本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
AWS Glue 串流自動擴展
AWS Glue 串流 ETL 任務會持續使用來自串流來源的資料、清理和轉換傳輸中的資料,並使其可用於分析。透過監控任務執行的每個階段, AWS Glue 自動擴展可以在工作者閒置時關閉工作者,如果可能進行額外的平行處理,則可以新增工作者。
下列各節提供 AWS Glue 串流自動調整規模的相關資訊
在 中啟用 Auto Scaling AWS Glue Studio
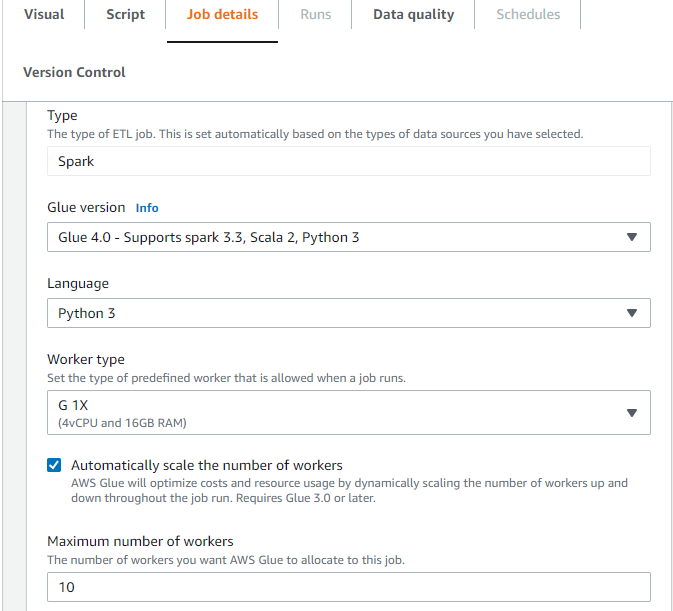
在 AWS Glue Studio 中的任務詳細資訊索引標籤上,選擇做為 Spark 或 Spark 串流的類型,以及做為 Glue 3.0 或 的 Glue 版本Glue 4.0。然後,一個核取方塊將顯示在 Worker type (工作者類型) 下方。
-
選取 Automatically scale the number of workers (自動擴展工作者數量) 選項。
-
設定 Maximum number of workers (工作者數上限) 以定義可提供給任務執行的工作者數上限。
使用 CLI 或 SDK AWS 啟用 Auto Scaling
若要為任務執行啟用 Auto Scaling 從 AWS CLI,start-job-run請使用下列組態執行 :
{ "JobName": "<your job name>", "Arguments": { "--enable-auto-scaling": "true" }, "WorkerType": "G.2X", // G.1X, G.2X, G.4X, G.8X, G.12X, G.16X, R.1X, R.2X, R.4X, and R.8X are supported for Auto Scaling Jobs "NumberOfWorkers": 20, // represents Maximum number of workers ...other job run configurations... }
在 ETL 任務執行完成後,您也可以呼叫 get-job-run 以檢查任務執行的實際資源使用情況 (以 DPU 秒為單位)。注意:新欄位 DPUSeconds 只會針對已啟用 Auto Scaling 的 AWS Glue 3.0 或更新版本上的批次任務顯示。此欄位不支援串流任務。
$ aws glue get-job-run --job-name your-job-name --run-id jr_xx --endpoint https://glue.us-east-1.amazonaws.com --region us-east-1 { "JobRun": { ... "GlueVersion": "3.0", "DPUSeconds": 386.0 } }
您還可以使用具有相同組態的 AWS Glue SDK 為任務執行設定 Auto Scaling。
運作方式
跨微批次進行調整
以下範例可說明自動調整的運作方式。
-
您有以 50 個 DPUs開頭 AWS Glue 的任務。
-
自動調整功能已啟用。
在此範例中, AWS Glue 查看幾個微批次的「batchProcessingTimeInMs」指標,並判斷您的任務是否在您已建立的時段大小內完成。如果任務提前完成,則視任務提前完成的時間多寡, AWS Glue 可能會縮減規模。您可以在 Amazon CloudWatch 監控這項使用「numberAllExecutors」繪製的指標,以了解自動調整功能的運作方式。
只有在每個微批次完成後,執行器的數量才會呈指數級擴展或縮減。如您在 Amazon CloudWatch 監控日誌中所見, 會 AWS Glue 尋找所需的執行器數量 (橘色線),並擴展執行器 (藍色線) 以自動符合該數量。
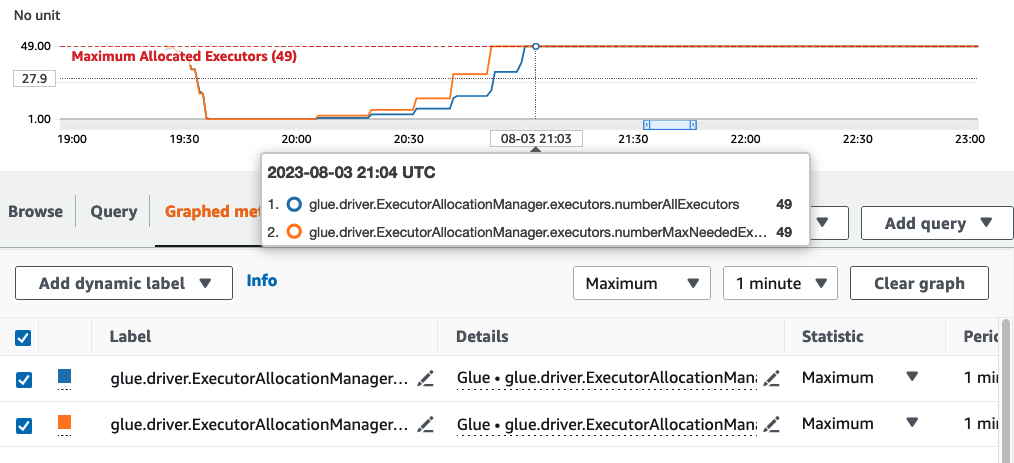
一旦 AWS Glue 縮減執行器數量,並觀察到資料磁碟區增加,因而增加微批次處理時間, AWS Glue 將擴展到最多 50 DPUs,這是指定的上限。
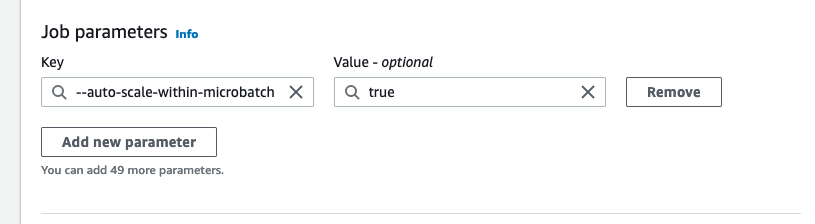
在微批次內調整
在上述範例中,系統會監控一些已完成的微批次,以決定要擴展還是縮減數量。若時間較長則需要自動擴展,以便可更快在微批次內回應,而無需等待幾個微批次。在這些情況下,您可以將其他設定 --auto-scale-within-microbatch 設定為 true。您可以將此新增至 中的 AWS Glue 任務屬性 AWS Glue Studio ,如下所示。