本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Aurora零 ETL 整合
Aurora與 Amazon Redshift 的零 ETL 整合,並使用 Aurora 的資料 Amazon SageMaker AI 啟用近乎即時的分析和機器學習 (ML)。其是一種全受管解決方案,可讓交易資料在寫入 Aurora 資料庫叢集之後,於分析目的地中使用。擷取、轉換和載入 (ETL) 是一種過程,可將來自多個來源的資料合併為大型、中央資料倉儲。
零 ETL 整合可讓 Aurora 資料庫叢集 中的資料近乎即時地在 Amazon Redshift 或 Amazon SageMaker AI 資料湖倉中提供。一旦資料位於目標資料倉儲或資料湖中,您可以使用內建功能來支援分析、ML 和 AI 工作負載,例如機器學習、具體化視觀表、資料共用、對多個資料存放區和資料湖的聯合存取,以及與 Amazon SageMaker AI、Quick 和其他 整合 AWS 服務。
若要建立零 ETL 整合時,請指定 Aurora 資料庫叢集做為來源,以及指定支援資料倉儲或資料湖倉做為目標。整合會將來源資料庫中的資料複寫到目標資料倉儲或資料湖倉。
下圖說明與 Amazon Redshift 進行零 ETL 整合的此功能:
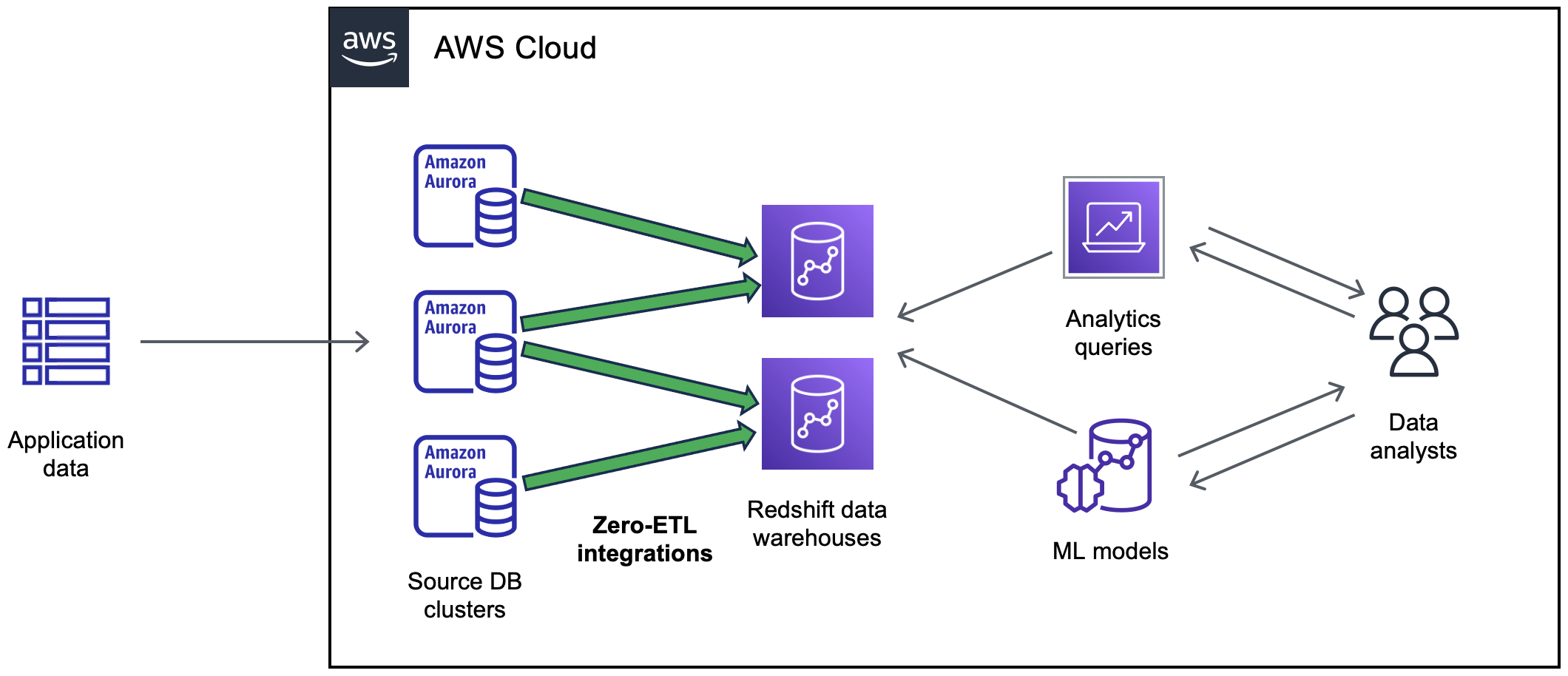
下圖說明與 Amazon SageMaker AI 資料湖倉進行零 ETL 整合的此功能:
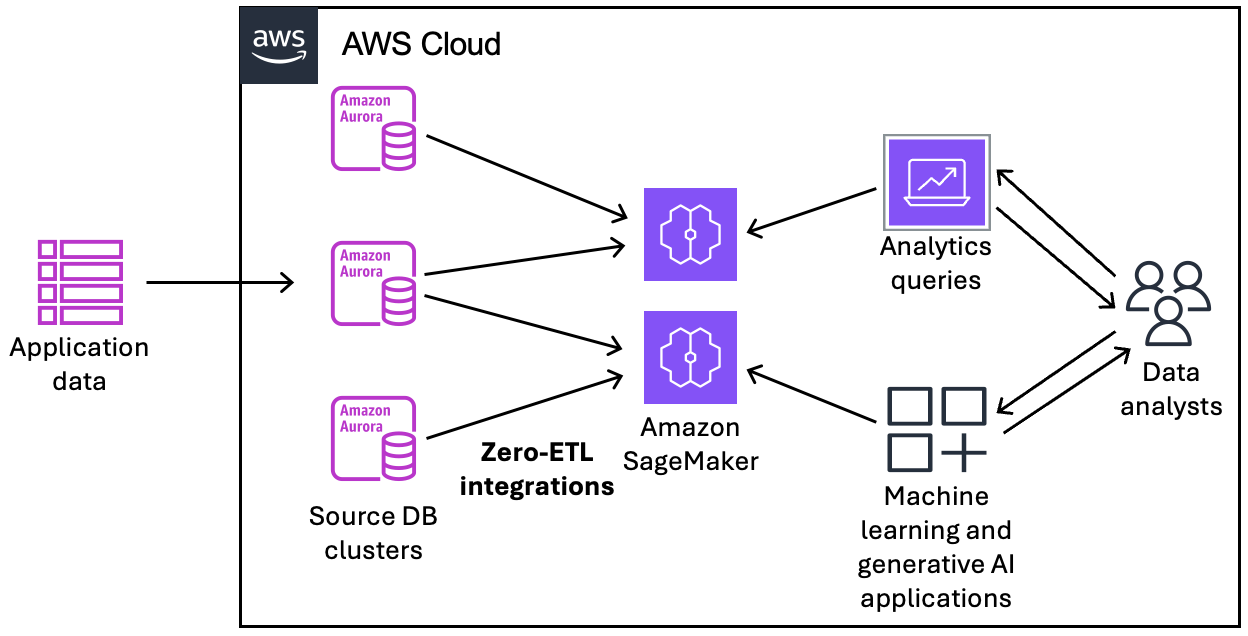
整合會監控資料管道的運作狀態,並在可能的情況下從問題中復原。您可以建立從多個 Aurora 資料庫叢集到單一目標資料倉儲或資料湖倉的整合,讓您能夠跨多個應用程式衍生洞察。
如需零 ETL 整合定價的詳細資訊,請參閱 Amazon Aurora 定價
主題
優勢
Aurora 零 ETL 整合具有下列優勢:
-
協助您從多個資料來源衍生整體洞見。
-
無需建置和維護執行擷取、轉換和載入 (ETL) 操作的複雜資料管道。Zero-ETL 整合會透過為您佈建和管理管道,免除建置和管理這些管道所帶來的挑戰。
-
減少操作負擔和成本,讓您專注於改善應用程式。
-
讓您利用目標目的地的分析和 ML 功能,從交易和其他資料衍生洞見,以有效地回應關鍵、時間敏感的事件。
重要概念
當您開始使用零 ETL 整合時,請考慮下列概念:
- 整合
-
全受管資料管道,其會自動將交易資料和結構描述從 Aurora 資料庫叢集複寫到資料倉儲或目錄。
- 來源資料庫叢集
-
從中複寫資料的 Aurora 資料庫叢集。您可以指定使用佈建資料庫執行個體或資料庫執行個體做為來源的Aurora serverless資料庫叢集。
- Target
-
將資料複寫至其中的資料倉儲或資料湖倉。資料倉儲有兩種類型:佈建的叢集資料倉儲和無伺服器資料倉儲。佈建的叢集資料倉儲是稱為節點的運算資源集合,這些節點會組織成稱為叢集的群組。無伺服器資料倉儲由存放運算資源的工作群組,以及為資料庫物件和使用者提供空間的命名空間所組成。這兩個資料倉儲都會執行分析引擎,並包含一或多個資料庫。
目標資料湖倉由目錄、資料庫、資料表和檢視組成。如需資料湖倉架構的詳細資訊,請參閱《Amazon SageMaker AI Unified Studio 使用者指南》中的 SageMaker Lakehouse components。
多個來源資料庫叢集可以寫入至相同的目標。
如需詳細資訊,請參閱《Amazon Redshift 開發人員指南》中的資料倉儲系統架構。
限制
以下限制適用於 Aurora 零 ETL 整合。
一般限制
-
來源資料庫叢集必須與目標位於相同的區域。
-
您無法重新命名資料庫叢集或其任何執行個體,如果它具有現有整合的話。
-
您無法在相同的來源和目標資料庫之間建立多個整合。
-
您無法刪除具有現有整合的資料庫叢集。您必須先刪除所有相關聯的整合。
-
如果停止來源資料庫叢集,則最後幾個交易可能不會複寫到目標,直到您恢復叢集為止。
-
如果您的叢集是藍/綠部署的來源,則藍色和綠色環境在轉換期間無法具有現有的零 ETL 整合。您必須先刪除整合再進行轉換,然後重新建立該整合。
-
資料庫叢集必須至少包含一個資料庫執行個體,才能成為整合的來源。
-
您無法為跨帳戶複製的來源資料庫叢集建立整合,例如使用 AWS Resource Access Manager () 共用的資料庫叢集AWS RAM。
-
如果來源叢集是 Aurora 全域資料庫中的主要資料庫叢集,且容錯移轉到其中一個次要叢集,則整合會變成非作用中。您必須刪除並重新建立整合。
-
您無法為正在主動建立另一個整合的來源資料庫建立整合。
-
當您一開始建立整合時或當資料表重新同步時,從來源植入目標的資料可能需要 20 到 25 分鐘或更長時間,取決於來源資料庫的大小。此延遲可能會導致複本延遲增加。
-
不支援某些資料類型。如需詳細資訊,請參閱Aurora 與 Amazon Redshift 資料庫之間的資料類型差異。
-
系統資料表、暫存資料表和檢視不會複寫到目標倉儲。
-
在來源資料表上執行 DDL 命令 (例如
ALTER TABLE) 可以觸發資料表重新同步,使得資料表無法在重新同步時進行查詢。如需詳細資訊,請參閱我的一個或多個 Amazon Redshift 資料表需要重新同步。
Aurora MySQL 限制
-
您的來源資料庫叢集必須執行支援的 Aurora MySQL 版本。如需支援的版本的清單,請參閱零 ETL 整合的支援區域和 Aurora 資料庫引擎。
-
零 ETL 整合依賴 MySQL 二進位記錄 (binlog),來擷取持續的資料變更。不要使用 Binlog 型資料篩選,因為其可能會在來源資料庫與目標資料庫之間導致資料不一致。
-
僅針對設定為使用 InnoDB 儲存體引擎的資料庫支援零 ETL 整合。
-
不支援具有預先定義之資料表更新的外部索引鍵參考。具體而言,不支援
ON DELETE和ON UPDATE規則搭配CASCADE、SET NULL和SET DEFAULT動作。嘗試建立或更新對另一個資料表具有這類參考的資料表,會將該資料表置於失敗狀態。 -
在來源資料庫叢集上執行的 XA 交易
會導致整合進入 Syncing狀態。
Aurora PostgreSQL 限制
-
您的來源資料庫叢集必須執行支援的 Aurora PostgreSQL 版本。如需支援的版本的清單,請參閱零 ETL 整合的支援區域和 Aurora 資料庫引擎。
-
如果您選取 Aurora PostgreSQL 來源資料庫叢集,則必須至少指定一個資料篩選條件模式。模式至少必須包含單一資料庫 (
database-name.*.* -
在來源 Aurora PostgreSQL 資料庫叢集內建立的所有資料庫都必須使用 UTF-8 編碼。
-
使用宣告式分割時,資料表分割區會複寫至 Amazon Redshift。不過,分割的資料表本身不會複寫到 Amazon Redshift。
-
不支援兩階段交易
。 -
如果您從整合來源的資料庫叢集刪除所有資料庫執行個體,然後重新新增資料庫執行個體,則來源與目標叢集之間的複寫會中斷。
-
來源資料庫叢集無法使用 Aurora Limitless Database。
-
資料篩選條件中存在的所有資料表都需要主索引鍵。任何沒有主索引鍵的資料表都會進入失敗狀態。
Amazon Redshift 限制
如需與零 ETL 整合相關的 Amazon Redshift 限制清單,請參閱《Amazon Redshift 管理指南》中的將零 ETL 整合與 Amazon Redshift 搭配使用的考量。
Amazon SageMaker AI Lakehouse 限制
以下是湖房零 ETL Amazon SageMaker AI 整合的限制。
-
目錄名稱的長度限制為 19 個字元。
配額
您的帳戶具有與 Aurora 零 ETL 整合相關的下列配額。除非另有說明,否則每個配額都是根據區域而定。
| 名稱 | 預設 | 說明 |
|---|---|---|
| 整合 | 100 | AWS 帳戶內的整合總數。 |
| 每個目標的整合 | 50 | 將資料傳送至單一目標資料倉儲或資料湖倉的整合數目。 |
| 每個來源叢集的整合 | 5 | 從單一來源資料庫叢集傳送資料的整合數目。 |
此外,目標倉儲會對每個資料庫執行個體或叢集節點中允許的資料表數目設定某些限制。如需 Amazon Redshift 配額和限制的詳細資訊,請參閱《Amazon Redshift 管理指南》中的 Amazon Redshift 中的配額和限制。
支援的區域
Aurora零 ETL 整合可在 的子集中使用 AWS 區域。如需支援的區域的清單,請參閱 零 ETL 整合的支援區域和 Aurora 資料庫引擎。
