本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
掃描 DynamoDB 中的資料表
Amazon DynamoDB 中的 Scan 操作會讀取資料表或次要索引中的每個項目。根據預設,Scan 操作會傳回資料表或索引中每個項目的所有資料屬性。您可以使用 ProjectionExpression 參數,以便 Scan 只傳回部分屬性,而不會全部傳回。
Scan 一律會傳回結果集。如果找不到相符項目,表示結果集是空的。
單一 Scan 請求最多可擷取 1 MB 的資料。或者,DynamoDB 可將篩選條件表達式套用至此資料,縮減結果後再傳回給使用者。
掃描的篩選條件表達式
若您需要更精確的 Scan 結果,您可以選擇性的提供篩選條件表達式。篩選條件表達式會判斷要傳回 Scan 結果中的哪些項目。所有其他結果皆會捨棄。
篩選條件表達式會在 Scan 完成後、結果傳回前套用。因此,無論是否有篩選條件表達式,Scan 都會使用相同數量的讀取容量。
Scan 操作最多可擷取 1 MB 的資料。系統會先套用這項限制,再評估篩選條件表達式。
使用 Scan,您可在篩選條件表達式中指定任何屬性,包括分割區索引鍵和排序索引鍵屬性。
篩選條件表達式的語法和條件表達式的語法相同。篩選條件表達式可以使用與條件表達式相同的比較子、函數和邏輯運算子。如需邏輯運算子的詳細資訊,請參閱 DynamoDB 中的條件表達式、篩選條件表達式、運算子和函數。。
範例
下列 AWS Command Line Interface (AWS CLI) 範例會掃描Thread資料表,並僅傳回特定使用者上次發佈到 的項目。
aws dynamodb scan \ --table-name Thread \ --filter-expression "LastPostedBy = :name" \ --expression-attribute-values '{":name":{"S":"User A"}}'
限制結果集的項目數
Scan 操作可讓您限制在結果中傳回的項目數目。若要執行此作業,請將 Limit 參數設定為您希望 Scan 操作在篩選表達式評估前回傳的最大項目數。
例如,假設您 Scan 一份資料表,將 Limit 值設為 6 且不使用篩選條件表達式。此 Scan 結果會包含資料表中的前六個項目。
現在假設您在 Scan 中新增一個篩選條件表達式。在本案例中,DynamoDB 會將篩選條件表達式套用至傳回的六個項目,捨棄那些不符的項目。最終的 Scan 結果會包含 6 個或以下項目,視篩選的項目數而定。
為結果編製分頁
DynamoDB 會對 Scan 操作的結果進行分頁。透過編製分頁,Scan 結果會分成數個大小為 1 MB (或更小) 的資料「頁」。應用程式可以處理結果的第一頁、第二頁,以此類推。
單一 Scan 只會傳回符合 1 MB 大小限制的結果集。
為判斷是否有更多結果,並且一次擷取一頁結果,應用程式應執行下列作業:
-
檢查低層級
Scan結果:-
若結果包含
LastEvaluatedKey元素,請接著進行步驟 2。 -
若結果中沒有
LastEvaluatedKey,就表示再也沒有要擷取的項目。
-
-
建構新的
Scan請求,和前一個請求使用相同的參數。但這一次採用步驟 1 的LastEvaluatedKey值,並用它做為新Scan要求的ExclusiveStartKey參數。 -
執行新的
Scan請求。 -
前往步驟 1。
換句話說,LastEvaluatedKey 回應的 Scan 應做為下一個 ExclusiveStartKey 請求的 Scan 使用。若 Scan 回應中沒有 LastEvaluatedKey 元素,表示您已擷取到結果的最終頁。(檢查是否沒有 LastEvaluatedKey 是確定您是否已到達結果集末頁的唯一方式)。
您可以使用 AWS CLI 來檢視此行為。會重複 AWS CLI 傳送低階Scan請求至 DynamoDB,直到結果LastEvaluatedKey中不再出現 為止。請考慮下列掃描整個Movies資料表,但僅傳回特定類型電影 AWS CLI 的範例。
aws dynamodb scan \ --table-name Movies \ --projection-expression "title" \ --filter-expression 'contains(info.genres,:gen)' \ --expression-attribute-values '{":gen":{"S":"Sci-Fi"}}' \ --page-size 100 \ --debug
一般而言, 會自動 AWS CLI 處理分頁。不過,在此範例中, AWS CLI --page-size 參數會限制每頁的項目數量。--debug 參數會列印請求及回應的下層資訊。
注意
您的分頁結果也會根據您傳遞的輸入參數而有所不同。
-
使用
aws dynamodb scan --table-name Prices --max-items 1會傳回NextToken -
使用
aws dynamodb scan --table-name Prices --limit 1會傳回LastEvaluatedKey。
另請注意,使用特定的 --starting-token 需要 NextToken 值。
如果您執行此範例,DynamoDB 的第一個回應會類似以下內容。
2017-07-07 12:19:14,389 - MainThread - botocore.parsers - DEBUG - Response body: b'{"Count":7,"Items":[{"title":{"S":"Monster on the Campus"}},{"title":{"S":"+1"}}, {"title":{"S":"100 Degrees Below Zero"}},{"title":{"S":"About Time"}},{"title":{"S":"After Earth"}}, {"title":{"S":"Age of Dinosaurs"}},{"title":{"S":"Cloudy with a Chance of Meatballs 2"}}], "LastEvaluatedKey":{"year":{"N":"2013"},"title":{"S":"Curse of Chucky"}},"ScannedCount":100}'
回應中的 LastEvaluatedKey 會指出並未擷取所有項目。 AWS CLI 然後, 向 DynamoDB 發出另一個Scan請求。此請求和回應模式會持續到最終回應出現為止。
2017-07-07 12:19:17,830 - MainThread - botocore.parsers - DEBUG - Response body: b'{"Count":1,"Items":[{"title":{"S":"WarGames"}}],"ScannedCount":6}'
若沒有 LastEvaluatedKey,就表示已不再有要擷取的項目。
注意
AWS SDKs 會處理低階 DynamoDB 回應 (包括是否存在 LastEvaluatedKey),並提供用於分頁Scan結果的各種抽象概念。例如,適用於 Java 的開發套件文件介面會提供 java.util.Iterator 支援,讓您可一次處理一個結果。
如需各種程式設計語言的程式碼範例,請參閱《Amazon DynamoDB 入門指南》和所需語言的 AWS 軟體開發套件文件。
計算結果中的項目
除了符合您條件的項目之外,Scan 回應還包含了下列元素:
-
ScannedCount:在套用任何ScanFilter前評估的項目數。ScannedCount值很高,但Count結果很少或沒有,表示Scan操作不足。如未在請求中使用篩選條件,則ScannedCount與Count相同。 -
Count:套用篩選條件表達式 (若有) 後剩餘的項目數。
注意
若不使用篩選條件表達式,則 ScannedCount 和 Count 會有相同的值。
若 Scan 結果集的大小大於 1 MB,則 ScannedCount 和 Count 僅代表總項目的部分計數。您需要執行多項 Scan 操作,才能擷取所有的結果 (請參閱為結果編製分頁)。
每個 Scan 回應都包含經該特定 Scan 請求處理過的項目 ScannedCount 和 Count。若要取得所有 Scan 請求的總計,您可以為 ScannedCount 及 Count 記錄流水帳。
掃描使用的容量單位
您可以 Scan 任何資料表或次要索引。Scan 操作會使用讀取容量單位,如下所示。
若您對下列進行 Scan |
DynamoDB 使用的讀取容量單位就會來自... |
|---|---|
| 資料表 | 該資料表的佈建讀取容量。 |
| 全域次要索引 | 該索引的佈建讀取容量。 |
| 本機次要索引 | 該基礎資料表的佈建讀取容量。 |
注意
資源型政策目前不支援次要索引掃描操作的跨帳戶存取。
根據預設,Scan 操作不會傳回任何使用之讀取容量的相關資料。但您可以在 ReturnConsumedCapacity 請求中指定 Scan 參數,來取得這項資訊。下列為 ReturnConsumedCapacity 的有效設定:
-
NONE:不會傳回耗用的容量資料。(此為預設值)。 -
TOTAL:回應包括耗用的讀取容量單位總數。 -
INDEXES:回應顯示耗用的讀取容量單位總數,以及每個資料表和存取之索引的耗用容量。
DynamoDB 會根據項目的數量以及大小 (而不是根據傳回給應用程式的資料量) 計算耗用的讀取容量單位數。因此,無論您請求所有屬性 (預設行為) 或只請求部分屬性 (使用投影表達式),使用的容量單位數都相同。無論您是否使用篩選條件表達式,此數量都相同。Scan 會耗用最小讀取容量單位,每秒執行一個高度一致性讀取;或者針對最大 4 KB 的項目,每秒執行兩個最終一致讀取。如果您需要讀取大於 4KB 的項目,DynamoDB 需要額外的讀取請求單位。空白資料表和擁有稀疏分割區索引鍵的超大型資料表,可能會出現超出掃描資料量的額外 RCU 收費。這涵蓋了處理 Scan 請求的成本,即使資料不存在亦然。
掃描的讀取一致性
根據預設,Scan 操作會執行最終一致讀取。這表示 Scan 的結果可能不會反映最近完成之 PutItem 或 UpdateItem 操作所造成的變更。如需詳細資訊,請參閱 DynamoDB 讀取一致性。
若您要進行高度一致性讀取,請在 Scan 開始時,將 ConsistentRead 請求中的 true 參數設為 Scan。這可確保 Scan 開始前即已完成的所有寫入操作,都會包含在 Scan 回應中。
將 ConsistentRead 設為 true,再結合 DynamoDB Streams,在資料表備份或複寫案例中很實用。首先使用 ConsistentRead 設為 true 的 Scan,取得和資料表資料一致的副本。在 Scan 期間,DynamoDB Streams 會紀錄資料表發生的所有額外寫入活動。Scan 完成後,您可將串流的寫入活動套用至資料表。
注意
與將 ConsistentRead 保留預設值 (false) 相較,將 ConsistentRead 設成 true 的 Scan 操作會使用兩倍的讀取容量單位。
平行掃描
根據預設,Scan 操作會依序處理資料。Amazon DynamoDB 會以 1 MB 的增量將資料傳回應用程式,而應用程式會執行額外的 Scan 操作來擷取下一個 1 MB 的資料。
掃描的資料表或索引越大,Scan 完成所需的時間就更多。此外,循序 Scan 可能並不總是能夠完全使用佈建的讀取輸送容量:即使 DynamoDB 將大型資料表的資料分配到多個實體分割區,Scan 操作一次只能讀取一個分割區。因此,Scan 的輸送量受到單一分割區的最大輸送量限制。
若要解決這些問題,Scan 操作在邏輯上可能會將資料表或次要索引分為多個區段,其中有多個應用程式工作者平行掃描區段。每個工作者都可以是執行緒 (在支援多執行緒的程式設計語言中) 或作業系統程序。若要執行平行掃描,每個工作者都會使用下列參數發出自己的 Scan 請求:
-
Segment:特定工作者要掃描的區段。每個工作者應該使用不同的Segment值。 -
TotalSegments:平行掃描區段的總數。此值必須與應用程式要使用的工作者數目相同。
下圖顯示多執行緒應用程式如何以三度平行處理執行平行 Scan。
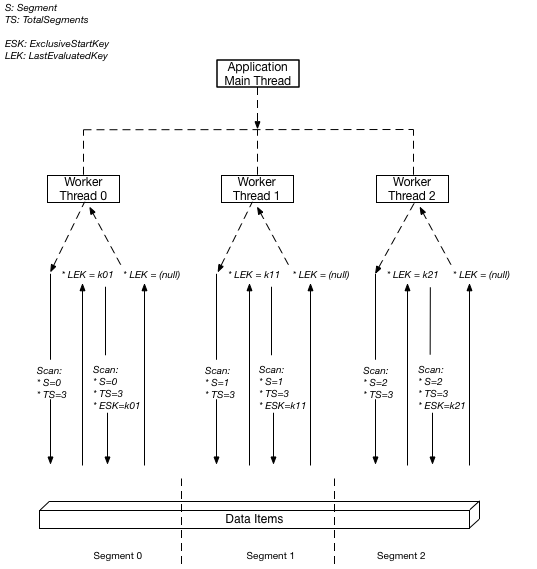
在此圖中,應用程式產生三個執行緒,並為每個執行緒指派一個數字。(區段從零開始,所以第一個數字永遠為 0。) 每個執行緒都會發出 Scan 請求、將 Segment 設定為指定號碼,並將 TotalSegments 設定為 3。每個執行緒都會掃描其指定的區段,一次擷取 1 MB 的資料,並將資料傳回至應用程式的主執行緒。
DynamoDB 透過將雜湊函數套用至每個項目的分割區索引鍵,將項目指派給區段。對於指定的TotalSegments值,具有相同分割區索引鍵的所有項目一律會指派給相同的 Segment。這表示在項目 1、項目 2 和項目 3 全部共用 pk="account#123"(但具有不同的排序索引鍵) 的表格中,這些項目將由相同的工作者處理,無論排序索引鍵值或項目集合的大小為何。
由於區段指派僅以分割區索引鍵雜湊為基礎,因此區段可能分佈不均勻。某些區段可能不包含任何項目,而其他區段則可能包含具有大型項目集合的許多分割區索引鍵。因此,增加區段總數並不能保證更快的掃描效能,特別是當分割區索引鍵未均勻分佈到金鑰空間時。
Segment 和 TotalSegments 的值會套用至個別 Scan 請求,並且您可以隨時使用不同的值。您可能需要對這些值以及使用的工作者數量進行試驗,直到應用程式達到最佳效能為止。
注意
具有大量工作者的平行掃描可以輕易耗用所掃描資料表或索引的所有佈建輸送量。如果資料表或索引也會造成來自其他應用程式的大量讀取或寫入活動,就最好避免這類掃描。
若要控制每個請求傳回的資料量,請使用 Limit 參數。這有助於預防某個工作者耗用所有佈建輸送量的情況,避免犧牲所有其他工作者。
