協助改進此頁面
本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
若要為本使用者指南貢獻內容,請點選每個頁面右側面板中的在 GitHub 上編輯此頁面連結。
本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
混合節點的 Kubernetes 概念
此頁面詳細說明支援 EKS 混合節點系統架構的重要 Kubernetes 概念。
VPC 中的 EKS 控制平面
EKS 控制平面 ENI 的 IP 會存放在 default 命名空間的 kubernetes Endpoints 物件中。當 EKS 建立新的 ENI 或移除較舊的 ENI 時,EKS 會更新此物件,以便 IP 清單永遠是保持最新。
您可以透過 kubernetes 服務使用這些端點,也可以在 default 命名空間中使用這些端點。此服務為 ClusterIP 類型,且一律會獲指派叢集服務 CIDR 的第一個 IP。例如,對於服務 CIDR 172.16.0.0/16,服務 IP 將為 172.16.0.1。
一般而言,這就是 Pod (無論是在雲端還是在混合節點中執行) 存取 EKS Kubernetes API 伺服器的方式。Pod 使用服務 IP 最為目的地 IP,且其會轉譯為其中一個 EKS 控制平面 ENI 的實際 IP。主要例外狀況是 kube-proxy,因為它會設定轉譯。
EKS API 伺服器端點
kubernetes 服務 IP 並非存取 EKS API 伺服器的唯一方式。當您建立叢集時,EKS 也會建立一個 Route53 DNS 名稱。這是呼叫 EKS DescribeCluster API 動作時 EKS 叢集的 endpoint 欄位。
{ "cluster": { "endpoint": "https://xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.gr7.us-west-2.eks.amazonaws.com", "name": "my-cluster", "status": "ACTIVE" } }
在公有端點存取或公有和私有端點存取叢集中,根據預設,您的混合節點會將此 DNS 名稱解析為公有 IP,且可透過網際網路路由。在私有端點存取叢集中,DNS 名稱會解析為 EKS 控制平面 ENI 的私有 IP。
這是 kubelet 和 kube-proxy 存取 Kubernetes API 伺服器的方式。如果您希望所有 Kubernetes 叢集流量流經 VPC,您需要以私有存取模式設定叢集,或修改內部部署 DNS 伺服器,以將 EKS 叢集端點解析為 EKS 控制平面 ENI 的私有 IP。
kubelet 端點
kubelet 會公開數個 REST 端點,從而允許系統的其他部分與每個節點互動並收集資訊。在大多數叢集中,前往 kubelet 伺服器的大多數流量都來自控制平面,但某些監控代理程式也可能會與其互動。
透過此介面,kubelet 會處理各種請求:擷取日誌 (kubectl logs)、在容器內執行命令 (kubectl exec) 以及連接埠轉送流量 (kubectl port-forward)。其中每個請求皆會透過 kubelet 與基礎容器執行時期互動,而對叢集管理員和開發人員來說,這似乎是無縫的。
此 API 最常見的取用者是 Kubernetes API 伺服器。當您使用上述任何 kubectl 命令時,kubectl 會向 API 伺服器發出 API 請求,然後呼叫執行 Pod 的節點的 kubelet API。這就是需要從 EKS 控制平面連接至節點 IP,以及即使您的 Pod 正在執行,如果節點路由設定錯誤,您也無法存取其日誌或 exec 的主要原因。
節點 IP
當 EKS 控制平面與節點通訊時,其會使用以 Node 物件狀態 (status.addresses) 回報的其中一個地址。
使用 EKS 雲端節點時,kubelet 通常會在節點註冊期間將 EC2 執行個體的私有 IP 報告為 InternalIP。然後,雲端控制器管理員 (CCM) 會驗證此 IP,進而確保其屬於 EC2 執行個體。此外,CCM 通常會將執行個體的公有 IP (例如 ExternalIP) 和 DNS 名稱 (InternalDNS 和 ExternalDNS) 新增至節點狀態。
不過,混合節點沒有 CCM。當您向 EKS 混合節點 CLI (nodeadm) 註冊混合節點時,它會將 kubelet 設定為在節點狀態中直接報告機器的 IP,且不需要 CCM。
apiVersion: v1 kind: Node metadata: name: my-node-1 spec: providerID: eks-hybrid:///us-west-2/my-cluster/my-node-1 status: addresses: - address: 10.1.1.236 type: InternalIP - address: my-node-1 type: Hostname
如果您的機器具有多個 IP,則 kubelet 會依照其自己的邏輯選取其中一個 IP。您可以使用 --node-ip 旗標來控制選取的 IP,而您可以在 spec.kubelet.flags 中的 nodeadm 組態內傳遞該旗標。只有 Node 物件中報告的 IP 需要來自 VPC 的路由。您的機器可能擁有無法從雲端連線的其他 IP。
kube-proxy
kube-proxy 負責在每個節點的網路層實作服務抽象。它可作為通往 Kubernetes Services 的流量的網路代理和負載平衡器。透過持續監看 Kubernetes API 伺服器中是否存在與服務和端點相關的變更,kube-proxy 會動態更新基礎主機的聯網規則,進而確保流量導向正確無誤。
在 iptables 模式中,kube-proxy 會設定數個 netfilter 鏈結來處理服務流量。這些規則可組成下列階層:
-
KUBE-SERVICES 鏈結:所有服務流量的進入點。它具有與每個服務的
ClusterIP和連接埠相符的規則。 -
KUBE-SVC-XXX 鏈結:服務特定鏈結針對每個服務都設有負載平衡規則。
-
KUBE-SEP-XXX 鏈結:端點特定鏈結設有實際
DNAT規則。
讓我們檢查 default 命名空間中服務 test-server 的情況:* 服務 ClusterIP:172.16.31.14 * 服務連接埠:80 * 支援 Pod:10.2.0.110、10.2.1.39 和 10.2.2.254
當我們檢查 iptables 規則時 (使用 iptables-save –0— grep -A10 KUBE-SERVICES):
-
在 KUBE-SERVICES 鏈結中,我們可找到與服務相符的規則:
-A KUBE-SERVICES -d 172.16.31.14/32 -p tcp -m comment --comment "default/test-server cluster IP" -m tcp --dport 80 -j KUBE-SVC-XYZABC123456-
此規則與目的地為 172.16.31.14:80 的封包相符
-
該註解指出此規則的用途:
default/test-server cluster IP -
相符的封包會跳至
KUBE-SVC-XYZABC123456鏈結
-
-
KUBE-SVC-XYZABC123456 鏈結設有機率型負載平衡規則:
-A KUBE-SVC-XYZABC123456 -m statistic --mode random --probability 0.33333333349 -j KUBE-SEP-POD1XYZABC -A KUBE-SVC-XYZABC123456 -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-POD2XYZABC -A KUBE-SVC-XYZABC123456 -j KUBE-SEP-POD3XYZABC-
第一項規則:33.3% 的機會跳至
KUBE-SEP-POD1XYZABC -
第二項規則:50% 的剩餘流量 (總計的 33.3%) 會跳至
KUBE-SEP-POD2XYZABC -
最後一項規則:所有剩餘的流量 (總計的 33.3%) 會跳至
KUBE-SEP-POD3XYZABC
-
-
個別 KUBE-SEP-XXX 鏈結會執行 DNAT (目的地 NAT):
-A KUBE-SEP-POD1XYZABC -p tcp -m tcp -j DNAT --to-destination 10.2.0.110:80 -A KUBE-SEP-POD2XYZABC -p tcp -m tcp -j DNAT --to-destination 10.2.1.39:80 -A KUBE-SEP-POD3XYZABC -p tcp -m tcp -j DNAT --to-destination 10.2.2.254:80-
這些 DNAT 規則會重寫目的地 IP 和連接埠,以將流量導向特定的 Pod。
-
每項規則可處理大約 33.3% 的流量,以便在
10.2.0.110、10.2.1.39和10.2.2.254之間提供均勻的負載平衡。
-
此多層級鏈結結構讓 kube-proxy 能夠透過核心層級封包操作高效實作服務負載平衡和重新導向,而不需要資料路徑中的代理。
對 Kubernetes 操作的影響
節點上中斷的 kube-proxy 可防止該節點正常路由服務流量,進而導致依賴叢集服務的 Pod 逾時或連線失敗。首次註冊節點時,這尤其會造成干擾。在設定任何 Pod 聯網之前,CNI 需要與 Kubernetes API 伺服器通訊以取得資訊,例如節點的 Pod CIDR。為此,它會使用 kubernetes 服務 IP。不過,如果 kube-proxy 無法啟動或無法設定正確的 iptables 規則,則傳送至 kubernetes 服務 IP 的請求不會轉譯為 EKS 控制平面 ENI 的實際 IP。因此,CNI 將進入損毀循環,而且任何 Pod 都無法正常執行。
我們知道 Pod 會使用 kubernetes 服務 IP 與 Kubernetes API 伺服器通訊,但 kube-proxy 需要先設定 iptables 規則才能讓其運作。
kube-proxy 如何與 API 伺服器通訊?
必須將 kube-proxy 設定為使用 Kubernetes API 伺服器的實際 IP 或解析為它們的 DNS 名稱。若為 EKS,則 EKS 會將預設的 kube-proxy 設定為指向 EKS 在您建立叢集時建立的 Route53 DNS 名稱。您可以在 kube-system 命名空間的 kube-proxy ConfigMap 中看到此值。此 ConfigMap 的內容是注入 kube-proxy Pod 中的 kubeconfig,因此請尋找 clusters–0—.cluster.server 欄位。此值將與您 EKS 叢集的 endpoint 欄位相符 (呼叫 EKS DescribeCluster API 時)。
apiVersion: v1 data: kubeconfig: |- kind: Config apiVersion: v1 clusters: - cluster: certificate-authority: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt server: https://xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.gr7.us-west-2.eks.amazonaws.com name: default contexts: - context: cluster: default namespace: default user: default name: default current-context: default users: - name: default user: tokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token kind: ConfigMap metadata: name: kube-proxy namespace: kube-system
可路由的遠端 Pod CIDR
此 混合節點的聯網概念 頁面會詳細說明在混合節點上執行 Webhook 或讓在雲端節點上執行的 Pod 與在混合節點上執行的 Pod 進行通訊的需求。關鍵要求是,內部部署路由器需要知道哪個節點負責特定的 Pod IP。有幾種方法可以實現這一點,包括邊界閘道協定 (BGP)、靜態路由和位址解析通訊協定 (ARP) 代理。詳細方法請參閱下列各節。
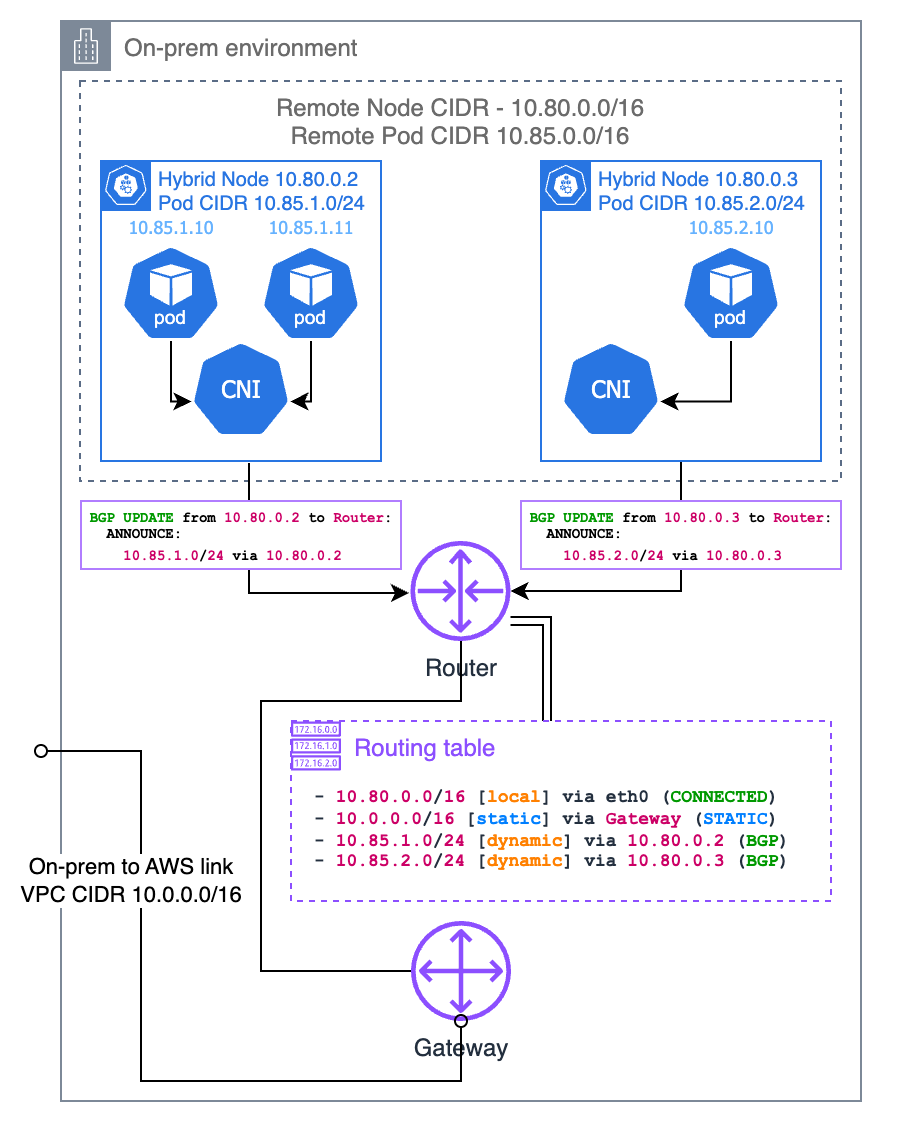
邊界閘道協定 (BGP)
如果您的 CNI 對其提供支援 (例如 Cilium 和 Calico),您可以使用 CNI 的 BGP 模式,以將路由傳播到每個節點的 Pod CIDR (從節點到本機路由器)。使用 CNI 的 BGP 模式時,您的 CNI 可作為虛擬路由器,因此您的本機路由器會認為 Pod CIDR 屬於不同的子網路,而您的節點是該子網路的閘道。
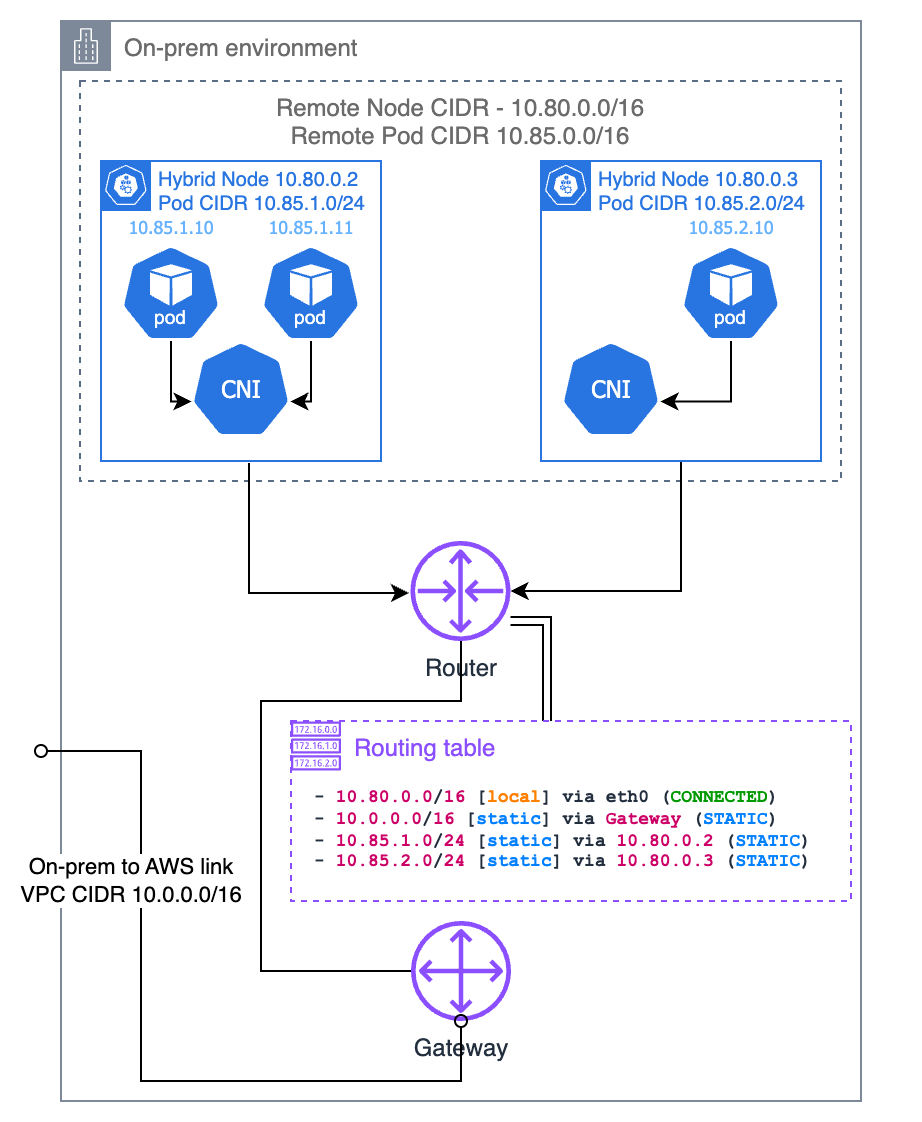
靜態路由
或者,您可以在本機路由器中設定靜態路由。這是將內部部署 Pod CIDR 路由至 VPC 的最簡單方法,但這也是最容易出錯且難以維護的方法。您需要確保路由始終與現有節點及其指派的 Pod CIDR 保持同步。如果您的節點數量很小且基礎結構為靜態,則此方案可行,並且不需要路由器中的 BGP 支援。如果您選擇此方案,那麼建議您使用要指派給每個節點的 Pod CIDR 配量來設定 CNI,而不是讓其 IPAM 決定。
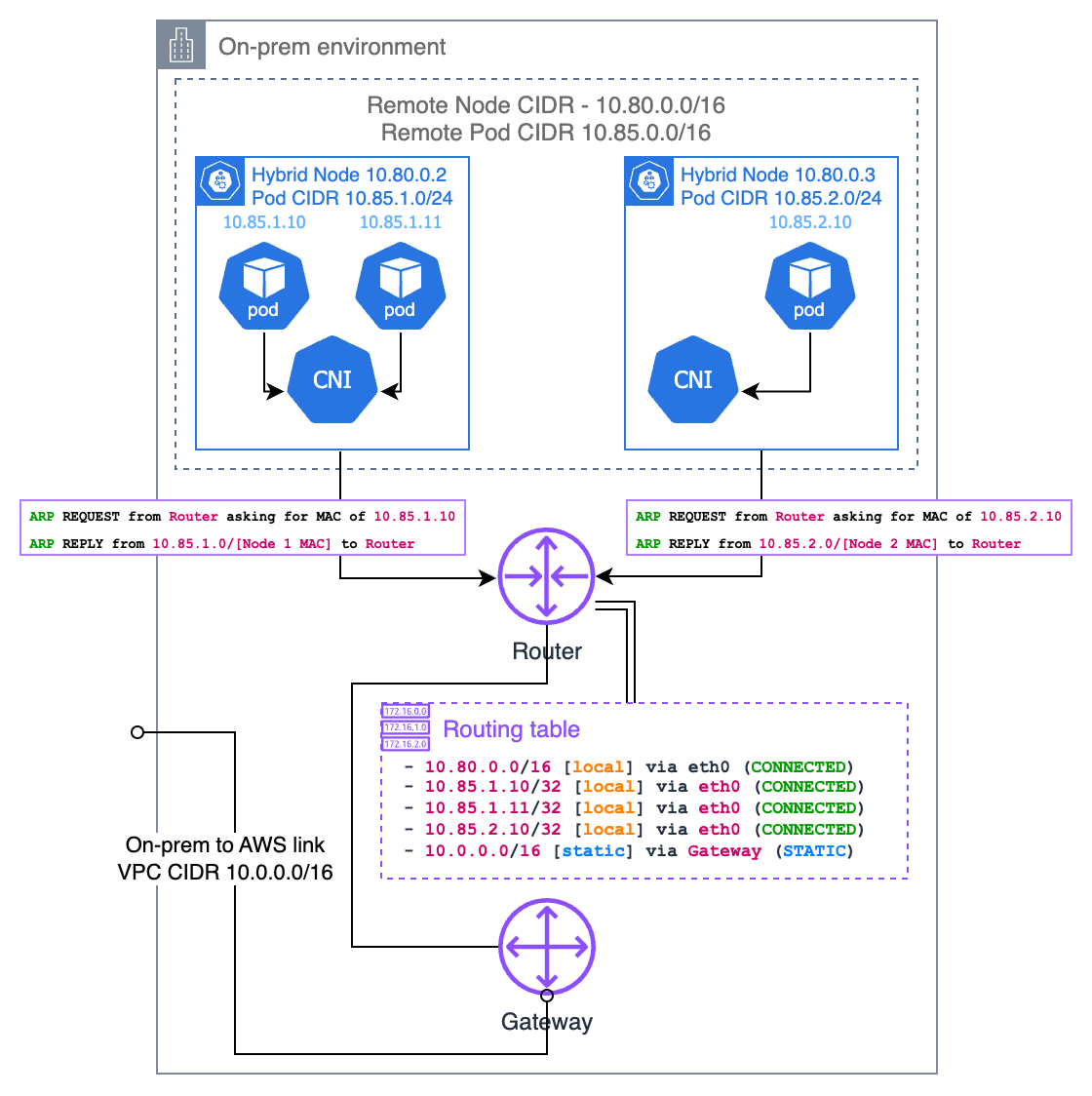
位址解析通訊協定 (ARP) 代理
ARP 代理是讓內部部署 Pod IP 可路由的另一種方法,並且當您的混合節點與本機路由器位於相同的第 2 層網路上時,特別有用。啟用 ARP 代理後,節點會回應其託管的 Pod IP 的 ARP 請求,即使這些 IP 屬於不同的子網路。
當您本機網路上的裝置嘗試連接 Pod IP 時,會先傳送 ARP 請求,並詢問「誰有此 IP?」。託管該 Pod 的混合節點將以其自己的 MAC 位址回應,表示「我可以處理該 IP 的流量」。這會在本機網路上的裝置與 Pod 之間建立一條直接路徑,而無需路由器組態。
若要使其運作,您的 CNI 必須支援代理 ARP 功能。Cilium 內建對代理 ARP 的支援,並且您可以透過組態將其啟用。關鍵考量是,Pod CIDR 不得與您環境中的任何其他網路重疊,因為這可能會導致路由衝突。
此方法有多個優點:* 無需使用 BGP 設定路由器或維護靜態路由 * 適用於您無法控制路由器組態的環境
Pod 至 Pod 封裝
在內部部署環境中,CNI 通常會使用封裝通訊協定來建立可在實體網路上運行的覆蓋網路,而無需重新設定。本節說明此封裝如何運作。請注意,某些詳細資訊可能會因您使用的 CNI 而有所不同。
封裝會將原始 Pod 網路封包包裝在另一個可透過基礎實體網路路由的網路封包內。這可讓 Pod 跨執行相同 CNI 的節點進行通訊,而不需要實體網路知道如何路由這些 Pod CIDR。
與 Kubernetes 搭配使用的最常見封裝通訊協定是虛擬局域網擴展 (VXLAN),但視您的 CNI 而定,也可使用其他通訊協定 (例如 Geneve)。
VXLAN 封裝
VXLAN 將第 2 層乙太網路訊框封裝在 UDP 封包內。當 Pod 將流量傳送至不同節點上的另一個 Pod 時,CNI 會執行下列動作:
-
CNI 攔截來自 Pod A 的封包
-
CNI 將原始封包包裝在 VXLAN 標頭中
-
然後,此已包裝的封包會透過節點的一般網路堆疊傳送至目的地節點
-
目的地節點上的 CNI 會取消包裝封包並將其交付至 Pod B
以下是 VXLAN 封裝期間封包結構的相關情況:
原始 Pod 至 Pod 封包:
+-----------------+---------------+-------------+-----------------+ | Ethernet Header | IP Header | TCP/UDP | Payload | | Src: Pod A MAC | Src: Pod A IP | Src Port | | | Dst: Pod B MAC | Dst: Pod B IP | Dst Port | | +-----------------+---------------+-------------+-----------------+
VXLAN 封裝後:
+-----------------+-------------+--------------+------------+---------------------------+ | Outer Ethernet | Outer IP | Outer UDP | VXLAN | Original Pod-to-Pod | | Src: Node A MAC | Src: Node A | Src: Random | VNI: xx | Packet (unchanged | | Dst: Node B MAC | Dst: Node B | Dst: 4789 | | from above) | +-----------------+-------------+--------------+------------+---------------------------+
VXLAN 網路識別符 (VNI) 可區分不同的覆蓋網路。
Pod 通訊案例
相同混合節點上的 Pod
當相同混合節點上的 Pod 彼此通訊時,通常不需要封裝。CNI 會設定本機路由,而該路由可透過節點的內部虛擬介面來引導 Pod 之間的流量:
Pod A -> veth0 -> node's bridge/routing table -> veth1 -> Pod B
封包永遠不會離開節點,並且也不需要封裝。
不同混合節點上的 Pod
不同混合節點上的 Pod 之間的通訊需要封裝:
Pod A -> CNI -> [VXLAN encapsulation] -> Node A network -> router or gateway -> Node B network -> [VXLAN decapsulation] -> CNI -> Pod B
這可讓 Pod 流量周遊實體網路基礎結構,而無需實體網路來了解 Pod IP 路由。
