本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
當您查詢知識庫時,Amazon Bedrock 預設會在回應中傳回最多五個結果。每個結果對應至來源區塊。
回應中的實際結果數目可能小於指定的 numberOfResults 值,因為此參數會設定要傳回的結果數目上限。如果您已為分塊策略設定階層式分塊,numberOfResults 參數會對應至知識庫將擷取的子區塊數量。由於共用相同父區塊的子區塊會取代為最終回應中的父區塊,因此傳回的結果數目可能會小於請求的數量。
若要修改要傳回的結果數量上限,請選擇您偏好方法的索引標籤,然後遵循下列步驟:
- Console
-
請遵循 查詢知識庫並擷取資料 或 查詢知識庫並根據擷取的資料產生回應 的主控台步驟。在組態窗格中,展開來源區塊區段,然後輸入要傳回的來源區塊數目上限。
- API
當您提出 Retrieve 或 RetrieveAndGenerate 請求時,請包含對應至 KnowledgeBaseRetrievalConfiguration 物件的 retrievalConfiguration 欄位。若要查看此欄位的位置,請參閱 API 參考中的 Retrieve 和 RetrieveAndGenerate 請求內文。
下列 JSON 物件顯示設定要傳回的結果數目上限時,KnowledgeBaseRetrievalConfiguration 物件中所需的最少欄位:
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"numberOfResults": number
}
}
指定要在 numberOfResults 欄位中傳回的擷取結果數目上限 (請參閱 KnowledgeBaseRetrievalConfiguration 中的 numberOfResults 欄位,以取得接受值的範圍)。
搜尋類型會定義如何查詢知識庫中的資料來源。可能的搜尋類型如下:
只有包含可篩選文字欄位的 Amazon RDS、Amazon OpenSearch Serverless 和 MongoDB 向量存放區才支援混合搜尋。如果您使用不同的向量存放區,或您的向量存放區不包含可篩選的文字欄位,則查詢會使用語義搜尋。
若要了解如何定義搜尋類型,請選擇您偏好方法的索引標籤,然後遵循下列步驟:
- Console
-
請遵循 查詢知識庫並擷取資料 或 查詢知識庫並根據擷取的資料產生回應 的主控台步驟。當您開啟組態窗格時,請展開搜尋類型區段、開啟覆寫預設搜尋,然後選取選項。
- API
當您提出 Retrieve 或 RetrieveAndGenerate 請求時,請包含對應至 KnowledgeBaseRetrievalConfiguration 物件的 retrievalConfiguration 欄位。若要查看此欄位的位置,請參閱 API 參考中的 Retrieve 和 RetrieveAndGenerate 請求內文。
下列 JSON 物件顯示設定搜尋類型組態時,KnowledgeBaseRetrievalConfiguration 物件中所需的最少欄位:
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"overrideSearchType": "HYBRID | SEMANTIC"
}
}
在 overrideSearchType 欄位中指定搜尋類型。您有下列選項:
-
如果您未指定值,Amazon Bedrock 會決定哪種搜尋策略最適合您的向量存放區組態。
-
混合 – Amazon Bedrock 會使用向量嵌入和原始文字來查詢知識庫。
-
語義 – Amazon Bedrock 會使用其向量嵌入來查詢知識庫。
- Console
-
請遵循 查詢知識庫並根據擷取的資料產生回應 的主控台步驟。當您開啟組態窗格時,請展開串流偏好設定區段,並開啟串流回應。
- API
-
若要串流回應,請使用 RetrieveAndGenerateStream API。如需填寫欄位的詳細資訊,請參閱位於 查詢知識庫並根據擷取的資料產生回應 的 API 索引標籤。
您可以將篩選條件套用至文件欄位/屬性,以協助您進一步改善回應的相關性。您的資料來源可以包含要篩選的文件中繼資料屬性/欄位,並可以指定要包含在嵌入中的欄位。
例如,"epoch_modification_time" 代表文件上次更新時,自 1970 年 1 月 1 日 (UTC) 以來的秒數。您可以篩選最近的資料,其中「epoch_modification_time」大於特定數字。這些最新的文件可用於查詢。
若要在查詢知識庫時使用篩選條件,請檢查您的知識庫是否符合下列要求:
-
設定資料來源連接器時,大多數連接器會網路爬取文件的主要中繼資料欄位。如果您使用 Amazon S3 儲存貯體作為資料來源,則儲存貯體必須至少包含一個 fileName.extension.metadata.json 以用於與其相關聯的檔案或文件。如需設定中繼資料檔案的詳細資訊,請參閱 連線組態 中的文件中繼資料欄位。
-
如果您知識庫的向量索引位於 Amazon OpenSearch Serverless 向量存放區中,請檢查向量索引是否已使用 faiss 引擎設定。如果向量索引是使用 nmslib 引擎設定,您必須執行下列其中一項操作:
-
如果您的知識庫在 S3 向量儲存貯體中使用向量索引,則無法使用 startsWith 和 stringContains 篩選條件。
-
如果您要將中繼資料新增至 Amazon Aurora 資料庫叢集中的現有向量索引,建議您提供自訂中繼資料資料欄的欄位名稱,以將所有中繼資料存放在單一資料欄中。在資料擷取期間,此欄將用於從資料來源填入中繼資料檔案中的所有資訊。如果您選擇提供此欄位,則必須在此資料欄上建立索引。
-
當您在主控台中建立新的知識庫,並讓 Amazon Bedrock 設定您的 Amazon Aurora 資料庫時,它會自動為您建立單一資料欄,並填入中繼資料檔案中的資訊。
-
當您選擇在向量存放區中建立另一個向量索引時,必須提供自訂中繼資料欄位名稱,以存放中繼資料檔案中的資訊。如果您未提供此欄位名稱,則必須為檔案中的每個中繼資料屬性建立資料欄,並指定資料類型 (文字、數字或布林值)。例如,如果您的資料來源中存在屬性 genre,您可以新增名為 genre 的資料欄,並將 text 指定為資料類型。在擷取期間,這些個別的資料欄會填入對應的屬性值。
如果您的資料來源中有 PDF 文件,並將 Amazon OpenSearch Serverless 或 Amazon Aurora 用於向量存放區:Amazon Bedrock 知識庫會產生文件頁碼,並將其存放在名為 x-amz-bedrock-kb-document-page-number 的中繼資料欄位/屬性中。請注意,如果您沒有為文件選擇分塊,則不支援存放在中繼資料欄位中的頁碼。
您可以在查詢時使用下列篩選運算子來篩選結果:
篩選運算子
| 運算子 |
主控台 |
API 篩選條件名稱 |
支援的屬性資料類型 |
篩選結果 |
| Equals |
= |
等於 |
字串、數字、布林值 |
屬性符合您提供的值 |
| 不等於 |
!= |
notEquals |
字串、數字、布林值 |
屬性不符合您提供的值 |
| Greater than |
> |
greaterThan |
number |
屬性大於您提供的值 |
| 大於或等於 |
>= |
greaterThanOrEquals |
number |
屬性大於或等於您提供的值 |
| Less than |
< |
lessThan |
number |
屬性小於您提供的值 |
| 小於或等於 |
<= |
lessThanOrEquals |
number |
屬性小於或等於您提供的值 |
| In (入) |
: |
在 中 |
字串清單 |
屬性位於您提供的清單中 (Amazon OpenSearch Serverless 和 Neptune Analytics GraphRAG 向量存放區目前最受支援) |
| 不在 |
!: |
notIn |
字串清單 |
屬性不在您提供的清單中 (Amazon OpenSearch Serverless 和 Neptune Analytics GraphRAG 向量存放區目前最受支援) |
| 字串包含 |
不適用 |
stringContains |
string |
屬性必須是字串。屬性名稱符合索引鍵,且其值為包含您以子字串提供之值的字串,或包含您以子字串提供之值的成員清單 (目前 Amazon OpenSearch Serverless 向量存放區最受支援。Neptune Analytics GraphRAG 向量存放區支援字串變體,但不支援此篩選條件的清單變體)。 |
| 清單包含 |
不適用 |
listContains |
string |
屬性必須是字串清單。屬性名稱符合金鑰,且其值是包含您作為其成員之一所提供值的清單 (目前 Amazon OpenSearch Serverless 向量存放區最受支援)。 |
若要結合篩選運算子,您可以使用下列邏輯運算子:
邏輯運算子
| 運算子 |
主控台 |
API 篩選條件欄位名稱 |
篩選結果 |
| 及 |
及 |
andAll |
結果滿足群組中的所有篩選表達式 |
| 或 |
或 |
orAll |
結果至少滿足群組中其中一個篩選表達式 |
若要了解如何使用中繼資料篩選結果,請選擇您偏好方法的標籤,然後遵循下列步驟:
- Console
-
請遵循 查詢知識庫並擷取資料 或 查詢知識庫並根據擷取的資料產生回應 的主控台步驟。當您開啟組態窗格時,您會看到篩選條件區段。下列程序說明不同的使用案例:
-
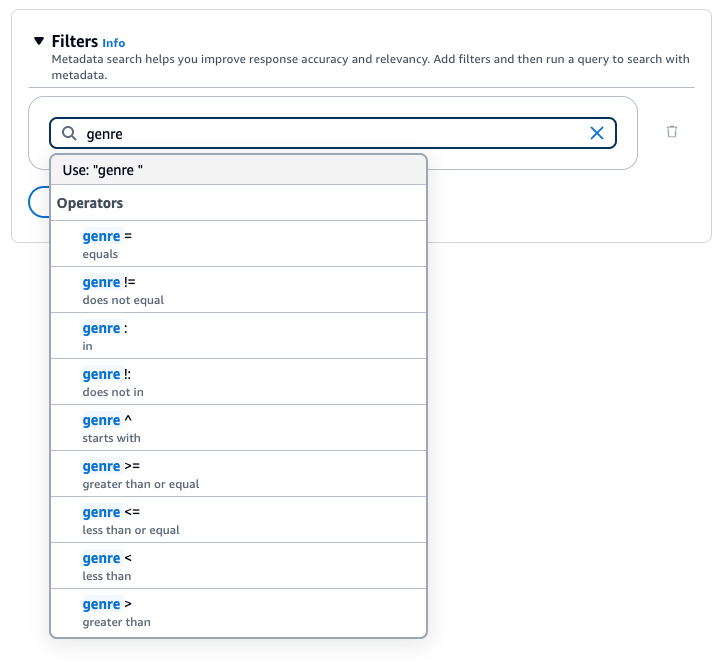
若要新增篩選條件,請在方塊中輸入中繼資料屬性、篩選運算子和值來建立篩選表達式。使用空格來分隔表達式的每個部分。按 Enter 以新增篩選條件。
如需可接受的篩選運算子清單,請參閱上方的篩選運算子資料表。您也可以在中繼資料屬性之後新增空格時,查看篩選運算子的清單。
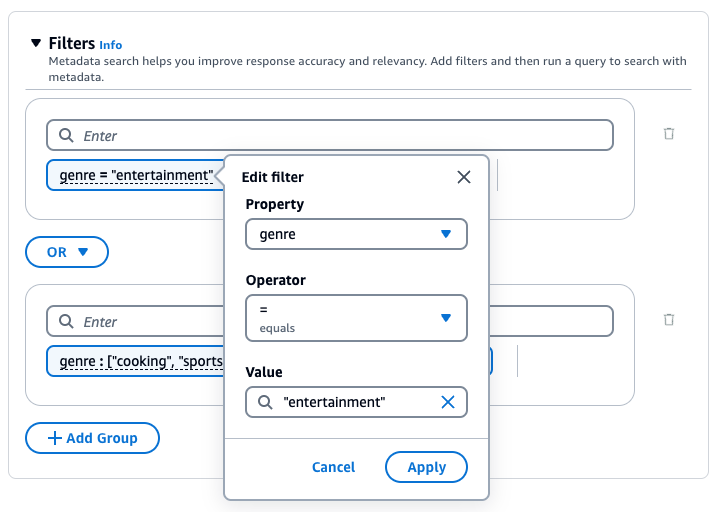
例如,您可以新增下列篩選條件,從包含其值為 "entertainment" 之 genre 中繼資料屬性的來源文件中篩選結果:genre = "entertainment"。
-
若要新增另一個篩選條件,請在方塊中輸入另一個篩選表達式,然後按 Enter。您最多可以在群組中新增 5 個篩選條件。
-
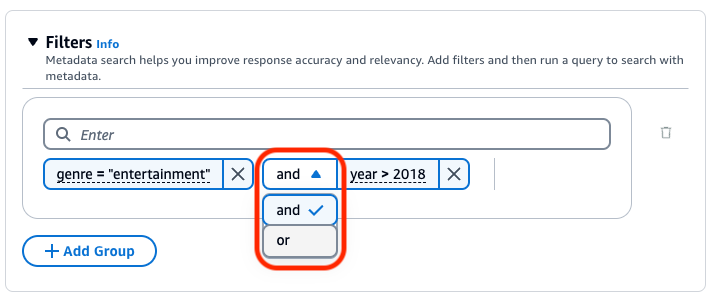
根據預設,查詢會傳回滿足您提供的所有篩選表達式的結果。若要傳回至少滿足其中一個篩選表達式的結果,請在任兩個篩選操作之間選擇和下拉式功能表,然後選取或。
-
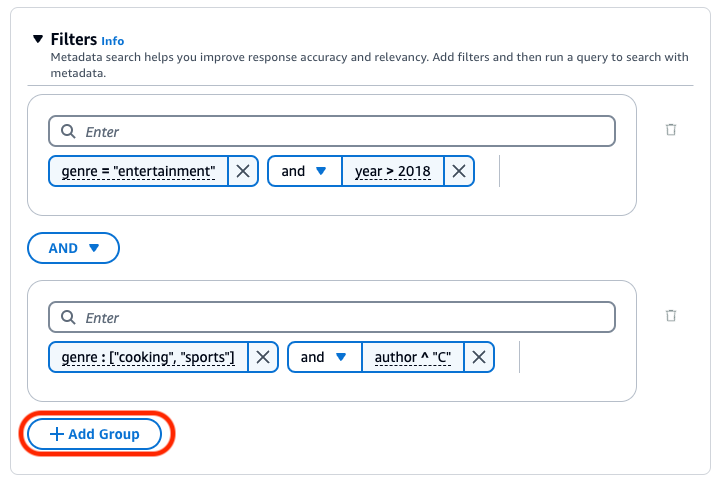
若要結合不同的邏輯運算子,請選取 + 新增群組以新增篩選條件群組。在新群組中輸入篩選表達式。您最多可以新增 5 個篩選條件群組。
-
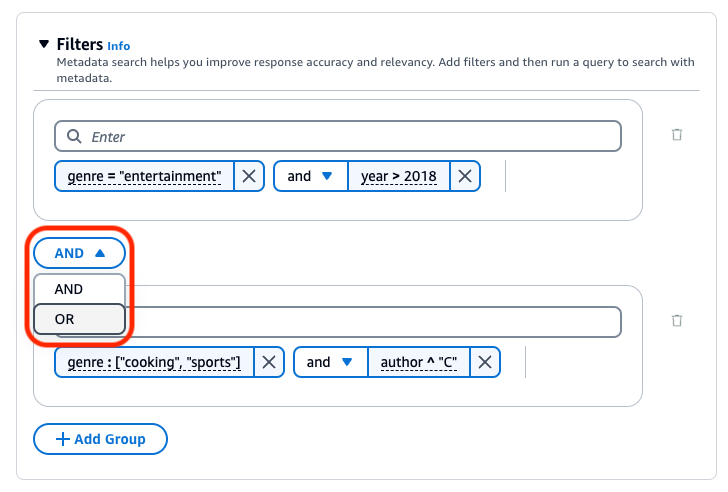
若要變更所有篩選群組之間使用的邏輯運算子,請在任兩個篩選群組之間選擇和下拉式功能表,然後選取或。
-
若要編輯篩選條件、選取篩選條件、修改篩選操作,然後選擇套用。
-
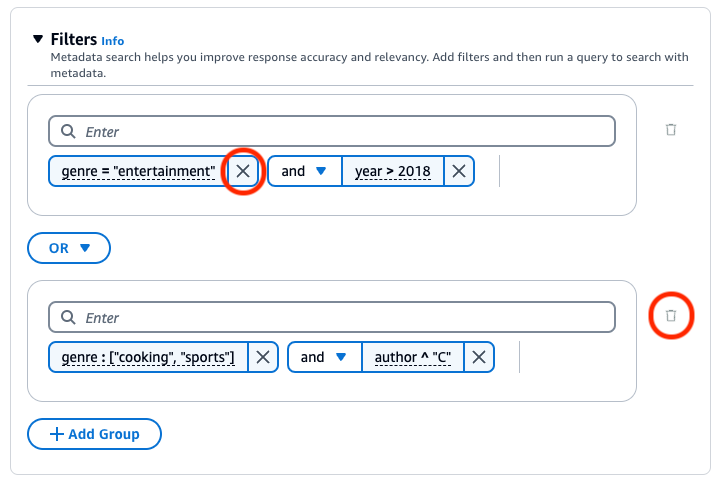
若要移除篩選條件群組,請選擇群組旁的垃圾桶圖示 (
 )。若要移除篩選條件,請選擇篩選條件旁的刪除圖示 (
)。若要移除篩選條件,請選擇篩選條件旁的刪除圖示 (
 )。
)。
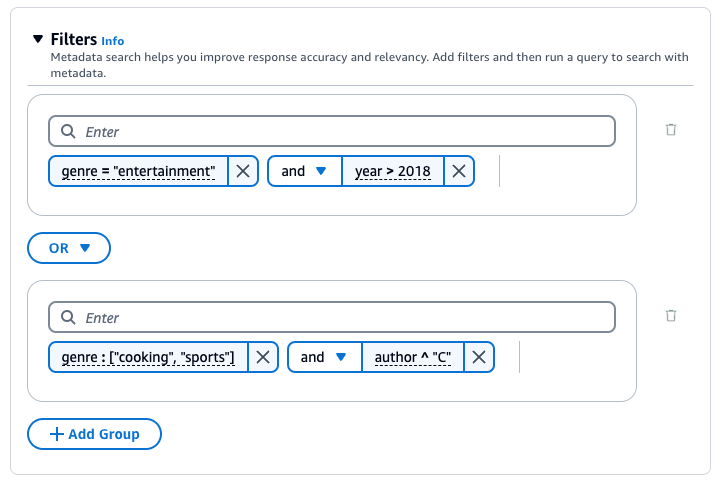
下圖顯示範例篩選條件組態,除了類型為 "cooking" 或 "sports" 且作者以 "C" 開頭的文件之外,還傳回在 2018 後寫入且類型為 "entertainment" 的所有文件。
- API
當您提出 Retrieve 或 RetrieveAndGenerate 請求時,請包含對應至 KnowledgeBaseRetrievalConfiguration 物件的 retrievalConfiguration 欄位。若要查看此欄位的位置,請參閱 API 參考中的 Retrieve 和 RetrieveAndGenerate 請求內文。
下列 JSON 物件顯示設定不同使用案例的篩選條件時,KnowledgeBaseRetrievalConfiguration 物件中所需的最少欄位:
-
使用一個篩選運算子 (請參閱上方的篩選運算子資料表)。
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"filter": {
"<filter-type>": {
"key": "string",
"value": "string" | number | boolean | ["string", "string", ...]
}
}
}
}
-
使用邏輯運算子 (請參閱上方的邏輯運算子資料表) 來結合最多 5 個運算子。
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"filter": {
"andAll | orAll": [
"<filter-type>": {
"key": "string",
"value": "string" | number | boolean | ["string", "string", ...]
},
"<filter-type>": {
"key": "string",
"value": "string" | number | boolean | ["string", "string", ...]
},
...
]
}
}
}
-
使用邏輯運算子以將最多 5 個篩選運算子合併為篩選條件群組,並使用第二個邏輯運算子將該篩選條件群組與其他篩選運算子合併。
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"filter": {
"andAll | orAll": [
"andAll | orAll": [
"<filter-type>": {
"key": "string",
"value": "string" | number | boolean | ["string", "string", ...]
},
"<filter-type>": {
"key": "string",
"value": "string" | number | boolean | ["string", "string", ...]
},
...
],
"<filter-type>": {
"key": "string",
"value": "string" | number | boolean | ["string", "string", ...]
}
]
}
}
}
-
將最多 5 個篩選條件群組嵌入在另一個邏輯運算子中,以結合這些群組。您可以建立一個嵌入層級。
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"filter": {
"andAll | orAll": [
"andAll | orAll": [
"<filter-type>": {
"key": "string",
"value": "string" | number | boolean | ["string", "string", ...]
},
"<filter-type>": {
"key": "string",
"value": "string" | number | boolean | ["string", "string", ...]
},
...
],
"andAll | orAll": [
"<filter-type>": {
"key": "string",
"value": "string" | number | boolean | ["string", "string", ...]
},
"<filter-type>": {
"key": "string",
"value": "string" | number | boolean | ["string", "string", ...]
},
...
]
]
}
}
}
下表說明您可以使用的篩選條件類型:
| 欄位 |
支援的值資料類型 |
篩選結果 |
equals |
字串、數字、布林值 |
屬性符合您提供的值 |
notEquals |
字串、數字、布林值 |
屬性不符合您提供的值 |
greaterThan |
number |
屬性大於您提供的值 |
greaterThanOrEquals |
number |
屬性大於或等於您提供的值 |
lessThan |
number |
屬性小於您提供的值 |
lessThanOrEquals |
number |
屬性小於或等於您提供的值 |
in |
字串清單 |
屬性位於您提供的清單中 |
notIn |
字串清單 |
屬性不在您提供的清單中 |
startsWith |
string |
屬性開頭為您提供的字串 (僅 Amazon OpenSearch Serverless 向量存放區可支援) |
若要合併篩選條件類型,您可以使用下列其中一個邏輯運算子:
| 欄位 |
對應至 |
篩選結果 |
andAll |
最多 5 個篩選條件類型的清單 |
結果滿足群組中的所有篩選表達式 |
orAll |
最多 5 個篩選條件類型的清單 |
結果至少滿足群組中其中一個篩選表達式 |
如需範例,請參閱傳送查詢並包含篩選條件 (擷取) 和傳送查詢並包含篩選條件 RetrieveAndGenerate)。
Amazon Bedrock 知識庫會根據使用者查詢和中繼資料結構描述產生並套用擷取篩選條件。
Anthropic Claude 模型支援隱含中繼資料篩選。如需支援模型的詳細資訊,請參閱模型一目了然。
implicitFilterConfiguration 會在 Retrieve 請求內文的 vectorSearchConfiguration 中指定。包含下列欄位:
以下顯示您可以在 metadataAttributes 中新增至陣列的中繼資料結構描述範例。
[
{
"key": "company",
"type": "STRING",
"description": "The full name of the company. E.g. `Amazon.com, Inc.`, `Alphabet Inc.`, etc"
},
{
"key": "ticker",
"type": "STRING",
"description": "The ticker name of a company in the stock market, e.g. AMZN, AAPL"
},
{
"key": "pe_ratio",
"type": "NUMBER",
"description": "The price to earning ratio of the company. This is a measure of valuation of a company. The lower the pe ratio, the company stock is considered chearper."
},
{
"key": "is_us_company",
"type": "BOOLEAN",
"description": "Indicates whether the company is a US company."
},
{
"key": "tags",
"type": "STRING_LIST",
"description": "Tags of the company, indicating its main business. E.g. `E-commerce`, `Search engine`, `Artificial intelligence`, `Cloud computing`, etc"
}
]
您可以針對使用案例和負責任的 AI 原則的知識庫實作保護措施。您可以針對不同的使用案例量身制訂多項防護機制,並將其套用至多種請求與回應條件,藉此提供一致的使用者體驗,並對您的知識庫實施標準化的安全管控。您可以設定拒絕的主題,以禁止不適當的主題,並且設定內容篩選器來封鎖模型輸入和回應中的有害內容。如需詳細資訊,請參閱使用 Amazon Bedrock 防護機制偵測和篩選有害內容。
Claude 3 Sonnet 和 Haiku 目前不支援將防護機制與知識庫的內容關聯依據搭配使用。
如需一般提示工程指導方針,請參閱 提示工程概念。
選擇您偏好方法的索引標籤,然後遵循下列步驟:
- Console
-
請遵循 查詢知識庫並擷取資料 或 查詢知識庫並根據擷取的資料產生回應 的主控台步驟。在測試視窗中,開啟產生回應。然後,在組態窗格中,展開防護機制區段。
-
在防護機制區段中,選擇防護機制的名稱和版本。如果您想要查看所選防護機制和版本的詳細資訊,請選擇檢視。
或者,您可以選擇防護機制連結來建立新的防護機制。
-
完成編輯後,請選擇 Save changes (儲存變更)。若要退出而不儲存,請選擇捨棄變更。
- API
-
當您提出 RetrieveAndGenerate 請求時,請在 generationConfiguration 中包含 guardrailConfiguration 欄位,以搭配請求使用您的防護機制。若要查看此欄位的位置,請參閱 API 參考中的 RetrieveAndGenerate 請求內文。
下列 JSON 物件顯示設定 guardrailConfiguration 時,GenerationConfiguration 中所需的最少欄位:
"generationConfiguration": {
"guardrailConfiguration": {
"guardrailId": "string",
"guardrailVersion": "string"
}
}
指定所選防護機制的 guardrailId 和 guardrailVersion。
您可以使用重新排名器模型來重新排名知識庫查詢的結果。請遵循 查詢知識庫並擷取資料 或 查詢知識庫並根據擷取的資料產生回應 的主控台步驟。當您開啟組態窗格時,請展開重新排名區段。選取重新排名器模型、視需要更新許可,並修改任何其他選項。輸入提示,然後選取執行以在重新排名後測試結果。
查詢分解是一種技術,用於將複雜的查詢分解為更小、更易於管理的子查詢。這種方法有助於擷取更準確和相關的資訊,特別是當初始查詢具有多面向或過於廣泛時。啟用此選項可能會導致針對您的知識庫執行多個查詢,這可能有助於提供更準確的最終回應。
例如,對於「在 2022 年 FIFA 世界盃中,阿根廷或法國誰獲得更高的分數?」之類的問題,Amazon Bedrock 知識庫可能會先產生下列子查詢,然後再產生最終回答:
-
阿根廷在 2022 FIFA 世界盃決賽中獲得了幾分?
-
法國在 2022 FIFA 世界盃決賽中獲得了幾分?
- Console
-
-
建立和同步資料來源或使用現有的知識庫。
-
前往測試視窗並開啟組態面板。
-
啟用查詢分解。
- API
-
POST /retrieveAndGenerate HTTP/1.1
Content-type: application/json
{
"input": {
"text": "string"
},
"retrieveAndGenerateConfiguration": {
"knowledgeBaseConfiguration": {
"orchestrationConfiguration": { // Query decomposition
"queryTransformationConfiguration": {
"type": "string" // enum of QUERY_DECOMPOSITION
}
},
...}
}
根據擷取資訊產生回應時,您可以使用推論參數,在推論期間進一步控制模型的行為,並影響模型的輸出。
若要了解如何修改推論參數,請選擇您偏好方法的索引標籤,然後遵循下列步驟:
- Console
-
若要在查詢知識庫時修改推論參數 – 請遵循 查詢知識庫並擷取資料 或 查詢知識庫並根據擷取的資料產生回應 的主控台步驟。當您開啟組態窗格時,您會看到推論參數區段。視需要修改參數。
若要在與文件聊天時修改推論參數 – 請遵循 與未設定知識庫的文件聊天 中的步驟。在組態窗格中,展開推論參數區段,並視需要修改參數。
- API
-
您可以在對 RetrieveAndGenerate API 的呼叫中提供模型參數。您可以在 knowledgeBaseConfiguration (如果您查詢知識庫) 或 externalSourcesConfiguration (如果您與文件聊天) 的 inferenceConfig 欄位中提供推論參數,以自訂模型。
inferenceConfig 欄位中有一個 textInferenceConfig 欄位,其中包含您可以執行的下列參數:
-
溫度
-
topP
-
maxTokenCount
-
stopSequences
您可以在 externalSourcesConfiguration 和 knowledgeBaseConfiguration 的 inferenceConfig 欄位中使用下列參數來自訂模型:
-
溫度
-
topP
-
maxTokenCount
-
stopSequences
如需這些參數之函數的詳細說明,請參閱 使用推論參數影響回應生成。
此外,您可以透過 additionalModelRequestFields 對應提供 textInferenceConfig 不支援的自訂參數。您可以使用此引數為特定模型提供唯一的參數,如需唯一的參數,請參閱 基礎模型的推論請求參數和回應欄位。
如果參數從 textInferenceConfig 忽略,則會使用預設值。任何在 textInferneceConfig 中無法辨識的參數都會遭到忽略,而在 AdditionalModelRequestFields 中無法辨識的參數則會導致例外狀況。
如果 additionalModelRequestFields 和 TextInferenceConfig 中有相同的參數,則會擲回驗證例外狀況。
在 RetrieveAndGenerate 中使用模型參數
以下是 RetrieveAndGenerate 請求內文中的 generationConfiguration 下,inferenceConfig 和 additionalModelRequestFields 的結構範例:
"inferenceConfig": {
"textInferenceConfig": {
"temperature": 0.5,
"topP": 0.5,
"maxTokens": 2048,
"stopSequences": ["\nObservation"]
}
},
"additionalModelRequestFields": {
"top_k": 50
}
程序範例將 temperature 設定為 0.5、將 top_p 設定為 0.5、將 maxTokens 設定為 2048,如果在產生的回應中遇到字串 "\nObservation",則會停止產生,並傳遞自訂 top_k 值 50。
當您查詢知識庫和請求回應產生時,Amazon Bedrock 會使用提示範本,將指示和情境與使用者查詢結合,以建構傳送至模型的產生提示來產生回應。您也可以自訂協調提示,將使用者的提示轉換為搜尋查詢。您可以使用下列工具來設計提示範本:
-
提示預留位置 – Amazon Bedrock 知識庫中的預先定義變數,會在知識庫查詢期間於執行時期動態填入。在系統提示中,您會看到這些預留位置由 $ 符號包圍。下列清單說明您可以使用的預留位置:
$output_format_instructions$ 預留位置是要在回應中顯示的引文的必要欄位。
| 變數 |
提示範本 |
取代為 |
模型 |
是否為必要? |
| $query$ |
協調、產生 |
傳送至知識庫的使用者查詢。 |
Anthropic Claude Instant、Anthropic Claude v2.x |
是 |
| Anthropic Claude 3 Sonnet |
否 (自動包含在模型輸入中) |
| $search_results$ |
產生 |
使用者查詢的擷取結果。 |
全部 |
是 |
| $output_format_instructions$ |
協調 |
格式化回應產生和引文的基本指示。依模型而異。如果您定義自己的格式化指示,我們建議您移除此預留位置。如果沒有此預留位置,回應將不會包含引文。 |
全部 |
是 |
| $current_time$ |
協調、產生 |
目前時間。 |
全部 |
否 |
-
XML 標籤 – Anthropic 模型支援使用 XML 標籤來建構和描述您的提示。使用描述性標籤名稱以獲得最佳結果。例如,在預設系統提示中,您會看到用來描述先前所詢問問題的資料庫的 <database> 標籤)。如需詳細資訊,請參閱《Anthropic 使用者指南》中的使用 XML 標籤。
如需一般提示工程指導方針,請參閱 提示工程概念。
當您不提供自訂提示範本時,Amazon Bedrock 會使用預設系統提示,其中包含一般範例內容 (例如範例問題和有關不相關主題的答案),以引導模型的回應格式。此預設提示會顯示在模型調用日誌中。預設提示中的範例內容不是來自其他客戶的資料,而是 Amazon Bedrock 提供的靜態範本。您可以指定自己的 來覆寫預設提示textPromptTemplate。
選擇您偏好方法的索引標籤,然後遵循下列步驟:
- Console
-
請遵循 查詢知識庫並擷取資料 或 查詢知識庫並根據擷取的資料產生回應 的主控台步驟。在測試視窗中,開啟產生回應。然後,在組態窗格中,展開知識庫提示範本區段。
-
選擇編輯。
-
在文字編輯器中編輯系統提示,包括提示預留位置和視需要的 XML 標籤。若要還原為預設提示範本,請選擇重設為預設值。
-
完成編輯後,請選擇 Save changes (儲存變更)。若要退出而不儲存系統提示,請選擇捨棄變更。
- API
-
當您提出 RetrieveAndGenerate 請求時,請包含對應至 GenerationConfiguration 物件的 generationConfiguration 欄位。若要查看此欄位的位置,請參閱 API 參考中的 RetrieveAndGenerate 請求內文。
下列 JSON 物件會顯示設定要傳回的擷取結果數目上限時,GenerationConfiguration 物件中所需的最少欄位:
"generationConfiguration": {
"promptTemplate": {
"textPromptTemplate": "string"
}
}
在 textPromptTemplate 欄位中輸入您的自訂提示範本,包括提示預留位置和視需要的 XML 標籤。如需系統提示中允許的字元數上限,請參閱 GenerationConfiguration 中的 textPromptTemplate 欄位。