本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
啟用壓縮最佳化工具
您可以使用 AWS Glue 主控台 AWS CLI或 AWS API,為 AWS Glue Data Catalog 中的 Apache Iceberg 資料表啟用壓縮。針對新的資料表,您可以選擇 Apache Iceberg 作為資料表格式,並在您建立資料表時啟用壓縮功能。新資料表依預設會停用壓縮功能。
- Console
-
啟用壓縮功能
-
在 https://https://console.aws.amazon.com/glue/ 開啟 AWS Glue 主控台,並以資料湖管理員、資料表建立者或已在資料表上授予 glue:UpdateTable和 lakeformation:GetDataAccess許可的使用者身分登入。
-
在導覽面板的 Data Catalog 下方,選擇資料表。
在資料表頁面中,選擇您想要啟用壓縮的開放資料表格式的資料表,然後在動作功能表下依次選擇最佳化和啟用。
您也可以透過選取資料表詳細資訊頁面上的資料表最佳化索引標籤,來啟用壓縮。選擇頁面下半區段的資料表最佳化索引標籤,然後選擇啟用壓縮。
當您在 Data Catalog 中建立新的 Iceberg 資料表時,也可以使用啟用最佳化選項。
-
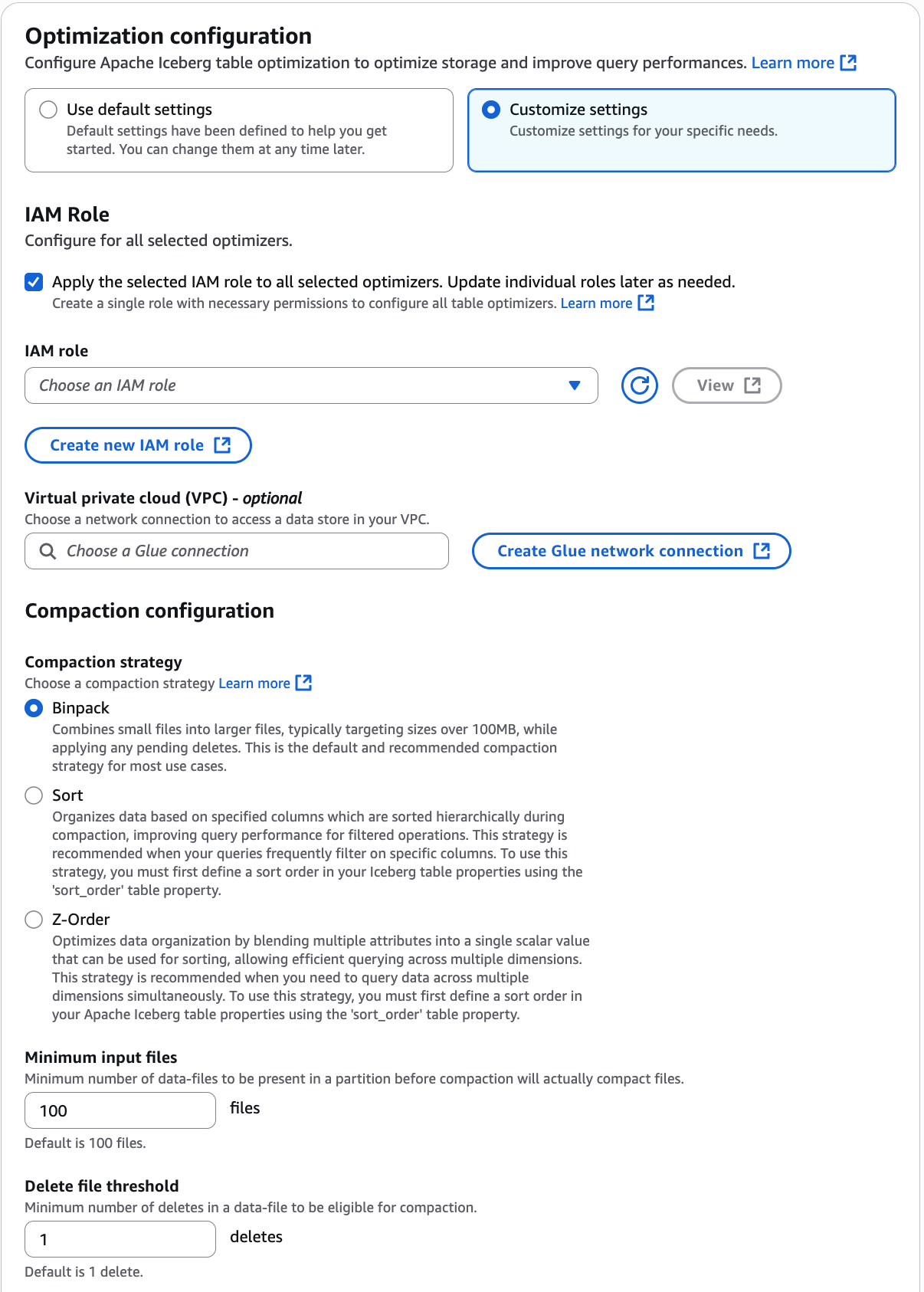
在啟用最佳化頁面上,選擇最佳化選項下的壓縮。
-
接下來,從下拉式清單中選取 IAM 角色,其許可會在 資料表最佳化先決條件 區段中顯示。
您也可以選擇建立新 IAM 角色選項,來建立具有執行壓縮所需許可的自訂角色。
請依照以下步驟更新現有 IAM 角色:
-
若要更新 IAM 角色的權限政策,請在 IAM 主控台中,前往用於執行壓縮程序的 IAM 角色。
-
在新增許可區段中,選擇「建立政策」。在新開啟的瀏覽器視窗中,建立要搭配您角色使用的新政策。
-
在「建立政策」頁面上,選擇 JSON 索引標籤。將「先決條件」中顯示的 JSON 程式碼複製到政策編輯器欄位中。
-
如果您有安全政策組態,其中 Iceberg 資料表最佳化工具需要從特定虛擬私有雲端 (VPC) 存取 Amazon S3 儲存貯體,請建立 AWS Glue 網路連線或使用現有的網路連線。
如果您尚未設定 AWS Glue VPC 連線,請依照使用 AWS Glue 主控台或 AWS CLI/SDK 建立連接器連線一節中的步驟建立新的連線。
-
選擇壓縮策略。可用選項為:
Binpack – Binpack 是 Apache Iceberg 中的預設壓縮策略。其會將較小的資料檔案合併為較大的檔案,以獲得最佳效能。
-
排序 – 在 Apache Iceberg 中排序是一種資料組織技術,可根據指定的資料欄叢集化檔案內的資訊,透過減少需要處理的檔案數目來大幅改善查詢效能。您可以使用排序順序欄位在 Iceberg 的中繼資料中定義排序順序,並且在指定多個資料欄時,資料會以資料欄在排序順序中出現的順序排序,以確保具有類似值的記錄儲存在檔案內。排序壓縮策略透過排序分區內所有檔案的資料,進一步進行最佳化。
Z 排序 – 當您需要依具有相同重要性的多個資料欄排序時,Z 排序是一種整理資料的方式。與優先考慮某一資料欄的傳統排序不同,Z 排序為每個資料欄賦予了平衡的權重,協助您的查詢引擎在搜尋資料時讀取更少的檔案。
該技術的運作方式是將不同資料欄的值的二進制數字組合在一起。例如,如果您有兩個資料欄中的數字 3 和 4,Z 排序會先將其轉換為二進制 (3 變成 011,4 變成 100),然後交錯這些數字以建立新的值:011010。此交錯會建立一種模式,讓相關資料實際緊密相鄰。
Z 排序對於多維查詢特別有效。例如,在跨多個維度查詢時,依收入、州/省和郵遞區號進行 Z 排序的客戶資料表可以提供比分階層排序更優越的效能。此組織允許以收入和地理位置的特定組合為目標的查詢,以快速找到相關資料,同時盡量減少不必要的檔案掃描。
-
最小輸入檔案 – 觸發壓縮之前,分區中所需的資料檔案數目。
-
刪除檔案閾值 – 資料檔案在符合壓縮條件之前所需的最少刪除操作。
-
選擇啟用最佳化。
- AWS CLI
-
下列範例顯示如何啟用壓縮功能。以有效的帳戶 ID 取代 AWS 帳戶 ID。將資料庫名稱和資料表名稱取代為實際的 Iceberg 資料表名稱和資料庫名稱。將 roleArn 取代為 IAM 角色的 AWS Resource Name (ARN),以及具有執行壓縮程序之必要權限的 IAM 角色名稱。您可以將壓縮策略 sort 取代為其他支援的策略,例如 z-order 或 binpack。
順序」,視您的需求而定。
aws glue create-table-optimizer \
--catalog-id 123456789012 \
--database-name iceberg_db \
--table-name iceberg_table \
--table-optimizer-configuration '{
"roleArn": "arn:aws:iam::123456789012:role/optimizer_role",
"enabled": true,
"vpcConfiguration": {"glueConnectionName": "glue_connection_name"},
"compactionConfiguration": {
"icebergConfiguration": {"strategy": "sort"}
}
}'\
--type compaction
- AWS API
-
呼叫 CreateTableOptimizer 操作以啟用資料表的壓縮。
啟用壓縮後,資料表最佳化索引標籤會在壓縮執行完成後,顯示下列壓縮詳細資訊:
- 開始時間
-
在 Data Catalog 內啟動壓縮程序的時間。該值為以 UTC 時間為單位的時間戳記。
- 結束時間
-
壓縮程序在 Data Catalog 中結束的時間。該值為以 UTC 時間為單位的時間戳記。
- 狀態
-
壓縮執行的狀態。值會是 success 或 fail。
- 壓縮的檔案數
壓縮的檔案總數。
- 壓縮的位元組數
-
壓縮的位元組總數。