本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
執行高可用性應用程式
您的客戶預期您的應用程式隨時可用,包括當您進行變更時,特別是在流量激增期間。可擴展且具彈性的架構可讓您的應用程式和服務在不中斷的情況下運作,讓您的使用者滿意。可擴展的基礎設施會根據業務需求成長和縮減。消除單點故障是改善應用程式可用性並提高其彈性的關鍵步驟。
使用 Kubernetes,您可以操作您的應用程式,並以高可用性和彈性的方式執行它們。其宣告式管理可確保設定應用程式後,Kubernetes 會持續嘗試將目前狀態與所需狀態配對
建議
設定 Pod 中斷預算
Pod 中斷預算
避免執行單一 Pod
如果您的整個應用程式在單一 Pod 中執行,則如果該 Pod 終止,您的應用程式將無法使用。建立部署,而不是使用個別 Pod 部署
執行多個複本
使用部署執行應用程式的多個複本 Pod,有助於以高可用性的方式執行。如果一個複本失敗,剩餘的複本仍會正常運作,即使容量減少,直到 Kubernetes 建立另一個 Pod 來彌補遺失為止。此外,您可以使用 Horizontal Pod Autoscaler
跨節點排程複本
如果所有複本都在同一個節點上執行,而且節點變得無法使用,則執行多個複本會非常有用。考慮使用 Pod 反親和性或 Pod 拓撲分散限制,將部署的複本分散到多個工作者節點。
您可以透過在多個 AZs 中執行應用程式,進一步改善典型應用程式的可靠性。
使用 Pod 反親和性規則
下列資訊清單會告知 Kubernetes 排程器偏好將 Pod 放置在不同的節點和 AZs 上。它不需要不同的節點或 AZ,因為如果這樣做,則一旦每個 AZ 中有一個執行中的 Pod,Kubernetes 將無法排程任何 Pod。如果您的應用程式只需要三個複本,您可以將 requiredDuringSchedulingIgnoredDuringExecution用於 topologyKey: topology.kubernetes.io/zone,Kubernetes 排程器不會在相同的可用區域中排程兩個 Pod。
apiVersion: apps/v1 kind: Deployment metadata: name: spread-host-az labels: app: web-server spec: replicas: 4 selector: matchLabels: app: web-server template: metadata: labels: app: web-server spec: affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - podAffinityTerm: labelSelector: matchExpressions: - key: app operator: In values: - web-server topologyKey: topology.kubernetes.io/zone weight: 100 - podAffinityTerm: labelSelector: matchExpressions: - key: app operator: In values: - web-server topologyKey: kubernetes.io/hostname weight: 99 containers: - name: web-app image: nginx:1.16-alpine
使用 Pod 拓撲分散限制
與 Pod 反親和性規則類似,Pod 拓撲分散限制可讓您在不同故障 (或拓撲) 網域間使用應用程式,例如主機或可用AZs。當您嘗試在每個不同的拓撲網域中擁有多個複本,以確保容錯能力和可用性時,此方法非常有效。另一方面,Pod 反親和性規則可以輕鬆地產生您在拓撲網域中具有單一複本的結果,因為對彼此具有反親和性的 Pod 具有回推效果。在這種情況下,專用節點上的單一複本不適合容錯能力,也不適合使用 資源。透過拓撲分散限制,您可以更好地控制排程器應嘗試跨拓撲網域套用的分散或分佈。以下是在此方法中使用的一些重要屬性:
-
maxSkew用於控制或判斷物件在拓撲網域間可能不均勻的最大點。例如,如果應用程式有 10 個複本,並部署在 3 AZs,則無法獲得均勻分散,但可以影響分佈的不均勻程度。在這種情況下,maxSkew可以是介於 1 到 10 之間的任何項目。值 1 表示最終可能會像 一樣分散4,3,3,3,4,3或3,3,4分散到 3 AZs。相反地,值 10 表示最終可能會像 一樣分散10,0,0,0,10,0或0,0,10分散到 3 AZs。 -
topologyKey是其中一個節點標籤的金鑰,並定義應該用於 Pod 分佈的拓撲網域類型。例如,區域分散會有下列索引鍵/值對:topologyKey: "topology.kubernetes.io/zone" -
whenUnsatisfiable如果無法滿足所需的限制條件, 屬性會用來決定您希望排程器如何回應。 -
labelSelector用於尋找相符的 Pod,以便排程器在根據您指定的限制條件決定放置 Pod 的位置時,可以知道它們。
除了上述內容之外,您還可以在 Kubernetes 文件中
Pod 拓撲將限制分散到 3 AZs
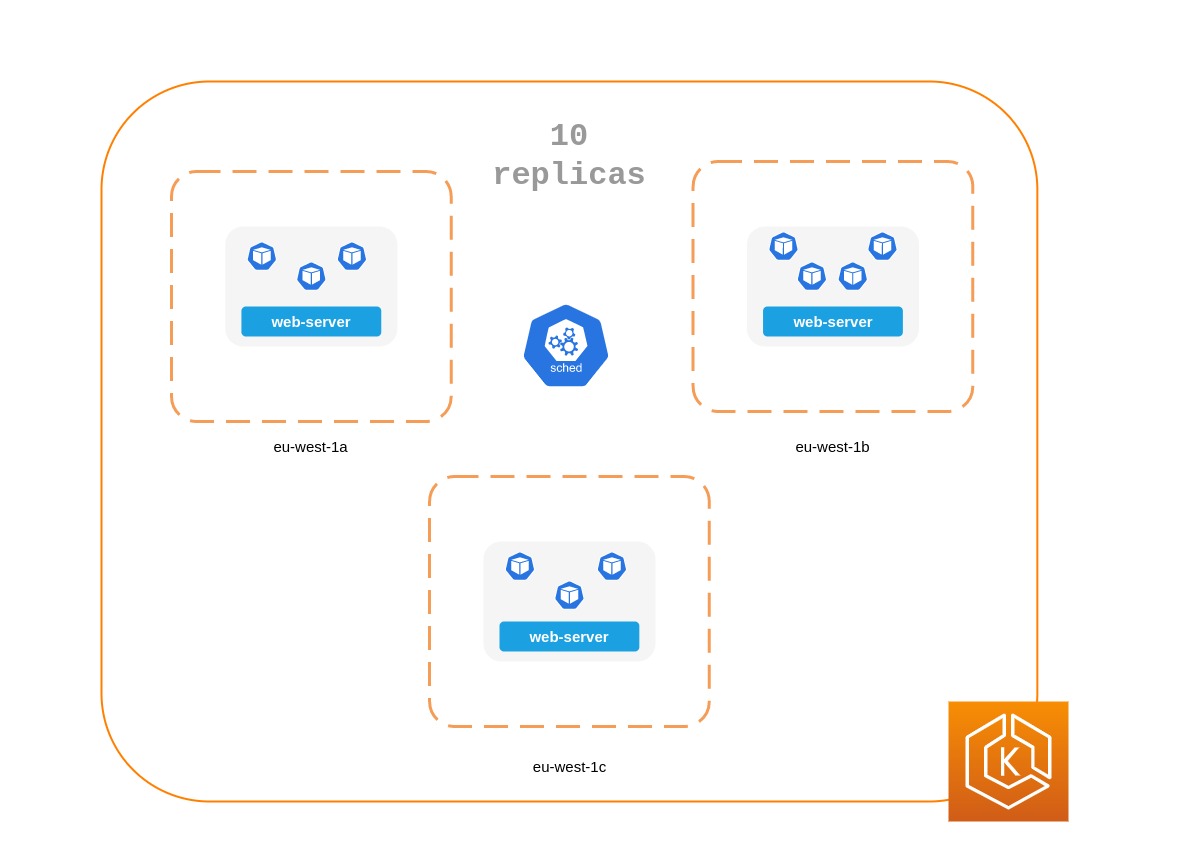
apiVersion: apps/v1 kind: Deployment metadata: name: spread-host-az labels: app: web-server spec: replicas: 10 selector: matchLabels: app: web-server template: metadata: labels: app: web-server spec: topologySpreadConstraints: - maxSkew: 1 topologyKey: "topology.kubernetes.io/zone" whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: app: express-test containers: - name: web-app image: nginx:1.16-alpine
執行 Kubernetes 指標伺服器
安裝 Kubernetes 指標伺服器
指標伺服器不會保留任何資料,也不是監控解決方案。其目的是向其他系統公開 CPU 和記憶體用量指標。如果您想要隨著時間追蹤應用程式的狀態,您需要監控工具,例如 Prometheus 或 Amazon CloudWatch。
遵循 EKS 文件,在您的 EKS 叢集中安裝 metrics-server。
水平 Pod Autoscaler (HPA)
HPA 可以自動擴展您的應用程式以回應需求,並協助您避免在尖峰流量期間影響客戶。它在 Kubernetes 中實作為控制迴圈,定期從提供資源指標APIs 查詢指標。
HPA 可以從下列 APIs 擷取指標:1. metrics.k8s.io也稱為資源指標 API — 為 Pod 2 提供 CPU 和記憶體用量。 custom.metrics.k8s.io— 提供來自 Prometheus 等其他指標收集器的指標;這些指標位於 Kubernetes 叢集內部。3. external.metrics.k8s.io — 提供 Kubernetes 叢集外部的指標 (例如 SQS 佇列深度、ELB 延遲)。
您必須使用這三個 APIs之一來提供指標來擴展您的應用程式。
根據自訂或外部指標擴展應用程式
您可以使用自訂或外部指標,根據 CPU 或記憶體使用率以外的指標來擴展應用程式。自訂指標custom-metrics.k8s.io API。
您可以使用 Prometheus Adapter for Kubernetes Metrics APIs
部署 Prometheus Adapter 後,您可以使用 kubectl 查詢自訂指標。 kubectl get —raw /apis/custom.metrics.k8s.io/v1beta1/
如名稱所示,外部指標可讓 Horizontal Pod Autoscaler 使用 Kubernetes 叢集外部的指標擴展部署。例如,在批次處理工作負載中,根據 SQS 佇列中正在執行的任務數量來擴展複本數量是很常見的。
若要自動擴展 Kubernetes 工作負載,您可以使用 KEDA (Kubernetes 事件驅動的 Autoscaling),這是可以根據多個自訂事件驅動容器擴展的開放原始碼專案。此 AWS 部落格
垂直 Pod Autoscaler (VPA)
VPA 會自動調整 Pod 的 CPU 和記憶體保留,以協助您「正確大小」的應用程式。對於需要垂直擴展的應用程式 - 透過增加資源配置來完成 - 您可以使用 VPA
如果 VPA 需要擴展應用程式,您的應用程式可能會暫時無法使用,因為 VPA 目前的實作不會對 Pod 執行就地調整;而是會重新建立需要擴展的 Pod。
EKS 文件包含設定 VPA 的逐步解說。
Fairwinds Goldilocks
更新應用程式
現代應用程式需要具有高度穩定性和可用性的快速創新。Kubernetes 為您提供工具來持續更新應用程式,而不會中斷您的客戶。
我們來看看一些最佳實務,可讓您快速部署變更,而不會犧牲可用性。
具有執行轉返的機制
使用復原按鈕可逃避災難。最佳實務是在不同的較低環境 (測試或開發環境) 中測試部署,然後再更新生產叢集。使用 CI/CD 管道可協助您自動化和測試部署。透過持續部署管道,如果升級發生瑕疵,您可以快速還原至較舊的版本。
您可以使用 部署來更新執行中的應用程式。這通常透過更新容器映像來完成。您可以使用 kubectl 更新部署,如下所示:
kubectl --record deployment.apps/nginx-deployment set image nginx-deployment nginx=nginx:1.16.1
--record 引數會記錄部署的變更,並在您需要執行復原時提供協助。 kubectl rollout history deployment會顯示叢集中部署的記錄變更。您可以使用 轉返變更kubectl rollout undo deployment <DEPLOYMENT_NAME>。
根據預設,當您更新需要重新建立 Pod 的部署時,部署會執行滾動更新RollingUpdateStrategy 屬性執行滾動更新。
執行部署的滾動更新時,您可以使用 Max UnavailableMax Surge 屬性可讓您設定可透過所需 Pod 數量建立的 Pod 數量上限。
考慮調整max unavailable以確保推展不會中斷您的客戶。例如,Kubernetes max unavailable 預設會設定 25%,這表示如果您有 100 個 Pod,您可能只有 75 個 Pod 在推展期間主動運作。如果您的應用程式需要至少 80 個 Pod,則此推展可能會中斷。反之,您可以將 max unavailable設定為 20%,以確保在整個推出期間至少有 80 個功能 Pod。
使用藍/綠部署
變更本質上具有風險,但無法復原的變更可能具有災難性。變更程序可讓您透過復原有效轉換時間,讓增強功能和實驗更安全。藍/綠部署可讓您在發生錯誤時快速撤回變更。在此部署策略中,您會為新版本建立環境。此環境與目前更新的應用程式版本相同。佈建新環境後,流量會路由至新環境。如果新版本產生所需的結果而不產生錯誤,則舊環境會終止。否則,流量會還原至舊版本。
您可以透過建立與現有版本部署相同的新部署,在 Kubernetes 中執行藍/綠部署。一旦確認新部署中的 Pod 執行時沒有發生錯誤,您可以在 服務中變更將流量路由至應用程式 Pod 的selector規格,以開始將流量傳送至新部署。
許多持續整合工具,例如 Flux
使用 Canary 部署
Canary 部署是藍/綠部署的變體,可大幅降低變更的風險。在此部署策略中,您會使用較少的 Pod 與舊部署建立新的部署,並將一小部分的流量轉移到新的部署。如果指標指出新版本的效能與現有版本相同或更好,您會逐步增加新部署的流量,同時向上擴展,直到將所有流量轉移到新部署為止。如果發生問題,您可以將所有流量路由到舊的部署,並停止傳送流量到新的部署。
雖然 Kubernetes 不提供執行 Canary 部署的原生方式,但您可以使用 Flagger
運作狀態檢查和自我修復
沒有任何軟體沒有錯誤,但 Kubernetes 可協助您將軟體故障的影響降至最低。在過去,如果應用程式當機,則有人必須透過手動重新啟動應用程式來修復情況。Kubernetes 可讓您偵測 Pod 中的軟體故障,並自動將其取代為新的複本。透過 Kubernetes,您可以監控應用程式的運作狀態,並自動取代運作狀態不佳的執行個體。
Kubernetes 支援三種類型的運作狀態檢查
-
活體探查
-
啟動探查 (Kubernetes 1.16+ 版支援)
-
準備度探查
Kubernetes 代理程式 Kubelet
如果您選擇在容器內執行 shell 指令碼exec的 型探查,請確保 shell 命令在timeoutSeconds值過期之前結束。否則,您的節點將具有 <defunct> 程序,導致節點失敗。
建議
使用 Liveness Probe 移除運作狀態不佳的 Pod
活體探查可以偵測程序繼續執行的死結條件,但應用程式變得沒有回應。例如,如果您正在執行在連接埠 80 上接聽的 Web 服務,您可以設定 Liveness 探查,以在 Pod 的連接埠 80 上傳送 HTTP GET 請求。Kubelet 會定期將 GET 請求傳送至 Pod 並預期回應;如果 Pod 在 200-399 之間回應,則 kubelet 會認為 Pod 運作狀態良好;否則,Pod 會標示為運作狀態不佳。如果 Pod 持續運作狀態檢查失敗,kubelet 會將其終止。
您可以使用 initialDelaySeconds 來延遲第一個探查。
使用 Liveness Probe 時,請確保應用程式不會遇到所有 Pod 同時失敗 Liveness Probe 的情況,因為 Kubernetes 會嘗試取代所有 Pod,這會使應用程式離線。此外,Kubernetes 將繼續建立新的 Pod,這也會使 Liveness Probes 失敗,對控制平面造成不必要的壓力。避免將 Liveness Probe 設定為取決於 Pod 外部的因素,例如外部資料庫。換言之,無回應external-to-your-Pod 資料庫不應讓您的 Pod 失敗其即時探查。
Sandor Szücs 的 LIVENESS PROBES 為危險
將 Startup Probe 用於需要更長的時間才能啟動的應用程式
當您的應用程式需要額外的時間啟動時,您可以使用啟動探查來延遲活體和準備度探查。例如,需要從資料庫補充快取的 Java 應用程式最多可能需要兩分鐘才能完全運作。任何存留期或準備度探查在完全運作前都可能失敗。設定啟動探查將允許 Java 應用程式在執行活體或準備度探查之前正常運作。
在啟動探查成功之前,所有其他探查都會停用。您可以定義 Kubernetes 應等待應用程式啟動的時間上限。如果在設定的時間上限之後,Pod 仍然失敗啟動探查,則會終止,並建立新的 Pod。
啟動探查類似於即時探查 – 如果失敗,則會重新建立 Pod。如同 Ricardo A. 在他的文章 Fantastic Probes 和如何設定它們initialDelaySeconds改用 Liveness/Readiness Probe 搭配 。
使用整備探查來偵測部分無法使用
雖然活體探查會偵測透過終止 Pod 解決的應用程式故障 (因此,重新啟動應用程式),但準備程度探查會偵測應用程式可能暫時無法使用的情況。在這些情況下,應用程式可能會暫時沒有回應;不過,一旦此操作完成,預期會再次正常運作。
例如,在密集磁碟 I/O 操作期間,應用程式可能暫時無法處理請求。在這裡,終止應用程式的 Pod 不是補救措施;同時,傳送至 Pod 的其他請求可能會失敗。
您可以使用整備探查來偵測應用程式中的暫時無法使用,並停止傳送請求至其 Pod,直到其再次運作為止。與 Liveness Probe 不同,失敗會導致 Pod 重新建立,失敗的準備程度探查表示 Pod 不會收到來自 Kubernetes Service 的任何流量。當整備探查成功時,Pod 會繼續接收來自 Service 的流量。
如同 Liveness Probe,避免設定依賴 Pod 外部資源 (例如資料庫) 的準備程度探查。以下案例顯示配置不佳的準備度會使應用程式無法運作 - 如果 Pod 的準備度探查在應用程式資料庫無法連線時失敗,其他 Pod 複本也會同時失敗,因為它們共用相同的運作狀態檢查條件。以這種方式設定探查將確保資料庫無法使用時,Pod 的整備探查將會失敗,而 Kubernetes 會停止傳送所有 Pod 的流量。
使用整備探查的副作用是,它們可以增加更新部署所需的時間。除非整備探查成功,否則新複本將不會接收流量;在此之前,舊複本將繼續接收流量。
處理中斷
Pod 的生命週期有限 - 即使您有長時間執行的 Pod,也請務必確保 Pod 在時間到時正確終止。根據您的升級策略,Kubernetes 叢集升級可能需要您建立新的工作者節點,這需要在較新的節點上重新建立所有 Pod。適當的終止處理和 Pod 中斷預算可協助您避免服務中斷,因為 Pod 從較舊的節點移除並在較新的節點上重新建立。
升級工作者節點的首選方法是建立新的工作者節點並終止舊節點。在終止工作者節點之前,您應該drain這麼做。當工作者節點耗盡時,會安全地移出其所有 Pod。安全地是這裡的關鍵字;當移出工作者上的 Pod 時,它們不只是傳送SIGKILL訊號。相反地,SIGTERM訊號會傳送至要移出之 Pod 中每個容器的主要程序 (PID 1)。傳送SIGTERM訊號後,Kubernetes 會在傳送SIGKILL訊號之前提供一些時間 (寬限期) 給程序。此寬限期預設為 30 秒;您可以在 kubectl 中使用grace-period旗標或在 Podspec terminationGracePeriodSeconds中宣告來覆寫預設值。
kubectl delete pod <pod name> —grace-period=<seconds>
容器的主要程序沒有 PID 1 時很常見。請考慮此以 Python 為基礎的範例容器:
$ kubectl exec python-app -it ps PID USER TIME COMMAND 1 root 0:00 {script.sh} /bin/sh ./script.sh 5 root 0:00 python app.py
在此範例中, shell 指令碼會接收 SIGTERM,這是主要程序,在此範例中剛好是 Python 應用程式,不會收到SIGTERM訊號。當 Pod 終止時,Python 應用程式會突然遭到刪除。您可以透過變更容器ENTRYPOINT
您也可以使用容器掛鉤PreStop 掛鉤動作會在容器收到SIGTERM訊號之前執行,且必須在傳送此訊號之前完成。該terminationGracePeriodSeconds值會在PreStop掛鉤動作開始執行時套用,而不是在傳送SIGTERM訊號時套用。
建議
使用 Pod 中斷預算保護關鍵工作負載
如果應用程式的複本數量低於宣告的閾值,Pod 中斷預算或 PDB 可以暫時停止移出程序。一旦可用的複本數量超過閾值,移出程序就會繼續。您可以使用 PDB 宣告複本的 minAvailable和 maxUnavailable數目。例如,如果您希望應用程式至少有三個副本可供使用,您可以建立 PDB。
apiVersion: policy/v1beta1 kind: PodDisruptionBudget metadata: name: my-svc-pdb spec: minAvailable: 3 selector: matchLabels: app: my-svc
上述 PDB 政策會指示 Kubernetes 停止移出程序,直到有三個或更多複本可用為止。節點耗盡遵守 PodDisruptionBudgets。在 EKS 受管節點群組升級期間,節點會以十五分鐘的逾時耗盡。十五分鐘後,如果未強制更新 (EKS 主控台中的 選項稱為滾動更新),則更新會失敗。如果強制更新,則會刪除 Pod。
對於自我管理節點,您也可以使用 AWS Node Termination Handler
您可以使用 Pod 反親和性來排程不同節點上的部署 Pod,並避免節點升級期間的 PDB 相關延遲。
練習混沌工程
Chaos Engineering 是在分散式系統上進行實驗的紀律,以建立對系統承受生產環境中亂流條件的能力的信心。
在他的部落格中,Dominik Tornow 解釋 Kubernetes 是一種宣告式系統replica當機,部署 Contollerreplica。如此一來,Kubernetes 控制器會自動修正故障。
Gremlin
使用服務網格
您可以使用服務網格來改善應用程式的彈性。服務網格可啟用service-to-service通訊,並提高微服務網路的可觀測性。大多數服務網格產品的運作方式是讓小型網路代理與攔截和檢查應用程式網路流量的每個服務一起執行。您可以將應用程式放在網格中,而無需修改應用程式。使用服務代理的內建功能,您可以讓它產生網路統計資料、建立存取日誌,以及將 HTTP 標頭新增至傳出請求以進行分散式追蹤。
服務網格可協助您透過自動請求重試、逾時、中斷電路和限制速率等功能,讓您的微服務更具彈性。
如果您操作多個叢集,您可以使用服務網格來啟用跨叢集service-to-service通訊。
服務網格
可觀測性
可觀測性是一個包含監控、記錄和追蹤的概括術語。微服務型應用程式本質上會進行分佈。與監控單一系統的單一應用程式不同,在分散式應用程式架構中,您需要監控每個元件的效能。您可以使用叢集層級監控、記錄和分散式追蹤系統來識別叢集中的問題,然後再中斷您的客戶。
用於疑難排解和監控的 Kubernetes 內建工具有限。指標伺服器會收集資源指標並將其儲存在記憶體中,但不會保留它們。您可以使用 kubectl 檢視 Pod 的日誌,但 Kubernetes 不會自動保留日誌。而分散式追蹤的實作是在應用程式程式碼層級或使用 服務網格來完成。
Kubernetes 的可擴展性在此呈現。Kubernetes 可讓您使用偏好的集中式監控、記錄和追蹤解決方案。
建議
監控您的應用程式
您需要在現代應用程式中監控的指標數量持續增加。如果您有自動追蹤應用程式的方式,可以協助您專注於解決客戶的挑戰。Prometheus
監控工具可讓您建立營運團隊可訂閱的提醒。考慮規則,以針對可能在加劇時導致中斷或影響應用程式效能的事件啟用警示。
如果您不確定應該監控哪些指標,可以從這些方法中獲取啟發:
Sysdig 在 Kubernetes 上提醒的後期最佳實務
使用 Prometheus 用戶端程式庫公開應用程式指標
除了監控應用程式的狀態和彙總標準指標之外,您也可以使用 Prometheus 用戶端程式庫
使用集中式記錄工具來收集和保留日誌
在 EKS 中記錄分為兩個類別:控制平面日誌和應用程式日誌。EKS 控制平面記錄會將稽核和診斷日誌直接從控制平面提供給帳戶中的 CloudWatch Logs。應用程式日誌是叢集內執行的 Pod 所產生的日誌。應用程式日誌包含執行商業邏輯應用程式和 Kubernetes 系統元件的 Pod 所產生的日誌,例如 CoreDNS、Cluster Autoscaler、Prometheus 等。
-
Kubernetes API 伺服器元件日誌
-
稽核
-
驗證器
-
控制器管理員
-
排程器
控制器管理員和排程器日誌可協助診斷控制平面問題,例如瓶頸和錯誤。根據預設,EKS 控制平面日誌不會傳送至 CloudWatch Logs。您可以啟用控制平面記錄,然後選取您要為帳戶中的每個叢集擷取的 EKS 控制平面日誌類型
收集應用程式日誌需要在您的叢集中安裝日誌彙總工具,例如 Fluent Bit
Kubernetes 日誌彙總工具會以 DaemonSets 的形式執行,並從節點抓取容器日誌。然後,應用程式日誌會傳送到集中式目的地進行儲存。例如,CloudWatch Container Insights 可以使用 Fluent Bit 或 Fluentd 來收集日誌,並將其運送到 CloudWatch Logs 進行儲存。Fluent Bit 和 Fluentd 支援許多熱門日誌分析系統,例如 Elasticsearch 和 InfluxDB,可讓您透過修改 Fluent 位元或 Fluentd 的日誌組態來變更日誌的儲存後端。
使用分散式追蹤系統來識別瓶頸
典型的現代應用程式具有透過網路分佈的元件,其可靠性取決於組成應用程式的每個元件是否正常運作。您可以使用分散式追蹤解決方案來了解請求流程和系統通訊的方式。追蹤可以顯示應用程式網路中存在的瓶頸,並防止可能導致串聯失敗的問題。
您有兩個選項可在應用程式中實作追蹤:您可以使用共用程式庫在程式碼層級實作分散式追蹤,或使用服務網格。
在程式碼層級實作追蹤可能不利。在此方法中,您必須變更程式碼。如果您有多槽應用程式,這會更複雜。您也必須負責維護您服務中的另一個程式庫。
LinkerD
Jaeger
請考慮使用支援 (共用程式庫和服務網格) 實作的 AWS X-Ray
