本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
透過網路連線的 Kubernetes Pod 容錯移轉
首先,我們會回顧影響 Kubernetes 在節點與 Kubernetes 控制平面之間的網路中斷期間行為的關鍵概念、元件和設定。EKS 符合上游 Kubernetes,因此此處所述的所有 Kubernetes 概念、元件和設定都適用於 EKS 和 EKS 混合節點部署。
EKS 已針對改善網路連線中斷期間的 Pod 容錯移轉行為進行改善,如需詳細資訊,請參閱上游 Kubernetes 儲存庫中的 GitHub 問題 #131294
概念
標記和容錯:在 Kubernetes 中使用標記和容錯來控制 Pod 在節點上的排程。污點是由 node-lifecycle-controller 設定,以表示節點不符合排程資格,或應該移出這些節點上的 Pod。當節點因網路連線中斷而無法連線時,node-lifecycle-controller會使用 NoSchedule 效果套用 node.kubernetes.io/unreachable 污點,如果符合特定條件,則會套用 NoExecute 效果。node.kubernetes.io/unreachable 污點對應於 NodeCondition Ready be Unknown。使用者可以在 PodSpec 中的應用程式層級為污點指定容錯。
-
NoSchedule:除非有相符的容錯,否則不會在污點節點上排定新的 Pod。不會移出已在節點上執行的 Pod。
-
NoExecute:不會容忍污點的 Pod 會立即被移出。容忍污點的 Pod (不指定tolerationSeconds) 會永遠保持繫結。使用指定的tolerationSeconds容忍污點的 Pod 在指定的時間內保持繫結。經過這段時間後,節點生命週期控制器會從節點移出 Pod。
節點租用:Kubernetes 使用租用 API 將 kubelet 節點活動訊號與 Kubernetes API 伺服器通訊。對於每個節點,都有一個具有相符名稱的租用物件。在內部,每個 kubelet 活動訊號都會更新租用物件的 spec.renewTime 欄位。Kubernetes 控制平面會使用此欄位的時間戳記來判斷節點可用性。如果節點與 Kubernetes 控制平面中斷連線,則無法更新其租用的 spec.renewTime,且控制平面會將該節點解釋為 NodeCondition Ready 為未知。
元件
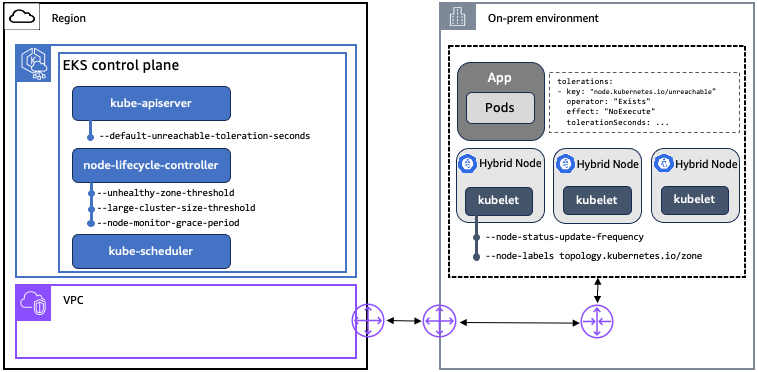
| 元件 | 子元件 | 說明 |
|---|---|---|
|
Kubernetes 控制平面 |
kube-api-server |
API 伺服器是 Kubernetes 控制平面的核心元件,可公開 Kubernetes API。 |
|
Kubernetes 控制平面 |
node-lifecycle-controller |
kube-controller-manager 執行的其中一個控制器。它負責偵測和回應節點問題。 |
|
Kubernetes 控制平面 |
kube-scheduler |
控制平面元件,可監控沒有指派節點的新建立 Pod,並選取要在其中執行的節點。 |
|
Kubernetes 節點 |
kubelet |
在叢集中每個節點上執行的代理程式。kubelet 會監看 PodSpecs,並確保這些 PodSpecs 中所述的容器執行正常。 |
組態設定
| 元件 | 設定 | 說明 | K8s 預設 | EKS 預設 | 可在 EKS 中設定 |
|---|---|---|---|---|---|
|
kube-api-server |
default-unreachable-toleration-seconds |
指出 的 公差的 |
300 |
300 |
否 |
|
node-lifecycle-controller |
node-monitor-grace-period |
在標示為運作狀態不佳之前,節點可能沒有回應的時間量。必須是 kubelet 的 N 倍 |
40 |
40 |
否 |
|
node-lifecycle-controller |
large-cluster-size-threshold |
對於移出邏輯,node-lifecycle-controller將叢集視為大型的節點數量。對於此大小或更小的叢集 |
50 |
100,000 |
否 |
|
node-lifecycle-controller |
unhealthy-zone-threshold |
區域中必須尚未就緒,才能將該區域視為運作狀態不佳的節點百分比。 |
55% |
55% |
否 |
|
kubelet |
node-status-update-frequency |
kubelet 將節點狀態發佈到控制平面的頻率。必須與 node-lifecycle-controller |
10 |
10 |
是 |
|
kubelet |
節點標籤 |
在叢集中註冊節點時要新增的標籤。 |
無 |
無 |
是 |
透過網路連線的 Kubernetes Pod 容錯移轉
此處所述的行為假設 Pod 正在執行為具有預設設定的 Kubernetes 部署,並使用 EKS 作為 Kubernetes 供應商。實際行為可能會因您的環境、網路連線類型、應用程式、相依性和叢集組態而有所不同。本指南中的內容已使用特定應用程式、叢集組態和外掛程式子集進行驗證。強烈建議在移至生產環境之前,先使用您自己的應用程式來測試行為。
當節點與 Kubernetes 控制平面之間發生網路連線中斷時,每個中斷連線節點上的 kubelet 無法與 Kubernetes 控制平面通訊。因此,在連線還原之前,kubelet 無法移出這些節點上的 Pod。這表示在網路連線中斷之前在這些節點上執行的 Pod 會在中斷連線期間繼續執行,假設沒有其他失敗導致它們關閉。總而言之,您可以在節點與 Kubernetes 控制平面之間的網路連線中斷期間達到靜態穩定性,但在連線還原之前,您無法對節點或工作負載執行變動操作。
有五種主要案例會根據網路連線的性質產生不同的 Pod 容錯移轉行為。在所有情況下,當節點重新連線至 Kubernetes 控制平面時,叢集會再次正常運作,無需操作員介入。以下案例根據我們的觀察概述預期結果,但這些結果可能不適用於所有可能的應用程式和叢集組態。
案例 1:完全叢集中斷
預期結果:無法連線節點上的 Pod 不會移出,並繼續在這些節點上執行。
完整的叢集中斷表示叢集中的所有節點都與 Kubernetes 控制平面中斷連線。在此案例中,控制平面上的node-lifecycle-controller會偵測到叢集中的所有節點都無法連線,並取消任何 Pod 移出。
叢集管理員會在中斷連線Not Ready期間看到狀態為 的所有節點。Pod 狀態不會變更,而且在中斷連線和後續重新連線期間,不會在任何節點上排程新的 Pod。
案例 2:全區域中斷
預期結果:無法連線節點上的 Pod 不會移出,並繼續在這些節點上執行。
完整區域中斷表示該區域中的所有節點都與 Kubernetes 控制平面中斷連線。在此案例中,控制平面上的node-lifecycle-controller會偵測到區域中的所有節點都無法連線,並取消任何 Pod 移出。
叢集管理員會在中斷連線Not Ready期間看到狀態為 的所有節點。Pod 狀態不會變更,而且在中斷連線和後續重新連線期間,不會在任何節點上排程新的 Pod。
案例 3:主要區域中斷
預期結果:無法連線節點上的 Pod 不會移出,並繼續在這些節點上執行。
大多數區域中斷表示指定區域中的大多數節點都與 Kubernetes 控制平面中斷連線。Kubernetes 中的區域由具有相同topology.kubernetes.io/zone標籤的節點定義。如果叢集中未定義任何區域,則大多數中斷表示整個叢集中的大多數節點都會中斷連線。根據預設,大多數是由node-lifecycle-controller的 定義unhealthy-zone-threshold,在 Kubernetes 和 EKS 中均設為 55%。由於 large-cluster-size-threshold EKS 中的 設為 100,000,如果區域中 55% 或以上的節點無法連線,則會取消 Pod 移出 (因為大多數叢集遠小於 100,000 個節點)。
叢集管理員會在中斷連線Not Ready期間看到區域中大部分處於 狀態的節點,但 Pod 的狀態不會變更,也不會在其他節點上重新排程這些節點。
請注意,上述行為僅適用於大於三個節點的叢集。在不超過三個節點的叢集中,無法連線節點上的 Pod 會排程為移出,而新的 Pod 會排程在運作狀態良好的節點上。
在測試期間,我們偶爾會觀察到 Pod 在網路連線中斷期間從剛好一個無法連線的節點移出,即使大部分的區域節點都無法連線。作為此行為的原因,我們仍在 Kubernetes node-lifecycle-controller中調查可能的競爭條件。
案例 4:少數區域中斷
預期結果:從無法連線的節點移出 Pod,並在可用的合格節點上排程新的 Pod。
少數中斷表示區域中較少百分比的節點與 Kubernetes 控制平面中斷連線。如果叢集中未定義任何區域,則少數中斷表示整個叢集中節點的少數節點會中斷連線。如前所述,少數是節點node-lifecycle-controllerunhealthy-zone-threshold的設定,預設為 55%。在此案例中,如果網路連線的持續時間超過 default-unreachable-toleration-seconds(5 分鐘) 和 node-monitor-grace-period(40 秒),且區域中少於 55% 的節點無法連線,則會在運作狀態良好的節點上排程新的 Pod,而無法連線節點上的 Pod 會標記為移出。
叢集管理員將看到在運作狀態良好的節點上建立的新 Pod,中斷連線節點上的 Pod 將顯示為 Terminating。請記住,即使已中斷連線節點上的 Pod 具有 Terminating 狀態,在節點重新連線至 Kubernetes 控制平面之前,它們不會完全移出。
案例 5:網路中斷期間節點重新啟動
預期結果:在節點重新連線至 Kubernetes 控制平面之前,無法連線節點上的 Pod 不會啟動。Pod 容錯移轉遵循案例 1–3 中所述的邏輯,取決於無法連線的節點數量。
網路中斷期間節點重新啟動表示節點上發生另一個故障 (例如電源循環、out-of-memory事件或其他問題),同時發生網路中斷連線。如果 kubelet 也已重新啟動,則網路中斷連線開始時在該節點上執行的 Pod 不會在中斷連線期間自動重新啟動。kubelet 會在啟動期間查詢 Kubernetes API 伺服器,以了解應執行哪些 Pod。如果 kubelet 由於網路連線中斷而無法連線到 API 伺服器,則無法擷取啟動 Pod 所需的資訊。
在此案例中,無法使用本機故障診斷工具,例如 crictl CLI,將 Pod 手動啟動為「中斷玻璃」量值。Kubernetes 通常會移除故障的 Pod 並建立新的 Pod,而不是重新啟動現有的 Pod (如需詳細資訊,請參閱容器化 GitHub 儲存庫中的 #10213
