本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
教學課程:撰寫 Glue for Spark AWS 指令碼
本教學課程向您介紹撰寫 Glue AWS 指令碼的程序。您可以按照任務的排程執行指令碼,也可以與互動式工作階段互動執行。如需任務的詳細資訊,請參閱建置視覺化的 ETL 任務。如需互動式工作階段的詳細資訊,請參閱AWS Glue 互動式工作階段概觀。
Glue Studio AWS 視覺化編輯器提供圖形化、無程式碼的界面,用於建置 AWS Glue 任務。 AWS Glue 指令碼會傳回視覺化任務。您可透過這些指令碼存取一組經過擴增的工具,這些工具能與 Apache Spark 程式搭配運作。您可以存取原生 Spark APIs,以及促進從 AWS Glue 指令碼內擷取、轉換和載入 (ETL) 工作流程的 AWS Glue 程式庫。
本教學課程中,您會擷取、轉換及載入違停罰單資料集。執行此工作的指令碼與 AWS 大數據部落格上使用 AWS Glue Studio 讓 ETL 更容易
在本教學課程中,您將使用 Python 語言和程式庫。類似的功能在 Scala 中可用。完成本教學課程後,您應該能夠產生並檢查範例 Scala 指令碼,以了解如何執行 Scala AWS Glue ETL 指令碼撰寫程序。
先決條件
本教學課程具備下列先決條件:
-
與 AWS Glue Studio 部落格文章相同的先決條件,它會指示您執行 CloudFormation 範本。
此範本使用 AWS Glue Data Catalog 來管理 中可用的停車票證資料集
s3://aws-bigdata-blog/artifacts/gluestudio/。它建立將被引用以下資源: -
AWS Glue StudioRole:要執行 AWS Glue 任務的 IAM 角色
-
AWS Glue StudioAmazon S3Bucket:儲存部落格相關檔案的 Amazon S3 儲存貯體名稱
-
AWS Glue StudioTicketsYYZDB:AWS Glue Data Catalog 資料庫
-
AWS Glue StudioTableTickets:用作來源的 Data Catalog 資料表
-
AWS Glue StudioTableTrials:用作來源的 Data Catalog 資料表
-
AWS Glue StudioParkingTicketCount:用作目的地的 Data Catalog 資料表
-
Glue Studio AWS 部落格文章中產生的指令碼。如果部落格文章變更,指令碼在下列文字中同樣可用。
產生範例指令碼
您可以使用 AWS Glue Studio 視覺化編輯器做為強大的程式碼產生工具,為您要寫入的指令碼建立 scaffold。您將使用此工具建立範例指令碼。
如果您想跳過這些步驟,系統會提供指令碼。
import sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job args = getResolvedOptions(sys.argv, ["JOB_NAME"]) sc = SparkContext() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) job.init(args["JOB_NAME"], args) # Script generated for node S3 bucket S3bucket_node1 = glueContext.create_dynamic_frame.from_catalog( database="yyz-tickets", table_name="tickets", transformation_ctx="S3bucket_node1" ) # Script generated for node ApplyMapping ApplyMapping_node2 = ApplyMapping.apply( frame=S3bucket_node1, mappings=[ ("tag_number_masked", "string", "tag_number_masked", "string"), ("date_of_infraction", "string", "date_of_infraction", "string"), ("ticket_date", "string", "ticket_date", "string"), ("ticket_number", "decimal", "ticket_number", "float"), ("officer", "decimal", "officer_name", "decimal"), ("infraction_code", "decimal", "infraction_code", "decimal"), ("infraction_description", "string", "infraction_description", "string"), ("set_fine_amount", "decimal", "set_fine_amount", "float"), ("time_of_infraction", "decimal", "time_of_infraction", "decimal"), ], transformation_ctx="ApplyMapping_node2", ) # Script generated for node S3 bucket S3bucket_node3 = glueContext.write_dynamic_frame.from_options( frame=ApplyMapping_node2, connection_type="s3", format="glueparquet", connection_options={"path": "s3://DOC-EXAMPLE-BUCKET", "partitionKeys": []}, format_options={"compression": "gzip"}, transformation_ctx="S3bucket_node3", ) job.commit()
產生範例指令碼
-
完成 AWS Glue Studio 教學課程。若要完成本教學課程,請參閱從範例任務在 Glue Studio AWS 中建立任務。
-
導覽至任務頁面上的 Script (指令碼) 索引標籤,如以下螢幕擷取畫面所示:
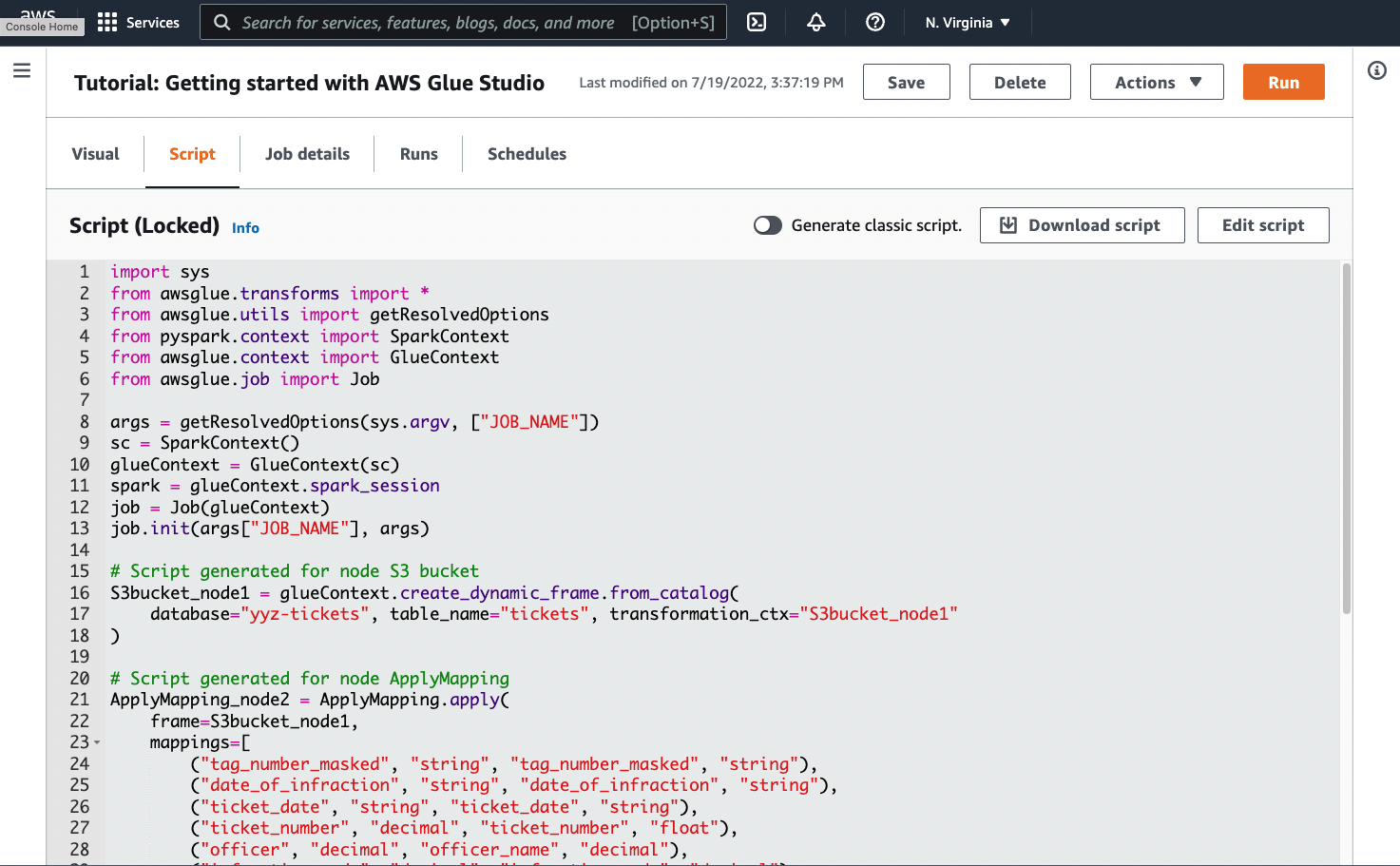
-
複製 Script (指令碼) 索引標籤中的完整內容。透過在 Job details (任務詳細資訊) 中設定指令碼語言,您可以在產生 Python 程式碼或 Scala 程式碼之間來回切換。
步驟 1. 建立任務並貼上指令碼
在此步驟中,您會在 中建立 AWS Glue 任務 AWS 管理主控台。這會設定允許 AWS Glue 執行指令碼的組態。此操作還會為您建立一個存放和編輯指令碼的地方。
建立任務
-
在 中 AWS 管理主控台,導覽至 AWS Glue 登陸頁面。
-
在側邊的導覽窗格中,選擇 Jobs (任務)。
-
在 Create job (建立任務) 中選擇 Spark script editor (Spark 指令碼編輯器),接著選擇 Create (建立)。
-
選用 – 將指令碼的完整文字貼入 Script (指令碼) 窗格中。或者,您可以按照教學課程進行操作。
步驟 2. 匯入 AWS Glue 程式庫
您需要設定指令碼,使其與在指令碼外部定義的程式碼和組態互動。此工作會在 Glue Studio AWS 的幕後完成。
在此步驟中,您會執行下列動作。
-
匯入並初始化
GlueContext物件。從指令碼編寫的角度來看,這是最重要的匯入。這會公開定義來源和目標資料集所使用的標準方法,也就是任何 ETL 指令碼的起點。若要進一步了解GlueContext類別,請參閱 GlueContext 類別。 -
初始化
SparkContext和SparkSession。這些可讓您設定 Glue 任務中可用的 Spark AWS 引擎。您不需要直接在 Glue AWS 指令碼簡介中使用這些指令碼。 -
呼叫
getResolvedOptions,準備您的任務參數以在指令碼內使用。如需有關解析任務參數的詳細資訊,請參閱 使用 getResolvedOptions 存取參數。 -
初始化
Job。Job物件會設定組態並追蹤各種選用 Glue AWS 功能的狀態。您的指令碼可以在沒有Job物件的情況下執行,但最佳實務是將其初始化,以免之後整合這些功能時造成混淆。其中一項功能是任務書籤,您可以在此教學課程中選擇性地設定該功能。您可以在以下章節中了解有關任務書籤的資訊:選用 – 啟用任務書籤。
在此程序中,您需編寫下列程式碼。此程式碼是產生的範例指令碼的一部分。
from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job args = getResolvedOptions(sys.argv, ["JOB_NAME"]) sc = SparkContext() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) job.init(args["JOB_NAME"], args)
匯入 AWS Glue 程式庫
-
複製此段程式碼並貼入 Script (指令碼) 編輯器中。
注意
您或許會認為,複製程式碼是一種不好的工程實務。在本教學課程中,我們建議您一致地命名所有 Glue ETL AWS 指令碼的核心變數。
步驟 3。從來源擷取資料
在任何 ETL 程序中,您都需要先定義要變更的來源資料集。在 AWS Glue Studio 視覺化編輯器中,您可以透過建立來源節點來提供此資訊。
在此步驟中,您需為 create_dynamic_frame.from_catalog 方法提供 database 和 table_name,以便從 AWS Glue 資料目錄所設定的來源擷取資料。
在先前的步驟中,您已初始化 GlueContext 物件。您可以使用此物件來尋找設定來源所需使用的方法,例如 create_dynamic_frame.from_catalog。
在此程序中,您需使用 create_dynamic_frame.from_catalog 編寫下列程式碼。此程式碼是產生的範例指令碼的一部分。
S3bucket_node1 = glueContext.create_dynamic_frame.from_catalog( database="yyz-tickets", table_name="tickets", transformation_ctx="S3bucket_node1" )
從來源擷取資料
-
檢查 文件,在 上尋找從 Glue Data Catalog AWS 中定義的來源
GlueContext擷取資料的方法。這些方法記錄於 GlueContext 類別。選擇 create_dynamic_frame.from_catalog 方法。在glueContext上呼叫此方法。 -
檢查
create_dynamic_frame.from_catalog的文件。此方法需要database和table_name參數。為create_dynamic_frame.from_catalog提供必要的參數。Glue Data Catalog AWS 會儲存來源資料的位置和格式相關資訊,並在先決條件區段中設定。您不必直接為指令碼提供該資訊。
-
選用 – 為該方法提供
transformation_ctx參數,以支援任務書籤。您可以在以下章節中了解有關任務書籤的資訊:選用 – 啟用任務書籤。
注意
擷取資料的常用方法
create_dynamic_frame_from_catalog 用於連接到 Glue Data Catalog AWS 中的資料表。
如果您需要直接為任務提供描述來源結構和位置的組態,請參閱 create_dynamic_frame_from_options 方法。您需要提供比使用 create_dynamic_frame.from_catalog 時更詳細的參數以描述您的資料。
請參閱有關 format_options 和 connection_parameters 的補充文件來識別所需參數。有關如何提供關於來源資料格式的指令碼資訊的說明,請參閱 AWS Glue for Spark 中的輸入與輸出的資料格式選項。有關如何提供關於來源資料位置的指令碼資訊的說明,請參閱 AWS Glue for Spark 中 ETL 的連線類型和選項。
如果您要從串流來源讀取資訊,您可以透過 create_data_frame_from_catalog 或 create_data_frame_from_options 方法為任務提供來源資訊。請注意,這些方法會傳回 Apache Spark DataFrames。
儘管參考文件參考的是 create_dynamic_frame_from_catalog,但產生的程式碼會呼叫 create_dynamic_frame.from_catalog。這些方法最終會呼叫相同的程式碼,並包含在內,以便您可以編寫更簡潔的程式碼。您可以檢視 Python 包裝函式的來源,藉以確認這一點,該包裝函式可在 aws-glue-libs
步驟 4. 使用 Glue AWS 轉換資料
在 ETL 程序中擷取來源資料後,您需要說明要如何變更資料。您可以在 Glue Studio AWS 視覺化編輯器中建立轉換節點,以提供此資訊。
在此步驟中,您需為 ApplyMapping 方法提供目前所需欄位名稱和類型的映射,以轉換您的 DynamicFrame。
執行以下轉換。
-
捨棄這四個
location和province索引鍵。 -
將
officer的名稱變更為officer_name。 -
將
ticket_number和set_fine_amount的類型變更為float。
create_dynamic_frame.from_catalog 將為您提供 DynamicFrame 物件。DynamicFrame 代表 Glue AWS 中的資料集。 AWS Glue 轉換是變更 的操作DynamicFrames。
注意
什麼是 DynamicFrame?
DynamicFrame 是一種抽象,允許您連接資料集,該資料集中包含資料中項目的名稱和類型的描述。Apache Spark 中存在類似的抽象,稱為 DataFrame。如需 DataFrame 的說明,請參閱 Spark SQL Guide
DynamicFrames 可讓您動態描述資料集結構描述。考慮具有價格欄的資料集,其中某些項目將價格儲存為字串,而其他項目則將價格儲存為雙重。 AWS Glue on-the-fly運算結構描述,它會為每個資料列建立自我描述記錄。
不一致的欄位 (如價格) 在框架結構描述中用類型 (ChoiceType) 明確表示。您可以使用 DropFields 捨棄不一致的欄位,或使用 ResolveChoice 來解析欄位,藉以處理欄位不一致的問題。這些轉換可從 DynamicFrame 取得。然後,您可以使用 writeDynamicFrame 將資料寫回資料湖。
您可以從 DynamicFrame 類別上的方法呼叫許多相同的轉換,這樣可以得到更具可讀性的指令碼。如需 DynamicFrame 的相關資訊,請參閱 DynamicFrame 類別。
在此程序中,您需使用 ApplyMapping 編寫下列程式碼。此程式碼是產生的範例指令碼的一部分。
ApplyMapping_node2 = ApplyMapping.apply( frame=S3bucket_node1, mappings=[ ("tag_number_masked", "string", "tag_number_masked", "string"), ("date_of_infraction", "string", "date_of_infraction", "string"), ("ticket_date", "string", "ticket_date", "string"), ("ticket_number", "decimal", "ticket_number", "float"), ("officer", "decimal", "officer_name", "decimal"), ("infraction_code", "decimal", "infraction_code", "decimal"), ("infraction_description", "string", "infraction_description", "string"), ("set_fine_amount", "decimal", "set_fine_amount", "float"), ("time_of_infraction", "decimal", "time_of_infraction", "decimal"), ], transformation_ctx="ApplyMapping_node2", )
使用 Glue AWS 轉換資料
-
檢查文件以識別要變更和捨棄欄位的轉換。如需詳細資訊,請參閱GlueTransform base 類別。選擇
ApplyMapping轉換。如需ApplyMapping的相關資訊,請參閱 ApplyMapping 類別。在ApplyMapping轉換物件上呼叫apply。注意
什麼是
ApplyMapping?ApplyMapping採用DynamicFrame並對其進行轉換。這需使用代表欄位轉換的元組清單,亦即「映射」。前兩個元組元素 (欄位名稱和類型) 用於識別框架中的欄位。第二對參數同樣是欄位名稱和類型。ApplyMapping 會以其傳回的新
DynamicFrame,將來源欄位轉換為目標名稱和類型。未提供的欄位會在傳回值中遭到捨棄。您可以呼叫與
DynamicFrame上的apply_mapping方法相同的轉換 (而不必呼叫apply) 來建立更流暢、更易讀的程式碼。如需詳細資訊,請參閱apply_mapping。 -
檢查
ApplyMapping的文件以識別所需參數。請參閱 ApplyMapping 類別。您會發現此方法需要frame和mappings參數。為ApplyMapping提供必要的參數。 -
選用 – 為該方法提供
transformation_ctx,以支援任務書籤。您可以在以下章節中了解有關任務書籤的資訊:選用 – 啟用任務書籤。
注意
步驟 5. 將資料載入目標
轉換資料之後,通常需將轉換後的資料存放在與來源不同的地方。您可以在 Glue Studio AWS 視覺化編輯器中建立目標節點來執行此操作。
在此步驟中,您需為 write_dynamic_frame.from_options 方法提供 connection_type、connection_options、format 和 format_options,將資料載入 Amazon S3 中的目標儲存貯體。
在步驟 1 中,您初始化了 GlueContext 物件。在 AWS Glue 中,您可以找到用來設定目標的方法,就像來源一樣。
在此程序中,您需使用 write_dynamic_frame.from_options 編寫下列程式碼。此程式碼是產生的範例指令碼的一部分。
S3bucket_node3 = glueContext.write_dynamic_frame.from_options( frame=ApplyMapping_node2, connection_type="s3", format="glueparquet", connection_options={"path": "s3://amzn-s3-demo-bucket", "partitionKeys": []}, format_options={"compression": "gzip"}, transformation_ctx="S3bucket_node3", )
將資料載入目標
-
檢查文件,查找將資料載入目標 Amazon S3 儲存貯體的方法。這些方法記錄於 GlueContext 類別。選擇 write_dynamic_frame_from_options 方法。在
glueContext上呼叫此方法。注意
常用資料載入方法
write_dynamic_frame.from_options是最常用的資料載入方法,它支援 Glue AWS 中提供的所有目標。如果您要寫入 Glue AWS 連線中定義的 JDBC 目標,請使用 write_dynamic_frame_from_jdbc_conf方法。 AWS Glue 連線會儲存有關如何連線至資料來源的資訊。如此一來,您就不需在
connection_options提供該資訊,不過您仍然需要使用connection_options來提供dbtable。write_dynamic_frame.from_catalog不是常用的資料載入方法。此方法會在不更新基礎資料集的情況下更新 AWS Glue Data Catalog,並與其他變更基礎資料集的程序結合使用。如需詳細資訊,請參閱使用 AWS Glue ETL 任務,在 Data Catalog 中更新結構描述並新增新的分區。 -
檢查 write_dynamic_frame_from_options 的文件。此方法需要
frame、connection_type、format、connection_options和format_options。在glueContext上呼叫此方法。-
請參閱有關
format_options和format的補充文件以識別您需要的參數。如需資料格式的說明,請參閱 AWS Glue for Spark 中的輸入與輸出的資料格式選項。 -
請參閱有關
connection_type和connection_options的補充文件以識別您需要的參數。如需連線的說明,請參閱 AWS Glue for Spark 中 ETL 的連線類型和選項。 -
為
write_dynamic_frame.from_options提供必要的參數。此方法的組態與create_dynamic_frame.from_options類似。
-
-
選用 – 向
write_dynamic_frame.from_options提供transformation_ctx,以支援任務書籤。您可以在以下章節中了解有關任務書籤的資訊:選用 – 啟用任務書籤。
步驟 6. 遞交 Job 物件
您在步驟 1 中初始化了 Job 物件。如果某些選用功能需要此功能才能正常運作 (例如在使用任務書籤時),您可能需要在指令碼結尾處手動斷定其生命週期。此工作會在 Glue Studio AWS 的幕後完成。
在此步驟中,在 Job 物件上呼叫 commit 方法。
在此程序中,您需編寫下列程式碼。此程式碼是產生的範例指令碼的一部分。
job.commit()
遞交 Job 物件
-
如果您尚未執行此操作,請執行先前章節中概述的選用步驟,將
transformation_ctx納入其中。 -
呼叫
commit。
選用 – 啟用任務書籤
之前的每個步驟都已經指示您設定 transformation_ctx 參數。這與名為任務書籤的功能有關。
藉由任務書籤,您可針對資料集定期執行任務,達到節省時間和金錢的目的,同時還能輕鬆追蹤先前的工作。任務書籤會追蹤從先前執行跨資料集的 AWS Glue 轉換進度。透過追蹤先前執行的結束位置, AWS Glue 可以將工作限制為之前未處理的資料列。如需任務書籤的詳細資訊,請參閱 使用任務書籤追蹤處理的資料。
若要啟用任務書籤,請先新增 transformation_ctx 陳述式至我們所提供的函數,如之前的範例所述。任務書籤狀態會在執行期間維持不變,而 transformation_ctx 參數是存取該狀態所需的索引鍵。這些陳述式自身不會執行任何操作。您還需要在任務的組態中啟用該功能。
在此程序中,您會使用 AWS 管理主控台啟用任務書籤。
啟用任務書籤
-
導覽至相應任務的 Job details (任務詳細資訊) 一節。
-
將 Job bookmark (任務書籤) 設定為 Enable (啟用)。
步驟 7. 將程式碼作為任務執行
在此步驟中,您需執行任務以確認您是否已成功完成本教學課程。按一下按鈕即可完成此操作,如 Glue Studio AWS 視覺化編輯器所示。
將程式碼作為任務執行
-
在標題列上選擇 Untitled job (未命名任務) 以編輯和設定您的任務名稱。
-
導覽至 Job details (任務詳細資訊) 索引標籤。為您的任務指派 IAM Role (IAM 角色)。您可以在 AWS Glue Studio 教學課程的先決條件中使用 CloudFormation 範本建立的 。如果您已完成該教學課程,則該角色應可用,名為
AWS Glue StudioRole。 -
選擇 Save (儲存) 以儲存您的指令碼。
-
選擇 Run (執行) 以執行您的任務。
-
導覽至 Runs (執行) 索引標籤,以確認您的任務已完成。
-
導覽至
amzn-s3-demo-bucket(write_dynamic_frame.from_options的目標)。確認輸出符合您的期望。
如需有關設定和管理任務的詳細資訊,請參閱 提供您的自訂指令碼。
其他資訊
Apache Spark 程式庫和方法可在 Glue AWS 指令碼中使用。您可以查看 Spark 文件以了解您可以使用這些包含的程式庫來做什麼。如需詳細資訊,請參閱 Spark 來源儲存庫的範例區段
AWS Glue 2.0+ 預設包含數個常見的 Python 程式庫。也有機制可將您自己的相依性載入 Scala 或 Python 環境中的 AWS Glue 任務。如需 Python 相依性的相關資訊,請參閱 搭配 Glue 使用 Python AWS 程式庫。
如需如何在 Python 中使用 AWS Glue 功能的詳細資訊,請參閱 AWS Glue Python 程式碼範例。Scala 和 Python 任務具有相同的功能,所以我們的 Python 範例應能為您提供以 Scala 執行類似工作的些許想法。
