本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Glue 中 Apache Spark 的生成式 AI AWS 疑難排解
Glue 中 Apache Spark AWS 任務的生成式 AI 疑難排解是一項新功能,可協助資料工程師和科學家輕鬆診斷和修正 Spark 應用程式的問題。此功能利用機器學習和生成式 AI 技術,可分析 Spark 任務中的問題,並提供詳細的根本原因分析以及可行的建議來解決這些問題。Apache Spark 的生成式 AI 疑難排解適用於在 Glue AWS 4.0 版及更高版本上執行的任務。
|
使用採用 AI 技術的故障診斷代理程式轉換您的 Apache Spark 故障診斷,現在支援所有主要部署模式,包括 AWS Glue、Amazon EMR-EC2、Amazon EMR-Serverless 和 Amazon SageMaker AI 筆記本。此強大的代理程式透過將自然語言互動、即時工作負載分析和智慧程式碼建議結合到無縫體驗中,來消除複雜的偵錯程序。如需實作詳細資訊,請參閱什麼是 Amazon EMR 的 Apache Spark 故障診斷代理程式。檢視使用 Glue 疑難排解代理程式疑難排解範例中的第二個示範。 AWS |
適用於 Apache Spark 的生成式 AI 疑難排解如何工作?
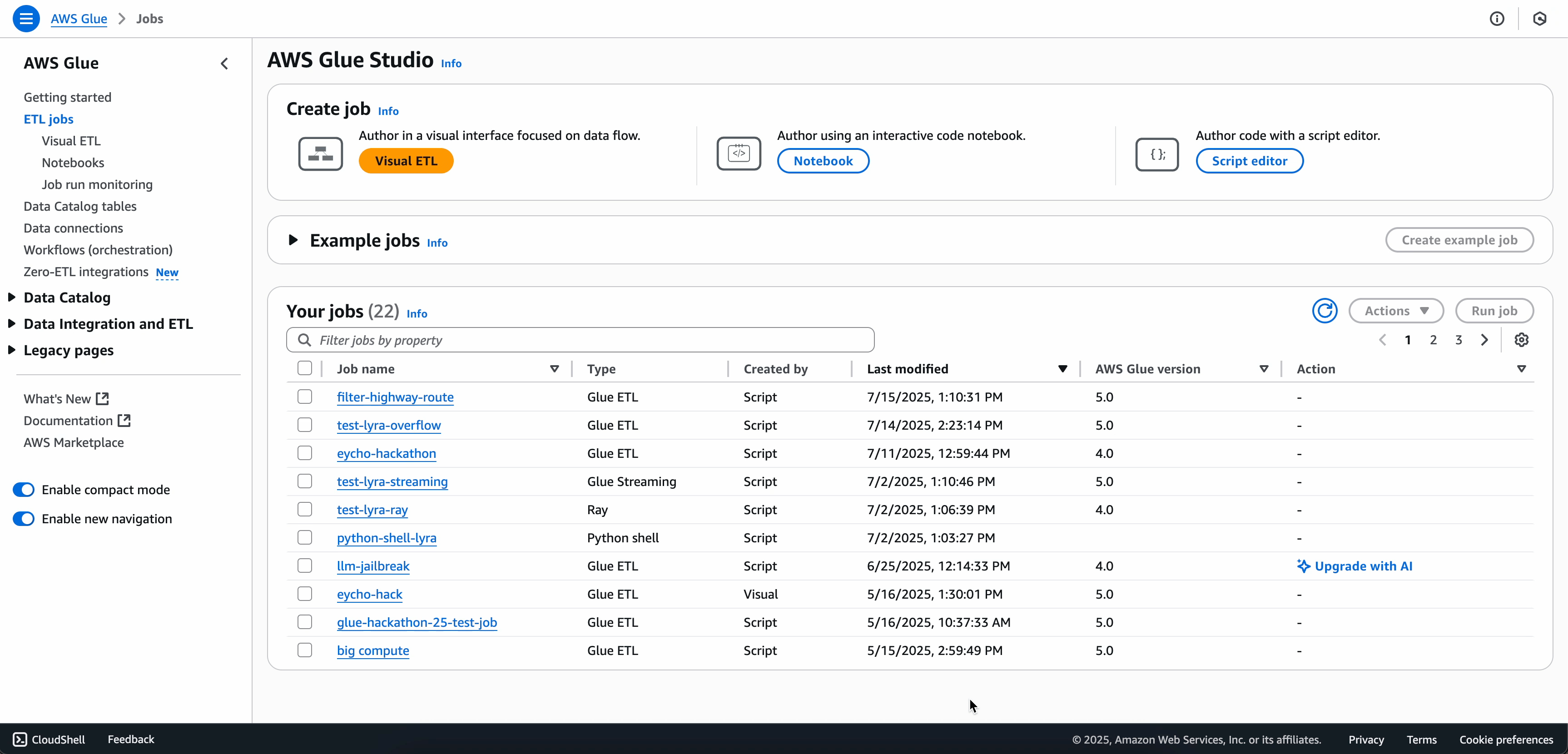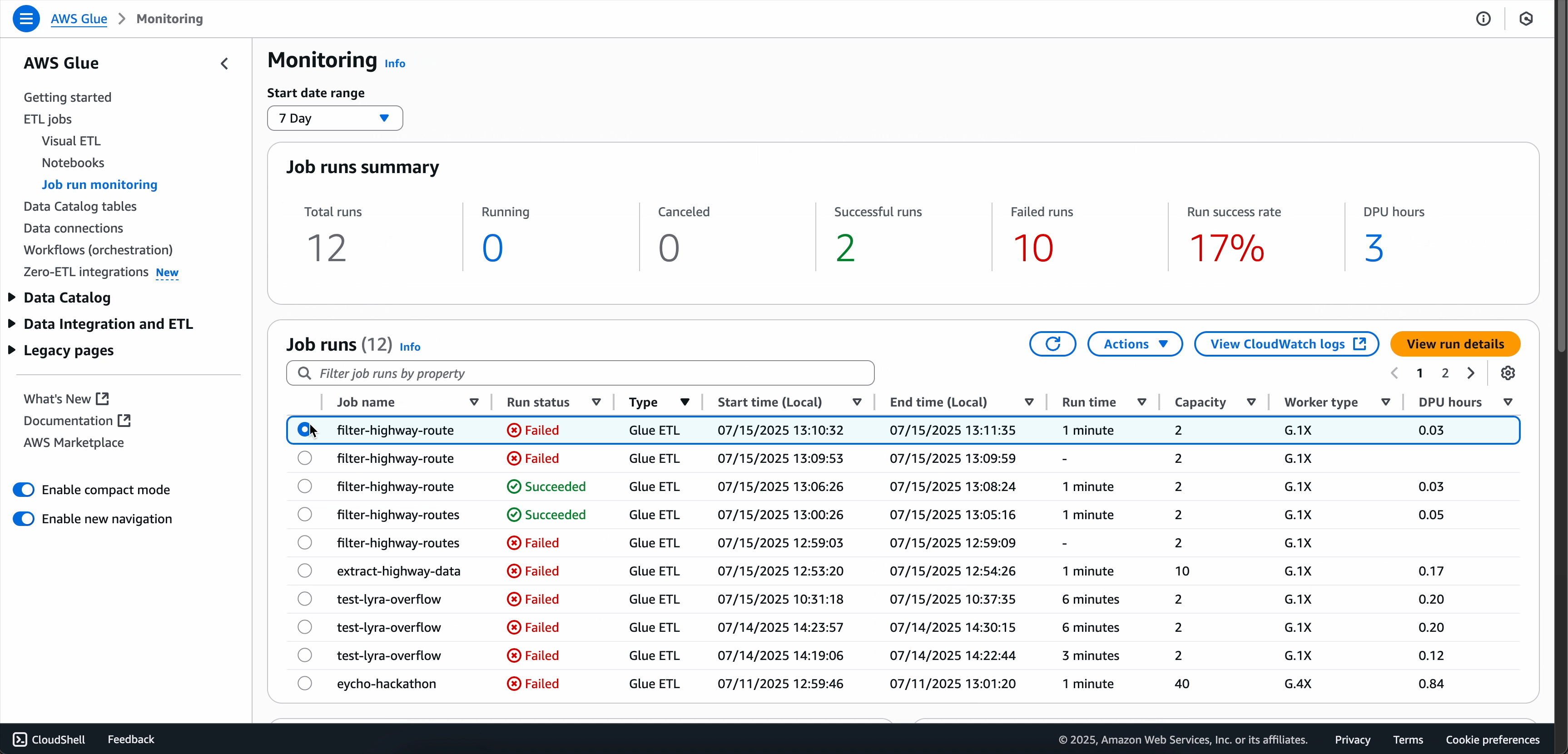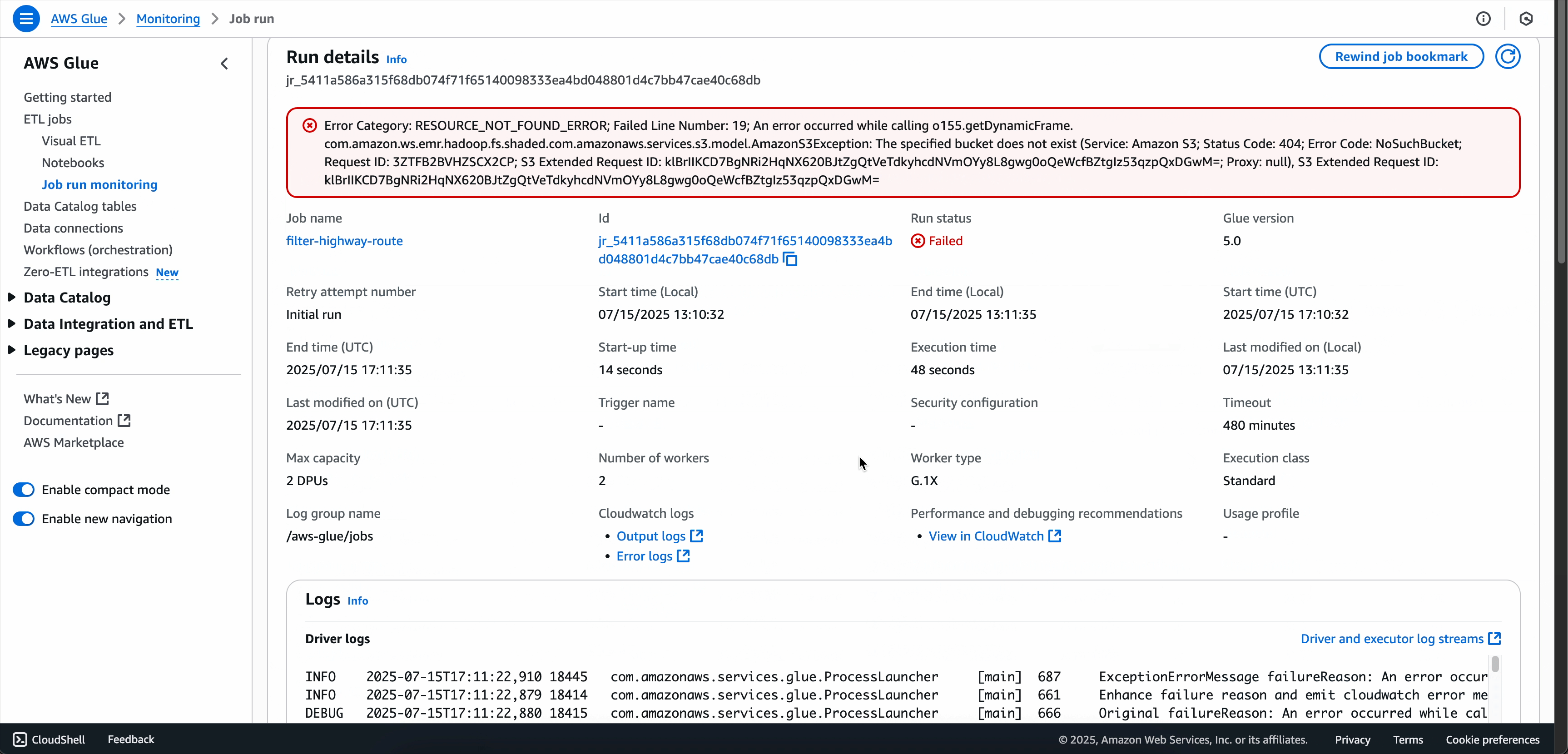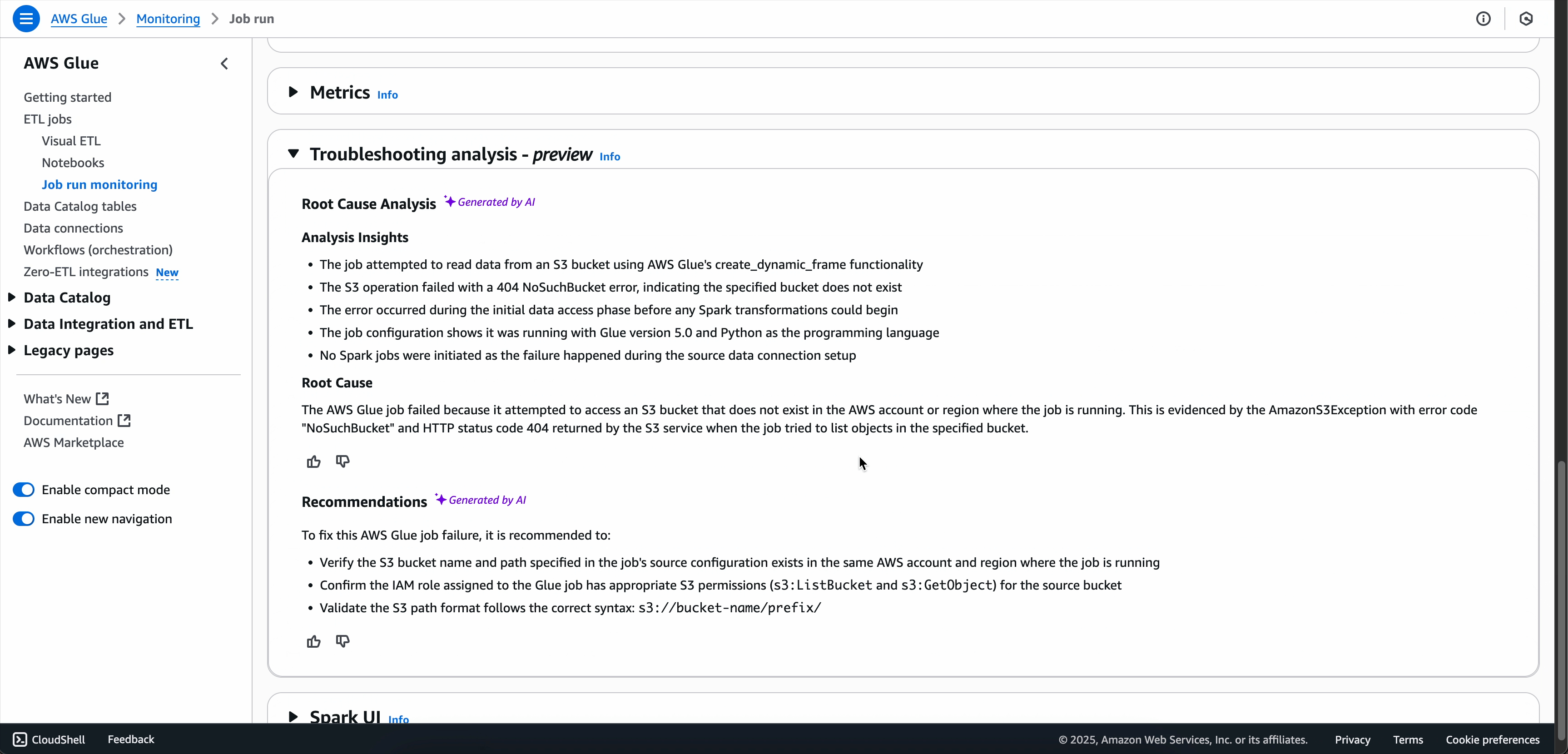
對於失敗的 Spark 任務,生成式 AI 疑難排解會分析任務中繼資料,以及與任務錯誤簽章相關聯的精確指標和日誌,以產生根本原因分析,並建議特定解決方案和最佳實務,以協助解決任務失敗。
針對您的任務設定適用於 Apache Spark 的生成式 AI 疑難排解
設定 IAM 許可權限
授予許可給 Glue 中任務的 Spark 故障診斷所使用的 APIs AWS ,需要適當的 IAM 許可。您可以將下列自訂 AWS 政策連接至 IAM 身分 (例如使用者、角色或群組) 來取得許可。
注意
IAM 政策中使用下列兩個 APIs,透過 Glue Studio AWS 主控台啟用此體驗: StartCompletion和 GetCompletion。
指派權限
若要提供存取權,請新增權限至您的使用者、群組或角色:
-
對於 IAM Identity Center 中的使用者和群組:建立許可集。請按照《IAM Identity Center 使用者指南》中建立許可集的說明進行操作。
-
對於在 IAM 中透過身分提供者管理的使用者:建立聯合身分的角色。請按照《IAM 使用者指南》的為第三方身分提供者 (聯合) 建立角色中的指示進行操作。
-
對於 IAM 使用者:建立您的使用者可擔任的角色。請按照《IAM 使用者指南》的為 IAM 使用者建立角色中的指示進行操作。
從失敗的任務執行中執行疑難排解分析
您可以透過 Glue AWS 主控台中的多個路徑存取故障診斷功能。以下是如何開始:
選項 1:從「任務清單」頁面中
-
在 AWS https://console.aws.amazon.com/glue/
:// 開啟 Glue 主控台。 -
在導覽窗格中,選擇 ETL 任務。
-
在任務清單中找到失敗的任務。
-
在任務詳細資訊區段中選取執行索引標籤。
-
按一下您要分析的失敗任務執行。
-
選擇使用 AI 進行疑難排解以開始分析。
-
疑難排解分析完成後,可以在畫面底部的疑難排解分析索引標籤中檢視根本原因分析和建議。
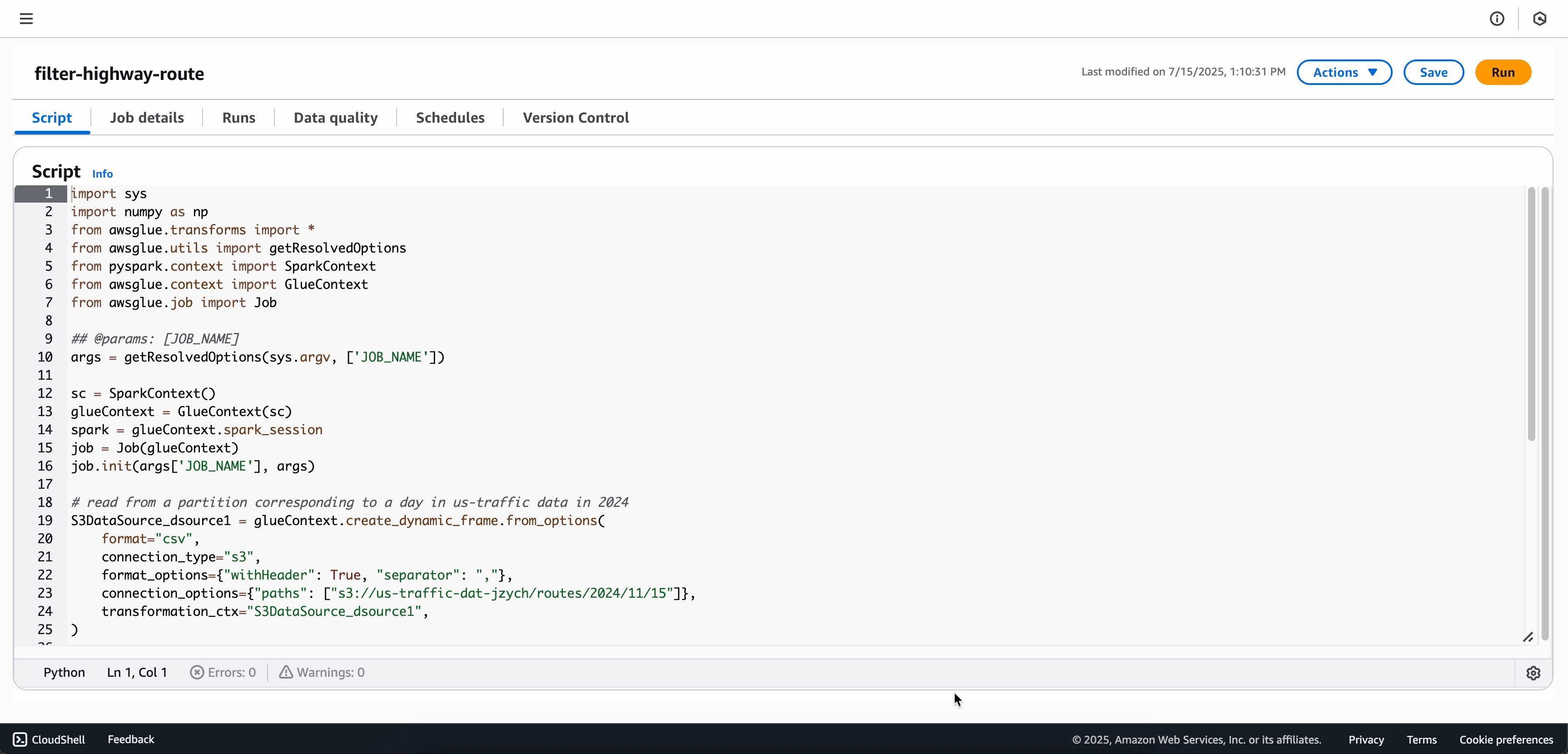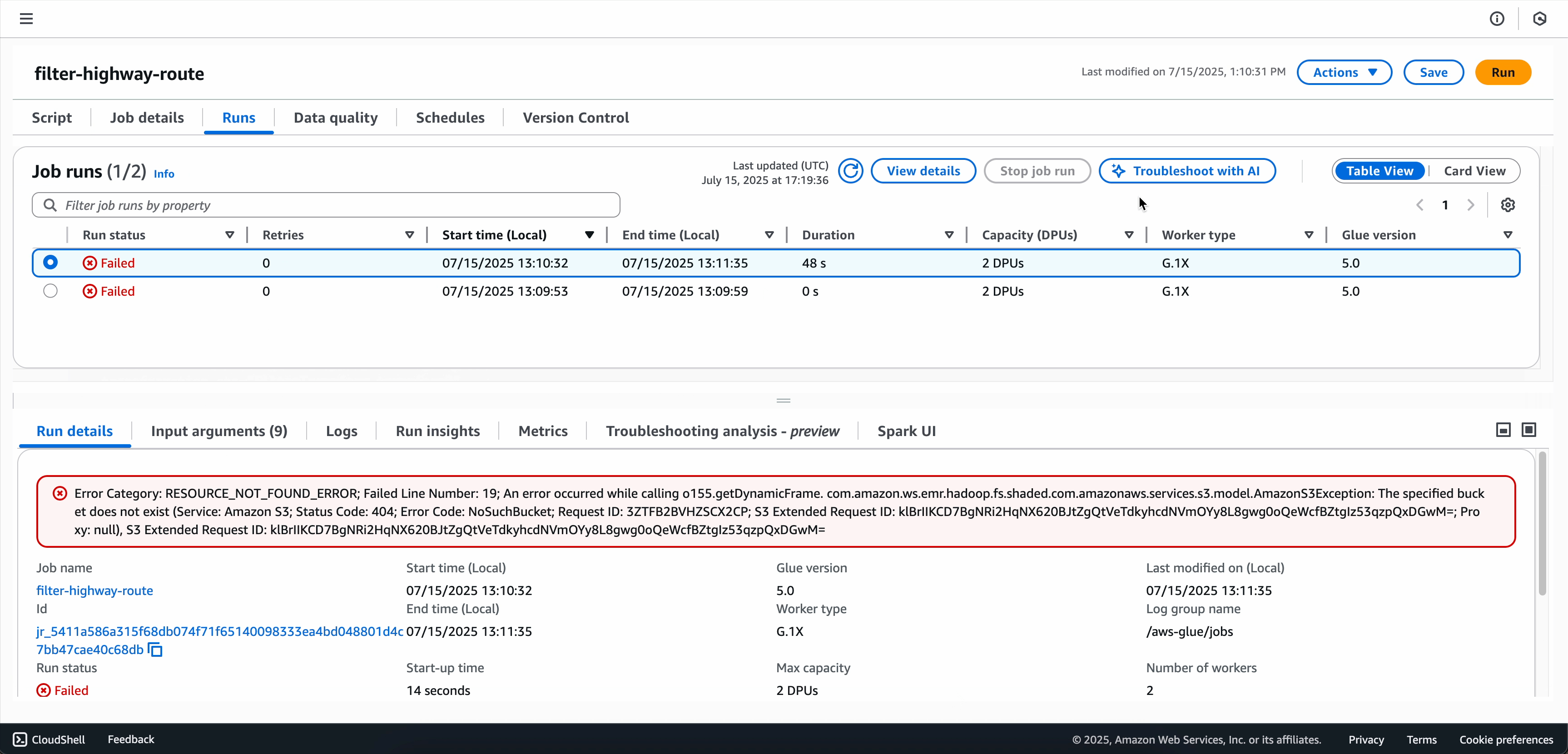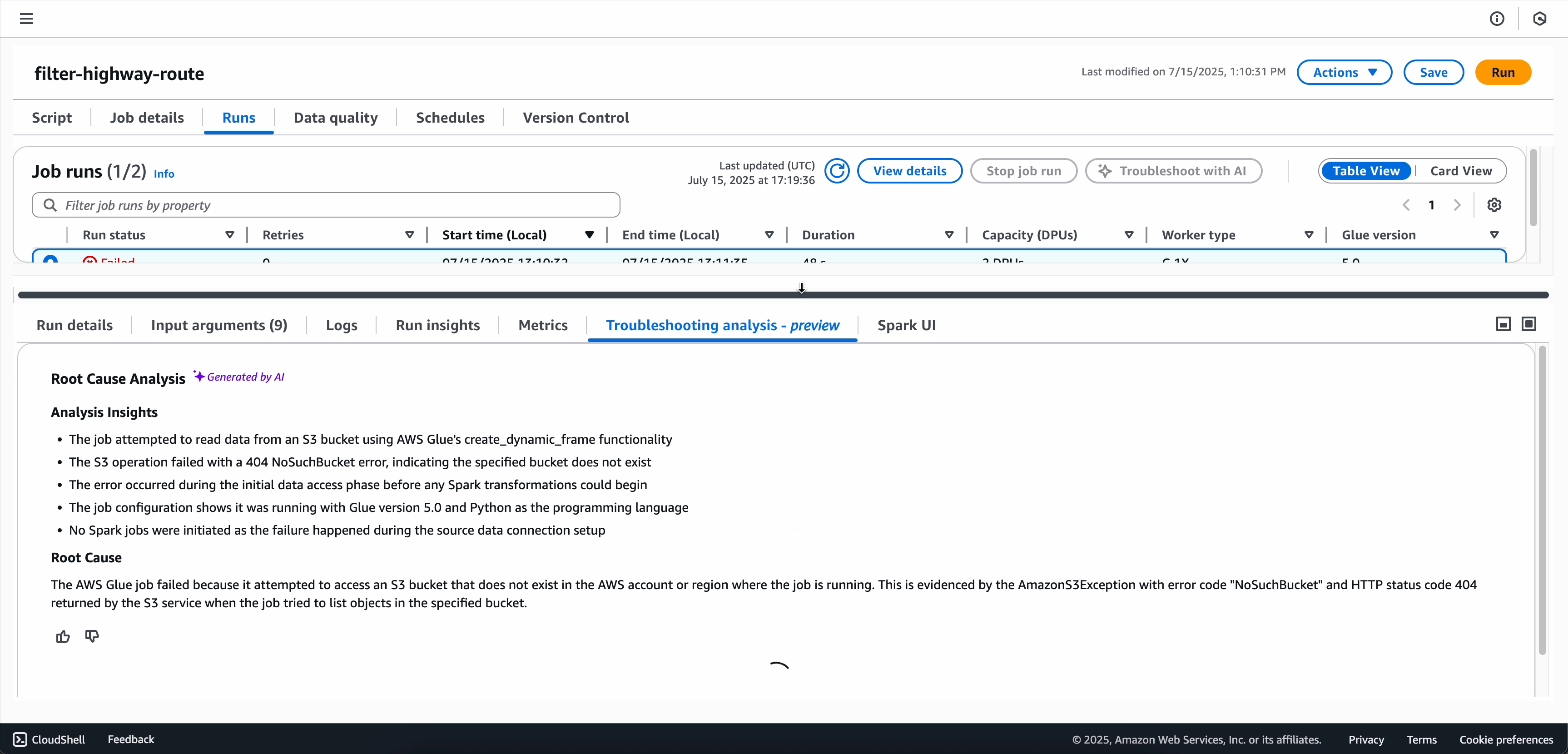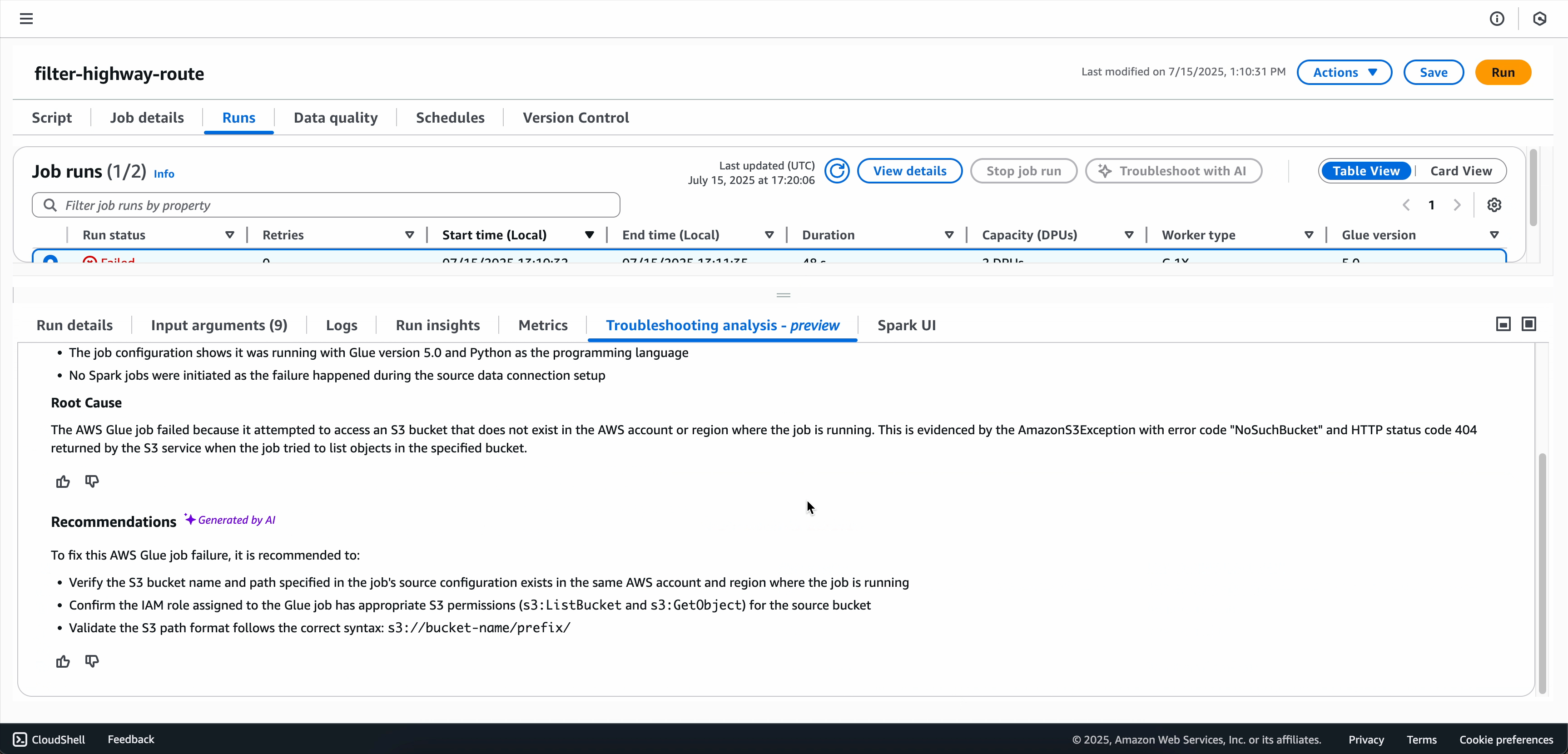
選項 2:使用「任務執行監控」頁面
-
導覽至任務執行監控頁面。
-
找到失敗的任務執行。
-
選擇動作下拉式功能表。
-
選擇使用 AI 進行故障診斷。
選項 3:從「任務執行詳細資訊」頁面中
-
按一下執行索引標籤中失敗執行的檢視詳細資訊,或在任務執行監控頁面中選取任務執行,導覽至失敗任務執行的詳細資訊頁面。
-
在任務執行詳細資訊頁面中,找到疑難排解分析索引標籤。
支援的故障診斷類別
此服務著重於資料工程師和開發人員在其 Spark 應用程式中經常遇到的三個主要問題類別:
-
資源設定和存取錯誤:在 Glue AWS 中執行 Spark 應用程式時,資源設定和存取錯誤是最常診斷但具挑戰性的問題之一。當您的 Spark 應用程式嘗試與 AWS 資源互動,但遇到許可問題、資源遺失或組態問題時,通常會發生這些錯誤。
-
Spark 驅動程式和執行器記憶體問題:Apache Spark 任務中的記憶體相關錯誤的診斷和解決可能很複雜。當資料處理要求超過驅動程式節點或執行器節點上可用的記憶體資源時,這些錯誤通常會顯現出來。
-
Spark 磁碟容量問題:Glue Spark 任務中的儲存相關錯誤通常會在隨機播放操作、資料溢出或處理大規模資料轉換時出現。 AWS 這些錯誤可能特別棘手,因為其可能會在您的任務執行一段時間後才會顯現,因此可能會浪費寶貴的運算時間和資源。
-
查詢執行錯誤:Spark SQL 和 DataFrame 操作中的查詢失敗可能難以進行故障診斷,因為錯誤訊息可能無法明確指向根本原因,並且可以使用小型資料集的查詢可能會突然大規模失敗。當這些錯誤在複雜的轉換管道中深入發生時,會變得更加具有挑戰性,其中實際問題可能來自較早階段的資料品質問題,而不是查詢邏輯本身。
注意
在生產環境中實作任何建議的變更之前,請徹底檢閱建議的變更。此服務會根據模式和最佳實務提供建議,但您的特定使用案例可能需要其他考量。
支援的 區域
Apache Spark 的生成式 AI 疑難排解可在下列區域使用:
-
非洲:開普敦 (af-south-1)
-
亞太區域:香港 (ap-east-1)、東京 (ap-northeast-1)、首爾 (ap-northeast-2)、大阪 (ap-northeast-3)、孟買 (ap-south-1)、新加坡 (ap-southeast-1)、雪梨 (ap-southeast-2) 和雅加達 (ap-southeast-3)
-
歐洲:法蘭克福 (eu-central-1)、斯德哥爾摩 (eu-north-1)、米蘭 (eu-south-1)、愛爾蘭 (eu-west-1)、倫敦 (eu-west-2) 和巴黎 (eu-west-3)
-
中東:巴林 (me-south-1) 和阿拉伯聯合大公國 (me-central-1)
-
北美洲:加拿大 (ca-central-1)
-
南美洲:聖保羅 (sa-east-1)
-
美國:北維吉尼亞 (us-east-1)、俄亥俄 (us-east-2)、北加州 (us-west-1) 和奧勒岡 (us-west-2)
