 |
2,000 |
100% |
mykeyspace.mytable2 |
用來存放最新的設定檔資訊 |
20,000 |
1,000 |
850 |
1,000 |
25% |
如何收集資料表指標
本節提供如何從現有 Cassandra 叢集收集必要資料表指標的逐步說明。這些指標包括資料列大小、資料表大小和每秒讀取/寫入請求 (RPS)。它們可讓您評估 Amazon Keyspaces 資料表的輸送量容量需求,並預估定價。
如何在 Cassandra 來源資料表上收集資料表指標
判斷資料列大小
資料列大小對於判斷 Amazon Keyspaces 中的讀取容量和寫入容量使用率非常重要。下圖顯示 Cassandra 字符範圍的典型資料分佈。
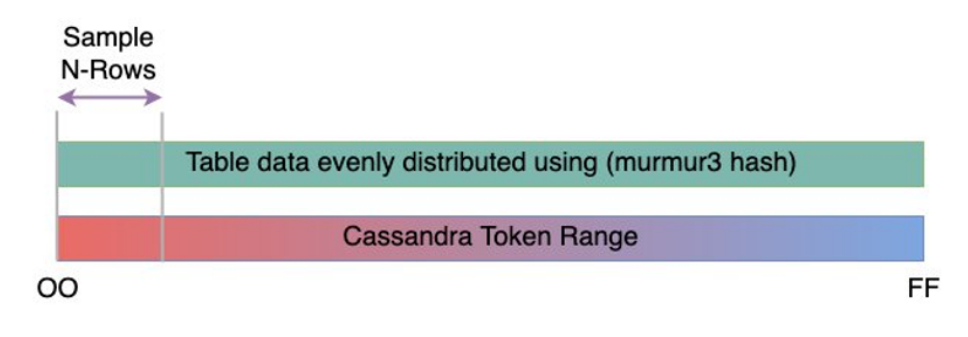
您可以使用 GitHub
上可用的資料列大小採樣器指令碼,收集 Cassandra 叢集中每個資料表的資料列大小指標。 指令碼會使用
cqlsh和 從 Apache Cassandra 匯出資料表資料awk,以計算資料列大小與可設定範例資料集之間的最小、最大、平均和標準差。資料列大小取樣器會將引數傳遞至cqlsh,因此相同的參數可用於連接和讀取 Cassandra 叢集。下列陳述式為範例。
./row-size-sampler.sh10.22.33.449142 \\ -u "username" -p "password" --ssl如需如何在 Amazon Keyspaces 中計算資料列大小的詳細資訊,請參閱 估計 Amazon Keyspaces 中的資料列大小。
判斷資料表大小
使用 Amazon Keyspaces,您不需要預先佈建儲存體。Amazon Keyspaces 會持續監控資料表的計費大小,以判斷您的儲存費用。儲存空間按 GB 每月計費。Amazon Keyspaces 資料表大小是根據單一複本的原始大小 (未壓縮)。
若要監控 Amazon Keyspaces 中的資料表大小,您可以使用指標
BillableTableSizeInBytes,該指標會針對 中的每個資料表顯示 AWS 管理主控台。若要估計 Amazon Keyspaces 資料表的計費大小,您可以使用下列兩種方法之一:
使用平均資料列大小,並乘以數字或資料列。
您可以將平均資料列大小乘以 Cassandra 來源資料表中的資料列數,以估計 Amazon Keyspaces 資料表的大小。使用上一節的資料列大小範例指令碼來擷取平均的資料列大小。若要擷取資料列計數,您可以使用 等工具
dsbulk count來判斷來源資料表中的資料列總數。使用
nodetool收集資料表中繼資料。Nodetool是 Apache Cassandra 分佈中提供的管理工具,可讓您深入了解 Cassandra 程序的狀態,並傳回資料表中繼資料。您可以使用nodetool來取樣資料表大小的中繼資料,並使用 來推斷 Amazon Keyspaces 中的資料表大小。要使用的命令是
nodetool tablestats。Tablestats 會傳回資料表的大小和壓縮比。資料表的大小會儲存為資料表tablelivespace的 ,您可以將其除以compression ratio。然後,將此大小值乘以節點數量。最後除以複寫係數 (通常是三個)。這是計算的完整公式,您可以用來評估資料表大小。
((tablelivespace / compression ratio) * (total number of nodes))/ (replication factor)假設您的 Cassandra 叢集有 12 個節點。執行
nodetool tablestats命令會傳回 200 GBtablelivespace的 和 0.5compression ratio的 。金鑰空間的複寫係數為 3。這是此範例的計算方式。
(200 GB / 0.5) * (12 nodes)/ (replication factor of 3) = 4,800 GB / 3 = 1,600 GB is the table size estimate for Amazon Keyspaces
擷取讀取和寫入次數
若要判斷 Amazon Keyspaces 資料表的容量和擴展需求,請在遷移之前擷取 Cassandra 資料表的讀取和寫入請求率。
Amazon Keyspaces 是無伺服器,您只需支付使用量的費用。一般而言,Amazon Keyspaces 中的讀取/寫入輸送量價格取決於請求的數量和大小。
Amazon Keyspaces 有兩種容量模式:
隨需 – 這是一個靈活的計費選項,能夠每秒處理數千個請求,而無需進行容量規劃。它為讀取和寫入請求提供pay-per-request定價,因此您只需為使用量付費。
佈建 – 如果您選擇佈建的輸送量容量模式,您可以指定應用程式所需的每秒讀取和寫入次數。這可協助您管理 Amazon Keyspaces 用量,以維持或低於定義的請求率,以維持可預測性。
佈建模式提供自動擴展功能,可自動調整佈建速率以擴展或縮減規模,以提升營運效率。如需無伺服器資源管理的詳細資訊,請參閱 在 Amazon Keyspaces 中管理無伺服器資源 (適用於 Apache Cassandra)。
由於您在 Amazon Keyspaces 中分別佈建讀取和寫入輸送量容量,因此您需要獨立測量現有資料表中讀取和寫入的請求率。
若要從現有的 Cassandra 叢集收集最準確的使用率指標,請針對在單一資料中心所有節點上彙總的資料表,擷取長時間內協調器層級讀取和寫入操作的平均每秒請求數 (RPS)。
擷取至少數週內的平均 RPS 會擷取流量模式中的尖峰和山谷,如下圖所示。
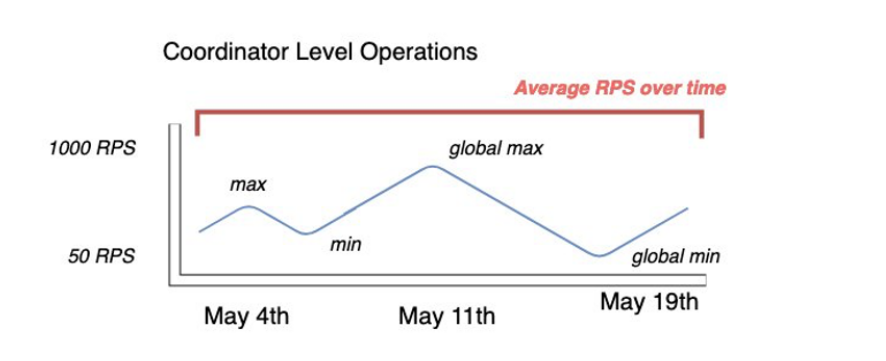
您有兩個選項可判斷 Cassandra 資料表的讀取和寫入請求率。
使用現有的 Cassandra 監控
您可以使用下表所示的指標來觀察讀取和寫入請求。請注意,指標名稱可能會根據您使用的監控工具而變更。
維度 Cassandra JMX 指標 寫入
org.apache.cassandra.metrics:type=ClientRequest, scope=Write,name=Latency#Count讀取
org.apache.cassandra.metrics:type=ClientRequest, scope=Read,name=Latency#Count使用
nodetool使用
nodetool infonodetool tablestats和 從資料表擷取平均讀取和寫入操作。 會tablestats傳回節點啟動後的總讀取和寫入計數。 會以秒為單位nodetool info提供節點的執行時間。若要接收讀取和寫入的每秒平均值,請將讀取和寫入計數除以節點正常執行時間,以秒為單位。然後,對於讀取,您將除以一致性層級廣告,對於寫入,您將除以複寫係數。這些計算會以下列公式表示。
每秒平均讀取的公式:
((number of reads * number of nodes in cluster) / read consistency quorum (2)) / uptime每秒平均寫入的公式:
((number of writes * number of nodes in cluster) / replication factor of 3) / uptime假設我們有 12 個節點叢集已運作 4 週。 會
nodetool info傳回 2,419,200 秒的正常運作時間,並nodetool tablestats傳回 10 億筆寫入和 20 億筆讀取。此範例將導致以下計算。((2 billion reads * 12 in cluster) / read consistency quorum (2)) / 2,419,200 seconds = 12 billion reads / 2,419,200 seconds = 4,960 read request per second ((1 billion writes * 12 in cluster) / replication factor of 3) / 2,419,200 seconds = 4 billion writes / 2,419,200 seconds = 1,653 write request per second
判斷資料表的容量使用率
若要估計平均容量使用率,請從平均請求率和 Cassandra 來源資料表的平均資料列大小開始。
Amazon Keyspaces 使用讀取容量單位 RCUs) 和寫入容量單位 WCUs) 來測量資料表讀取和寫入的佈建輸送量容量。在此預估中,我們會使用這些單位來計算遷移後新 Amazon Keyspaces 資料表的讀取和寫入容量需求。
本主題稍後將討論佈建容量模式和隨需容量模式之間的選擇如何影響帳單。但是,在此範例中,為了估計容量使用率,我們假設資料表處於佈建模式。
讀取 – 一個 RCU 代表一個
LOCAL_QUORUM讀取請求,或兩個LOCAL_ONE讀取請求,適用於大小上限為 4 KB 的資料列。如果您需要讀取大於 4 KB 的資料列,則讀取操作會使用其他 RCUs。所需的 RCUs 總數取決於資料列大小,以及您是否要使用或LOCAL_QUORUMLOCAL_ONE讀取一致性。例如,讀取 8 KB 的資料列需要 2 個使用
LOCAL_QUORUM讀取一致性RCUs,如果您選擇LOCAL_ONE讀取一致性,則需要 1 個 RCU。寫入 – 一個 WCU 代表大小上限為 1 KB 的資料列一個寫入。所有寫入都使用
LOCAL_QUORUM一致性,而且使用輕量型交易 (LWTs) 無需額外付費。所需的 WCUs 總數取決於資料列大小。如果您需要寫入大於 1 KB 的資料列,則寫入操作會使用其他 WCUs。例如,如果您的資料列大小為 2 KB,則需要 2 WCUs 來執行一個寫入請求。
下列公式可用來預估所需的 RCUs 和 WCUs。
RCUs中的讀取容量可以透過每秒讀取數乘以每個讀取的資料列數乘以平均資料列大小除以 4KB,四捨五入到最接近的整數來決定。
WCUs中的寫入容量可以透過將請求數量乘以平均資料列大小除以 1KB 並四捨五入至最接近的整數來決定。
這在下列公式中表示。
Read requests per second * ROUNDUP((Average Row Size)/4096 per unit) = RCUs per second Write requests per second * ROUNDUP(Average Row Size/1024 per unit) = WCUs per second例如,如果您在 Cassandra 資料表上執行的資料列大小為 2.5KB 的 4,960 個讀取請求,則需要 Amazon Keyspaces 中的 4,960 RCUs。如果您目前在 Cassandra 資料表上執行每秒 1,653 個寫入請求,且資料列大小為 2.5KB,則 Amazon Keyspaces 中需要每秒 4,959 個 WCUs。
此範例以下列公式表示。
4,960 read requests per second * ROUNDUP( 2.5KB /4KB bytes per unit) = 4,960 read requests per second * 1 RCU = 4,960 RCUs 1,653 write requests per second * ROUNDUP(2.5KB/1KB per unit) = 1,653 requests per second * 3 WCUs = 4,959 WCUs使用
eventual consistency可讓您在每個讀取請求上儲存高達輸送量容量的一半。每個最終一致讀取最多可耗用 8KB。您可以計算最終一致讀取,方法是將先前的計算乘以 0.5,如下列公式所示。4,960 read requests per second * ROUNDUP( 2.5KB /4KB per unit) * .5 = 2,480 read request per second * 1 RCU = 2,480 RCUs-
計算 Amazon Keyspaces 的每月定價預估
若要根據讀取/寫入容量輸送量預估資料表的每月帳單,您可以使用不同的公式計算隨需和佈建模式的定價,並比較資料表的選項。
佈建模式 – 讀取和寫入容量消耗會根據每秒容量單位的每小時費率計費。首先,將該速率除以 0.7,表示預設自動擴展目標使用率為 70%。然後乘以 30 個日曆天、每天 24 小時,以及區域費率定價。
此計算摘要於下列公式中。
(read capacity per second / .7) * 24 hours * 30 days * regional rate (write capacity per second / .7) * 24 hours * 30 days * regional rate隨需模式 – 讀取和寫入容量是以每個請求速率計費。首先,將請求率乘以 30 個日曆天和每天 24 小時。然後除以一百萬個請求單位。最後,將 乘以區域費率。
此計算摘要於下列公式中。
((read capacity per second * 30 * 24 * 60 * 60) / 1 Million read request units) * regional rate ((write capacity per second * 30 * 24 * 60 * 60) / 1 Million write request units) * regional rate
選擇遷移策略
從 Apache Cassandra 遷移至 Amazon Keyspaces 時,您可以選擇下列遷移策略:
線上 – 這是使用雙寫入開始同時將新資料寫入 Amazon Keyspaces 和 Cassandra 叢集的即時遷移。對於在遷移期間需要零停機時間並在寫入一致性後讀取的應用程式,建議使用此遷移類型。
如需如何規劃和實作線上遷移策略的詳細資訊,請參閱 線上遷移至 Amazon Keyspaces:策略和最佳實務。
離線 – 此遷移技術涉及在停機時間期間將資料集從 Cassandra 複製到 Amazon Keyspaces。離線遷移可以簡化遷移程序,因為它不需要變更您的應用程式,或在歷史資料和新寫入之間解決衝突。
如需如何規劃離線遷移的詳細資訊,請參閱 離線遷移程序:Apache Cassandra 到 Amazon Keyspaces。
混合 – 此遷移技術允許近乎即時地將變更複寫至 Amazon Keyspaces,但不會在寫入一致性後讀取。
如需如何規劃混合遷移的詳細資訊,請參閱 使用混合遷移解決方案:Apache Cassandra 到 Amazon Keyspaces。
檢閱本主題中討論的遷移技術和最佳實務後,您可以在決策樹中放置可用的選項,以根據您的需求和可用的資源設計遷移策略。
