本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
搭配 AWS 使用 Glue AWS Lake Formation 進行精細存取控制
概觀
使用 AWS Glue 5.0 版和更新版本,您可以利用 AWS Lake Formation 在 S3 支援的 Data Catalog 資料表上套用精細存取控制。此功能可讓您設定 AWS Glue for Apache Spark 任務中 read 查詢的資料表、資料列、資料欄和儲存格層級存取控制。請參閱下列各節,進一步了解 Lake Formation 以及如何搭配 Glue AWS 使用。
GlueContextGlue 5.0 不支援具有 Glue 4.0 或 以前支援 AWS Lake Formation 許可的 型資料表層級存取控制。在 Glue 5.0 中使用新的 Spark 原生精細存取控制 (FGAC)。請注意下列詳細資訊:
如果您需要精細的存取控制 (FGAC) 進行資料列/資料欄/儲存格存取控制,將需要從 Glue 4.0 和之前版本中的
GlueContext/Glue DynamicFrame 移轉至 Glue 5.0 中的 Spark dataframe。如需取得範例,請參閱「從 GlueContext/Glue DynamicFrame 移轉至 Spark DataFrame」。如果您需要完整資料表存取控制 (FTA),您可以利用 FTA AWS 搭配 Glue 5.0 中的 DynamicFrames。您也可以遷移至原生 Spark 方法,以取得其他功能,例如彈性分散式資料集 (RDDs)、自訂程式庫,以及具有 AWS Lake Formation 資料表的使用者定義函數 (UDFs)。如需範例,請參閱從 AWS Glue 4.0 遷移至 AWS Glue 5.0。
如果不需要 FGAC,則不需要移轉 Spark dataframe,而且諸如任務書籤和下推述詞等
GlueContext功能將繼續運作。使用 FGAC 的任務需要至少 4 個工作者:一個使用者驅動程式、一個系統驅動程式、一個系統執行器和一個待命使用者執行器。
將 AWS Glue 與 搭配使用 AWS Lake Formation 會產生額外費用。
Glue AWS 如何使用 AWS Lake Formation
使用 AWS Glue 搭配 Lake Formation 可讓您對每個 Spark 任務強制執行一層許可,以在 Glue 執行任務時套用 Lake Formation AWS 許可控制。 AWS Glue 使用 Spark 資源描述
以下是 Glue AWS 如何存取 Lake Formation 安全政策所保護資料的高階概觀。
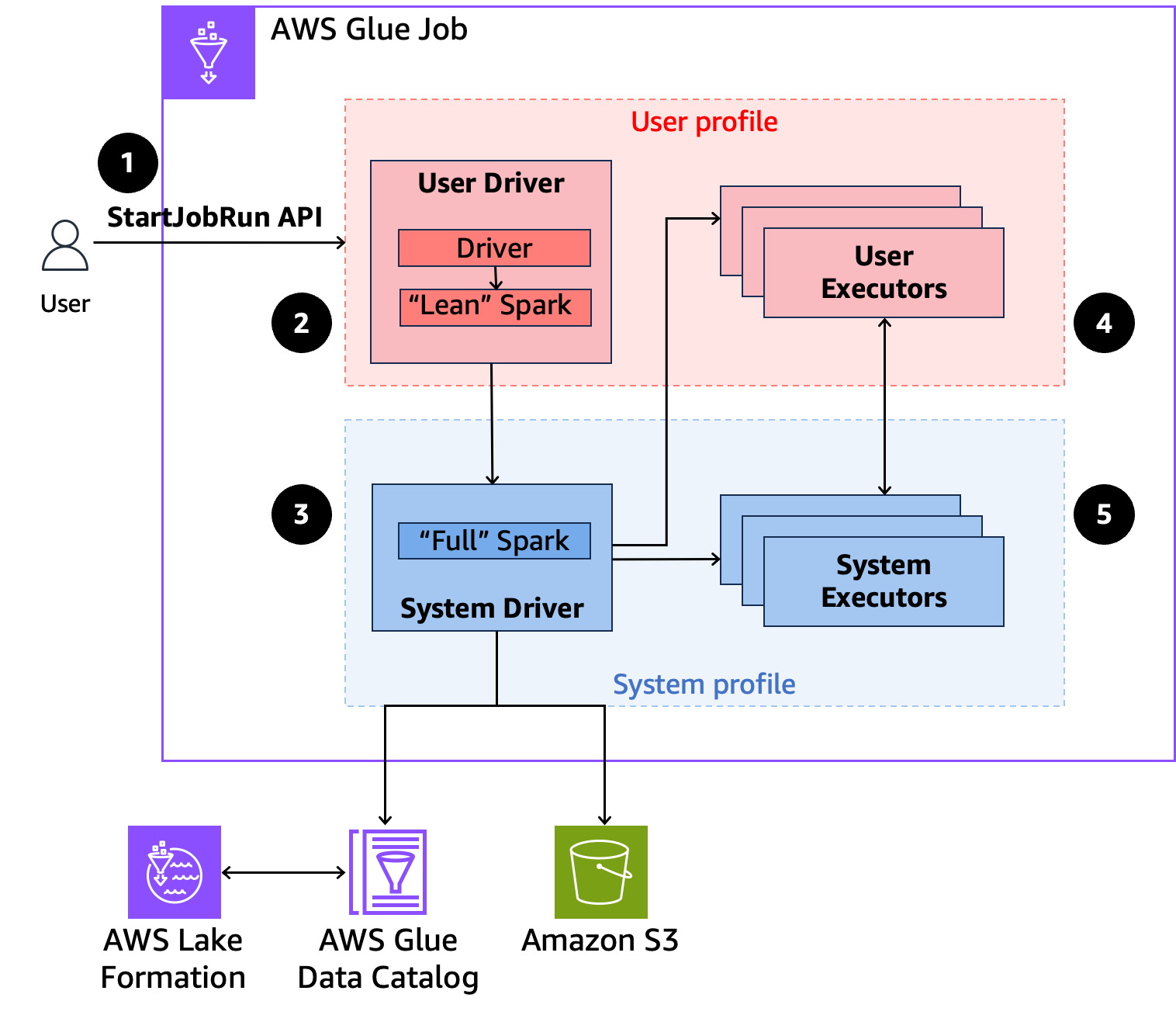
-
使用者在已啟用 AWS Lake Formation 的 Glue AWS 任務上呼叫
StartJobRunAPI。 -
AWS Glue 會將任務傳送給使用者驅動程式,並在使用者設定檔中執行任務。使用者驅動程式會執行 Spark 的精簡版本,該版本無法啟動任務、請求執行器、存取 S3 或 Glue Catalog。其會建置任務計畫。
-
AWS Glue 會設定第二個稱為系統驅動程式的驅動程式,並在系統設定檔中執行它 (具有特殊權限身分)。 AWS Glue 會在兩個驅動程式之間設定加密的 TLS 頻道以進行通訊。使用者驅動程式使用該頻道將任務計劃傳送至系統驅動程式。系統驅動程式不會執行使用者提交的程式碼。其會執行完整的 Spark,並與 S3 和 Data Catalog 通訊以進行資料存取。其會請求執行器,並將任務計畫編譯成一系列的執行階段。
-
AWS 然後,Glue 會使用使用者驅動程式或系統驅動程式在執行器上執行階段。任何階段的使用者程式碼只會在使用者設定檔執行器上執行。
-
從受 保護的資料目錄資料表 AWS Lake Formation 或套用安全篩選條件的資料表讀取資料的階段,會委派給系統執行器。
最低工作者要求
Glue AWS 中已啟用 Lake Formation 的任務至少需要 4 個工作者:一個使用者驅動程式、一個系統驅動程式、一個系統執行器和一個待命使用者執行器。這高於標準 Glue 任務所需的最少 AWS 2 個工作者。
Glue 中已啟用 Lake Formation AWS 的任務會使用兩個 Spark 驅動程式,一個用於系統設定檔,另一個用於使用者設定檔。同樣,執行器也分為兩個設定檔:
系統執行器:處理套用 Lake Formation 資料篩選條件的任務。
使用者執行器:由系統驅動程式視需要請求。
由於 Spark 任務本質上是延遲的,因此在扣除兩個驅動程式後, AWS Glue 會為使用者執行器保留 10% 的工作者總數 (最少 1 個)。
所有啟用 Lake Formation 的任務都已啟用自動擴展,這表示使用者執行器只會在需要時啟動。
如需範例組態,請參閱考量和限制。
任務執行時期角色 IAM 許可
Lake Formation 許可控制對 AWS Glue Data Catalog 資源、Amazon S3 位置和這些位置基礎資料的存取。IAM 許可可控制對 Lake Formation 和 AWS Glue API 和資源的存取。雖然您可能具有 Lake Formation 許可來存取 Data Catalog (SELECT) 中的資料表,但是如果您沒有 glue:Get* API 操作的 IAM 許可,您的操作會失敗。
以下範例政策說明如何提供 IAM 許可來存取 S3 中的指令碼 (將日誌上傳至 S3)、 AWS Glue API 許可以及用於存取 Lake Formation 的許可。
設定任務執行時期角色的 Lake Formation 許可
首先,向 Lake Formation 註冊 Hive 資料表的位置。然後在所需的資料表上建立任務執行時期角色的許可。如需 Lake Formation 的詳細資訊,請參閱《 AWS Lake Formation 開發人員指南》中的什麼是 AWS Lake Formation?。
設定 Lake Formation 許可後,可以在 AWS Glue 上提交 Spark 任務。
提交任務執行
完成 Lake Formation 授予的設定後,您可以在 Glue 上提交 Spark AWS 任務。若要執行 Iceberg 任務,必須提供下列 Spark 組態。若要透過 Glue 任務參數進行設定,請放置下列參數:
金錀:
--conf值:
spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog --conf spark.sql.catalog.spark_catalog.warehouse=<S3_DATA_LOCATION> --conf spark.sql.catalog.spark_catalog.glue.account-id=<ACCOUNT_ID> --conf spark.sql.catalog.spark_catalog.client.region=<REGION> --conf spark.sql.catalog.spark_catalog.glue.endpoint=https://glue.<REGION>.amazonaws.com
使用互動式工作階段
完成 AWS Lake Formation 授予的設定後,您可以在 Glue AWS 上使用互動式工作階段。必須先透過 %%configure 魔法提供下列 Spark 組態,才能執行程式碼。
%%configure { "--enable-lakeformation-fine-grained-access": "true", "--conf": "spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog --conf spark.sql.catalog.spark_catalog.warehouse=<S3_DATA_LOCATION> --conf spark.sql.catalog.spark_catalog.catalog-impl=org.apache.iceberg.aws.glue.GlueCatalog --conf spark.sql.catalog.spark_catalog.io-impl=org.apache.iceberg.aws.s3.S3FileIO --conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions --conf spark.sql.catalog.spark_catalog.client.region=<REGION> --conf spark.sql.catalog.spark_catalog.glue.account-id=<ACCOUNT_ID> --conf spark.sql.catalog.spark_catalog.glue.endpoint=https://glue.<REGION>.amazonaws.com" }
FGAC for AWS Glue 5.0 筆記本或互動式工作階段
若要在 Glue AWS 中啟用精細存取控制 (FGAC),您必須在建立第一個儲存格之前,將 Lake Formation 所需的 Spark confs 指定為 %%configure 魔術的一部分。
稍後使用 SparkSession.builder().conf("").get() 或 SparkSession.builder().conf("").create() 呼叫來指定其將不起作用。這是 Glue 4.0 AWS 行為的變更。
支援開放式資料表格式
AWS Glue 5.0 版或更新版本包括支援以 Lake Formation 為基礎的精細存取控制。 AWS Glue 支援 Hive 和 Iceberg 資料表類型。下表說明所有支援的操作。
| 作業 | Hive | Iceberg |
|---|---|---|
| DDL 命令 | 僅具有 IAM 角色許可 | 僅具有 IAM 角色許可 |
| 增量查詢 | 不適用 | 完全支援 |
| 時間歷程查詢 | 不適用於此資料表格式 | 完全支援 |
| 中繼資料表 | 不適用於此資料表格式 | 支援,但會隱藏某些資料表。如需詳細資訊,請參閱考量和限制。 |
DML INSERT |
僅具有 IAM 許可 | 僅具有 IAM 許可 |
| DML UPDATE | 不適用於此資料表格式 | 僅具有 IAM 許可 |
DML DELETE |
不適用於此資料表格式 | 僅具有 IAM 許可 |
| 讀取操作 | 完全支援 | 完全支援 |
| 預存程序 | 不適用 | 支援 ,但 register_table 和 migrate 例外。如需詳細資訊,請參閱考量和限制。 |
