本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
AWS Glue Data Quality 中的異常偵測
工程師同時管理數百個資料管道。每個管道都可以從各種來源擷取資料並將資料載入資料湖或其他資料儲存庫中。為了確保交付高品質資料以進行決策,他們會制定資料品質規則。這些規則會根據反映目前業務狀態的固定條件來評估資料。不過,當商業環境變更時,資料屬性會轉移,使這些固定條件過時,並導致資料品質不佳。
例如,一家零售公司的資料工程師制定了一條規則,要求每日銷售額的規則,要求每日銷售額必須超過一百萬美元的閾值。幾個月後,每日銷售額超過兩百萬美元,導致閾值過時。由於缺乏通知以及手動分析和更新規則所需的工作,資料工程師無法更新規則以反映最新閾值。本月稍後,商業使用者注意到銷售額下降了 25%。經過數小時的調查後,資料工程師發現負責從某些存放區擷取資料的 ETL 管道失敗,而不會產生錯誤。閾值過期的規則繼續成功運作,而沒有檢測到此問題。
或者,可以偵測這些異常的主動提醒可能讓使用者能夠偵測此問題。此外,追蹤業務的季節性可能會突顯重大的資料品質問題。例如,零售額在週末和假日期間可能最高,而在工作日則相對較低。偏離此模式可能表示資料品質問題或業務情況的變化。資料品質規則無法偵測季節性模式,因為這需要進階演算法,才能從過去擷取季節性的模式中學習,以偵測偏差。
最後,由於規則建立流程的技術性質以及撰寫規則所需的時間,使用者發現建立和維護規則具有挑戰性。因此,他們偏好在定義規則之前先探索資料洞察。客戶需要能夠輕鬆發現異常,讓他們能夠主動偵測資料品質問題,並做出自信的業務決策。
運作方式
注意
只有 Glue ETL AWS 才支援異常偵測。Data Catalog 型資料品質不支援此功能。
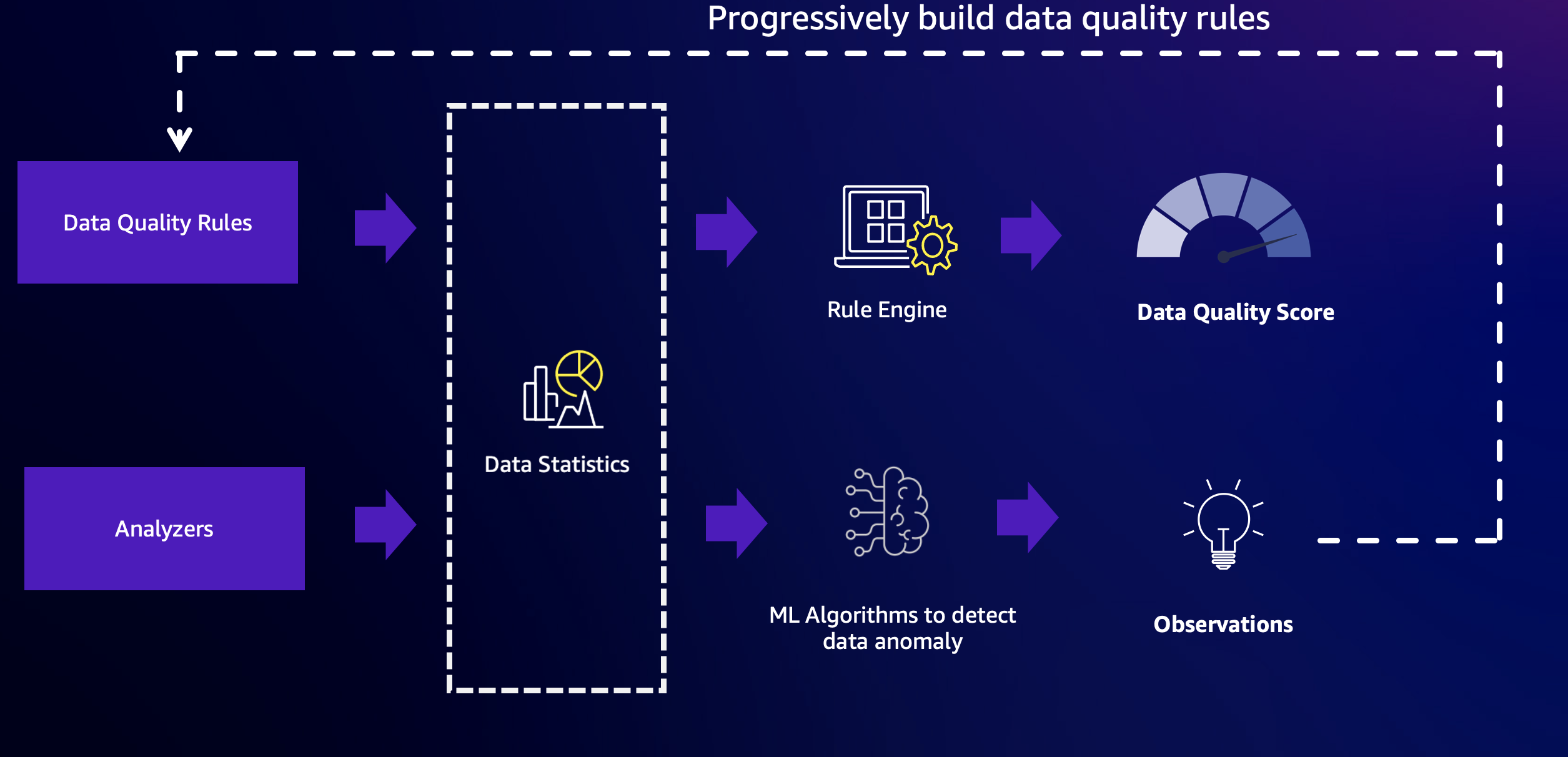
AWS Glue Data Quality 結合了規則型資料品質和異常偵測功能的強大功能,可提供高品質的資料。若要開始使用,您必須先設定規則和分析器,然後啟用異常偵測。
Rules
規則 – 規則使用一種稱為資料品質定義語言 (DQDL) 的開放語言表達對資料的期望。以下所示為規則的範例。在 `passenger_count` 資料欄中沒有空值或 NULL 值時,此規則將會成功:
Rules = [ IsComplete "passenger_count" ]
分析器
在您知道關鍵資料欄,但可能對資料了解不夠而無法撰寫特定規則時,您可以使用分析器監控這些資料欄。分析器是一種無需定義明確規則即可收集資料統計資料的方式。設定分析器的範例如下所示:
Analyzers = [ AllStatistics "fare_amount", DistinctValuesCount "pulocationid", RowCount ]
在此範例中,設定三個分析器:
-
第一個分析器 `AllStatistics "fare_amount"` 會擷取 `fare_amount` 欄位的所有可用統計資料。
-
第二個分析器 `DistinctValuesCount "pulocationid"` 會擷取 `pulocationid` 資料欄中不同值的計數。
-
第三個分析器 `RowCount` 會擷取資料集中的記錄總數。
分析器是一種無需指定複雜規則即可收集相關資料統計資料的方式。透過監控這些統計資料,您可以深入了解資料品質,並識別可能需要進一步調查或建立特定規則的潛在問題或異常。
資料統計資料
Glue Data Quality AWS 中的分析器和規則都會收集資料統計資料,也稱為資料設定檔。這些統計資料可讓您深入了解資料的特性和品質。收集的統計資料會隨時間儲存在 Glue AWS 服務中,可讓您追蹤和分析資料設定檔中的變更。
您可以輕鬆擷取這些統計資料,並透過調用適當的 APIs 將其寫入 Amazon S3 以供進一步分析或長期儲存。此功能可讓您將資料效能分析整合到資料處理工作流程中,並利用收集的統計資料用於各種目的,例如資料品質監控、異常偵測。
透過將資料設定檔儲存在 Amazon S3 中,您可以利用 Amazon 物件儲存服務的可擴展性、耐久性和成本效益。此外,您可以利用 AWS 其他服務或第三方工具來分析和視覺化資料設定檔,讓您深入了解資料品質,並做出有關資料管理和管控的明智決策。
以下是一段時間內儲存的資料統計資料範例。
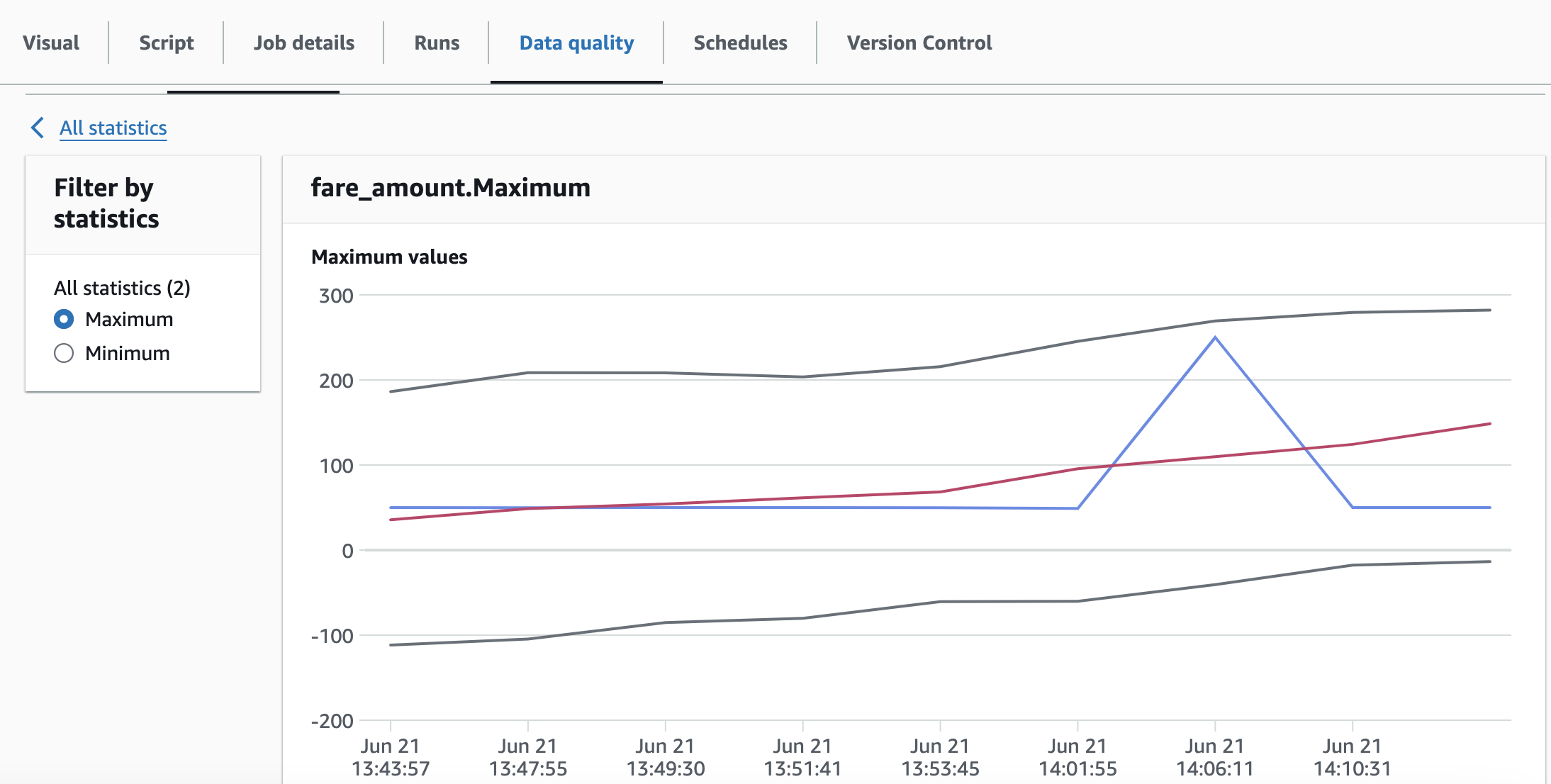
注意
AWS Glue Data Quality 只會收集一次統計資料,即使您同時擁有相同資料欄的 Rule 和 Analyzer,也可讓統計資料產生程序更有效率。
異常偵測
AWS Glue Data Quality 需要至少三個資料點才能偵測異常。其利用機器學習演算法從過去的趨勢中學習,然後預測未來的價值。當實際值不在預測範圍內時, AWS Glue Data Quality 會建立異常觀察。其提供實際值和趨勢的視覺化呈現。下面的圖表顯示了四個值。
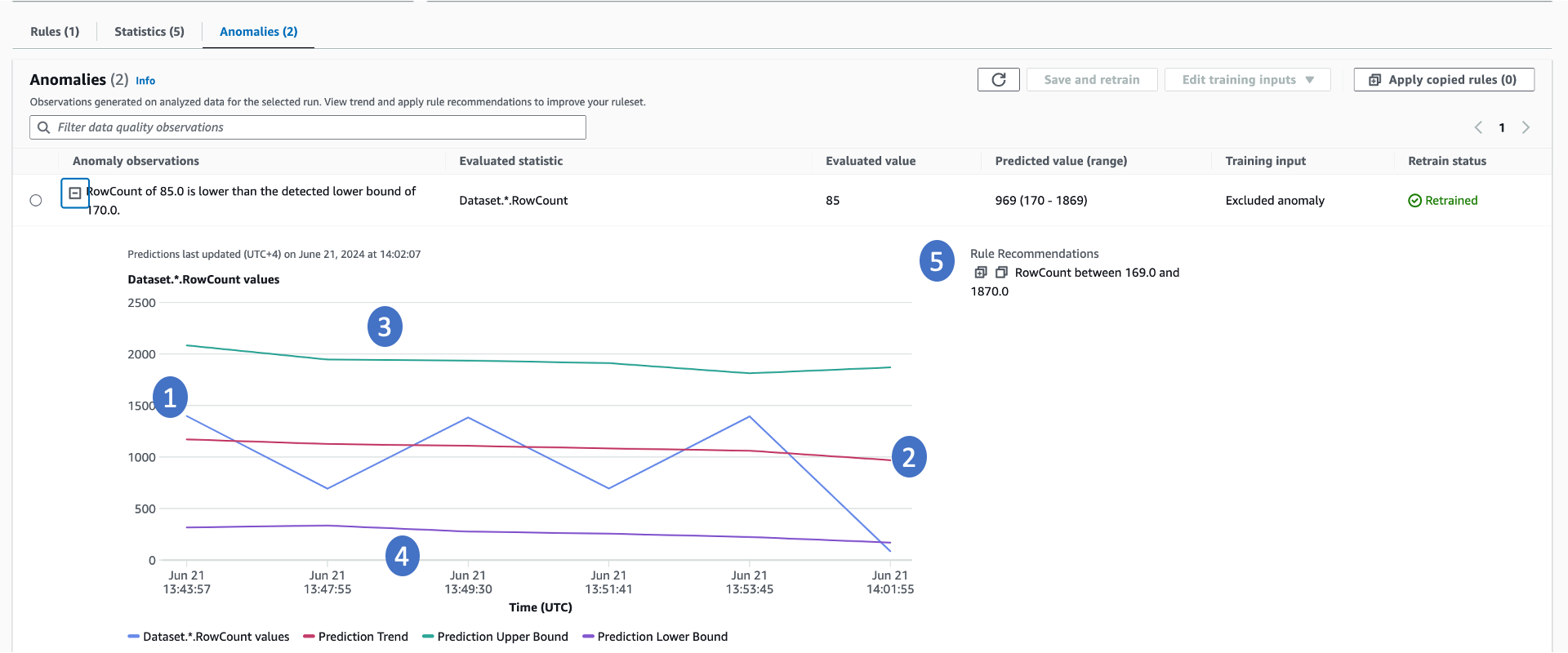
-
實際統計資料及其隨著時間變化的趨勢。
-
透過從實際趨勢中學習衍生的趨勢。這有助於了解趨勢方向。
-
統計資料的可能上限。
-
統計資料的可能下限。
-
建議的資料品質規則,可在未來偵測這些問題。
關於異常,有幾個重要事項需要注意:
-
在產生異常時,資料品質分數不會受到影響。
-
在偵測到異常時,後續執行會視為正常。除非明確排除,否則機器學習演算法會將此異常值視為輸入。
重新訓練
重新訓練異常偵測模型對於偵測正確的異常至關重要。偵測到異常時, AWS Glue Data Quality 會將模型中的異常納入為正常值。為了確保異常偵測可正確運作,請務必透過確認或拒絕異常來提供意見回饋。 AWS Glue Data Quality 在 Glue Studio 和 APIs AWS 中提供機制,以向模型提供意見回饋。若要進一步了解,請參閱在 Glue ETL AWS 管道中設定異常偵測的文件。
異常偵測演算法的詳細資訊
-
異常偵測演算法會檢查一段時間內的資料統計資料。演算法會考慮所有可用的資料點,並忽略明確排除的任何統計資料。
-
這些資料統計資料會存放在 AWS Glue 服務中,您可以提供用於加密它們的 AWS KMS 金鑰。請參閱 安全指南,了解如何提供 AWS KMS 金鑰來加密 Glue Data Quality AWS 統計資料。
-
時間元件對於異常偵測演算法至關重要。根據過去的值, AWS Glue Data Quality 會決定上限和下限。在此判斷期間,其會考慮時間元件。在一分鐘間隔、每小時間隔或每日間隔內,相同值的限制會有所不同。
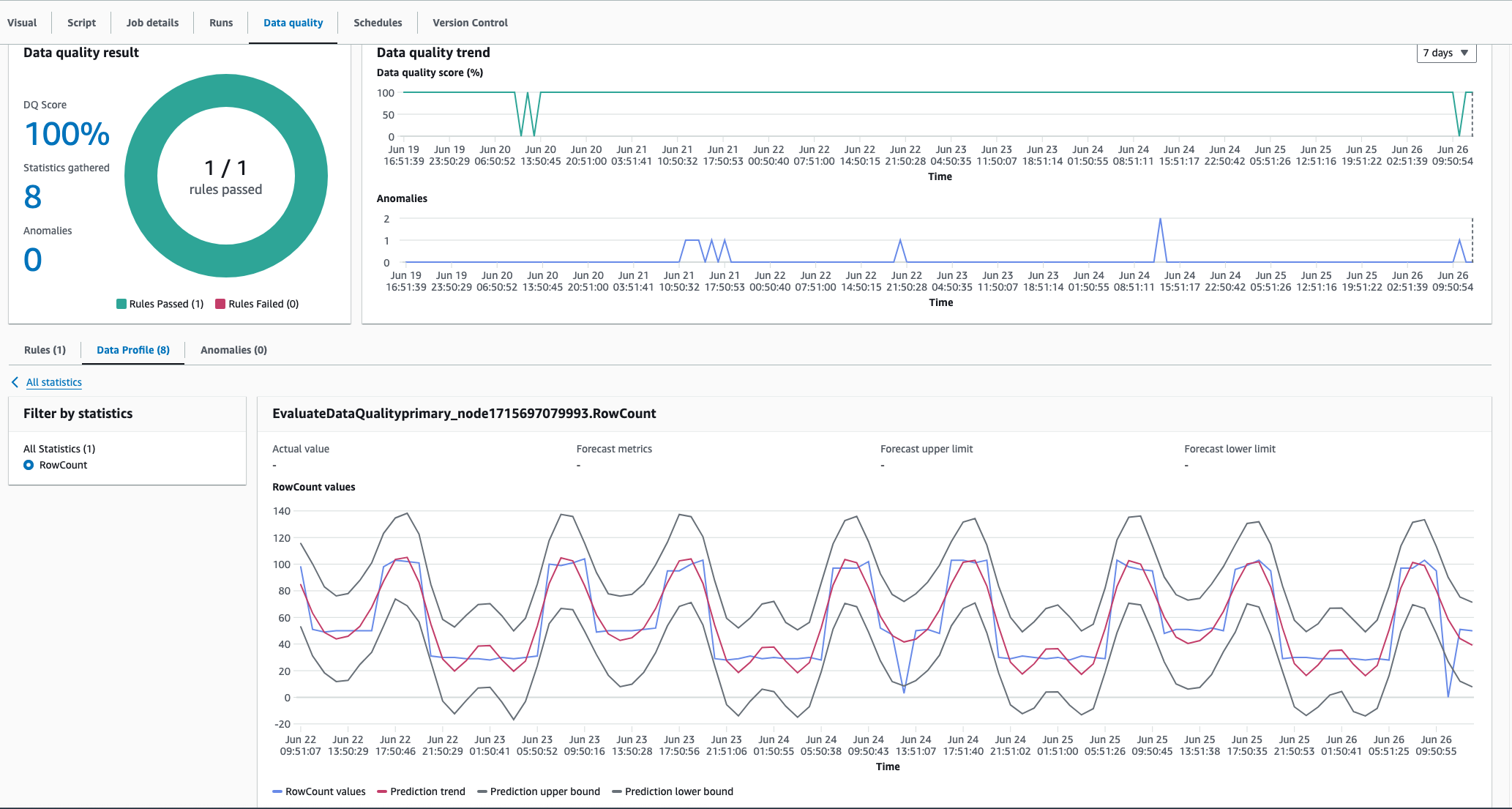
擷取季節性
AWS Glue Data Quality 的異常偵測演算法可以擷取季節性模式。例如,其可以了解工作日模式與週末模式不同。這可在以下範例中看到,其中 AWS Glue Data Quality 偵測到資料值中的季節性趨勢。您不需要執行任何特定動作即可啟用此功能。隨著時間的推移, AWS Glue Data Quality 會學習季節性趨勢,並在這些模式中斷時偵測異常。
Cost
您需要根據偵測異常所需的時間付費。每個統計資料都會針對偵測異常所需的時間收取 1 個 DPU。如需詳細範例,請參閱 AWS Glue 定價
關鍵考量
儲存統計資料無需任何成本。但是,每個帳戶的統計資料限制為 10 萬條。這些統計資料最多會儲存兩年。
