本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
控制平面監控
API 伺服器
查看我們的 API 伺服器時,請務必記住,其其中一個函數是調節傳入請求,以防止控制平面過載。API 伺服器層級的瓶頸可能實際上是保護它免受更嚴重問題的影響。我們需要考慮增加在系統中移動的請求量的優缺點。若要判斷 API 伺服器值是否應增加,以下是我們需要注意的事項的小型抽樣:
-
請求在系統中移動的延遲為何?
-
該延遲是 API 伺服器本身還是像是「下游」等?
-
API 伺服器佇列深度是否為此延遲的因素?
-
針對我們想要的 API 呼叫模式,是否正確設定 API Priority and Fairness (APF) 佇列?
問題在哪裡?
首先,我們可以使用 API 延遲的 指標,讓我們深入了解 API 伺服器服務請求所需的時間。讓我們使用下列 PromQL 和 Grafana 熱度圖來顯示此資料。
max(increase(apiserver_request_duration_seconds_bucket{subresource!="status",subresource!="token",subresource!="scale",subresource!="/healthz",subresource!="binding",subresource!="proxy",verb!="WATCH"}[$__rate_interval])) by (le)
注意
如需如何使用本文中使用的 API 儀表板來監控 API 伺服器的深度寫入,請參閱下列部落格
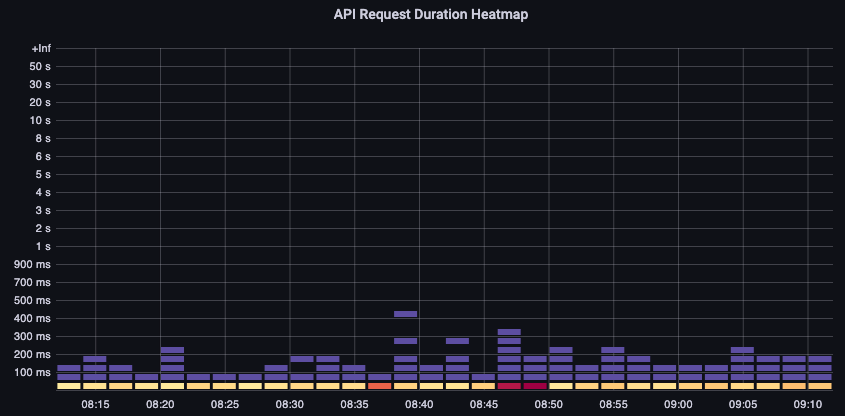
這些請求都低於一秒標記,這是控制平面及時處理請求的良好跡象。但是,如果不是這種情況,該怎麼辦?
我們在上述 API 請求持續時間中使用的格式是熱度圖。熱度圖格式的優點是,它預設會告訴我們 API 的逾時值 (60 秒)。不過,我們真正需要知道的是,在達到逾時閾值之前,此值應考量的閾值為何。如需了解哪些可接受閾值的粗略準則,我們可以使用上游 Kubernetes SLO,可在這裡
注意
請注意此陳述式的最大函數? 使用彙總多個伺服器的指標時 (預設為 EKS 上的兩個 API 伺服器),請務必不要將這些伺服器平均在一起。
非對稱流量模式
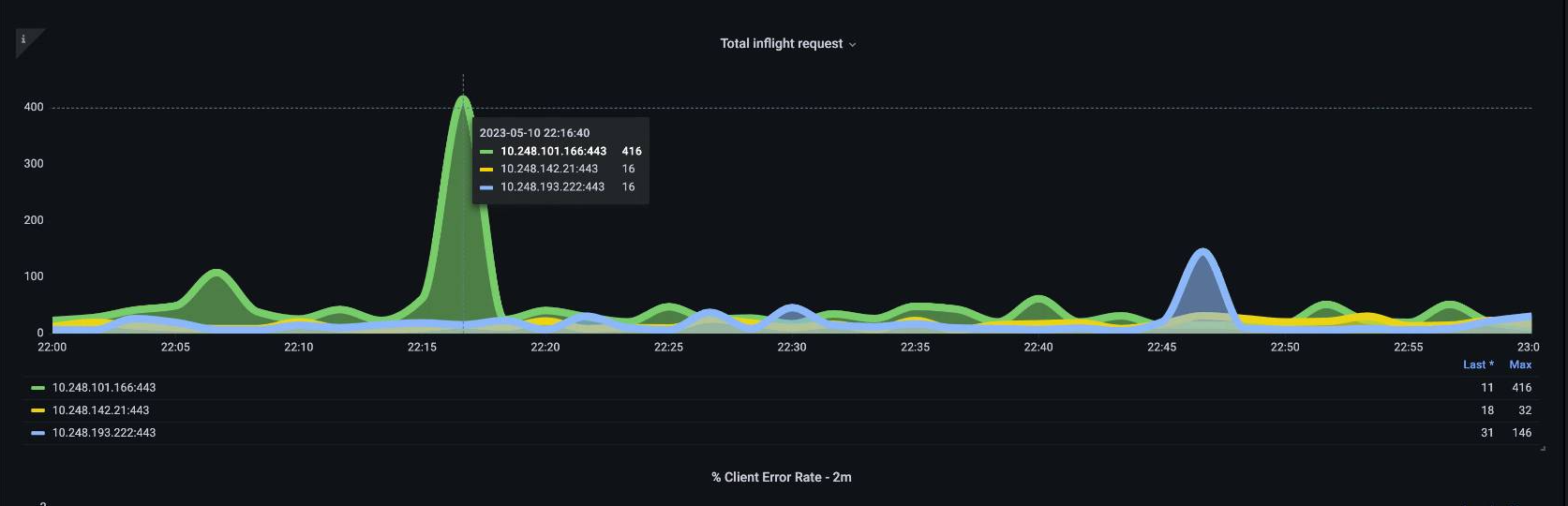
如果一個 API 伺服器 【Pod】 被輕載,而另一個 API 伺服器被重載,該怎麼辦? 如果我們將這兩個數字平均在一起,我們可能會誤判所發生的情況。例如,這裡有三個 API 伺服器,但所有負載都在其中一個 API 伺服器上。作為一項規則,在投資擴展和效能問題時,任何有多個伺服器,例如 etcd 和 API 伺服器,都應被分解。
移至 API Priority and Fairness 時,系統上的請求總數只是檢查 API 伺服器是否過度訂閱的一個因素。由於系統現在可處理一系列佇列,因此我們必須查看這些佇列中是否有任何佇列已滿,以及該佇列的流量是否遭到捨棄。
讓我們使用下列查詢來查看這些佇列:
max without(instance)(apiserver_flowcontrol_nominal_limit_seats{})
注意
如需 API A&F 運作方式的詳細資訊,請參閱下列最佳實務指南
在這裡,我們看到叢集上預設出現的七個不同的優先順序群組

接下來,我們想要查看使用該優先順序群組的百分比,以便了解特定優先順序層級是否飽和。調節低工作負載層級的請求可能是理想的,但不會在領導者選擇層級下降。
API Priority and Fairness (APF) 系統有許多複雜的選項,其中一些選項可能會產生意外的後果。我們在 欄位中看到的常見問題是將佇列深度增加到開始新增不必要的延遲點。我們可以使用 apiserver_flowcontrol_current_inqueue_request 指標來監控此問題。我們可以使用 檢查 是否捨棄apiserver_flowcontrol_rejected_requests_total。如果任何儲存貯體超過其並行,這些指標將是非零值。
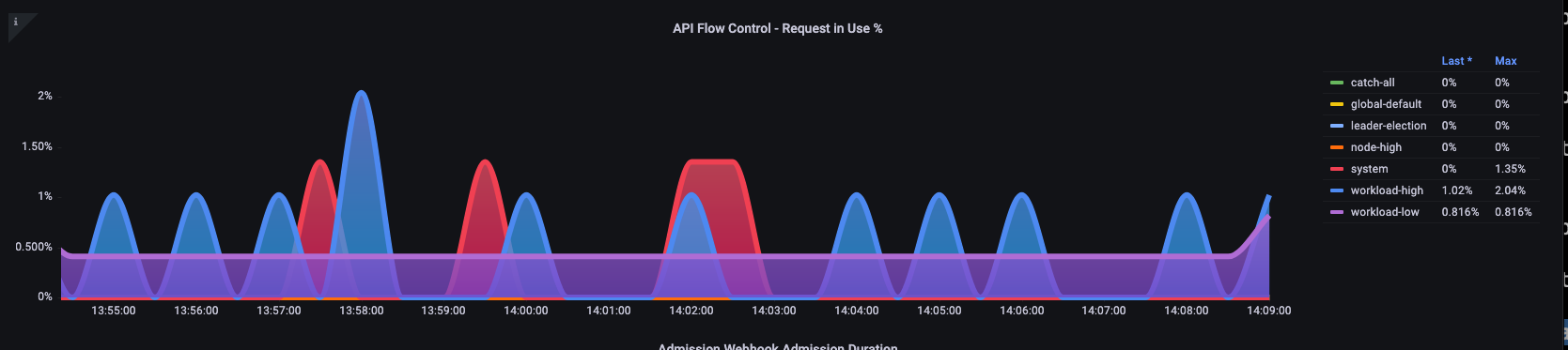
增加佇列深度可讓 API Server 成為重要的延遲來源,並應謹慎執行。我們建議您謹慎處理建立的佇列數量。例如,EKS 系統上的共用數目為 600,如果我們建立太多佇列,這可以減少需要輸送量的重要佇列中的共用,例如領導者選擇佇列或系統佇列。建立過多的額外佇列可能會讓正確調整這些佇列的大小變得更困難。
為了專注於您可以在 APF 中進行的簡單影響性變更,我們只會從未充分利用的儲存貯體取得共用,並增加使用量上限的儲存貯體大小。透過智慧地重新分配這些儲存貯體之間的共用,您可以降低捨棄的可能性。
如需詳細資訊,請參閱《EKS 最佳實務指南》中的 API 優先順序和公平性設定。
API 與 等延遲
如何使用 API 伺服器的指標/日誌來判斷 API 伺服器是否有問題,或 API 伺服器上游/下游的問題,或兩者的組合。為了更清楚這一點,讓我們看看 API Server 和 等的關聯性,以及對錯誤系統進行故障診斷的難易度。
在下表中,我們看到 API 伺服器延遲,但由於圖表中的長條顯示大多數的延遲,我們也會看到大部分的延遲與等化伺服器相關。如果具有 15 秒的刻印延遲,同時有 20 秒的 API 伺服器延遲,則大多數延遲實際上是在刻印層級。
透過查看整個流程,我們發現不僅專注於 API 伺服器是明智的,但也要尋找表示被壓縮的訊號 (即緩慢套用計數器增加)。只需一目了然就能快速移動到正確的問題區域,這使得儀表板功能強大。
注意
您可以在 https://https://github.com/RiskyAdventure/Troubleshooting-Dashboards/blob/main/api-troubleshooter.json 找到 區段中的儀表板
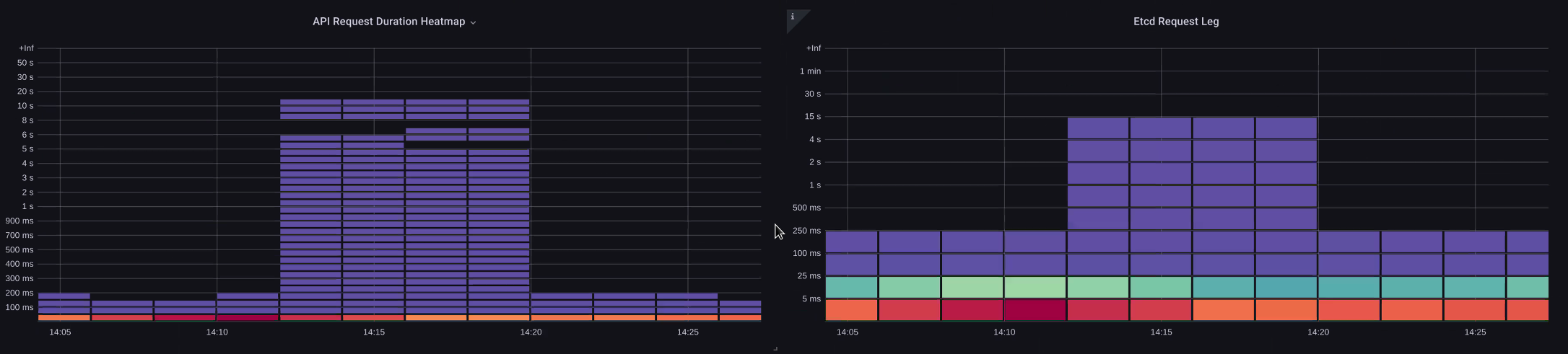
控制平面與用戶端問題
在此圖表中,我們正在尋找在該期間內最花時間完成的 API 呼叫。在這種情況下,我們看到自訂資源 (CRD) 正在呼叫套用函數,這是 05:40 時間範圍內最隱含的呼叫。
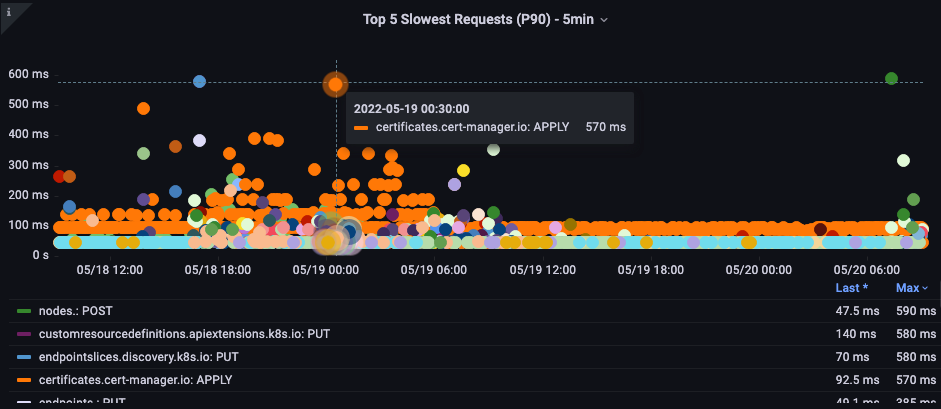
透過這些資料,我們可以使用 Ad-Hoc PromQL 或 CloudWatch Insights 查詢,在該時間範圍內從稽核日誌提取 LIST 請求,以查看這可能是哪個應用程式。
使用 CloudWatch 尋找來源
指標最適合用來尋找我們想要查看並縮小問題時間範圍和搜尋參數的問題區域。取得這些資料後,我們希望轉換為日誌,以取得更詳細的時間和錯誤。為此,我們將使用 CloudWatch Logs Insights 將日誌轉換為指標。
例如,為了調查上述問題,我們將使用下列 CloudWatch Logs Insights 查詢提取 userAgent 和 requestURI,以便我們鎖定導致此延遲的應用程式。
注意
必須使用適當的 Count 做為 ,才不會提取 Watch 上的正常 List/Resync 行為。
fields @timestamp, @message | filter @logStream like "kube-apiserver-audit" | filter ispresent(requestURI) | filter verb = "list" | parse requestReceivedTimestamp /\d+-\d+-(?<StartDay>\d+)T(?<StartHour>\d+):(?<StartMinute>\d+):(?<StartSec>\d+).(?<StartMsec>\d+)Z/ | parse stageTimestamp /\d+-\d+-(?<EndDay>\d+)T(?<EndHour>\d+):(?<EndMinute>\d+):(?<EndSec>\d+).(?<EndMsec>\d+)Z/ | fields (StartHour * 3600 + StartMinute * 60 + StartSec + StartMsec / 1000000) as StartTime, (EndHour * 3600 + EndMinute * 60 + EndSec + EndMsec / 1000000) as EndTime, (EndTime - StartTime) as DeltaTime | stats avg(DeltaTime) as AverageDeltaTime, count(*) as CountTime by requestURI, userAgent | filter CountTime >=50 | sort AverageDeltaTime desc
使用此查詢,我們找到了兩個執行大量高延遲清單操作的不同代理程式。Splunk 和 CloudWatch 代理程式。使用資料,我們可以決定移除、更新或將此控制器取代為另一個專案。

注意
如需此主題的詳細資訊,請參閱下列部落格
排程器
由於 EKS 控制平面執行個體是在不同的 AWS 帳戶中執行,因此我們將無法抓取這些元件以進行指標 (API 伺服器是例外狀況)。不過,由於我們可以存取這些元件的稽核日誌,因此可以將這些日誌轉換為指標,以查看是否有任何子系統造成擴展瓶頸。讓我們使用 CloudWatch Logs Insights 來查看排程器佇列中有多少未排程的 Pod。
排程器日誌中的未排程 Pod
如果我們可以直接在自我管理的 Kubernetes (例如 Kops) 上抓取排程器指標,我們會使用下列 PromQL 來了解排程器待處理項目。
max without(instance)(scheduler_pending_pods)
由於我們無法在 EKS 中存取上述指標,因此我們會使用下列 CloudWatch Logs Insights 查詢,檢查在特定時間範圍內有多少 Pod 無法未排程,以查看待處理項目。然後,我們可以進一步深入探討尖峰時段的訊息,以了解瓶頸的性質。例如,節點旋轉速度不夠快,或排程器本身的速率限制器。
fields timestamp, pod, err, @message
| filter @logStream like "scheduler"
| filter @message like "Unable to schedule pod"
| parse @message /^.(?<date>\d{4})\s+(?<timestamp>\d+:\d+:\d+\.\d+)\s+\S*\s+\S+\]\s\"(.*?)\"\s+pod=(?<pod>\"(.*?)\")\s+err=(?<err>\"(.*?)\")/
| count(*) as count by pod, err
| sort count desc
在這裡,我們看到排程器的錯誤,指出 Pod 未部署,因為儲存體 PVC 無法使用。

注意
稽核記錄必須開啟控制平面,才能啟用此函數。這也是最佳實務,限制日誌保留,以免不必要地隨著時間推移增加成本。使用下列 EKSCTL 工具開啟所有記錄函數的範例。
cloudWatch: clusterLogging: enableTypes: ["*"] logRetentionInDays: 10
Kube Controller Manager
如同所有其他控制器,Kube Controller Manager 會限制一次可以執行的操作數量。讓我們看看我們可以設定這些參數的 KOPS 組態,來檢閱這些旗標有哪些。
kubeControllerManager: concurrentEndpointSyncs: 5 concurrentReplicasetSyncs: 5 concurrentNamespaceSyncs: 10 concurrentServiceaccountTokenSyncs: 5 concurrentServiceSyncs: 5 concurrentResourceQuotaSyncs: 5 concurrentGcSyncs: 20 kubeAPIBurst: 30 kubeAPIQPS: "20"
這些控制器具有在叢集上的高流失期間填滿的佇列。在此情況下,我們看到複本集控制器的佇列中有大型待處理項目。
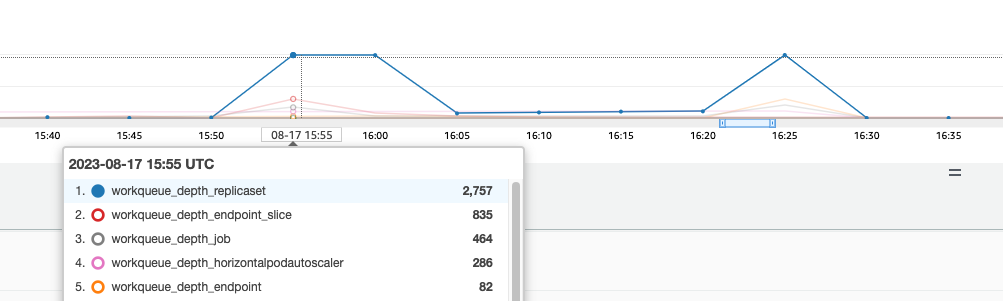
我們有兩種不同的方法來解決這種情況。如果執行自我管理,我們可以簡單地增加並行 goroutine,但這會因為在 KCM 中處理更多資料而影響到 等。另一個選項是減少部署.spec.revisionHistoryLimit上使用 的複本集物件數量,以減少我們可以轉返的複本集物件數量,從而降低此控制器的壓力。
spec: revisionHistoryLimit: 2
其他 Kubernetes 功能可以調校或關閉,以減少高流失率系統中的壓力。例如,如果我們 Pod 中的應用程式不需要直接與 k8s API 交談,則關閉這些 Pod 中投影的秘密會減少 ServiceaccountTokenSyncs 的負載。如果可能,這是更理想的方法來解決此類問題。
kind: Pod spec: automountServiceAccountToken: false
在無法存取指標的系統中,我們可以再次查看日誌以偵測爭用。如果我們希望查看每個控制器或彙總層級上正在處理的請求數量,我們會使用下列 CloudWatch Logs Insights 查詢。
KCM 處理的磁碟區總數
# Query to count API qps coming from kube-controller-manager, split by controller type. # If you're seeing values close to 20/sec for any particular controller, it's most likely seeing client-side API throttling. fields @timestamp, @logStream, @message | filter @logStream like /kube-apiserver-audit/ | filter userAgent like /kube-controller-manager/ # Exclude lease-related calls (not counted under kcm qps) | filter requestURI not like "apis/coordination.k8s.io/v1/namespaces/kube-system/leases/kube-controller-manager" # Exclude API discovery calls (not counted under kcm qps) | filter requestURI not like "?timeout=32s" # Exclude watch calls (not counted under kcm qps) | filter verb != "watch" # If you want to get counts of API calls coming from a specific controller, uncomment the appropriate line below: # | filter user.username like "system:serviceaccount:kube-system:job-controller" # | filter user.username like "system:serviceaccount:kube-system:cronjob-controller" # | filter user.username like "system:serviceaccount:kube-system:deployment-controller" # | filter user.username like "system:serviceaccount:kube-system:replicaset-controller" # | filter user.username like "system:serviceaccount:kube-system:horizontal-pod-autoscaler" # | filter user.username like "system:serviceaccount:kube-system:persistent-volume-binder" # | filter user.username like "system:serviceaccount:kube-system:endpointslice-controller" # | filter user.username like "system:serviceaccount:kube-system:endpoint-controller" # | filter user.username like "system:serviceaccount:kube-system:generic-garbage-controller" | stats count(*) as count by user.username | sort count desc
這裡的關鍵要點是在查看可擴展性問題時,先查看路徑中的每個步驟 (API、排程器、KCM 等),再進入詳細的故障診斷階段。通常在生產環境中,您會發現需要調整 Kubernetes 的多個部分,以允許系統以其效能最佳的方式運作。不小心疑難排解什麼只是較大瓶頸的症狀 (例如節點逾時) 很容易。
ETCD
etcd 使用記憶體映射檔案來有效率地存放金鑰值對。有一種保護機制可設定此可用記憶體空間的大小,通常設定為 2、4 和 8GB 限制。資料庫中的物件較少,表示更新物件且需要清除較舊版本時,需要執行的清除等動作較少。此清除物件舊版本的程序稱為壓縮。在多次壓縮操作之後,後續程序會復原稱為重組的可用空間,該空間發生在超過特定閾值或固定的時間排程。
我們可以執行幾個與使用者相關的項目來限制 Kubernetes 中的物件數量,從而減少壓縮和分離程序的影響。例如,Helm 保持較高的 revisionHistoryLimit。這可讓系統中 ReplicaSets 等較舊的物件能夠執行轉返。透過將歷史記錄限制設定為 2,我們可以將物件數量 (例如 ReplicaSets) 從 10 個減少到 2 個,進而減少對系統的負載。
apiVersion: apps/v1 kind: Deployment spec: revisionHistoryLimit: 2
從監控的角度來看,如果系統延遲尖峰發生在以小時分隔的集合模式中,請檢查此重組程序是否有助於來源。我們可以使用 CloudWatch Logs 來查看。
如果您想要查看重組的開始/結束時間,請使用下列查詢:
fields @timestamp, @message | filter @logStream like /etcd-manager/ | filter @message like /defraging|defraged/ | sort @timestamp asc

