本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
AWS Glue 將 Spark 任務遷移至 5.0 AWS Glue 版
本主題說明 0.9、1.0、2.0、3.0 和 4.0 AWS Glue 版之間的變更,以允許您將 Spark 應用程式和 ETL 任務遷移至 AWS Glue 5.0。它還描述了 AWS Glue 5.0 中的功能以及使用它的優勢。
若要將此功能與 AWS Glue ETL 任務搭配使用,請在建立任務Glue version時5.0為 選擇 。
主題
新功能
本節說明 5.0 AWS Glue 版的新功能和優點。
-
Apache Spark 從 3.3.0 in AWS Glue 4.0 更新至 3.5.4 in AWS Glue 5.0。請參閱 從 Spark 3.3.0 到 Spark 3.5.4 的主要增強功能。
-
使用 Lake Formation 的 Spark 原生精細存取控制 (FGAC)。這包括適用於 Iceberg、Delta 和 Hudi 資料表的 FGAC。如需詳細資訊,請參閱使用 AWS Glue 搭配 AWS Lake Formation 進行精細存取控制。
請注意 Spark 原生 FGAC 的下列考量或限制:
目前不支援資料寫入
透過
GlueContext使用 Lake Formation 寫入到 Iceberg 需要改用 IAM 存取控制
如需使用 Spark 原生 FGAC 時的限制和考量完整清單,請參閱考量和限制。
-
支援 Amazon S3 Access Grants 作為 Amazon S3 資料的可擴展存取控制解決方案 AWS Glue。如需詳細資訊,請參閱搭配 使用 Amazon S3 Access Grants AWS Glue。
-
開放式資料表格式 (OTF) 已更新為 Hudi 0.15.0、Iceberg 1.7.1 和 Delta Lake 3.3.0
-
Amazon SageMaker Unified Studio 支援。
-
Amazon SageMaker 資料湖倉和資料抽象整合。如需詳細資訊,請參閱從 AWS Glue ETL 查詢中繼存放區資料目錄。
-
支援使用
requirements.txt安裝其他 Python 程式庫。如需詳細資訊,請參閱使用 requirements.txt AWS 在 Glue 5.0 或更高版本中安裝其他 Python 程式庫。 -
AWS Glue 5.0 支援 Amazon DataZone 中的資料歷程。您可以設定 AWS Glue 在 Spark 任務執行期間自動收集歷程資訊,並傳送要在 Amazon DataZone 中視覺化的歷程事件。如需詳細資訊,請參閱 Amazon DataZone 中的資料沿襲。
若要在 AWS Glue 主控台上設定,請開啟產生歷程事件,然後在任務詳細資訊索引標籤上輸入您的 Amazon DataZone 網域 ID。
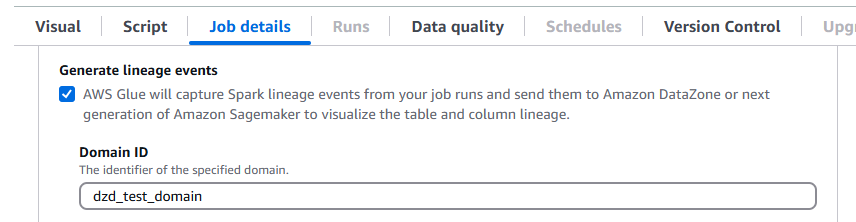
或者,可以提供下列任務參數 (提供 DataZone 網域 ID):
索引鍵:
--conf值:
extraListeners=io.openlineage.spark.agent.OpenLineageSparkListener —conf spark.openlineage.transport.type=amazon_datazone_api -conf spark.openlineage.transport.domainId=<your-domain-ID>
-
連接器和 JDBC 驅動器更新。如需詳細資訊,請參閱附錄 B:JDBC 驅動程式升級及附錄 C:連接器升級。
-
Java 從 8 更新至 17。
-
為 AWS Glue
G.1X和G.2X工作者增加的儲存空間,磁碟空間分別增加到 94GB 和 138GB。此外,新的工作者類型G.12X、G.16X和記憶體最佳化R.1X、R.2X、R.4X、R.8X提供 AWS Glue 4.0 和更新版本。如需詳細資訊,請參閱任務 如果任務支援 v2,則支援適用於 Java 的 AWS SDK,第 2 - AWS Glue 5.0 版任務可以使用適用於 Java 的 1.12.569
或 2.28.8 版。 適用於 Java 的 AWS SDK 2.x 是 1.x 版程式碼基礎的主要重寫。它建置在 Java 8+ 上,並新增了數個經常請求的功能。這些包括支援非封鎖 I/O 以及能夠在執行期外掛不同的 HTTP 實作。如需詳細資訊,包括從 SDK for Java v1 到 v2 的移轉指南,請參閱 AWS SDK for Java 第 2 版指南。
突破性變更
請注意下列變更:
-
在 AWS Glue 5.0 中,使用 S3A 檔案系統時,如果未設定 `fs.s3a.endpoint` 和 `fs.s3a.endpoint.region`,則 S3A 使用的預設區域為 `us-east-2`。這可能會導致問題,例如 S3 上傳逾時錯誤,尤其是 VPC 任務。若要緩解此變更造成的問題,請在 AWS Glue 5.0 中使用 S3A 檔案系統時,設定 `fs.s3a.endpoint.region` Spark 組態。
-
Lake Formation 精細存取控制 (FGAC)
-
AWS Glue 5.0 僅支援使用 Spark DataFrames 的新 Spark 原生 FGAC。它不支援使用 AWS Glue DynamicFrames 的 FGAC。
-
在 5.0 中使用 FGAC 需要從 AWS Glue DynamicFrames 遷移至 Spark DataFrames
-
如果您不需要 FGAC,則不需要移轉至 Spark DataFrame 和 GlueContext 功能,例如任務書籤和下推述詞將繼續運作。
-
-
使用 Spark 原生 FGAC 的任務需要至少 4 個工作者:一個使用者驅動程式、一個系統驅動程式、一個系統執行器和一個待命使用者執行器。
-
如需詳細資訊,請參閱使用 AWS Glue 搭配 AWS Lake Formation 進行精細存取控制。
-
-
Lake Formation 完整資料表存取 (FTA)
-
AWS Glue 5.0 支援 FTA 搭配 Spark 原生 DataFrames (新) 和 GlueContext DynamicFrames (舊版,有限制)
-
Spark 原生 FTA
-
如果 4.0 指令碼使用 GlueContext,請移轉為使用原生 Spark。
-
此功能僅限於 hive 和 iceberg 資料表
-
如需設定 5.0 任務以使用 Spark 原生 FTA 的詳細資訊,請參閱 AWS Glue 5.0 版的原生 Spark FTA。
-
-
GlueContext DynamicFrame FTA
-
不需要變更程式碼
-
此功能僅限於非 OTF 資料表,不適用於 Iceberg、Delta Lake 和 Hudi。
-
-
不支援向量化 SIMD CSV 讀取器。
不支援持續記錄至輸出日誌群組。請改用
error日誌群組。AWS Glue 任務執行洞見
job-insights-rule-driver已棄用。job-insights-rca-driver日誌串流現在位於錯誤日誌群組中。不支援基於 Athena 的自訂/市場連接器。
不支援 Adobe Marketo Engage、Facebook Ads、Google Ads、Google Analytics 4、Google Sheets、Hubspot、Instagram Ads、Intercom、Jira Cloud、Oracle NetSuite、Salesforce、Salesforce Marketing Cloud、Salesforce Marketing Cloud Account Engagement、SAP OData、ServiceNow、Slack、Snapchat Ads、S Stripe、Zendesk 和 Zoho CRM 連接器。
AWS Glue 5.0 不支援自訂 log4j 屬性。
從 Spark 3.3.0 到 Spark 3.5.4 的主要增強功能
請注意下列增強功能:
-
適用於 Spark Connect 的 Python 用戶端 (SPARK-39375
)。 -
實作對資料表中資料欄 DEFAULT 值的支援 (SPARK-38334
)。 -
支援「橫向資料欄別名參考」(SPARK-27561
)。 -
強化錯誤類別的 SQLSTATE 使用 (SPARK-41994
)。 -
預設啟用 Bloom Filter Joins (SPARK-38841
)。 -
Spark UI 可擴展性和驅動程式穩定性更佳,適用於大型應用程式 (SPARK-41053
)。 -
結構化串流中的非同步進度追蹤 (SPARK-39591
)。 -
結構化串流中的 Python 任意狀態處理 (SPARK-40434
)。 -
Pandas API 覆蓋率改進 (SPARK-42882
) 和 PySpark 中的 NumPy 輸入支援 (SPARK-39405 )。 -
為 PySpark 使用者定義的函數提供記憶體分析工具 (SPARK-40281
)。 -
實作 PyTorch Distributor (SPARK-41589
)。 -
發布 SBOM 成品 (SPARK-41893
)。 -
僅支援 IPv6 環境 (SPARK-39457
)。 -
自訂的 K8s 排程器 (Apache YuniKorn 和 Volcano) GA (SPARK-42802
)。 -
Spark Connect (SPARK-42554
) 和 (SPARK-43351 ) 中的 Scala 和 Go 用戶端支援。 -
適用於 Spark Connect 的基於 PyTorch 的分佈式 ML 支援 (SPARK-42471
)。 -
Python 和 Scala (SPARK-42938
) 中 Spark Connect 的結構化串流支援。 -
Python Spark Connect 用戶端 (SPARK-42497
) 的 Pandas API 支援。 -
介紹 Arrow Python UDF (SPARK-40307
)。 -
支援 Python 使用者定義的資料表函數 (SPARK-43798
)。 -
將 PySpark 錯誤移轉至錯誤類別 (SPARK-42986
)。 -
PySpark 測試架構 (SPARK-44042
)。 -
新增對 Datasketches HllSketch (SPARK-16484
) 的支援。 -
內建 SQL 函數改進 (SPARK-41231
)。 -
IDENTIFIER 子句 (SPARK-43205
)。 -
將 SQL 函數新增至 Scala、Python 和 R API (SPARK-43907
)。 -
新增 SQL 函數的具名引數支援 (SPARK-43922
)。 -
如果隨機資料已移轉,避免在停用的執行器上重新執行不必要的任務 (SPARK-41469
)。 -
分散式 ML <> spark connect (SPARK-42471
)。 -
DeepSpeed 分配器 (SPARK-44264
)。 -
實作 RocksDB 狀態存放區的變更日誌檢查點 (SPARK-43421
)。 -
引入運算子之間的浮水印傳播 (SPARK-42376
)。 -
介紹 dropDuplicatesWithinWatermark (SPARK-42931
)。 -
RocksDB 狀態存放區提供器記憶體管理增強功能 (SPARK-43311
)。
要遷移至 AWS Glue 5.0 的動作
對於現有的任務,請將舊版 Glue version 變更為任務組態中的 Glue 5.0。
-
在 AWS Glue Studio
Glue 5.0 - Supports Spark 3.5.4, Scala 2, Python 3中,選擇Glue version。 -
在 API 中,選擇
UpdateJobAPI 操作GlueVersion參數中的5.0。
對於新任務,當您建立任務時請選擇 Glue 5.0。
-
在主控台中,在
Glue version中選擇Spark 3.5.4, Python 3 (Glue Version 5.0) or Spark 3.5.4, Scala 2 (Glue Version 5.0)。 -
在 AWS Glue Studio
Glue 5.0 - Supports Spark 3.5.4, Scala 2, Python 3中,選擇Glue version。 -
在 API 中,選擇
CreateJobAPI 操作GlueVersion參數中的5.0。
若要檢視來自 AWS Glue 2.0 或更早版本的 AWS Glue 5.0 Spark 事件日誌,請使用 CloudFormation 或 Docker 啟動升級的 Spark 歷史記錄伺服器 for AWS Glue 5.0。
移轉檢查清單
檢閱此檢查清單以進行移轉:
-
Java 17 更新
-
【Scala】 從 v1 升級 AWS SDK 呼叫至 v2
-
Python 3.10 移轉到 3.11
-
[Python] 將 boto 參考從 1.26 更新至 1.34
AWS Glue 5.0 功能
本節詳細說明 AWS Glue 功能。
從 AWS Glue ETL 查詢中繼存放區資料目錄
您可以註冊您的 AWS Glue 任務以存取 AWS Glue Data Catalog,讓資料表和其他中繼存放區資源可用於分散消費者。Data Catalog 支援多目錄階層,其可跨 Amazon S3 資料湖統一所有資料。其還提供 Hive 中繼存放區 API 和開放原始碼 Apache Iceberg API 來存取資料。這些功能可供 AWS Glue 和其他資料導向服務使用,例如 Amazon EMR、Amazon Athena 和 Amazon Redshift。
當您在 Data Catalog 中建立資源時,您可以從支援 Apache Iceberg REST API. AWS Lake Formation manages 許可的任何 SQL 引擎存取資源。在組態之後,您可以使用熟悉的應用程式查詢這些中繼存放區資源,利用 AWS Glue的功能來查詢不同的資料。包括 Apache Spark 和 Trino。
中繼資料資源的組織方式
使用 將資料組織在目錄、資料庫和資料表的邏輯階層中 AWS Glue Data Catalog:
目錄 – 包含資料存放區物件的邏輯容器,例如結構描述或資料表。
資料庫 – 在目錄中組織諸如資料表和檢視等資料物件。
資料表和檢視 – 資料庫中的資料物件,提供具有可理解結構描述的抽象層。其可讓您輕鬆存取各種格式和各種位置的基礎資料。
從 AWS Glue 4.0 遷移至 AWS Glue 5.0
AWS Glue 4.0 中存在的所有現有任務參數和主要功能都將存在於 AWS Glue 5.0 中,但機器學習轉換除外。
已新增下列新參數:
-
--enable-lakeformation-fine-grained-access:在 AWS Lake Formation 資料表中啟用精細存取控制 (FGAC) 功能。
請參閱 Spark 移轉文件:
從 AWS Glue 3.0 遷移至 AWS Glue 5.0
注意
如需與 AWS Glue 4.0 相關的遷移步驟,請參閱 從 AWS Glue 3.0 遷移至 AWS Glue 4.0。
AWS Glue 3.0 中存在的所有現有任務參數和主要功能都將存在於 AWS Glue 5.0 中,但機器學習轉換除外。
從 AWS Glue 2.0 遷移至 AWS Glue 5.0
注意
如需與 AWS Glue 4.0 相關的遷移步驟,以及 3.0 和 4.0 AWS Glue 版之間的遷移差異清單,請參閱 從 AWS Glue 3.0 遷移至 AWS Glue 4.0。
另請注意 3.0 和 2.0 AWS Glue 版之間的下列遷移差異:
AWS Glue 2.0 中存在的所有現有任務參數和主要功能都將存在於 AWS Glue 5.0 中,但機器學習轉換除外。
單獨的數個 Spark 變更可能需要修改指令碼,以確保沒有被引用刪除的功能。例如,Spark 3.1.1 和更新版本不會啟用 Scala 無類型的 UDF,但 Spark 2.4 確實允許。
不支援 Python 2.7。
在現有 AWS Glue 2.0 任務中提供的任何額外 jar 都可能會導致相互衝突的相依性,因為在數個相依性中有升級。可以避免
--user-jars-first任務參數的 classpath 衝突。parquet 檔案的載入/儲存時間戳記的行為變更。有關更多詳細資訊,請參閱從 Spark SQL 3.0 升級到 3.1。
驅動器/執行器組態的不同 Spark 任務平行處理。可以透過傳遞
--executor-cores任務引數來調整任務平行處理。
AWS Glue 5.0 中的記錄行為變更
以下是 AWS Glue 5.0 中記錄行為的變更。如需詳細資訊,請參閱記錄 AWS Glue 任務。
-
所有日誌 (系統日誌、Spark 常駐程式日誌、使用者日誌和 Glue Logger 日誌) 現在預設都會寫入到
/aws-glue/jobs/error日誌群組。 -
不再使用先前版本中用於持續記錄的
/aws-glue/jobs/logs-v2日誌群組。 -
無法再使用已移除的持續記錄引數來重新命名或自訂日誌群組或日誌串流名稱。反之,請參閱 AWS Glue 5.0 中的新任務引數。
AWS Glue 5.0 中引入了兩個新的任務引數
-
––custom-logGroup-prefix:可讓您指定/aws-glue/jobs/error和/aws-glue/jobs/output日誌群組的自訂字首。 -
––custom-logStream-prefix:可讓您為日誌群組中的日誌串流名稱指定自訂字首。自訂字首的驗證規則和限制包括:
-
整個日誌串流名稱的長度必須介於 1 到 512 個字元之間。
-
日誌串流名稱的自訂字首限制為 400 個字元。
-
字首中允許的字元包括字母數字字元、底線 (`_`)、連字號 (`-`) 和斜線 (`/`)。
-
AWS Glue 5.0 中的已棄用連續記錄引數
下列用於連續記錄的任務引數已在 AWS Glue 5.0 中棄用
-
––enable-continuous-cloudwatch-log -
––continuous-log-logGroup -
––continuous-log-logStreamPrefix -
––continuous-log-conversionPattern -
––enable-continuous-log-filter
Connector 和 JDBC 驅動程式遷移 for AWS Glue 5.0
如需已升級的 JDBC 和資料湖連接器版本,請參閱:
下列變更適用於 Glue 5.0 附錄中識別的連接器或驅動器版本。
Amazon Redshift
請注意下列變更:
新增支援三部分資料表名稱,以允許連接器查詢 Redshift 資料共用資料表。
更正 Spark
ShortType的映射,使用 RedshiftSMALLINT而非INTEGER,以更好地比對預期的資料大小。新增對 Amazon Redshift Serverless 自訂叢集名稱 (CNAME) 的支援。
Apache Hudi
請注意下列變更:
支援記錄層級索引。
支援自動產生記錄金鑰。現在不需要指定記錄金鑰欄位。
Apache Iceberg
請注意下列變更:
使用 支援精細存取控制 AWS Lake Formation。
支援分支和標記,其為具有各自獨立生命週期的具名快照參考。
已新增變更日誌檢視程序,該程序會產生檢視,其中包含在指定期間或特定快照之間對資料表所做的變更。
Delta Lake
請注意下列變更:
支援 Delta Universal Format (UniForm),其可透過 Apache Iceberg 和 Apache Hudi 進行無縫存取。
支援實作 Merge-on-Read 範例的刪除向量。
AzureCosmos
請注意下列變更:
新增階層分區索引鍵支援。
已新增將自訂結構描述與 StringType (原始 json) 用於巢狀屬性的選項。
已新增組態選項
spark.cosmos.auth.aad.clientCertPemBase64,以允許搭配使用 SPN (ServicePrincipal 名稱) 身分驗證與憑證,而非用戶端機密。
如需詳細資訊,請參閱 Azure Cosmos DB Spark 連接器變更日誌
Microsoft SQL Server
請注意下列變更:
預設啟用 TLS 加密。
當 encrypt = false 但伺服器需要加密時,會根據
trustServerCertificate連線設定來驗證憑證。aadSecurePrincipalId和aadSecurePrincipalSecret已棄用。已移除
getAADSecretPrincipalIdAPI。在指定領域時新增了 CNAME 解析度。
MongoDB
請注意下列變更:
支援使用 Spark 結構化串流的微型批量模式。
支援 BSON 資料類型。
新增了在使用微型批量或連續串流模式時讀取多個集合的支援。
如果
collection組態選項中使用的集合名稱包含逗號,Spark Connector 會將其視為兩個不同的集合。為了避免這種情況,必須在逗號前面加上反斜線 (\) 來轉義逗號。如果
collection組態選項中使用的集合名稱為 "*",Spark Connector 會將其解譯為掃描所有集合的規格。為了避免這種情況,必須在星號前面加上反斜線 (\) 來轉義逗號。如果
collection組態選項中使用的集合名稱包含反斜線 (\),Spark Connector 會將反斜線視為轉義字元,這可能會變更其解譯值的方式。為了避免這種情況,必須在反斜線前面加上另一個反斜線來轉義反斜線。
如需詳細資訊,請參閱適用於 Spark 的 MongoDB 連接器版本備註
Snowflake
請注意下列變更:
引進了一個新
trim_space參數,可以在儲存到 Snowflake 資料表時,用來自動修剪StringType資料欄的值。預設:false。根據預設,在工作階段層級停用
abort_detached_query參數。使用 OAUTH 時移除了
SFUSER參數的需求。已移除進階查詢下推功能。提供了此功能的替代方案。例如,使用者可以直接從 Snowflake SQL 查詢載入資料,而不是從 Snowflake 資料表載入資料。
如需詳細資訊,請參閱 Snowflake Connector for Spark 版本備註
附錄 A:值得注意的相依性升級
以下是相依性升級:
| 相依性 | in AWS Glue 5.0 版本 | in AWS Glue 4.0 版本 | in AWS Glue 3.0 版 | in AWS Glue 2.0 版本 | AWS Glue 1.0 版 |
|---|---|---|---|---|---|
| Java | 17 | 8 | 8 | 8 | 8 |
| Spark | 3.5.4 | 3.3.0-amzn-1 | 3.1.1-amzn-0 | 2.4.3 | 2.4.3 |
| Hadoop | 3.4.1 | 3.3.3-amzn-0 | 3.2.1-amzn-3 | 2.8.5-amzn-5 | 2.8.5-amzn-1 |
| Scala | 2.12.18 | 2.12 | 2.12 | 2.11 | 2.11 |
| Jackson | 2.15.2 | 2.12 | 2.12 | 2.11 | 2.11 |
| Hive | 2.3.9-amzn-4 | 2.3.9-amzn-2 | 2.3.7-amzn-4 | 1.2 | 1.2 |
| EMRFS | 2.69.0 | 2.54.0 | 2.46.0 | 2.38.0 | 2.30.0 |
| Json4s | 3.7.0-M11 | 3.7.0-M11 | 3.6.6 | 3.5.x | 3.5.x |
| Arrow | 12.0.1 | 7.0.0 | 2.0.0 | 0.10.0 | 0.10.0 |
| AWS Glue Data Catalog 用戶端 | 4.5.0 | 3.7.0 | 3.0.0 | 1.10.0 | N/A |
| AWS 適用於 Java 的 SDK | 2.29.52 | 1.12 | 1.12 | ||
| Python | 3.11 | 3.10 | 3.7 | 2.7 和 3.6 | 2.7 和 3.6 |
| Boto | 1.34.131 | 1.26 | 1.18 | 1.12 | N/A |
| EMR DynamoDB 連接器 | 5.6.0 | 4.16.0 |
附錄 B:JDBC 驅動程式升級
以下是 JDBC 驅動程式升級:
| 驅動程式 | JDBC 驅動程式 AWS Glue 5.0 版 | JDBC 驅動程式 in AWS Glue 4.0 版 | JDBC 驅動程式 in AWS Glue 3.0 版 | 過去版本的 JDBC 驅動程式 AWS Glue 版本 |
|---|---|---|---|---|
| MySQL | 8.0.33 | 8.0.23 | 8.0.23 | 5.1 |
| Microsoft SQL Server | 10.2.0 | 9.4.0 | 7.0.0 | 6.1.0 |
| Oracle 資料庫 | 23.3.0.23.09 | 21.7 | 21.1 | 11.2 |
| PostgreSQL | 42.7.3 | 42.3.6 | 42.2.18 | 42.1.0 |
| Amazon Redshift |
redshift-jdbc42-2.1.0.29 |
redshift-jdbc42-2.1.0.16 |
redshift-jdbc41-1.2.12.1017 |
redshift-jdbc41-1.2.12.1017 |
| SAP Hana | 2.20.17 | 2.17.12 | ||
| Teradata | 20.00.00.33 | 20.00.00.06 |
附錄 C:連接器升級
以下是連接器升級:
| 驅動程式 | AWS Glue 5.0 中的連接器版本 | AWS Glue 4.0 中的連接器版本 | 連接器 in AWS Glue 3.0 版 |
|---|---|---|---|
| EMR DynamoDB 連接器 | 5.6.0 | 4.16.0 | |
| Amazon Redshift | 6.4.0 | 6.1.3 | |
| OpenSearch | 1.2.0 | 1.0.1 | |
| MongoDB | 10.3.0 | 10.0.4 | 3.0.0 |
| Snowflake | 3.0.0 | 2.12.0 | |
| Google BigQuery | 0.32.2 | 0.32.2 | |
| AzureCosmos | 4.33.0 | 4.22.0 | |
| AzureSQL | 1.3.0 | 1.3.0 | |
| Vertica | 3.3.5 | 3.3.5 |
附錄 D:開放式資料表格式升級
以下是開放式資料表格式升級:
| OTF | AWS Glue 5.0 中的連接器版本 | AWS Glue 4.0 中的連接器版本 | 連接器 in AWS Glue 3.0 版 |
|---|---|---|---|
| Hudi | 0.15.0 | 0.12.1 | 0.10.1 |
| Delta Lake | 3.3.0 | 2.1.0 | 1.0.0 |
| Iceberg | 1.7.1 | 1.0.0 | 0.13.1 |
