本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
最佳化 S3 Express One Zone 效能的最佳實務
建置從 Amazon S3 Express One Zone 上傳和擷取物件的應用程式時,請依照我們的最佳實務指導方針來最佳化效能。若要使用 S3 Express One Zone 儲存類別,您必須建立 S3 目錄儲存貯體。S3 Express One Zone 儲存類別不支援搭配 S3 一般用途儲存貯體使用。
如需所有其他 Amazon S3 儲存類別和 S3 一般用途儲存貯體的效能指導方針,請參閱 最佳實務設計模式:最佳化 Amazon S3 效能。
為了在大規模工作負載中使用 S3 Express One Zone 儲存類別和目錄儲存貯體時獲得最佳效能和可擴展性,請務必了解目錄儲存貯體的運作方式與一般用途儲存貯體不同之處。然後,我們提供最佳實務,讓您的應用程式與目錄儲存貯體的運作方式保持一致。
目錄儲存貯體的運作方式
Amazon S3 Express One Zone 儲存類別可支援每個目錄儲存貯體每秒最多 2,000,000 個 GET 和 200,000 個 PUT 交易 (TPS) 的工作負載。使用 S3 Express One Zone 可將資料儲存在可用區域的 S3 目錄儲存貯體中。目錄儲存貯體中的物件可在階層式命名空間內存取,其類似於檔案系統,與具有一般命名空間的 S3 一般用途儲存貯體正好相反。與一般用途儲存貯體不同的是,目錄儲存貯體是以階層方式將索引鍵組織成目錄,而非字首。字首是物件索引鍵名稱開頭的字元字串。您可以使用字首來整理資料,並可用於管理一般用途儲存貯體中的扁平式物件儲存架構。如需詳細資訊,請參閱使用字首整理物件。
在目錄儲存貯體中,物件會在階層式命名空間中使用正斜線 (/) 做為唯一支援的分隔符號。當您使用如 dir1/dir2/file1.txt 一樣的金鑰上傳物件時,目錄 dir1/ 和 dir2/ 會自動由 Amazon S3 建立和管理。目錄會在 PutObject 或 CreateMultiPartUpload 操作期間建立,並且會在 DeleteObject 或 AbortMultiPartUpload 操作後變成空白時,自動移除。目錄中的物件和子目錄數量沒有上限。
物件上傳到目錄儲存貯體時所建立的目錄,可以立即擴展,以減少發生 HTTP 503 (Slow Down) 錯誤的機會。這種自動擴展可讓您的應用程式視需要在目錄內和目錄之間平行處理讀取和寫入請求。對於 S3 Express One Zone,個別目錄旨在支援目錄儲存貯體的最大請求率。由於系統會自動分配物件以實現均勻的負載分佈,無需隨機化索引鍵字首即可達到最佳效能,因此索引鍵不會依詞典編纂順序排列方式儲存在目錄儲存貯體中。這與 S3 一般用途儲存貯體形成對比,其中詞典編纂順序相近的索引鍵更有可能位於同一部伺服器上。
如需目錄儲存貯體操作和目錄互動範例的詳細資訊,請參閱 目錄儲存貯體操作和目錄互動範例。
最佳實務
遵循最佳實務來最佳化目錄儲存貯體效能,並協助您的工作負載隨時間擴展。
使用包含許多項目的目錄 (物件或子目錄)
目錄儲存貯體預設為所有工作負載提供高效能。若要在某些操作中進一步最佳化效能,將更多項目 (即物件或子目錄) 合併到目錄中,這將會導致更低的延遲和更高的請求率:
改變 API 操作,例如
PutObject、DeleteObject、CreateMultiPartUpload和AbortMultiPartUpload,在使用包含數千個項目的較少但更密集的目錄,而非大量卻較小的目錄實作時,可達到最佳效能。當需要遍歷較少的目錄來填入結果頁面時,
ListObjectsV2操作效能會更好。
請勿在字首中使用熵
在 Amazon S3 操作中,熵是指字首命名中的隨機化,可協助跨儲存體分割區平均分配工作負載。不過,由於目錄儲存貯體會在內部管理負載分佈,因此不建議在字首中使用熵來獲得最佳效能。這是因為對於目錄儲存貯體來說,熵會導致請求速度變慢是因為它無法重複使用已經建立的目錄。
像 $HASH/directory/object 這樣的關鍵模式最終可能會建立許多中間目錄。在下列範例中,所有 job-1 都是不同的目錄,因為其父系不同。目錄會變得稀疏,而變動和清單請求會變慢。在此範例中,有 12 個中間目錄,每個目錄都只有單一項目。
s3://my-bucket/0cc175b9c0f1b6a831c399e269772661/job-1/file1 s3://my-bucket/92eb5ffee6ae2fec3ad71c777531578f/job-1/file2 s3://my-bucket/4a8a08f09d37b73795649038408b5f33/job-1/file3 s3://my-bucket/8277e0910d750195b448797616e091ad/job-1/file4 s3://my-bucket/e1671797c52e15f763380b45e841ec32/job-1/file5 s3://my-bucket/8fa14cdd754f91cc6554c9e71929cce7/job-1/file6
相反地,為了獲得更好的效能,我們可以移除 $HASH 元件,並允許 job-1 成為單一目錄,以改善目錄的密度。在下列範例中,與前一個範例相比,包含 6 個項目的單一中間目錄,可以獲得更好的效能。
s3://my-bucket/job-1/file1 s3://my-bucket/job-1/file2 s3://my-bucket/job-1/file3 s3://my-bucket/job-1/file4 s3://my-bucket/job-1/file5 s3://my-bucket/job-1/file6
有這種效能優點,是因為一開始建立物件索引鍵且其索引鍵名稱包含目錄時,會自動為該物件建立目錄。後續物件上傳到同一個目錄時,就不需要建立目錄,這樣可以減少物件上傳至現有目錄的延遲。
如果您不需要在 ListObjectsV2 呼叫期間為物件進行邏輯分組的能力,請使用分隔符號 / 以外的分隔符號來分隔索引鍵的部分
由於 / 分隔符號對目錄儲存貯體有特殊處理,因此應謹慎使用。雖然目錄儲存貯體不會依詞典編纂順序排列物件,但目錄中的物件仍會在 ListObjectsV2 輸出中分在同一組。如果您不需要此功能,您可以將 / 取代為另一個字元做為分隔符號,以免造成中間目錄的建立。
例如,假設下列索引鍵處於 YYYY/MM/DD/HH/ 字首模式
s3://my-bucket/2024/04/00/01/file1 s3://my-bucket/2024/04/00/02/file2 s3://my-bucket/2024/04/00/03/file3 s3://my-bucket/2024/04/01/01/file4 s3://my-bucket/2024/04/01/02/file5 s3://my-bucket/2024/04/01/03/file6
如果您不需要在 ListObjectsV2 結果中依小時或天為物件分組,但需要依月份為物件分組,則 YYYY/MM/DD-HH- 的下列索引鍵模式將大幅減少目錄,並提高 ListObjectsV2 操作的效能。
s3://my-bucket/2024/04/00-01-file1 s3://my-bucket/2024/04/00-01-file2 s3://my-bucket/2024/04/00-01-file3 s3://my-bucket/2024/04/01-02-file4 s3://my-bucket/2024/04/01-02-file5 s3://my-bucket/2024/04/01-02-file6
盡可能使用分隔符號清單來操作
沒有 delimiter 的 ListObjectsV2 請求會執行所有目錄的深度優先遞迴遍歷。具有 delimiter 的 ListObjectsV2 請求只會擷取 prefix 參數所指定目錄中的項目,以減少請求延遲,並增加每秒的聚合鍵數。對於目錄儲存貯體,請盡可能使用分隔符號清單來操作。使用分隔符號的清單可以減少目錄的存取次數,進而提高每秒的鍵數,並降低請求延遲。
例如,對於目錄儲存貯體中的下列目錄和物件:
s3://my-bucket/2024/04/12-01-file1 s3://my-bucket/2024/04/12-01-file2 ... s3://my-bucket/2024/05/12-01-file1 s3://my-bucket/2024/05/12-01-file2 ... s3://my-bucket/2024/06/12-01-file1 s3://my-bucket/2024/06/12-01-file2 ... s3://my-bucket/2024/07/12-01-file1 s3://my-bucket/2024/07/12-01-file2 ...
為了獲得更好的 ListObjectsV2 效能,如果應用程式的邏輯理論允許,請使用分隔符號清單列出子目錄和物件。例如,您可以針對分隔符號清單操作執行下列命令,
aws s3api list-objects-v2 --bucket my-bucket --prefix '2024/' --delimiter '/'
輸出是子目錄的清單。
{ "CommonPrefixes": [ { "Prefix": "2024/04/" }, { "Prefix": "2024/05/" }, { "Prefix": "2024/06/" }, { "Prefix": "2024/07/" } ] }
若要列出每個具有更佳效能的子目錄,您可以執行如下範例的命令:
命令:
aws s3api list-objects-v2 --bucket my-bucket --prefix '2024/04' --delimiter '/'
輸出:
{ "Contents": [ { "Key": "2024/04/12-01-file1" }, { "Key": "2024/04/12-01-file2" } ] }
將 S3 Express One Zone 儲存與您的 運算資源共置
使用 S3 Express One Zone 時,每個目錄儲存貯體都位於您建立儲存貯體時選取的單一可用區域中。您可以透過在運算工作負載或資源所在位置的可用區域中建立新的目錄儲存貯體來著手進行。然後就能立即開始非常低延遲的讀取和寫入。目錄儲存貯體是一種 S3 儲存貯體,您可以在其中選擇 中的可用區域 AWS 區域 ,以減少運算和儲存之間的延遲。
如果您在可用區域之間存取目錄儲存貯體,您經歷的延遲會稍微增加。為了達到最佳效能,建議您盡可能從位於相同可用區域中的 Amazon Elastic Container Service、Amazon Elastic Kubernetes Service 和 Amazon Elastic Compute Cloud 執行個體存取目錄儲存貯體。
使用並行連線,對於超過 1MB 的物件即達到高輸送量
您可以向目錄儲存貯體發出多個並行請求,以將請求分散到不同的連線上來獲得最大可存取頻寬,藉此達到最佳效能。如同一般用途儲存貯體,S3 Express One Zone 對於目錄儲存貯體的連線數沒有任何限制。當同一目錄發生大量並行寫入時,個別目錄可以水平和自動擴展效能。
目錄儲存貯體的個別 TCP 連線,在每秒可上傳或下載的位元組數上具有固定的上限。當物件變大時,請求時間主要取決於位元組串流處理,而不是交易處理。若要使用多個連線來平行處理大型物件的上傳或下載,您可以減少端對端延遲。如果使用 Java 2.x SDK,您應該考慮使用 S3 Transfer Manager,利用效能改善如分段上傳 API 操作和位元組範圍擷取,以平行存取資料。
使用閘道 VPC 端點
閘道端點提供從 VPC 到目錄儲存貯體的直接連線,不需要網際網路閘道或 VPC 的 NAT 裝置。若要減少封包在網路上花費的時間,您應該使用目錄儲存貯體的閘道 VPC 端點來設定 VPC。如需詳細資訊,請參閱目錄儲存貯體的網路。
使用工作階段驗證,並重複使用有效的工作階段字符
目錄儲存貯體提供工作階段字符驗證機制,以減少效能敏感 API 操作的延遲。您可以對 CreateSession 進行單一呼叫,以取得工作階段字符,如此即能在接下來 5 分鐘內對所有請求生效。若要在 API 呼叫中取得最低延遲,請務必取得工作階段字符,並在重新整理字符之前的整個生命週期內,重複使用該字符。
如果您使用 AWS SDKs,軟體SDKs會自動處理工作階段字符重新整理,以避免工作階段過期時服務中斷。我們建議您使用 AWS SDKs來啟動和管理對 CreateSession API 操作的請求。
如需 CreateSession 的相關資訊,請參閱 使用 CreateSession 授權區域端點 API 操作。
使用 CRT 型用戶端
AWS Common Runtime (CRT) 是一組以 C 撰寫的模組化、高效能且高效的程式庫,旨在做為 AWS SDKs 的基礎。CRT 提供更高的輸送量、增強的連線管理,以及更快的啟動時間。CRT 可透過 Go 以外的所有 AWS SDKs 使用。
如需如何為所使用的 SDK 設定 CRT 的詳細資訊,請參閱AWS 通用執行期 (CRT) 程式庫、使用 AWS 通用執行期加速 Amazon S3 輸送量
使用最新版本的 AWS SDKs
AWS SDKs 為許多最佳化 Amazon S3 效能的建議準則提供內建支援。這些 SDK 提供更簡單的 API,以便在應用程式中充分利用 Amazon S3,並定期更新來遵循最新的最佳實務。例如,SDK 會在發生 HTTP 503 錯誤後自動重試請求,並處理慢速連線回應。
如果使用 Java 2.x SDK,您應該考慮使用 S3 Transfer Manager,它會自動水平擴展連線,以適時使用位元組範圍請求,實現每秒數千個請求數。位元組範圍請求可以提高效能,因為您可以使用與 S3 的並行連線,從同一個物件擷取不同的位元組範圍。與單一整個物件請求相比,這可協助您實現更高的彙總傳輸量。因此,請務必使用最新版本的 AWS SDKs來取得最新的效能最佳化功能。
效能故障診斷
您是否為對延遲敏感的應用程式設定重試請求?
S3 Express One Zone 專為提供一致的高效能水準而打造,無需額外調整。但是,設定有利的逾時值和重試次數,可進一步協助實現一致的延遲和效能。 AWS SDKs 具有可設定的逾時和重試值,您可以根據特定應用程式的公差進行調整。
您是否使用 AWS 通用執行期 (CRT) 程式庫和最佳的 Amazon EC2 執行個體類型?
執行大量讀取和寫入操作的應用程式,可能會比未執行這些操作的應用程式需要更多的記憶體或運算能力。為要求高效能的工作負載啟動 Amazon Elastic Compute Cloud (Amazon EC2) 執行個體時,請選擇符合應用程式所需資源量的執行個體類型。S3 Express One Zone 高效能儲存最適合搭配較大和較新的執行個體類型,這些類型具備更大量的系統記憶體,以及更強大的 CPU 和 GPU,可充分利用效能更高的儲存。我們也建議使用最新版本的 CRT 啟用 AWS SDKs,這可以更好地平行加速讀取和寫入請求。
您是否使用 AWS SDKs進行工作階段型身分驗證?
透過 Amazon S3,您也可以遵循 AWS SDKs 的相同最佳實務,在使用 HTTP REST API 請求時最佳化效能。不過,透過 S3 Express One Zone 所使用的工作階段型授權和身分驗證機制,我們強烈建議您使用 AWS SDKs來管理 CreateSession及其受管工作階段字符。使用 CreateSession API 操作, AWS SDKs 會自動代表您建立和重新整理權杖。使用 CreateSession可節省對 AWS Identity and Access Management (IAM) 的每次請求往返延遲,以授權每個請求。
目錄儲存貯體操作和目錄互動範例
以下顯示目錄儲存貯體如何運作的三個範例。
範例 1:對目錄儲存貯體的 S3 PutObject 請求如何與目錄互動
-
在空儲存貯體中執行
PUT(<bucket>, "documents/reports/quarterly.txt")操作時,會在儲存貯體根目錄中建立目錄documents/、在documents/中建立目錄reports/,以及在reports/中建立物件quarterly.txt。對於此操作,除了該物件外,還會建立兩個目錄。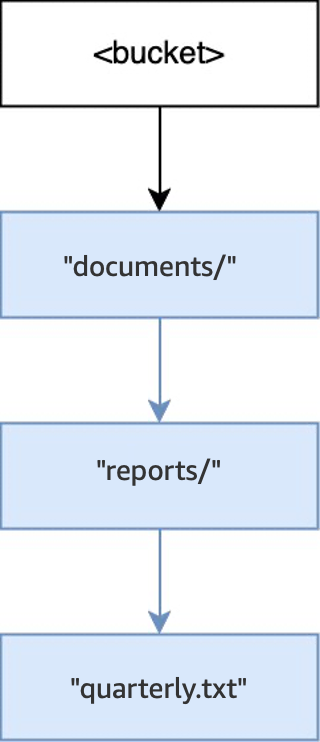
-
然後,當執行另一個
PUT(<bucket>, "documents/logs/application.txt")操作時,目錄documents/已存在、在documents/中的目錄logs/不存在,因此建立該目錄,以及在logs/中建立物件application.txt。對於此操作,除了該物件外,僅建立一個目錄。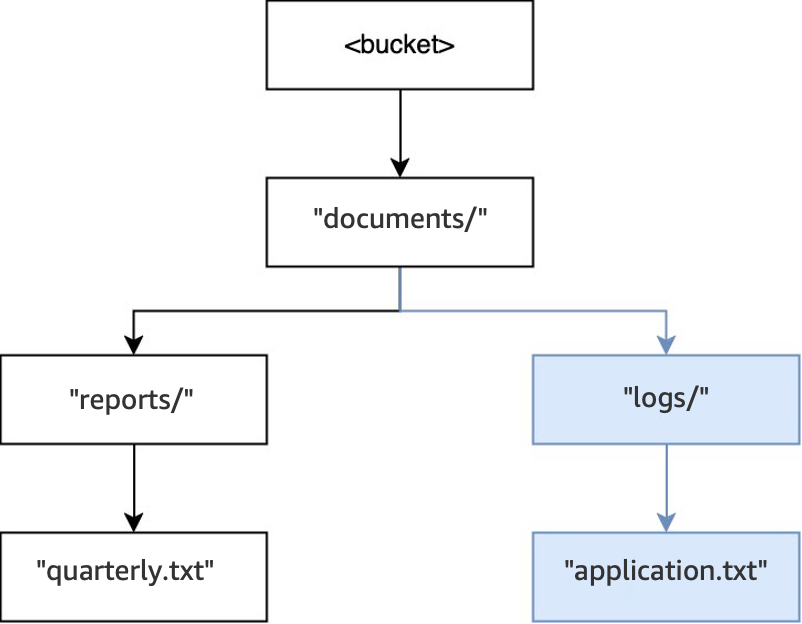
-
最後,執行
PUT(<bucket>, "documents/readme.txt")操作時,根目錄中的目錄documents/已存在,且物件readme.txt已建立。對於此操作,不會建立任何目錄。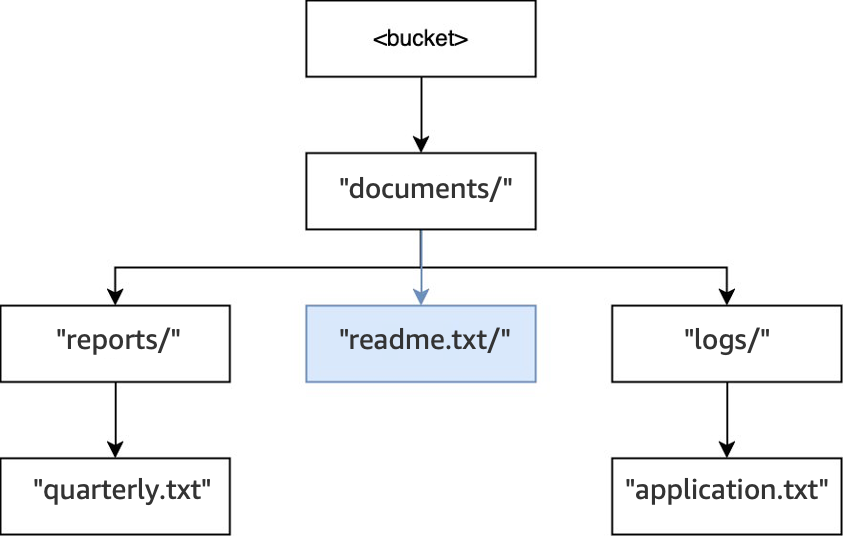
範例 2:對目錄儲存貯體的 S3 ListObjectsV2 請求如何與目錄互動
對於未指定分隔符號的 S3 ListObjectsV2 請求,會以深度優先的方式遍歷儲存貯體。輸出會以一致的順序傳回。不過,雖然此順序在請求之間保持不變,但順序並非依詞典編纂順序排列。對於先前範例中建立的儲存貯體和目錄:
-
執行
LIST(<bucket>)時,會輸入目錄documents/,並開始遍歷。 -
會輸入子目錄
logs/,並開始遍歷。 -
物件
application.txt可在logs/中找到。 -
logs/內沒有其他項目。清單操作從logs/結束,然後再次進入documents/。 -
documents/目錄會持續遍歷,並找到物件readme.txt。 -
繼續遍歷
documents/目錄,且會進入reports/子目錄,然後開始遍歷。 -
物件
quarterly.txt可在reports/中找到。 -
reports/內沒有其他項目。清單從reports/結束,然後再次進入documents/。 -
documents/內不存在其他項目,且清單會傳回。
在此範例中,logs/ 的順序在 readme.txt 之前,readme.txt 的順序在 reports/ 之前。
範例 3:對目錄儲存貯體的 S3 DeleteObject 請求如何與目錄互動
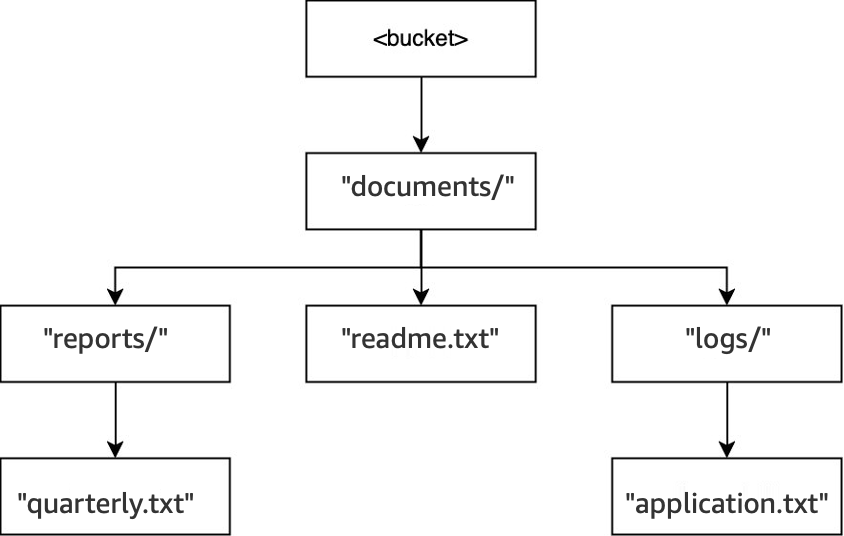
-
在相同的儲存貯體中,當執行
DELETE(<bucket>, "documents/reports/quarterly.txt")操作時,會刪除物件quarterly.txt,將目錄reports/保留空白,並導致立即刪除。documents/目錄不是空的,因為目錄中同時具有目錄logs/和物件readme.txt,因此不會遭到刪除。對於此操作,只會刪除一個物件和一個目錄。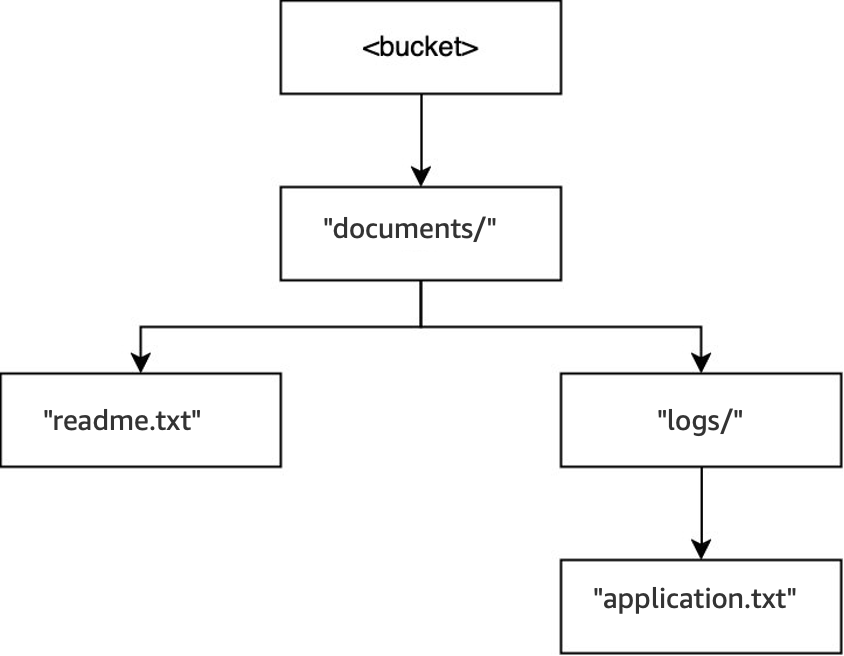
-
執行
DELETE(<bucket>, "documents/readme.txt")操作時,會刪除物件readme.txt。documents/仍未清空,因為其中包含目錄logs/,因此不會遭到刪除。對於此操作,不會刪除任何目錄,只會刪除物件。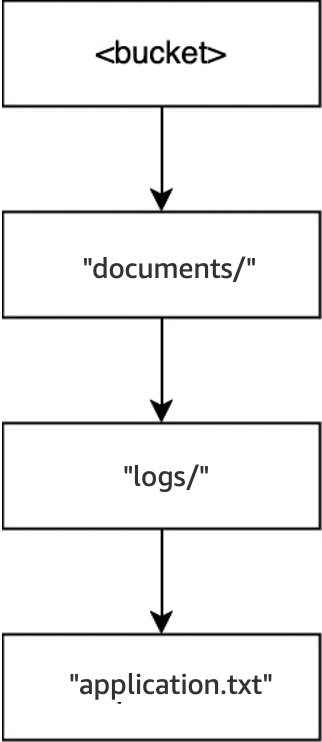
-
最後,在執行
DELETE(<bucket>, "documents/logs/application.txt")操作時,會刪除application.txt,並將logs/保留空白,因而導致立即刪除。這會使documents/保留空白,但也導致立即遭到刪除。對於此操作,會刪除兩個目錄和一個物件。儲存貯體現在已清空。
