本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
負載平衡
提示
透過 Amazon EKS 研討會探索
負載平衡器會接收傳入流量,並將其分佈到 EKS 叢集中託管的預期應用程式目標。這可改善應用程式的彈性。在 EKS 叢集中部署時,AWS Load Balancer 控制器會為該叢集建立和管理 AWS Elastic Load Balancer。建立類型 LoadBalancer 的 Kubernetes 服務時,AWS Load Balancer 控制器會建立 Network Load Balancer (NLB),以平衡 OSI 模型第 4 層接收的流量。建立 Kubernetes 輸入物件時,AWS Load Balancer 控制器會建立 Application Load Balancer (ALB),以平衡 OSI 模型第 7 層的流量。
選擇Load Balancer類型
AWS Elastic Load Balancing (ELB) 產品組合支援下列負載平衡器:Application Load Balancer (ALB)、Network Load Balancer (NLB)、Gateway Load Balancer (GWLB) 和 Classic Load Balancer (CLB)。此最佳實務區段將著重於 ALB 和 NLB,這是與 EKS 叢集最相關的兩個。
選擇負載平衡器類型的主要考量是工作負載需求。
如需更多詳細資訊並做為所有 AWS Load Balancer 的參考,請參閱產品比較
如果您的工作負載是 HTTP/HTTPS,請選擇 Application Load Balancer (ALB)
如果工作負載需要在 OSI 模型的第 7 層進行負載平衡,AWS Load Balancer 控制器可用於佈建 ALB;我們涵蓋下一節的佈建。ALB 由先前提到的輸入資源控制和設定,並將 HTTP 或 HTTPS 流量路由到叢集中的不同 Pod。ALB 可讓客戶靈活地變更應用程式流量路由演算法;預設路由演算法是循環路由演算法,具有最不未完成的請求路由演算法也是替代方案。
如果您的工作負載是 TCP,或者您的工作負載需要用戶端的來源 IP 保留,請選擇 Network Load Balancer (NLB)
Network Load Balancer 函數位於開放式系統互連 (OSI) 模型的第四個層 (傳輸)。它適用於 TCP 和 UDP 型工作負載。根據預設,Network Load Balancer 在將流量呈現至 Pod 時,也會保留用戶端地址的來源 IP。
如果您的工作負載無法使用 DNS,請選擇 Network Load Balancer (NLB)
使用 NLB 的另一個主要原因是,如果您的用戶端無法使用 DNS。在這種情況下,NLB 可能更適合您的工作負載,因為 Network Load Balancer IPs 是靜態的。雖然建議用戶端在連線至負載平衡器時將網域名稱解析為 IP 地址時使用 DNS,但如果用戶端的應用程式不支援 DNS 解析且只接受硬式編碼 IPs,則 NLB 更適合,因為 IPs是靜態的,並且在 NLB 的生命週期內保持不變。
佈建負載平衡器
在判斷最適合工作負載的Load Balancer之後,客戶有許多選項可以佈建負載平衡器。
部署 AWS Load Balancer 控制器來佈建Load Balancer
在 EKS 叢集中佈建負載平衡器有兩種關鍵方法。
-
在 AWS 雲端提供者中利用服務控制器 (舊版)
-
利用 AWS Load Balancer 控制器 (建議)
根據預設,Kubernetes Service Controller 也稱為樹狀內控制器,會協調 LoadBalancer 類型的 Kubernetes Service 資源。此控制器內建在 AWS Cloud Provider
佈建 Elastic Load Balancer 的組態是由必須新增至 Kubernetes Service 資訊清單的註釋所控制。服務控制器
服務控制器是舊版的,目前僅收到重要的錯誤修正。當您建立 LoadBalancer 類型的 Kubernetes 服務時,服務控制器預設會建立 AWS CLB,但如果您使用正確的註釋,也可以建立 AWS NLB。值得注意的是,Service Controller 不支援 Kubernetes Ingress 資源,也不支援 IPv6。
我們建議您在 EKS 叢集中使用 AWS Load Balancer 控制器,以協調 Kubernetes Service 和輸入資源。您必須在 Kubernetes 服務或輸入資訊清單中使用正確的註釋,以便 AWS Load Balancer 控制器擁有對帳程序。(而不是服務控制器)
如果您使用 EKS 自動模式,則會自動為您提供 AWS Load Balancer 控制器;不需要安裝。
選擇Load Balancer目標類型
使用 IP Target-Type 將 Pod 註冊為目標
AWS Elastic Load Balancer:Network & Application,將接收的流量傳送至目標群組中的已註冊目標。對於 EKS 叢集,您可以在目標群組中註冊 2 種類型的目標:執行個體和 IP,使用哪種目標類型會影響註冊的內容,以及如何將流量從 Load Balancer 路由到 Pod。根據預設,AWS Load Balancer 控制器會使用「執行個體」類型註冊目標,而此目標將是工作者節點的 IP 和 NodePort,其含意包括:
-
來自Load Balancer的流量將轉送至 NodePort 上的工作者節點,這會由 iptables 規則處理 (由節點上執行的 kube-proxy 設定),並轉送至 ClusterIP 上的服務 (仍在節點上),最後服務會隨機選取已註冊的 Pod,並將流量轉送至該節點。此流程涉及多個躍點,而且可能會產生額外的延遲,特別是因為服務有時會選取在另一個工作者節點上執行的 Pod,而該節點也可能位於另一個可用區域。
-
由於Load Balancer會將工作者節點註冊為其目標,這表示傳送至目標的運作狀態檢查不會直接由 Pod 接收,但由其 NodePort 上的工作者節點接收,且運作狀態檢查流量將遵循上述相同的路徑。
-
監控和故障診斷更為複雜,因為Load Balancer轉送的流量不會直接傳送到 Pod,而且您必須謹慎地將工作者節點上收到的封包與服務 ClusterIP 建立關聯,最終讓 Pod 能夠完全 end-to-end 掌握封包路徑,以進行適當的故障診斷。

相反地,如果您將目標類型設定為「IP」,我們建議隱含內容如下:
-
來自Load Balancer的流量將直接轉送到 Pod,這簡化了網路路徑,因為它繞過先前的工作者節點和服務叢集 IP 額外跳轉,它減少了如果服務將流量轉送到另一個可用區域中的 Pod,最後移除工作者節點上的 iptables 規則額外負荷處理,否則會發生的延遲。
-
Pod 會直接接收和回應 Load Balancer 的運作狀態檢查,這表示目標狀態「運作狀態良好」或「運作狀態不良」是 Pod 運作狀態的直接表示。
-
監控和故障診斷更容易,任何用於擷取封包 IP 地址的工具都會直接顯示Load Balancer與其來源和目的地欄位中 Pod 之間的雙向流量。

若要建立使用您新增之 IP 目標的 AWS Elastic Load Balancing:
-
alb.ingress.kubernetes.io/target-type: ip設定 Kubernetes 輸入時 (Application Load Balancer) 資訊清單的 註釋 -
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: ip設定類型 LoadBalancer (Network Load Balancer) 的 Kubernetes Service 時, 會註釋服務資訊清單。
設定Load Balancer運作狀態檢查
雖然 Kubernetes 提供自己的運作狀態檢查機制 (在下一節中詳細說明),但我們建議您實作 ELB 運作狀態檢查,做為在 Kubernetes 控制平面外部運作的補充保護措施。此獨立 layer 會在下列期間持續監控您的應用程式:
-
Kubernetes 控制平面中斷
-
探查執行延遲
-
kubelet 和 Pod 之間的網路分割區
對於在上述案例中需要最大可用性加速復原的關鍵工作負載,ELB 運作狀態檢查提供與 Kubernetes 原生機制一起運作的基本安全網,而不是替代。
若要在 ELB 上設定和微調運作狀態檢查,您必須使用 Kubernetes 服務或輸入資訊清單中的註釋,並由服務控制器或 AWS Load Balancer 控制器進行協調。
可用性和 Pod 生命週期
在應用程式升級期間,您必須確保您的應用程式隨時可用於處理請求,讓使用者不會遇到任何停機時間。在此案例中,一個常見的挑戰是在 Kubernetes 層和基礎設施之間同步工作負載的可用性狀態,例如外部負載平衡器。以下幾節重點介紹處理此類案例的最佳實務。
注意
以下說明是以 EndpointSlices
使用運作狀態檢查
Kubernetes 預設會執行程序運作狀態檢查
請參閱下方附錄一節中的 Pod 建立,以重新檢視 Pod 建立程序中的事件順序。
使用整備探查
根據預設,當 Pod 中的所有容器執行success。另一方面,如果探測進一步失敗,則會從 EndpointSlice 物件中移除 Pod。您可以在每個容器的 Pod 資訊清單中設定整備探查。每個節點上的 kubelet 程序都會對該節點上的容器執行整備探查。
使用 Pod 整備閘道
整備探查的一個方面是,其中沒有外部意見回饋/影響機制,節點上的 kubelet 程序會執行探查並定義探查的狀態。這不會影響 Kubernetes 層中微服務本身之間的請求 (東西流量),因為 EndpointSlice 控制器會將端點 (Pod) 清單保持在最新狀態。為什麼和何時需要外部機制,然後是 ?
當您使用 Load Balancer 或 Kubernetes Ingress (適用於北向 - 南向流量) 的 Kubernetes Service 類型公開應用程式時,必須將個別 Kubernetes Service 的 Pod IPs 清單傳播至外部基礎設施負載平衡器,以便負載平衡器也具有最新的清單目標。AWS Load Balancer 控制器會橋接此處的間隙。當您使用 AWS Load Balancer 控制器並利用 target group: IP 時,就像 kube-proxy AWS Load Balancer 控制器也會收到更新 (透過 watch),然後與 ELB API 通訊,以設定並開始將 Pod IP 註冊為 ELB 上的目標。
當您執行部署的滾動更新時,會建立新的 Pod,並在新 Pod 的條件為「就緒」時立即終止舊/現有的 Pod。在此過程中,Kubernetes EndpointSlice 物件的更新速度會比 ELB 將新 Pod 註冊為目標所需的時間更快,請參閱目標註冊。在短時間內,您可能會在 Kubernetes 層與可捨棄用戶端請求的基礎設施層之間發生狀態不符。在 Kubernetes layer 內的這段期間,新的 Pod 已準備好處理請求,但從 ELB 的角度來看,它們不是。
Pod 整備閘道
正常關閉應用程式
您的應用程式應該透過啟動正常關機來回應 SIGTERM 訊號,以便用戶端不會經歷任何停機時間。這表示您的應用程式應執行清除程序,例如儲存資料、關閉檔案描述項、關閉資料庫連線、正常完成傳輸中請求,以及及時結束以滿足 Pod 終止請求。您應該將寬限期設定為足夠長的時間,以便清除可以完成。若要了解如何回應 SIGTERM 訊號,您可以參考您用於應用程式之個別程式設計語言的資源。
如果您的應用程式在收到 SIGTERM 訊號時無法正常關閉,或忽略/未接收訊號
整體事件順序如下圖所示。注意:無論應用程式正常關閉程序的結果或 PreStop 掛鉤的結果為何,應用程式容器最終都會在寬限期結束時透過 SIGKILL 終止。
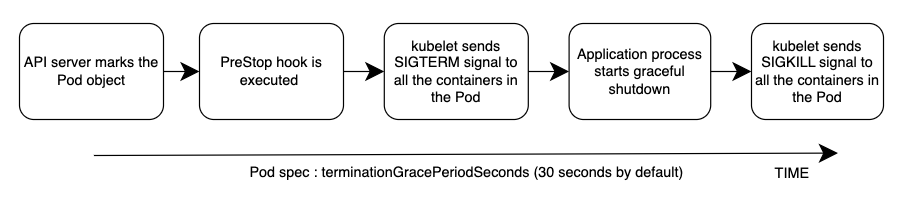
請參閱下方附錄一節中的 Pod 刪除,以重新檢視 Pod 刪除程序中的事件順序。
優雅地處理用戶端請求
Pod 刪除中的事件順序與建立 Pod 不同。建立 Pod 時,會在 Kubernetes API 中kubelet更新 Pod IP,而且只會更新 EndpointSlice 物件。另一方面,當 Pod 正在終止時,Kubernetes API 會同時通知 kubelet 和 EndpointSlice 控制器。仔細檢查下圖,其中顯示事件的順序。
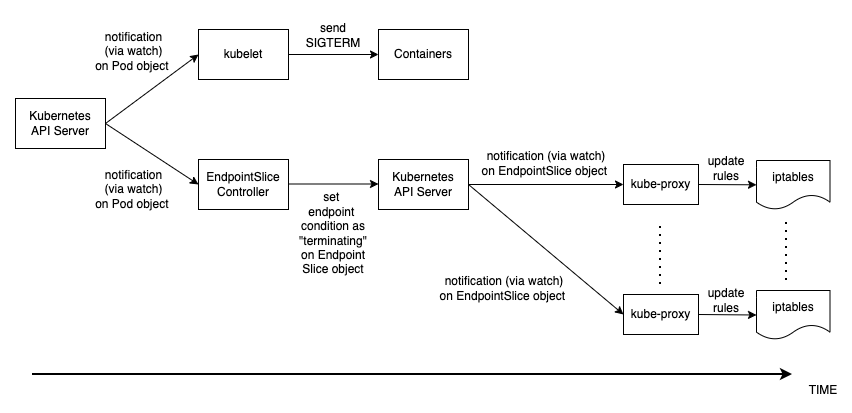
狀態從 API 伺服器傳播到上述節點上 iptables 規則的方式,會建立有趣的競爭條件。由於容器接收 SIGKILL 訊號的機率很高,比每個節點上的 kube-proxy 更早,因此會更新本機 iptables 規則。在這種情況下,值得提及的兩個案例是 :
-
如果您的應用程式在收到 SIGTERM 時立即且暗中捨棄處理中的請求和連線,這表示用戶端會看到整個位置的 50 倍錯誤。
-
即使您的應用程式確保在收到 SIGTERM 時,所有處理中的請求和連線都會完全處理,在寬限期內,新的用戶端請求仍會傳送到應用程式容器,因為 iptables 規則可能尚未更新。在清除程序關閉容器上的伺服器通訊端之前,這些新請求將產生新的連線。當寬限期結束時,這些連線會在 SIGTERM 之後建立,此時會無條件捨棄,因為 SIGKILL 已傳送。
在 Pod 規格中設定足夠長的寬限期可以解決此挑戰,但取決於傳播延遲和實際用戶端請求的數量,很難預測應用程式正常關閉連線所需的時間。因此,此處不完美但最可行的方法是使用 PreStop 勾點來延遲 SIGTERM 訊號,直到更新 iptables 規則,以確保不會將新的用戶端請求傳送至應用程式,而是只有現有的連線會繼續。PreStop hook 可以是簡單的 Exec 處理常式,例如 sleep 10。
當您使用 AWS Load Balancer 控制器使用 Load Balancer 的 Kubernetes Service 類型或 Kubernetes Ingress (適用於北向 - 南向流量) 公開應用程式並利用 target group: IP 時,上述行為和建議同樣適用。 Load Balancer 因為就像 kube-proxy AWS Load Balancer 控制器一樣,它也會收到 EndpointSlice 物件的更新 (透過監看),然後與 ELB API 通訊,以開始從 ELB 取消註冊 Pod IP。不過,根據 Kubernetes API 或 ELB API 的負載,這也可能需要一些時間,而且 SIGTERM 可能已在很久之前傳送到應用程式。一旦 ELB 開始取消註冊目標,它會停止傳送請求到該目標,因此應用程式不會收到任何新的請求,ELB 也會啟動取消註冊延遲,預設為 300 秒。在取消註冊過程中,目標draining基本上是 ELB 等待處理中的請求/與該目標的現有連線耗盡。一旦取消註冊延遲過期,目標就會未使用,且對該目標的任何傳輸中請求都會被強制捨棄。
使用 Pod 中斷預算
為您的應用程式設定 Pod 中斷預算
參考
-
KubeCon 歐洲 2019 工作階段 - 準備好了嗎? 深入了解適用於服務運作狀態的 Pod 準備階段
-
書籍 - Kubernetes 實際運作
-
AWS 部落格 - 如何在 EKS 上使用 ALB 快速擴展應用程式 (而不會遺失流量)
附錄
Pod 建立
在部署 Pod 的案例中,必須了解事件序列是什麼,然後它變得正常/準備好接收和處理用戶端請求。讓我們討論事件的順序。
-
Pod 是在 Kubernetes 控制平面上建立的 (即 透過 kubectl 命令、部署更新或擴展動作)。
-
kube-scheduler會將 Pod 指派給叢集中的節點。 -
在指派節點上執行的 kubelet 程序會收到更新 (透過
watch),並與容器執行時間通訊,以啟動 Pod 規格中定義的容器。 -
當容器開始執行時, kubelet 會將 Pod 條件
更新為 Kubernetes API Ready中的 Pod 物件。 -
EndpointSlice 控制器
會收到 Pod 條件更新 (透過 watch),並將 Pod IP/Port 做為新端點新增至個別 Kubernetes 服務的 EndpointSlice物件 (Pod IPs 清單)。 -
每個節點上的 kube-proxy
程序都會收到 EndpointSlice 物件的更新 (透過 watch),然後使用新的 Pod IP/連接埠更新每個節點上的 iptables規則。
Pod 刪除
如同建立 Pod 一樣,您必須了解 Pod 刪除期間的事件順序。讓我們討論事件的序列。
-
Pod 刪除請求會傳送至 Kubernetes API 伺服器 (即 透過
kubectl命令、部署更新或擴展動作)。 -
Kubernetes API 伺服器會在 Pod 物件中設定 deleteTimestamp 欄位,以啟動寬限期
,預設為 30 秒。 deletionTimestamp (寬限期可透過 在 Pod 規格中設定 terminationGracePeriodSeconds) -
在節點上執行
kubelet的程序會接收 Pod 物件的更新 (透過監看),並傳送 SIGTERM訊號以處理該 Pod 中每個容器內的識別符 1 (PID 1)。然後,它會監看 terminationGracePeriodSeconds。 -
EndpointSlice 控制器
也會從步驟 2 接收更新 (透過 watch),並將端點條件設定為個別 Kubernetes 服務的 EndpointSlice物件 (Pod IPs 清單) 中的「終止」。 -
每個節點上的 kube-proxy
程序會在 EndpointSlice 物件上接收更新 (透過 watch),然後 kube-proxy 會更新每個節點上的 iptables規則,以停止將用戶端請求轉送至 Pod。 -
當
terminationGracePeriodSeconds過期時,kubelet會將 SIGKILL訊號傳送至 Pod 中每個容器的父程序,並強制終止它們。 -
TheEndpointSlice控制器
會從 EndpointSlice 物件移除端點。 -
API 伺服器會刪除 Pod 物件。
