本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
使用自己的 JDBC 驅動程式新增 JDBC 連線
使用 JDBC 連線時,您可以使用自己的 JDBC 驅動程式。當 AWS Glue 爬蟲程式使用的預設驅動程式無法連線至資料庫時,您可以使用自己的 JDBC 驅動程式。例如,如果您想將 SHA-256 與 Postgres 資料庫搭配使用,而較舊的 Postgres 驅動程式不支援此功能,則可以使用自己的 JDBC 驅動程式。
支援的資料來源
| 支援的資料來源 | 不支援的資料來源 |
|---|---|
| MySQL | Snowflake |
| Postgres | |
| Oracle | |
| Redshift | |
| SQL Server | |
| Aurora* |
* 如果正在使用原生的 JDBC 驅動程式,則支援此功能。並非所有驅動程式功能都可供運用。
將 JDBC 驅動程式新增至 JDBC 連線
注意
如果您選擇使用自己的 JDBC 驅動程式版本, AWS Glue 爬蟲程式將使用 AWS Glue 任務和 Amazon S3 儲存貯體中的資源,以確保您提供的驅動程式在您的環境中執行。帳戶中將反映資源的額外使用量。 AWS Glue 爬蟲程式和任務的成本在計費中的 AWS Glue 類別下。此外,提供您的 JDBC 驅動程式,並不代表爬蟲程式能夠運用驅動程式的所有功能。
若要將自己的 JDBC 驅動程式新增至 JDBC 連線:
-
將 JDBC 驅動程式檔案新增至 Amazon S3 位置。您可以建立儲存貯體和/或資料夾,或使用現有的儲存貯體和/或資料夾。
-
在 AWS Glue 主控台中,選擇 Data Catalog 下左側選單中的連線,然後建立新的連線。
-
填寫連線屬性欄位,然後選擇 JDBC 作為連線類型。
-
在連線存取中,輸入 JDBC URL 和 JDBC 驅動程式類別名稱:選用。驅動程式類別名稱必須是 AWS Glue 爬蟲程式支援的資料來源。
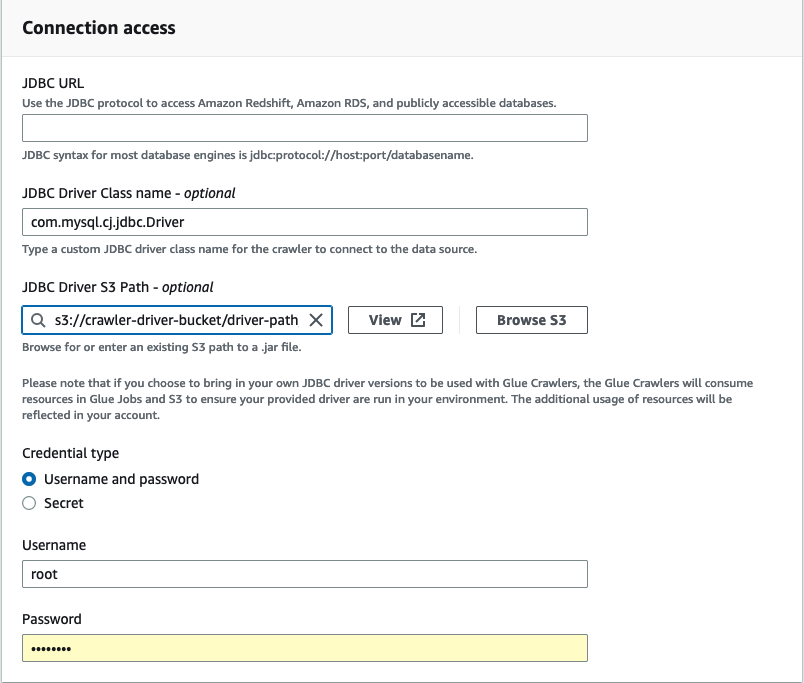
-
選擇 JDBC 驅動程式 Amazon S3 路徑中 JDBC 驅動程式所在的 Amazon S3 路徑:選用欄位。
-
如果輸入使用者名稱和密碼或機密,請填寫「憑證」類型的欄位。完成時,選擇建立連線。
注意
目前不支援測試連線。使用您提供的 JDBC 驅動程式針對資料來源進行網路爬取時,爬蟲程式會略過此步驟。
-
將新建立的連線新增至爬蟲程式。在 AWS Glue 主控台中,選擇 Data Catalog 下左側選單中的爬蟲程式,然後建立新的爬蟲程式。
-
在新增爬蟲程式精靈的步驟 2 中,選擇新增資料來源。

-
選擇 JDBC 作為資料來源,然後選擇在先前步驟中建立的連線。完成
-
為了搭配 AWS Glue 爬蟲程式使用您自己的 JDBC 驅動程式,請將下列許可新增至爬蟲程式使用的角色:
-
授予下列任務動作的許可:
CreateJob、DeleteJob、GetJob、GetJobRun、StartJobRun。 -
授予 IAM 動作的許可:
iam:PassRole -
授予 Amazon S3 動作的許可:
s3:DeleteObjects、s3:GetObject、s3:ListBucket、s3:PutObject。 -
在 IAM 政策中授予服務主體對儲存貯體/資料夾的存取權。
IAM 政策範例:
AWS Glue 爬蟲程式會建立兩個資料夾:_glue_job_crawler 和 _crawler。
如果驅動程式 jar 位於
s3://amzn-s3-demo-bucket/driver.jar"資料夾中,請新增下列資源:"Resource": [ "arn:aws:s3:::amzn-s3-demo-bucket/_glue_job_crawler/*", "arn:aws:s3:::amzn-s3-demo-bucket/_crawler/*" ]如果驅動程式 jar 位於
s3://amzn-s3-demo-bucket/tmp/driver/subfolder/driver.jar"資料夾中,請新增下列資源:"Resource": [ "arn:aws:s3:::amzn-s3-demo-bucket/tmp/_glue_job_crawler/*", "arn:aws:s3:::amzn-s3-demo-bucket/tmp/_crawler/*" ] -
-
如果您使用的是 VPC,則必須建立介面 AWS Glue 端點並將其新增至路由表,以允許存取端點。如需詳細資訊,請參閱建立 的介面 VPC 端點 AWS Glue
-
如果您在 Data Catalog 中使用加密,請建立 AWS KMS 介面端點並將其新增至您的路由表。如需詳細資訊,請參閱為 AWS KMS建立 VPC 端點。
