本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Glue 中 Apache Spark AWS 的生成式 AI 升級
Glue AWS 中的 Spark 升級可讓資料工程師和開發人員使用生成式 AI,將現有的 AWS Glue Spark 任務升級和遷移到最新的 Spark 版本。資料工程師可以使用它來掃描其 AWS Glue Spark 任務、產生升級計畫、執行計畫,以及驗證輸出。其透過自動化識別和更新 Spark 指令碼、組態、相依性、方法和功能等無差別的工作,來減少 Spark 升級的時間和成本。
運作方式
當您使用升級分析時, AWS Glue 會識別任務程式碼中版本和組態之間的差異,以產生升級計畫。升級計劃會詳細說明所有程式碼變更,以及必要的移轉步驟。接著, AWS Glue 會在 環境中建置並執行升級的應用程式,以驗證變更,並產生程式碼變更清單,供您遷移任務。可以檢視更新後的指令碼,以及詳細說明提議變更的摘要。執行您自己的測試後,請接受變更,Glue AWS 任務會使用新指令碼自動更新至最新版本。
升級分析程序可能需要一些時間才能完成,具體取決於任務的複雜性和工作負載。升級分析的結果將儲存在指定的 Amazon S3 路徑中,您可以檢閱這些路徑以了解升級和任何潛在的相容性問題。在檢閱升級分析結果之後,您可以決定是否要繼續實際升級,或在升級之前對任務進行任何必要的變更。
先決條件
使用生成式 AI 升級 Glue AWS 中的任務需要下列先決條件:
-
AWS Glue 2 PySpark 任務 – 只有 AWS Glue 2 任務可以升級至 AWS Glue 5。
-
需要 IAM 許可才能開始分析、檢閱結果並升級您的任務。如需詳細資訊,請參閱以下 許可 部分中的範例。
-
如果使用 AWS KMS 加密分析成品,則需要額外的 AWS AWS KMS 許可。如需詳細資訊,請參閱以下 AWS KMS 政策 部分中的範例。
許可
-
使用以下許可來更新呼叫者的 IAM 政策:
-
更新您要升級之任務的執行角色,以包含下列內嵌政策:
{ "Effect": "Allow", "Action": ["s3:GetObject"], "Resource": [ "ARN of the Amazon S3 path provided on API", "ARN of the Amazon S3 path provided on API/*" ] }例如,如果您使用的是 Amazon S3 路徑
s3://amzn-s3-demo-bucket/upgraded-result,則政策將為:{ "Effect": "Allow", "Action": ["s3:GetObject"], "Resource": [ "arn:aws:s3:::amzn-s3-demo-bucket/upgraded-result/", "arn:aws:s3:::amzn-s3-demo-bucket/upgraded-result/*" ] }
AWS KMS 政策
若要在開始分析時傳遞您自己的自訂 AWS KMS 金鑰,請參閱下一節以設定 AWS KMS 金鑰的適當許可。
此政策可確保您在 AWS KMS 金鑰上同時擁有加密和解密許可。
{ "Effect": "Allow", "Principal":{ "AWS": "<IAM Customer caller ARN>" }, "Action": [ "kms:Decrypt", "kms:GenerateDataKey", ], "Resource": "<key-arn-passed-on-start-api>" }
執行升級分析並套用升級指令碼
可以執行升級分析,這會對您從任務檢視中選取的任務產生升級計劃。
-
從任務中選取 AWS Glue 2.0 任務,然後從動作功能表中選擇執行升級分析。
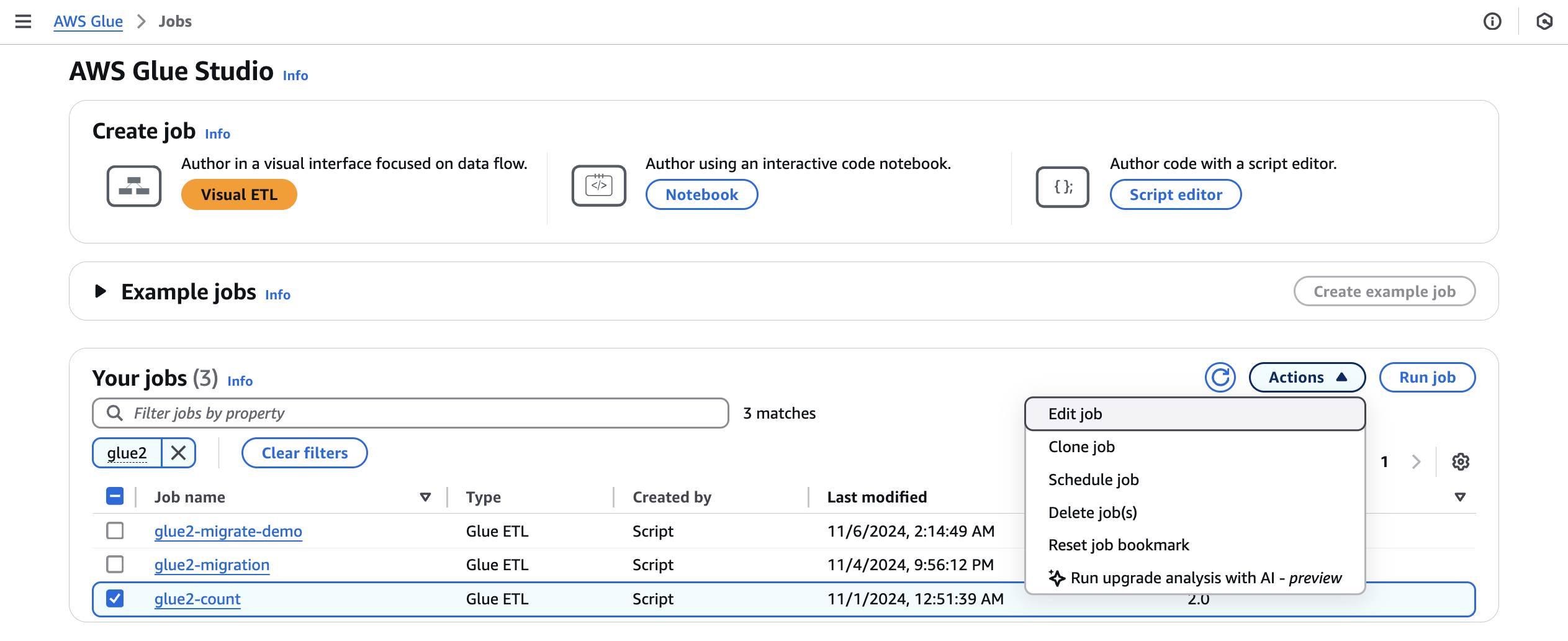
-
在該模型中,選取路徑,將產生的升級計畫存放在結果路徑中。這必須是您可以存取和寫入的 Amazon S3 儲存貯體。
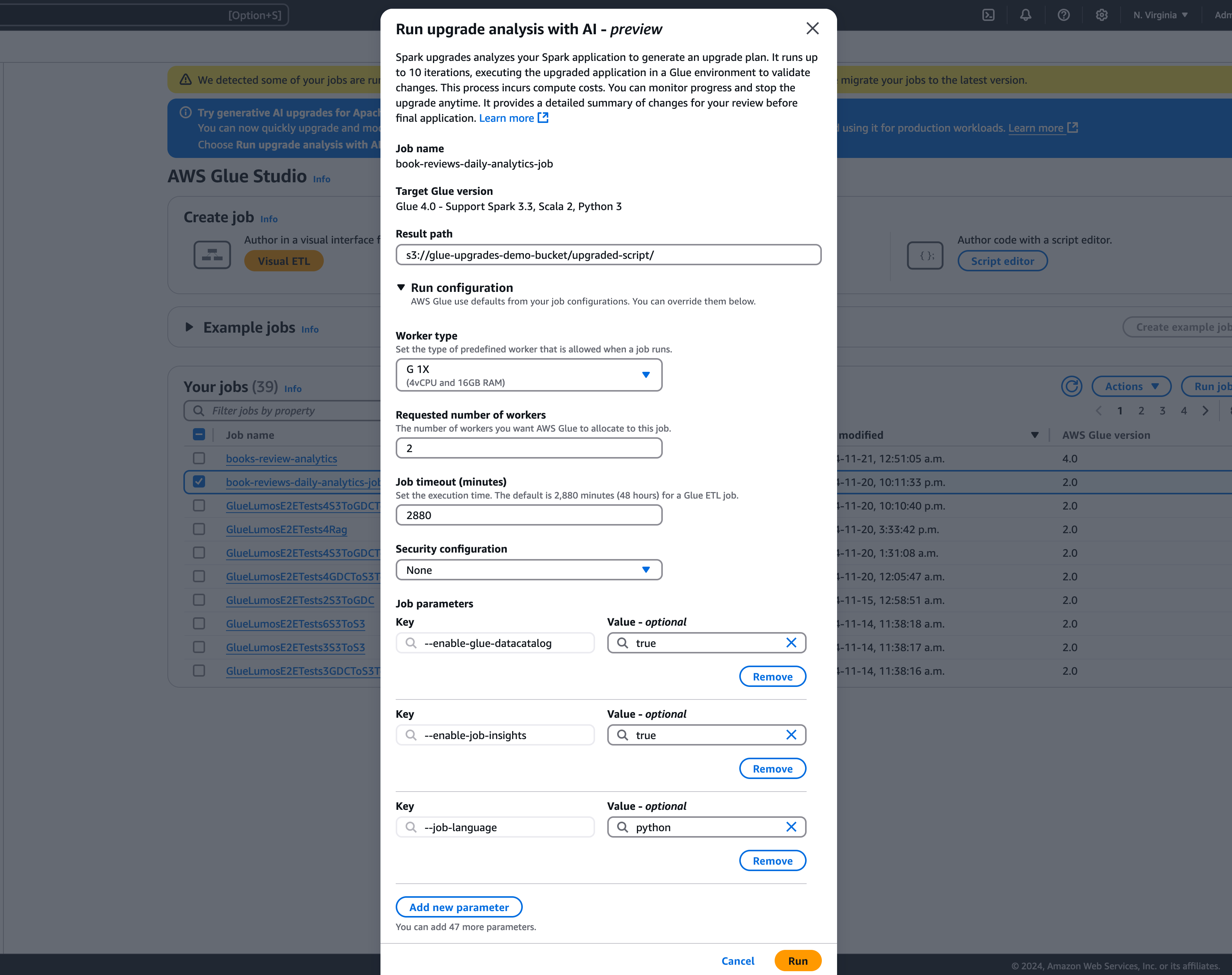
-
視需要設定下列其他選項:
-
執行組態 – 選用:執行組態是選用設定,可讓您自訂升級分析期間執行之驗證執行的各個層面。此組態用於執行已升級的指令碼,並可讓您選取運算環境屬性 (工作者類型、工作者數目等)。請注意,在檢閱、接受變更並將其套用至生產環境之前,應該使用非生產開發人員帳戶對範例資料集執行驗證。執行組態包含下列可自訂參數:
-
工作者類型:可以指定要用於驗證執行的工作者類型,讓您可以根據您的需求選擇適當的運算資源。
-
工作者數目:可以定義要為驗證執行佈建的工作者數目,讓您可以根據工作負載需求擴展資源。
-
任務逾時 (以分鐘為單位):此參數可讓您設定驗證執行的時間限制,確保任務在指定的持續時間後終止,以防止資源消耗過多。
-
安全組態:可以設定安全設定,例如加密和存取控制,以確保在驗證執行期間保護您的資料和資源。
-
其他任務參數:如有需要,可以新增任務參數,以進一步自訂驗證執行的執行環境。
透過利用執行組態,可以量身打造驗證執行以符合您的特定需求。例如,可以設定驗證執行以使用較小的資料集,讓分析更快完成並最佳化成本。此方法可確保有效執行升級分析,同時將驗證階段的資源使用率和相關成本降至最低。
-
-
加密組態 – 選用:
-
啟用升級成品加密:在將資料寫入結果路徑時啟用靜態加密。如果不想加密升級成品,請取消勾選此選項。
-
-
-
選擇執行以開始升級分析。分析執行時,可以在升級分析索引標籤中檢視結果。分析詳細資訊視窗會顯示關於分析的資訊,以及升級成品的連結。
-
結果路徑 – 這是存放結果摘要和升級指令碼的位置。
-
Amazon S3 中的已升級指令碼 – Amazon S3 中升級指令碼的位置。可以在套用升級之前檢視指令碼。
-
Amazon S3 中的升級摘要 – Amazon S3 中升級摘要的位置。可以在套用升級之前檢視升級摘要。
-
-
當升級分析成功完成後,可以選擇套用已升級的指令碼來升級指令碼,以自動升級任務。
套用後,Glue AWS 版本將更新為 4.0。可以在指令碼索引標籤中檢視新指令碼。
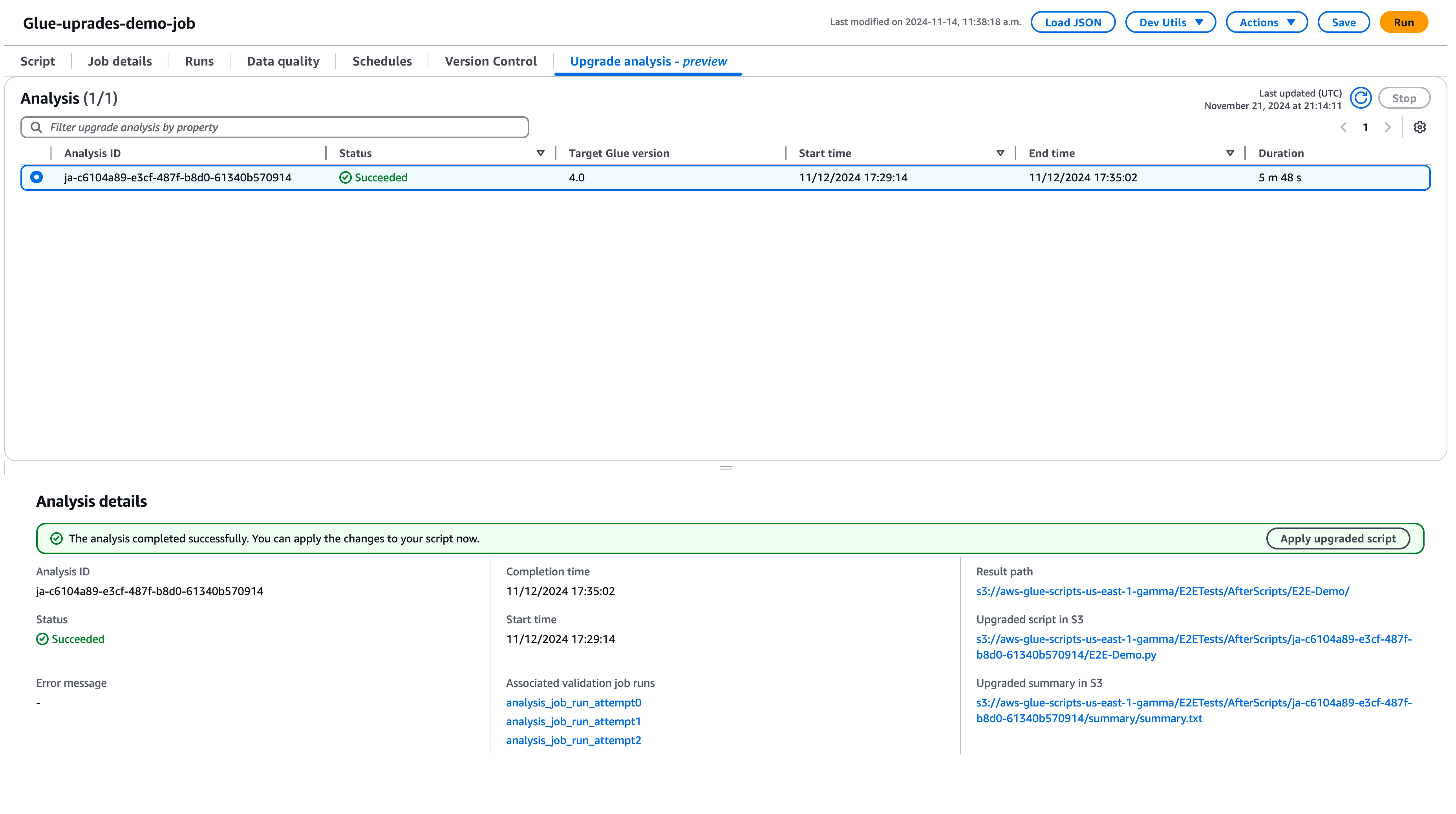
了解升級摘要
此範例示範將 AWS Glue 任務從 2.0 版升級至 4.0 版的程序。範例任務會從 Amazon S3 儲存貯體中讀取產品資料,使用 Spark SQL 將數個轉換套用至資料,然後將轉換的結果儲存回 Amazon S3 儲存貯體。
from awsglue.transforms import * from pyspark.context import SparkContext from awsglue.context import GlueContext from pyspark.sql.types import * from pyspark.sql.functions import * from awsglue.job import Job import json from pyspark.sql.types import StructType sc = SparkContext.getOrCreate() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) gdc_database = "s3://aws-glue-scripts-us-east-1-gamma/demo-database/" schema_location = ( "s3://aws-glue-scripts-us-east-1-gamma/DataFiles/" ) products_schema_string = spark.read.text( f"{schema_location}schemas/products_schema" ).first()[0] product_schema = StructType.fromJson(json.loads(products_schema_string)) products_source_df = ( spark.read.option("header", "true") .schema(product_schema) .option( "path", f"{gdc_database}products/", ) .csv(f"{gdc_database}products/") ) products_source_df.show() products_temp_view_name = "spark_upgrade_demo_product_view" products_source_df.createOrReplaceTempView(products_temp_view_name) query = f"select {products_temp_view_name}.*, format_string('%0$s-%0$s', category, subcategory) as unique_category from {products_temp_view_name}" products_with_combination_df = spark.sql(query) products_with_combination_df.show() products_with_combination_df.createOrReplaceTempView(products_temp_view_name) product_df_attribution = spark.sql( f""" SELECT *, unbase64(split(product_name, ' ')[0]) as product_name_decoded, unbase64(split(unique_category, '-')[1]) as subcategory_decoded FROM {products_temp_view_name} """ ) product_df_attribution.show() product_df_attribution.write.mode("overwrite").option("header", "true").option( "path", f"{gdc_database}spark_upgrade_demo_product_agg/" ).saveAsTable("spark_upgrade_demo_product_agg", external=True) spark_upgrade_demo_product_agg_table_df = spark.sql( f"SHOW TABLE EXTENDED in default like 'spark_upgrade_demo_product_agg'" ) spark_upgrade_demo_product_agg_table_df.show() job.commit()
from awsglue.transforms import * from pyspark.context import SparkContext from awsglue.context import GlueContext from pyspark.sql.types import * from pyspark.sql.functions import * from awsglue.job import Job import json from pyspark.sql.types import StructType sc = SparkContext.getOrCreate() glueContext = GlueContext(sc) spark = glueContext.spark_session # change 1 spark.conf.set("spark.sql.adaptive.enabled", "false") # change 2 spark.conf.set("spark.sql.legacy.pathOptionBehavior.enabled", "true") job = Job(glueContext) gdc_database = "s3://aws-glue-scripts-us-east-1-gamma/demo-database/" schema_location = ( "s3://aws-glue-scripts-us-east-1-gamma/DataFiles/" ) products_schema_string = spark.read.text( f"{schema_location}schemas/products_schema" ).first()[0] product_schema = StructType.fromJson(json.loads(products_schema_string)) products_source_df = ( spark.read.option("header", "true") .schema(product_schema) .option( "path", f"{gdc_database}products/", ) .csv(f"{gdc_database}products/") ) products_source_df.show() products_temp_view_name = "spark_upgrade_demo_product_view" products_source_df.createOrReplaceTempView(products_temp_view_name) # change 3 query = f"select {products_temp_view_name}.*, format_string('%1$s-%1$s', category, subcategory) as unique_category from {products_temp_view_name}" products_with_combination_df = spark.sql(query) products_with_combination_df.show() products_with_combination_df.createOrReplaceTempView(products_temp_view_name) # change 4 product_df_attribution = spark.sql( f""" SELECT *, try_to_binary(split(product_name, ' ')[0], 'base64') as product_name_decoded, try_to_binary(split(unique_category, '-')[1], 'base64') as subcategory_decoded FROM {products_temp_view_name} """ ) product_df_attribution.show() product_df_attribution.write.mode("overwrite").option("header", "true").option( "path", f"{gdc_database}spark_upgrade_demo_product_agg/" ).saveAsTable("spark_upgrade_demo_product_agg", external=True) spark_upgrade_demo_product_agg_table_df = spark.sql( f"SHOW TABLE EXTENDED in default like 'spark_upgrade_demo_product_agg'" ) spark_upgrade_demo_product_agg_table_df.show() job.commit()

根據摘要,Glue AWS 提議了四種變更,以便成功將指令碼從 AWS Glue 2.0 升級到 AWS Glue 4.0:
-
Spark SQL 組態 (spark.sql.adaptive.enabled):此變更可還原應用程式行為,因為從 Spark 3.2 開始,針對 Spark SQL 適應性查詢執行推出了新功能。可以檢查此組態變更,並根據其偏好設定進一步啟用或停用其。
-
DataFrame API 變更:該路徑選項不能與其他 DataFrameReader 操作共存,例如
load()。若要保留先前的行為, AWS Glue 已更新指令碼以新增新的 SQL 組態 (spark.sql.legacy.pathOptionBehavior.enabled)。 -
Spark SQL API 變更:已更新
format_string(strfmt, obj, ...)中的strfmt行為,不允許0$作為第一個引數。為了確保相容性, AWS Glue 已改為將指令碼修改為使用1$做為第一個引數。 -
Spark SQL API 變更:
unbase64函數不允許格式不正確的字串輸入。為了保留先前的行為, AWS Glue 已更新指令碼以使用try_to_binary函數。
停止進行中的升級分析
可以取消進行中的升級分析,或直接停止分析。
-
選擇升級分析索引標籤。
-
選取正在執行的任務,然後選擇停止。這將停止分析。然後,可以對相同的任務執行另一個升級分析。

考量事項
當您開始使用 Spark 升級時,需要考慮幾個重要層面,才能以最佳方式使用服務。
-
服務範圍和限制:目前版本著重於將 PySpark 程式碼從 AWS Glue 2.0 版升級至 5.0 版。目前,服務會處理不依賴其他程式庫相依性的 PySpark 程式碼。您可以在 AWS 帳戶中同時執行最多 10 個任務的自動升級,讓您有效率地升級多個任務,同時維持系統穩定性。
-
僅支援 PySpark 任務。
-
升級分析會在 24 小時後逾時。
-
一個任務一次只能執行一個作用中的升級分析。在帳戶層級,最多可以同時執行 10 個作用中的升級分析。
-
-
在升級程序期間最佳化成本:由於 Spark 升級使用生成式 AI 透過多次反覆運算來驗證升級計畫,因此在帳戶中以 AWS Glue 任務身分執行每個反覆運算時,為了提高成本效益,最佳化驗證任務執行組態至關重要。若要達成此目的,建議您在開始升級分析時指定執行組態,如下所示:
-
使用非生產開發人員帳戶,然後選取代表生產資料但大小較小的模擬資料集範例,以便使用 Spark 升級進行驗證。
-
使用適當大小的運算資源,例如 G.1X 工作者,並選取適當數目的工作者來處理範例資料。
-
適用時啟用 AWS Glue 任務自動調整規模,以根據工作負載自動調整資源。
例如,如果您的生產任務使用 20 個 G.2X 工作者處理 TB 級資料,則可以將升級任務設定為使用 2 個 G.2X 工作者來處理 GB 級代表性資料,並啟用自動擴展以進行驗證。
-
-
最佳實務:強烈建議您使用非生產任務開始升級旅程。此方法可讓您熟悉升級工作流程,並了解服務如何處理不同類型的 Spark 程式碼模式。
-
警示和通知:針對任務使用生成式 AI 升級功能時,請確保已關閉失敗任務執行的警示/通知。在升級過程中,在提供升級成品之前,您的帳戶中最多可能會有 10 個失敗的任務執行。
-
異常偵測規則:關閉正在升級的任務中的任何異常偵測規則,因為在升級驗證進行期間,在中繼任務執行期間寫入到輸出資料夾的資料可能不是預期的格式。
-
將升級分析與冪等任務搭配使用:將升級分析與冪等任務搭配使用,以確保每次後續驗證任務執行嘗試都與前一個任務相似,並且不會遇到問題。冪等任務是可以使用相同輸入資料多次執行的任務,而且每次都會產生相同的輸出。在 Glue 中使用 Apache Spark AWS 的生成式 AI 升級時,服務會在驗證程序中執行任務的多個反覆運算。在每次反覆運算期間,其會變更您的 Spark 程式碼和組態,以驗證升級計畫。如果 Spark 任務不具冪等性,則使用相同的輸入資料多次執行其可能會導致問題。
支援的 區域
Apache Spark 的生成式 AI 升級可在下列區域使用:
-
亞太區域:東京 (ap-northeast-1)、首爾 (ap-northeast-2)、孟買 (ap-south-1)、新加坡 (ap-southeast-1) 和雪梨 (ap-southeast-2)
-
北美洲:加拿大 (ca-central-1)
-
歐洲:法蘭克福 (eu-central-1)、斯德哥爾摩 (eu-north-1)、愛爾蘭 (eu-west-1)、倫敦 (eu-west-2) 和巴黎 (eu-west-3)
-
南美洲:聖保羅 (sa-east-1)
-
美國:北維吉尼亞 (us-east-1)、俄亥俄 (us-east-2) 和奧勒岡 (us-west-2)
Spark 升級中的跨區域推論
Spark 升級採用 技術 Amazon Bedrock ,並利用跨區域推論 (CRIS)。透過 CRIS,Spark 升級會自動選擇您所在地理位置內的最佳區域 (請參閱此處的詳細說明) 來處理您的推論請求,最大限度地利用可用的運算資源和模型可用性,以提供最佳的客戶體驗。使用跨區域推論無需額外付費。
跨區域推論請求會保留在原始資料所在地理位置的 AWS 區域中。例如,在美國提出的請求會保留在美國的 AWS 區域內。雖然資料只會存放在主要區域中,但在使用跨區域推論時,您的輸入提示和輸出結果可能會移動到主要區域之外。所有資料都會透過 Amazon 的安全網路進行加密傳輸。
