本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
JDBC 自動產生結構描述
Amazon DocumentDB 是文件資料庫,因此沒有資料表和結構描述的概念。不過,Tableau 等 BI 工具預期其連線的資料庫會呈現結構描述。具體而言,當 JDBC 驅動程式連線需要取得資料庫中集合的結構描述時,它會輪詢資料庫中的所有集合。驅動程式將判斷該集合的結構描述快取版本是否已存在。如果快取版本不存在,它會取樣文件的集合,並根據下列行為建立結構描述。
結構描述產生限制
DocumentDB JDBC 驅動程式對識別符的長度施加 128 個字元的限制。結構描述產生器可能會截斷產生的識別符 (資料表名稱和資料欄名稱) 的長度,以確保它們符合該限制。
掃描方法選項
您可以使用連線字串或資料來源選項來修改抽樣行為。
-
scanMethod=<option>
-
random - (預設) - 以隨機順序傳回範例文件。
-
idForward - 依 ID 順序傳回範例文件。
-
idReverse - 以 ID 的相反順序傳回範例文件。
-
all - 取樣集合中的所有文件。
-
-
scanLimit=<n> - 要取樣的文件數量。其值必須為正整數。預設值為 1000。如果 scanMethod 設為全部,則會忽略此選項。
Amazon DocumentDB 資料類型
Amazon DocumentDB 伺服器支援多種 MongoDB 資料類型。以下列出支援的資料類型及其相關聯的 JDBC 資料類型。
| MongoDB 資料類型 | DocumentDB 支援 | JDBC 資料類型 |
|---|---|---|
| 二進位資料 | 是 | VARBINARY |
| Boolean | 是 | BOOLEAN |
| Double | 是 | DOUBLE |
| 32 位元整數 | 是 | INTEGER |
| 64 位元整數 | 是 | BIGINT |
| String | 是 | VARCHAR |
| ObjectId | 是 | VARCHAR |
| Date | 是 | TIMESTAMP |
| Null | 是 | VARCHAR |
| 規則表達式 | 是 | VARCHAR |
| 時間戳記 | 是 | VARCHAR |
| MinKey | 是 | VARCHAR |
| MaxKey | 是 | VARCHAR |
| 物件 | 是 | 虛擬資料表 |
| 陣列 | 是 | 虛擬資料表 |
| Decimal128 | 否 | DECIMAL |
| JavaScript | 否 | VARCHAR |
| JavaScript (含範圍) | 否 | VARCHAR |
| 未定義 | 否 | VARCHAR |
| Symbol | 否 | VARCHAR |
| DBPointer (4.0+) | 否 | VARCHAR |
映射純量文件欄位
從集合掃描文件範例時,JDBC 驅動程式會建立一或多個結構描述,以代表集合中的範例。一般而言,文件中的純量欄位會映射至資料表結構描述中的資料欄。例如,在名為 團隊和單一文件 的集合中{ "_id" : "112233", "name" : "Alastair", "age": 25 },這會映射到結構描述:
| 資料表名稱 | 資料行名稱 | 資料類型 | 金錀 |
|---|---|---|---|
| 團隊 | 團隊 ID | VARCHAR | PK |
| 團隊 | name | VARCHAR | |
| 團隊 | age | INTEGER |
資料類型衝突提升
掃描抽樣文件時,欄位的資料類型可能因文件而不一致。在此情況下,JDBC 驅動程式會將 JDBC 資料類型提升為通用資料類型,以符合抽樣文件中的所有資料類型。
例如:
{ "_id" : "112233", "name" : "Alastair", "age" : 25 } { "_id" : "112244", "name" : "Benjamin", "age" : "32" }
存留期欄位在第一個文件中為 32 位元整數類型,但在第二個文件中為字串。在這裡,JDBC 驅動程式會將 JDBC 資料類型提升為 VARCHAR,以便在遇到時處理任一資料類型。
| 資料表名稱 | 資料行名稱 | 資料類型 | 金錀 |
|---|---|---|---|
| 團隊 | 團隊 ID | VARCHAR | PK |
| 團隊 | name | VARCHAR | |
| 團隊 | age | VARCHAR |
純量衝突提升
下圖顯示純量-純量資料類型衝突的解決方式。
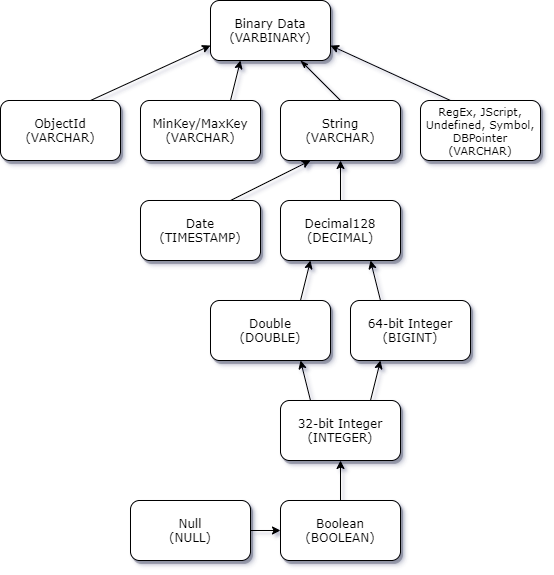
Scalar-complex 類型衝突提升
與純量類型衝突一樣,不同文件中的相同欄位在複雜 (陣列和物件) 和純量 (整數、布林值等) 之間可能會有衝突的資料類型。所有這些衝突都會針對這些欄位解析 (提升) 為 VARCHAR。在此情況下,陣列和物件資料會以 JSON 表示法傳回。
內嵌陣列 - 字串欄位衝突範例:
{ "_id":"112233", "name":"George Jackson", "subscriptions":[ "Vogue", "People", "USA Today" ] } { "_id":"112244", "name":"Joan Starr", "subscriptions":1 }
上述範例映射至 customer2 資料表的結構描述:
| 資料表名稱 | 資料行名稱 | 資料類型 | 金錀 |
|---|---|---|---|
| customer2 | customer2 ID | VARCHAR | PK |
| customer2 | name | VARCHAR | |
| customer2 | 訂閱 | VARCHAR |
和 customer1_subscriptions 虛擬資料表:
| 資料表名稱 | 資料行名稱 | 資料類型 | 金錀 |
|---|---|---|---|
| customer1_subscriptions | customer1 ID | VARCHAR | PK/FK |
| customer1_subscriptions | subscriptions_index_lvl0 | BIGINT | PK |
| customer1_subscriptions | value | VARCHAR | |
| customer_address | 城市 | VARCHAR | |
| customer_address | region | VARCHAR | |
| customer_address | 國家/地區 | VARCHAR | |
| customer_address | code | VARCHAR |
物件和陣列資料類型處理
到目前為止,我們只描述了純量資料類型的映射方式。物件和陣列資料類型會 (目前) 映射至虛擬資料表。JDBC 驅動程式會建立虛擬資料表,以代表文件中的物件或陣列欄位。映射虛擬資料表的名稱會串連原始集合的名稱,後面接著以底線字元 ("_") 分隔的欄位名稱。
基礎資料表的主索引鍵 ("_id") 會採用新虛擬資料表中的新名稱,並以外部索引鍵的形式提供給相關聯的基礎資料表。
對於內嵌陣列類型欄位,會產生索引欄,以在陣列的每個層級將索引表示為陣列。
內嵌物件欄位範例
對於文件中的物件欄位,JDBC 驅動程式會建立虛擬資料表的映射。
{ "Collection: customer", "_id":"112233", "name":"George Jackson", "address":{ "address1":"123 Avenue Way", "address2":"Apt. 5", "city":"Hollywood", "region":"California", "country":"USA", "code":"90210" } }
上述範例映射到客戶資料表的結構描述:
| 資料表名稱 | 資料行名稱 | 資料類型 | 金錀 |
|---|---|---|---|
| customer | 客戶 ID | VARCHAR | PK |
| customer | name | VARCHAR |
和 customer_address 虛擬資料表:
| 資料表名稱 | 資料行名稱 | 資料類型 | 金錀 |
|---|---|---|---|
| customer_address | 客戶 ID | VARCHAR | PK/FK |
| customer_address | 地址 1 | VARCHAR | |
| customer_address | address2 | VARCHAR | |
| customer_address | 城市 | VARCHAR | |
| customer_address | region | VARCHAR | |
| customer_address | 國家/地區 | VARCHAR | |
| customer_address | code | VARCHAR |
內嵌陣列欄位範例
對於文件中的陣列欄位,JDBC 驅動程式也會建立虛擬資料表的映射。
{ "Collection: customer1", "_id":"112233", "name":"George Jackson", "subscriptions":[ "Vogue", "People", "USA Today" ] }
上述範例映射至 customer1 資料表的結構描述:
| 資料表名稱 | 資料行名稱 | 資料類型 | 金錀 |
|---|---|---|---|
| customer1 | customer1 ID | VARCHAR | PK |
| customer1 | name | VARCHAR |
和 customer1_subscriptions 虛擬資料表:
| 資料表名稱 | 資料行名稱 | 資料類型 | 金錀 |
|---|---|---|---|
| customer1_subscriptions | customer1 ID | VARCHAR | PK/FK |
| customer1_subscriptions | subscriptions_index_lvl0 | BIGINT | PK |
| customer1_subscriptions | value | VARCHAR | |
| customer_address | 城市 | VARCHAR | |
| customer_address | region | VARCHAR | |
| customer_address | 國家/地區 | VARCHAR | |
| customer_address | code | VARCHAR |
