本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Aurora PostgreSQL Limitless Database 的 DDL 限制和其他資訊
下列主題說明限制,或提供 Aurora PostgreSQL Limitless Database 中 DDL SQL 命令的詳細資訊。
主題
ALTER TABLE
Aurora PostgreSQL Limitless Database 中通常支援 ALTER TABLE 命令。如需詳細資訊,請參閱 PostgreSQL 文件中的 ALTER TABLE
限制
ALTER TABLE 對於支援的選項有下列限制。
- 移除欄
-
-
在碎片資料表,您無法移除屬於碎片索引鍵一部分的欄。
-
在參考資料表,您無法移除主索引鍵欄。
-
- 變更資料欄的資料類型
-
-
不支援
USING運算式。 -
在碎片資料表,您無法變更屬於碎片索引鍵的欄類型。
-
- 新增或移除限制條件
-
如需不支援之項目的詳細資訊,請參閱Constraints。
- 變更欄的預設值
-
支援預設值。如需詳細資訊,請參閱預設值。
不支援的選項
不支援某些選項,因為其與不支援的功能相依,例如觸發。
不支援 ALTER TABLE 的下列資料表層級選項:
-
ALL IN TABLESPACE -
ATTACH PARTITION -
DETACH PARTITION -
ONLY標記 -
RENAME CONSTRAINT
不支援 ALTER TABLE 的下列欄層級選項:
-
ADD GENERATED
-
DROP EXPRESSION [ IF EXISTS ]
-
DROP IDENTITY [ IF EXISTS ]
-
RESET
-
RESTART
-
SET
-
SET COMPRESSION
-
SET STATISTICS
CREATE DATABASE
在 Aurora PostgreSQL Limitless Database 中,僅支援無限資料庫。
執行 CREATE DATABASE 時,在一或多個節點中成功建立的資料庫可能會在其他節點中失敗,因為資料庫建立是非交易操作。在這種情況下,成功建立的資料庫物件會在預定時間內自動從所有節點中移除,以保持資料庫碎片群組中的一致性。在此期間,以相同名稱重新建立資料庫可能會導致錯誤,指出資料庫已存在。
支援下列選項:
-
定序:
CREATE DATABASEnameWITH [LOCALE =locale] [LC_COLLATE =lc_collate] [LC_CTYPE =lc_ctype] [ICU_LOCALE =icu_locale] [ICU_RULES =icu_rules] [LOCALE_PROVIDER =locale_provider] [COLLATION_VERSION =collation_version]; -
CREATE DATABASE WITH OWNER:CREATE DATABASEnameWITH OWNER =user_name;
不支援下列選項:
-
CREATE DATABASE WITH TABLESPACE:CREATE DATABASEnameWITH TABLESPACE =tablespace_name; -
CREATE DATABASE WITH TEMPLATE:CREATE DATABASEnameWITH TEMPLATE =template;
CREATE INDEX
針對碎片資料表,支援 CREATE INDEX CONCURRENTLY:
CREATE INDEX CONCURRENTLYindex_nameONtable_name(column_name);
針對所有資料表類型,支援 CREATE UNIQUE INDEX:
CREATE UNIQUE INDEXindex_nameONtable_name(column_name);
不支援 CREATE UNIQUE INDEX CONCURRENTLY:
CREATE UNIQUE INDEX CONCURRENTLYindex_nameONtable_name(column_name);
如需詳細資訊,請參閱 UNIQUE。如需建立索引的一般資訊,請參閱 PostgreSQL 文件中的 CREATE INDEX
- 顯示索引
-
當您使用
\d或類似命令時,並非所有索引都會在路由器上可見。反之,請如下列範例所示,使用table_namepg_catalog.pg_indexes檢視來取得索引。SET rds_aurora.limitless_create_table_mode='sharded'; SET rds_aurora.limitless_create_table_shard_key='{"id"}'; CREATE TABLE items (id int PRIMARY KEY, val int); CREATE INDEX items_my_index on items (id, val); postgres_limitless=> SELECT * FROM pg_catalog.pg_indexes WHERE tablename='items'; schemaname | tablename | indexname | tablespace | indexdef ------------+-----------+----------------+------------+------------------------------------------------------------------------ public | items | items_my_index | | CREATE INDEX items_my_index ON ONLY public.items USING btree (id, val) public | items | items_pkey | | CREATE UNIQUE INDEX items_pkey ON ONLY public.items USING btree (id) (2 rows)
CREATE SCHEMA
不支援具有結構描述元素的 CREATE SCHEMA:
CREATE SCHEMAmy_schemaCREATE TABLE (column_nameINT);
此會產生如下的錯誤:
ERROR: CREATE SCHEMA with schema elements is not supported
CREATE TABLE
不支援 CREATE TABLE 陳述式中的關係,例如:
CREATE TABLE orders (orderid int, customerId int, orderDate date) WITH (autovacuum_enabled = false);
不支援 IDENTITY 欄,例如:
CREATE TABLE orders (orderid INT GENERATED ALWAYS AS IDENTITY);
Aurora PostgreSQL Limitless Database 支援最多 54 個字元的碎片資料表名稱。
CREATE TABLE AS
若要使用 CREATE TABLE AS 建立資料表,您必須使用 rds_aurora.limitless_create_table_mode 變數。對於碎片資料表,您還必須使用 rds_aurora.limitless_create_table_shard_key 變數。如需詳細資訊,請參閱使用變數建立無限資料表。
-- Set the variables. SET rds_aurora.limitless_create_table_mode='sharded'; SET rds_aurora.limitless_create_table_shard_key='{"a"}'; CREATE TABLE ctas_table AS SELECT 1 a; -- "source" is the source table whose columns and data types are used to create the new "ctas_table2" table. CREATE TABLE ctas_table2 AS SELECT a,b FROM source;
您無法使用 CREATE TABLE AS 建立參考資料表,因為其需要主索引鍵限制條件。CREATE TABLE
AS 不會將主索引鍵傳播到新資料表。
如需一般資訊,請參閱 PostgreSQL 文件中的 CREATE TABLE AS
DROP DATABASE
您可以捨棄已建立的資料庫。
DROP DATABASE 命令會在背景中以非同步方式執行。執行時,如果您嘗試建立同名的新資料庫,則會收到錯誤。
SELECT INTO
SELECT INTO 的功能類似於 CREATE TABLE AS。您必須使用 rds_aurora.limitless_create_table_mode 變數。對於碎片資料表,您還必須使用 rds_aurora.limitless_create_table_shard_key 變數。如需詳細資訊,請參閱使用變數建立無限資料表。
-- Set the variables. SET rds_aurora.limitless_create_table_mode='sharded'; SET rds_aurora.limitless_create_table_shard_key='{"a"}'; -- "source" is the source table whose columns and data types are used to create the new "destination" table. SELECT * INTO destination FROM source;
目前,SELECT INTO 操作是透過路由器 (而不是直接透過碎片) 執行。因此,效能可能會很慢。
如需一般資訊,請參閱 PostgreSQL 文件中的 SELECT INTO
Constraints
下列限制適用於 Aurora PostgreSQL Limitless Database 中的限制條件。
- CHECK
-
支援涉及比較運算子與常值的簡單限制條件。如下列範例所示,不支援需要函數驗證的更複雜運算式和限制條件。
CREATE TABLE my_table ( id INT CHECK (id > 0) -- supported , val INT CHECK (val > 0 AND val < 1000) -- supported , tag TEXT CHECK (length(tag) > 0) -- not supported: throws "Expression inside CHECK constraint is not supported" , op_date TIMESTAMP WITH TIME ZONE CHECK (op_date <= now()) -- not supported: throws "Expression inside CHECK constraint is not supported" );您可以如下列範例所示,提供限制條件明確名稱。
CREATE TABLE my_table ( id INT CONSTRAINT positive_id CHECK (id > 0) , val INT CONSTRAINT val_in_range CHECK (val > 0 AND val < 1000) );您可以如下列範例所示,將資料表層級限制條件語法與
CHECK限制條件搭配使用。CREATE TABLE my_table ( id INT CONSTRAINT positive_id CHECK (id > 0) , min_val INT CONSTRAINT min_val_in_range CHECK (min_val > 0 AND min_val < 1000) , max_val INT , CONSTRAINT max_val_in_range CHECK (max_val > 0 AND max_val < 1000 AND max_val > min_val) ); - EXCLUDE
-
Aurora PostgreSQL Limitless Database 中不支援排除限制條件。
- FOREIGN KEY
-
如需詳細資訊,請參閱外部索引鍵。
- NOT NULL
-
支援
NOT NULL限制條件,沒有限制。 - PRIMARY KEY
-
主索引鍵表示唯一限制條件,因此對唯一限制條件的相同限制適用於主索引鍵。這表示:
-
如果將資料表轉換為碎片資料表,碎片索引鍵必須是主索引鍵的子集。也就是說,主索引鍵包含碎片索引鍵的所有欄。
-
如果將資料表轉換為參考資料表,則其必須有主索引鍵。
下列範例說明主索引鍵的使用方式。
-- Create a standard table. CREATE TABLE public.my_table ( item_id INT , location_code INT , val INT , comment text ); -- Change the table to a sharded table using the 'item_id' and 'location_code' columns as shard keys. CALL rds_aurora.limitless_alter_table_type_sharded('public.my_table', ARRAY['item_id', 'location_code']);嘗試新增不包含碎片索引鍵的主索引鍵:
-- Add column 'item_id' as the primary key. -- Invalid because the primary key doesnt include all columns from the shard key: -- 'location_code' is part of the shard key but not part of the primary key ALTER TABLE public.my_table ADD PRIMARY KEY (item_id); -- ERROR -- add column "val" as primary key -- Invalid because primary key does not include all columns from shard key: -- item_id and location_code iare part of shard key but not part of the primary key ALTER TABLE public.my_table ADD PRIMARY KEY (item_id); -- ERROR嘗試新增包含碎片索引鍵的主索引鍵:
-- Add the 'item_id' and 'location_code' columns as the primary key. -- Valid because the primary key contains the shard key. ALTER TABLE public.my_table ADD PRIMARY KEY (item_id, location_code); -- OK -- Add the 'item_id', 'location_code', and 'val' columns as the primary key. -- Valid because the primary key contains the shard key. ALTER TABLE public.my_table ADD PRIMARY KEY (item_id, location_code, val); -- OK將標準資料表變更為參考資料表。
-- Create a standard table. CREATE TABLE zipcodes (zipcode INT PRIMARY KEY, details VARCHAR); -- Convert the table to a reference table. CALL rds_aurora.limitless_alter_table_type_reference('public.zipcode');如需建立碎片和參考資料表的詳細資訊,請參閱建立 Aurora PostgreSQL Limitless Database 資料表。
-
- UNIQUE
-
在碎片資料表中,唯一索引鍵必須包含碎片索引鍵,也就是說,碎片索引鍵必須是唯一索引鍵的子集。將資料表類型變更為碎片時會檢查此項目。在參考資料表中沒有限制。
CREATE TABLE customer ( customer_id INT NOT NULL , zipcode INT , email TEXT UNIQUE );如下列範例所示,支援資料表層級
UNIQUE限制條件。CREATE TABLE customer ( customer_id INT NOT NULL , zipcode INT , email TEXT , CONSTRAINT zipcode_and_email UNIQUE (zipcode, email) );下列範例示範同時使用主索引鍵和唯一索引鍵。這兩個索引鍵都必須包含碎片索引鍵。
SET rds_aurora.limitless_create_table_mode='sharded'; SET rds_aurora.limitless_create_table_shard_key='{"p_id"}'; CREATE TABLE t1 ( p_id BIGINT NOT NULL, c_id BIGINT NOT NULL, PRIMARY KEY (p_id), UNIQUE (p_id, c_id) );
如需詳細資訊,請參閱 PostgreSQL 文件中的限制條件
預設值
Aurora PostgreSQL Limitless Database 支援預設值中的運算式。
下列範例示範預設值的使用方式。
CREATE TABLE t ( a INT DEFAULT 5, b TEXT DEFAULT 'NAN', c NUMERIC ); CALL rds_aurora.limitless_alter_table_type_sharded('t', ARRAY['a']); INSERT INTO t DEFAULT VALUES; SELECT * FROM t; a | b | c ---+-----+--- 5 | NAN | (1 row)
如下列範例所示,支援運算式。
CREATE TABLE t1 (a NUMERIC DEFAULT random());
下列範例會新增新欄,該欄為 NOT NULL 且具有預設值。
ALTER TABLE t ADD COLUMN d BOOLEAN NOT NULL DEFAULT FALSE; SELECT * FROM t; a | b | c | d ---+-----+---+--- 5 | NAN | | f (1 row)
下列範例會變更具有預設值的現有欄。
ALTER TABLE t ALTER COLUMN c SET DEFAULT 0.0; INSERT INTO t DEFAULT VALUES; SELECT * FROM t; a | b | c | d ---+-----+-----+----- 5 | NAN | | f 5 | NAN | 0.0 | f (2 rows)
下列範例會捨棄預設值。
ALTER TABLE t ALTER COLUMN a DROP DEFAULT; INSERT INTO t DEFAULT VALUES; SELECT * FROM t; a | b | c | d ---+-----+-----+----- 5 | NAN | | f 5 | NAN | 0.0 | f | NAN | 0.0 | f (3 rows)
如需的詳細資訊,請參閱 PostgreSQL 文件中的預設值
延伸模組
Aurora PostgreSQL Limitless Database 支援下列 PostgreSQL 延伸模組:
-
aurora_limitless_fdw:已預先安裝此延伸模組。您無法將其捨棄。 -
aws_s3:此延伸模組可在 Aurora PostgreSQL Limitless Database 中運作,運作方式與在 Aurora PostgreSQL 中類似。您可以將資料從 Amazon S3 儲存貯體匯入 Aurora PostgreSQL 資料庫叢集,或將資料從 Aurora PostgreSQL Limitless Database 資料庫叢集匯出至 Amazon S3 儲存貯體。如需詳細資訊,請參閱將資料從 Amazon S3 匯入 Aurora PostgreSQL 資料庫叢集 及將資料從 Aurora PostgreSQL 資料庫叢集匯出至 Amazon S3。
-
btree_gin -
citext -
ip4r -
pg_buffercache:此延伸模組在 Aurora PostgreSQL Limitless Database 中的行為與在社群 PostgreSQL 不同。如需詳細資訊,請參閱Aurora PostgreSQL Limitless Database 中的 pg_buffercache 差異。 -
pg_stat_statements -
pg_trgm -
pgcrypto -
pgstattuple:此延伸模組在 Aurora PostgreSQL Limitless Database 中的行為與在社群 PostgreSQL 不同。如需詳細資訊,請參閱Aurora PostgreSQL Limitless Database 中的 pgstattuple 差異。 -
pgvector -
plpgsql:已預先安裝此延伸模組,但您可以將其捨棄。 -
PostGIS:不支援長交易和資料表管理函數。不支援對空間參考資料表進行修改。 -
unaccent -
uuid
Aurora PostgreSQL Limitless Database 目前不支援大多數 PostgreSQL 延伸模組。不過,您仍然可以使用 shared_preload_libraries
例如,您可以載入 pg_hint_plan 延伸模組,但載入延伸模組並不保證使用查詢註解中傳遞的提示。
注意
您無法修改與 pg_stat_statementspg_stat_statements 的資訊,請參閱 limitless_stat_statements。
您可以使用 pg_available_extensions 和 pg_available_extension_versions 函數,來尋找 Aurora PostgreSQL Limitless Database 中支援的延伸模組。
針對以下延伸模組,支援以下 DDL:
- CREATE EXTENSION
-
您可以如 PostgreSQL 中所示建立延伸模組。
CREATE EXTENSION [ IF NOT EXISTS ]extension_name[ WITH ] [ SCHEMAschema_name] [ VERSIONversion] [ CASCADE ]如需詳細資訊,請參閱 PostgreSQL 文件中的 CREATE EXTENSION
。 - ALTER EXTENSION
-
支援的 DDL 如下:
ALTER EXTENSIONnameUPDATE [ TOnew_version] ALTER EXTENSIONnameSET SCHEMAnew_schema如需詳細資訊,請參閱 PostgreSQL 文件中的 ALTER EXTENSION
。 - DROP EXTENSION
-
您可以如 PostgreSQL 中所示捨棄延伸模組。
DROP EXTENSION [ IF EXISTS ] name [, ...] [ CASCADE | RESTRICT ]如需詳細資訊,請參閱 PostgreSQL 文件中的 DROP EXTENSION
。
針對以下延伸模組,不支援以下 DDL:
- ALTER EXTENSION
-
您無法從延伸模組新增或捨棄成員物件。
ALTER EXTENSIONnameADDmember_objectALTER EXTENSIONnameDROPmember_object
Aurora PostgreSQL Limitless Database 中的 pg_buffercache 差異
在 Aurora PostgreSQL Limitless Database 中,當您安裝 pg_buffercachepg_buffercache 檢視時,您只會從目前連線的節點接收緩衝區相關資訊:路由器。同樣地,使用函數 pg_buffercache_summary 或 pg_buffercache_usage_counts 僅提供來自連線節點的資訊。
您可以擁有許多節點,而且可能需要從任何節點存取緩衝區資訊,才能有效地診斷問題。因此,Limitless Database 提供下列函數:
-
rds_aurora.limitless_pg_buffercache(subcluster_id) -
rds_aurora.limitless_pg_buffercache_summary(subcluster_id) -
rds_aurora.limitless_pg_buffercache_usage_counts(subcluster_id)
透過輸入任何節點的子叢集 ID (無論是路由器還是碎片),您都可以輕鬆存取該節點特定的緩衝區資訊。當您在無限資料庫中安裝 pg_buffercache 延伸模組時,即可直接使用這些函數。
注意
Aurora PostgreSQL Limitless Database 支援 1.4 版及更新版本的 pg_buffercache 延伸模組的這些函數。
limitless_pg_buffercache 檢視中顯示的欄與 pg_buffercache 檢視中的欄略有不同:
-
bufferid:與pg_buffercache保持不變。 -
relname:與pg_buffercache中顯示的檔案節點編號不同,limitless_pg_buffercache會呈現目前資料庫或共用系統目錄中可用的相關relname,否則會顯示NULL。 -
parent_relname:此新欄在pg_buffercache中不存在,如果relname欄中的值代表分割的資料表 (如果是碎片資料表),則會顯示父項relname。否則,會顯示NULL。 -
spcname:limitless_pg_buffercache會顯示資料表空間名稱,而不是在pg_buffercache中顯示資料表空間物件識別符 (OID)。 -
datname:limitless_pg_buffercache會顯示資料庫名稱,而不是在pg_buffercache中顯示資料庫 OID。 -
relforknumber:與pg_buffercache保持不變。 -
relblocknumber:與pg_buffercache保持不變。 -
isdirty:與pg_buffercache保持不變。 -
usagecount:與pg_buffercache保持不變。 -
pinning_backends:與pg_buffercache保持不變。
limitless_pg_buffercache_summary 和 limitless_pg_buffercache_usage_counts 檢視中的欄分別與一般 pg_buffercache_summary 和 pg_buffercache_usage_counts 檢視中的欄相同。
透過使用這些函數,您可以存取 Limitless Database 環境中所有節點的詳細緩衝區快取資訊,從而更有效地診斷和管理資料庫系統。
Aurora PostgreSQL Limitless Database 中的 pgstattuple 差異
在 Aurora PostgreSQL 中,pgstattuple
我們了解此延伸模組對於取得元組層級統計資料的重要性,這對於排除膨脹和收集診斷資訊等任務至關重要。因此,Aurora PostgreSQL Limitless Database 支援無限資料庫中的 pgstattuple 延伸模組。
Aurora PostgreSQL Limitless Database 在 rds_aurora 結構描述中包含下列函數:
- 元組層級統計資料函數
-
rds_aurora.limitless_pgstattuple(relation_name)-
目的:擷取標準資料表及其索引的元組層級統計資料
-
輸入:
relation_name(文字):關係的名稱 -
輸出:欄與 Aurora PostgreSQL 中的
pgstattuple函數傳回的欄一致
rds_aurora.limitless_pgstattuple(relation_name,subcluster_id)-
目的:擷取參考資料表、碎片資料表、目錄資料表及其索引的元組層級統計資料
-
輸入:
-
relation_name(文字):關係的名稱 -
subcluster_id(文字):要擷取統計資料之節點的子叢集 ID
-
-
輸出:
-
對於參考和目錄資料表 (包括其索引),欄與 Aurora PostgreSQL 中的欄一致。
-
對於碎片資料表,統計資料僅代表位於指定子叢集上碎片資料表的分割區。
-
-
- 索引統計資料函數
-
rds_aurora.limitless_pgstatindex(relation_name)-
目的:擷取標準資料表上 B 型樹狀索引的統計資料
-
輸入:
relation_name(文字):B 型樹狀索引的名稱 -
輸出:傳回除
root_block_no以外的所有欄。傳回的欄與 Aurora PostgreSQL 中的pgstatindex函數一致。
rds_aurora.limitless_pgstatindex(relation_name,subcluster_id)-
目的:擷取參考資料表、碎片資料表和目錄資料表上 B 型樹狀索引的統計資料。
-
輸入:
-
relation_name(文字):B 型樹狀索引的名稱 -
subcluster_id(文字):要擷取統計資料之節點的子叢集 ID
-
-
輸出:
-
對於參考和目錄資料表索引,會傳回所有欄 (
root_block_no除外)。傳回的欄與 Aurora PostgreSQL 一致。 -
對於碎片資料表,統計資料僅代表位於指定子叢集上碎片資料表索引的分割區。
tree_level欄會顯示請求子叢集上所有資料表配量中的平均值。
-
rds_aurora.limitless_pgstatginindex(relation_name)-
目的:擷取標準資料表一般化反轉索引 (GIN) 統計資料
-
輸入:
relation_name(文字):GIN 的名稱 -
輸出:欄與 Aurora PostgreSQL 中的
pgstatginindex函數傳回的欄一致
rds_aurora.limitless_pgstatginindex(relation_name,subcluster_id)-
目的:擷取參考資料表、碎片資料表和目錄資料表上 GIN 索引的統計資料。
-
輸入:
-
relation_name(文字):索引的名稱 -
subcluster_id(文字):要擷取統計資料之節點的子叢集 ID
-
-
輸出:
-
對於參考和目錄資料表 GIN 索引,欄與 Aurora PostgreSQL 中的欄一致。
-
對於碎片資料表,統計資料僅代表位於指定子叢集上碎片資料表索引的分割區。
-
rds_aurora.limitless_pgstathashindex(relation_name)-
目的:擷取標準資料表上雜湊索引的統計資料
-
輸入:
relation_name(文字):雜湊索引的名稱 -
輸出:欄與 Aurora PostgreSQL 中的
pgstathashindex函數傳回的欄一致
rds_aurora.limitless_pgstathashindex(relation_name,subcluster_id)-
目的:擷取參考資料表、碎片資料表和目錄資料表上雜湊索引的統計資料。
-
輸入:
-
relation_name(文字):索引的名稱 -
subcluster_id(文字):要擷取統計資料之節點的子叢集 ID
-
-
輸出:
-
對於參考和目錄資料表雜湊索引,欄與 Aurora PostgreSQL 一致。
-
對於碎片資料表,統計資料僅代表位於指定子叢集上碎片資料表索引的分割區。
-
-
- 頁面計數函數
-
rds_aurora.limitless_pg_relpages(relation_name)-
目的:擷取標準資料表及其索引的頁面計數
-
輸入:
relation_name(文字):關係的名稱 -
輸出:指定關係的頁面計數
rds_aurora.limitless_pg_relpages(relation_name,subcluster_id)-
目的:擷取參考資料表、碎片資料表和目錄資料表 (包括其索引) 的頁面計數
-
輸入:
-
relation_name(文字):關係的名稱 -
subcluster_id(文字):要擷取頁面計數之節點的子叢集 ID
-
-
輸出:對於碎片資料表,頁面計數是指定子叢集上所有資料表配量中的頁面總和。
-
- 約略元組層級統計資料函數
-
rds_aurora.limitless_pgstattuple_approx(relation_name)-
目的:擷取標準資料表及其索引的約略元組層級統計資料
-
輸入:
relation_name(文字):關係的名稱 -
輸出:欄與 Aurora PostgreSQL 中 pgstattuple_approx 函數傳回的欄一致
rds_aurora.limitless_pgstattuple_approx(relation_name,subcluster_id)-
目的:擷取參考資料表、碎片資料表和目錄資料表 (包括其索引) 的約略元組層級統計資料
-
輸入:
-
relation_name(文字):關係的名稱 -
subcluster_id(文字):要擷取統計資料之節點的子叢集 ID
-
-
輸出:
-
對於參考和目錄資料表 (包括其索引),欄與 Aurora PostgreSQL 中的欄一致。
-
對於碎片資料表,統計資料僅代表位於指定子叢集上碎片資料表的分割區。
-
-
注意
目前,Aurora PostgreSQL Limitless Database 不支援具體化視觀表、TOAST 資料表或暫存資料表上的 pgstattuple 延伸模組。
在 Aurora PostgreSQL Limitless Database 中,您必須以文字形式提供輸入,但 Aurora PostgreSQL 支援其他格式。
外部索引鍵
支援外部索引鍵 (FOREIGN KEY) 限制條件,但有一些限制:
-
僅針對標準資料表,支援
CREATE TABLE搭配FOREIGN KEY。若要使用FOREIGN KEY建立碎片或參考資料表,請先建立沒有外部索引鍵限制條件的資料表。然後使用下列陳述式進行修改:ALTER TABLE ADD CONSTRAINT; -
當資料表具有外部索引鍵限制條件時,不支援將標準資料表轉換為碎片或參考資料表。捨棄限制條件,然後在轉換後加以新增。
-
下列限制適用於外部索引鍵限制條件的資料表類型:
-
標準資料表可以對另一個標準資料表有外部索引鍵限制條件。
-
如果父資料表和子資料表共置,且外部索引鍵是碎片索引鍵的超集,則碎片資料表可能會有外部索引鍵限制條件。
-
碎片資料表對參考資料表可能有外部索引鍵限制條件。
-
參考資料表對另一個參考資料表可能有外部索引鍵限制條件。
-
外部索引鍵選項
對於某些 DDL 選項,Aurora PostgreSQL Limitless Database 中支援外部索引鍵。下表列出 Aurora PostgreSQL Limitless Database 資料表之間支援和不支援的選項。
| DDL 選項 | 參考到參考 | 碎片到碎片 (共置) | 碎片到參考 | 標準到標準 |
|---|---|---|---|---|
|
|
是 | 是 | 是 | 是 |
|
|
是 | 是 | 是 | 是 |
|
|
是 | 是 | 是 | 是 |
|
|
是 | 是 | 是 | 是 |
|
|
否 | 否 | 否 | 否 |
|
|
是 | 是 | 是 | 是 |
|
|
是 | 是 | 是 | 是 |
|
|
是 | 否 | 否 | 是 |
|
|
是 | 是 | 是 | 是 |
|
|
是 | 是 | 是 | 是 |
|
|
是 | 是 | 是 | 是 |
|
|
否 | 否 | 否 | 否 |
|
|
是 | 否 | 否 | 是 |
|
|
否 | 否 | 否 | 是 |
|
|
是 | 是 | 是 | 是 |
|
|
是 | 是 | 是 | 是 |
|
|
否 | 否 | 否 | 否 |
|
|
是 | 否 | 否 | 是 |
範例
-
標準到標準:
set rds_aurora.limitless_create_table_mode='standard'; CREATE TABLE products( product_no integer PRIMARY KEY, name text, price numeric ); CREATE TABLE orders ( order_id integer PRIMARY KEY, product_no integer REFERENCES products (product_no), quantity integer ); SELECT constraint_name, table_name, constraint_type FROM information_schema.table_constraints WHERE constraint_type='FOREIGN KEY'; constraint_name | table_name | constraint_type -------------------------+-------------+----------------- orders_product_no_fkey | orders | FOREIGN KEY (1 row) -
碎片到碎片 (共置):
set rds_aurora.limitless_create_table_mode='sharded'; set rds_aurora.limitless_create_table_shard_key='{"product_no"}'; CREATE TABLE products( product_no integer PRIMARY KEY, name text, price numeric ); set rds_aurora.limitless_create_table_shard_key='{"order_id"}'; set rds_aurora.limitless_create_table_collocate_with='products'; CREATE TABLE orders ( order_id integer PRIMARY KEY, product_no integer, quantity integer ); ALTER TABLE orders ADD CONSTRAINT order_product_fk FOREIGN KEY (product_no) REFERENCES products (product_no); -
碎片到參考:
set rds_aurora.limitless_create_table_mode='reference'; CREATE TABLE products( product_no integer PRIMARY KEY, name text, price numeric ); set rds_aurora.limitless_create_table_mode='sharded'; set rds_aurora.limitless_create_table_shard_key='{"order_id"}'; CREATE TABLE orders ( order_id integer PRIMARY KEY, product_no integer, quantity integer ); ALTER TABLE orders ADD CONSTRAINT order_product_fk FOREIGN KEY (product_no) REFERENCES products (product_no); -
參考到參考:
set rds_aurora.limitless_create_table_mode='reference'; CREATE TABLE products( product_no integer PRIMARY KEY, name text, price numeric ); CREATE TABLE orders ( order_id integer PRIMARY KEY, product_no integer, quantity integer ); ALTER TABLE orders ADD CONSTRAINT order_product_fk FOREIGN KEY (product_no) REFERENCES products (product_no);
函數
Aurora PostgreSQL Limitless Database 中支援函數。
針對函數,以下是支援的 DDL:
- CREATE FUNCTION
-
您可以像在 Aurora PostgreSQL 中一樣建立函數,在取代時變更其波動除外。
如需詳細資訊,請參閱 PostgreSQL 文件中的 CREATE FUNCTION
。 - ALTER FUNCTION
-
您可以像 Aurora PostgreSQL 一樣變更函數,但變更其波動除外。
如需詳細資訊,請參閱 PostgreSQL 文件中的 ALTER FUNCTION
。 - DROP FUNCTION
-
您可以如 Aurora PostgreSQL 中所示捨棄函數。
DROP FUNCTION [ IF EXISTS ]name[ ( [ [argmode] [argname]argtype[, ...] ] ) ] [, ...] [ CASCADE | RESTRICT ]如需詳細資訊,請參閱 PostgreSQL 文件中的 DROP FUNCTION
。
函數分佈
當函數的所有陳述式都以單一碎片為目標時,將整個函數向下推送到目標碎片是有益的。然後,結果會傳播回路由器 (而不是在路由器本身顯示函數)。函數和預存程序下推功能對於想要更接近資料來源 (也就是碎片) 的位置執行函數或預存程序的客戶而言相當實用。
若要分佈函數,請先建立函數,然後呼叫 rds_aurora.limitless_distribute_function 程序來分佈函數。此函數使用以下語法:
SELECT rds_aurora.limitless_distribute_function('function_prototype', ARRAY['shard_key'], 'collocating_table');
此函數採用下列參數:
-
function_prototype如果將任何引數定義為
OUT參數,請勿在function_prototype的引數中包含其類型。 -
ARRAY[':識別為函數碎片索引鍵的函數引數清單。shard_key'] -
collocating_table
若要識別要下推此函數以執行的碎片,系統會採用 ARRAY[' 引數、對其進行雜湊,並從 shard_key']collocating_table
- 限制
-
當您分佈函數或程序時,其只會處理該碎片中碎片索引鍵範圍所限制的資料。如果函數或程序嘗試從不同的碎片存取資料,則分散式函數或程序傳回的結果將與非分散式的函數或程序的結果不同。
例如,您建立一個函數,其中包含會觸動多個碎片的查詢,然後呼叫
rds_aurora.limitless_distribute_function程序來加以分佈。當您提供碎片索引鍵的引數來調用此函數時,執行該函數的結果可能會受到該碎片中存在的值所限制。這些結果與在不分佈函數的情況下產生的結果不同。 - 範例
-
請考慮以下函數
func,其中我們有具有碎片索引鍵customer_id的碎片資料表customers。postgres_limitless=> CREATE OR REPLACE FUNCTION func(c_id integer, sc integer) RETURNS int language SQL volatile AS $$ UPDATE customers SET score = sc WHERE customer_id = c_id RETURNING score; $$;現在我們分佈此函數:
SELECT rds_aurora.limitless_distribute_function('func(integer, integer)', ARRAY['c_id'], 'customers');以下是範例查詢計劃。
EXPLAIN(costs false, verbose true) SELECT func(27+1,10); QUERY PLAN -------------------------------------------------- Foreign Scan Output: (func((27 + 1), 10)) Remote SQL: SELECT func((27 + 1), 10) AS func Single Shard Optimized (4 rows)EXPLAIN(costs false, verbose true) SELECT * FROM customers,func(customer_id, score) WHERE customer_id=10 AND score=27; QUERY PLAN --------------------------------------------------------------------- Foreign Scan Output: customer_id, name, score, func Remote SQL: SELECT customers.customer_id, customers.name, customers.score, func.func FROM public.customers, LATERAL func(customers.customer_id, customers.score) func(func) WHERE ((customers.customer_id = 10) AND (customers.score = 27)) Single Shard Optimized (10 rows)下列範例示範具有
IN和OUT參數作為引數的程序。CREATE OR REPLACE FUNCTION get_data(OUT id INTEGER, IN arg_id INT) AS $$ BEGIN SELECT customer_id, INTO id FROM customer WHERE customer_id = arg_id; END; $$ LANGUAGE plpgsql;下列範例只會使用
IN參數來分佈程序。EXPLAIN(costs false, verbose true) SELECT * FROM get_data(1); QUERY PLAN ----------------------------------- Foreign Scan Output: id Remote SQL: SELECT customer_id FROM get_data(1) get_data(id) Single Shard Optimized (6 rows)
函數波動
您可以檢查 pg_procprovolatile 值,來判斷函數是不可變、穩定還是具有波動性。provolatile 值指出函數的結果是否僅取決於其輸入引數,還是受外部因素影響。
值可以是下列其中一項:
-
i:不可變函數,一律為相同的輸入提供相同的結果 -
s:穩定函數,其結果 (用於固定輸入) 在掃描中不會變更 -
v:揮發性函數,其結果可能隨時變更。也請將v用於具有副作用的函數,因此無法最佳化對這些函數的呼叫。
下列範例顯示波動性函數。
SELECT proname, provolatile FROM pg_proc WHERE proname='pg_sleep'; proname | provolatile ----------+------------- pg_sleep | v (1 row) SELECT proname, provolatile FROM pg_proc WHERE proname='uuid_generate_v4'; proname | provolatile ------------------+------------- uuid_generate_v4 | v (1 row) SELECT proname, provolatile FROM pg_proc WHERE proname='nextval'; proname | provolatile ---------+------------- nextval | v (1 row)
Aurora PostgreSQL Limitless Database 中不支援變更現有函數的波動。如下列範例所示,這同時適用於 ALTER FUNCTION 和 CREATE OR REPLACE FUNCTION 命令。
-- Create an immutable function CREATE FUNCTION immutable_func1(name text) RETURNS text language plpgsql AS $$ BEGIN RETURN name; END; $$IMMUTABLE; -- Altering the volatility throws an error ALTER FUNCTION immutable_func1 STABLE; -- Replacing the function with altered volatility throws an error CREATE OR REPLACE FUNCTION immutable_func1(name text) RETURNS text language plpgsql AS $$ BEGIN RETURN name; END; $$VOLATILE;
強烈建議您將正確的波動指派給函數。例如,如果函數從多個資料表使用 SELECT 或參考資料庫物件,請勿將其設為 IMMUTABLE。如果資料表內容變更,不變性就會中斷。
Aurora PostgreSQL 允許不可變函數中的 SELECT,但結果可能不正確。Aurora PostgreSQL Limitless Database 可能會同時傳回錯誤和不正確的結果。如需函數波動的詳細資訊,請參閱 PostgreSQL 文件中的函數波動類別
序列
具名序列是以遞增或遞減順序產生唯一數字的資料庫物件。CREATE SEQUENCE 會建立新的序號產生器。序列值保證是唯一的。
當您在 Aurora PostgreSQL Limitless Database 中建立具名序列時,系統會建立分散式序列物件。然後,Aurora PostgreSQL Limitless Database 會將非重疊的序列值區塊分佈到所有分散式交易路由器 (路由器)。區塊表示為路由器上的本機序列物件;因此,nextval 和 currval 等序列操作會在本機執行。路由器會獨立運作,並在需要時向分散式序列請求新的區塊。
如需序列的詳細資訊,請參閱 PostgreSQL 文件中的 CREATE SEQUENCE
請求新的區塊
您可以使用 rds_aurora.limitless_sequence_chunk_size 參數設定在路由器上分配的區塊大小。預設值為 250000。每個路由器最初擁有兩個區塊:作用中和預留。作用中區塊會用於設定本機序列物件 (設定 minvalue 和 maxvalue),而預留區塊會存放在內部目錄資料表中。當作用中區塊達到最小值或最大值時,會以預留區塊取代之。若要這樣做,系統會在內部使用 ALTER SEQUENCE,表示已取得 AccessExclusiveLock。
背景工作者每 10 秒在路由器節點執行一次,以掃描已使用預留區塊的序列。如果找到使用過的區塊,工作者會從分散式序列請求新的區塊。請務必設定夠大的區塊大小,讓背景工作者有足夠的時間來請求新的區塊。遠端請求永遠不會發生在使用者工作階段的情況中,這表示您無法直接請求新的序列。
限制
下列限制適用於 Aurora PostgreSQL Limitless Database 中的序列:
-
pg_sequence目錄、pg_sequences函數和SELECT * FROM陳述式都只顯示本機序列狀態 (而不是分散式狀態)。sequence_name -
序列值保證是唯一的,而且在工作階段中保證是單調的。但是,如果那些工作階段連接到其他路由器,則在其他工作階段中執行的
nextval陳述式可能會不按照順序。 -
請確定序列大小 (可用值的數量) 夠大,可以分佈到所有路由器。使用
rds_aurora.limitless_sequence_chunk_size參數來設定chunk_size。(每個路由器都有兩個區塊。) -
支援
CACHE選項,但快取必須小於chunk_size。
不支援的選項
Aurora PostgreSQL Limitless Database 中的序列不支援下列選項。
- 序列處理函式
-
不支援
setval函數。如需詳細資訊,請參閱 PostgreSQL 文件中的序列操作函數。 - CREATE SEQUENCE
-
不支援下列選項。
CREATE [{ TEMPORARY | TEMP} | UNLOGGED] SEQUENCE [[ NO ] CYCLE]如需詳細資訊,請參閱 PostgreSQL 文件中的 CREATE SEQUENCE
。 - ALTER SEQUENCE
-
不支援下列選項。
ALTER SEQUENCE [[ NO ] CYCLE]如需詳細資訊,請參閱 PostgreSQL 文件中的 ALTER SEQUENCE
。 - ALTER TABLE
-
針對序列,不支援
ALTER TABLE命令。
範例
- CREATE/DROP SEQUENCE
-
postgres_limitless=> CREATE SEQUENCE s; CREATE SEQUENCE postgres_limitless=> SELECT nextval('s'); nextval --------- 1 (1 row) postgres_limitless=> SELECT * FROM pg_sequence WHERE seqrelid='s'::regclass; seqrelid | seqtypid | seqstart | seqincrement | seqmax | seqmin | seqcache | seqcycle ----------+----------+----------+--------------+--------+--------+----------+---------- 16960 | 20 | 1 | 1 | 10000 | 1 | 1 | f (1 row) % connect to another router postgres_limitless=> SELECT nextval('s'); nextval --------- 10001 (1 row) postgres_limitless=> SELECT * FROM pg_sequence WHERE seqrelid='s'::regclass; seqrelid | seqtypid | seqstart | seqincrement | seqmax | seqmin | seqcache | seqcycle ----------+----------+----------+--------------+--------+--------+----------+---------- 16959 | 20 | 10001 | 1 | 20000 | 10001 | 1 | f (1 row) postgres_limitless=> DROP SEQUENCE s; DROP SEQUENCE - ALTER SEQUENCE
-
postgres_limitless=> CREATE SEQUENCE s; CREATE SEQUENCE postgres_limitless=> ALTER SEQUENCE s RESTART 500; ALTER SEQUENCE postgres_limitless=> SELECT nextval('s'); nextval --------- 500 (1 row) postgres_limitless=> SELECT currval('s'); currval --------- 500 (1 row) - 序列處理函式
-
postgres=# CREATE TABLE t(a bigint primary key, b bigint); CREATE TABLE postgres=# CREATE SEQUENCE s minvalue 0 START 0; CREATE SEQUENCE postgres=# INSERT INTO t VALUES (nextval('s'), currval('s')); INSERT 0 1 postgres=# INSERT INTO t VALUES (nextval('s'), currval('s')); INSERT 0 1 postgres=# SELECT * FROM t; a | b ---+--- 0 | 0 1 | 1 (2 rows) postgres=# ALTER SEQUENCE s RESTART 10000; ALTER SEQUENCE postgres=# INSERT INTO t VALUES (nextval('s'), currval('s')); INSERT 0 1 postgres=# SELECT * FROM t; a | b -------+------- 0 | 0 1 | 1 10000 | 10000 (3 rows)
序列檢視
Aurora PostgreSQL Limitless Database 提供下列序列檢視。
- rds_aurora.limitless_distributed_sequence
-
此檢視會顯示分散式序列狀態和組態。
minvalue、maxvalue、start、inc和cache欄具有與 pg_sequences檢視中相同的意義,以及顯示序列建立時所用的選項。 lastval欄會顯示分散式序列物件中最新分配或預留的值。這並不表示值已有人使用,因為路由器會在本機保留序列區塊。postgres_limitless=> SELECT * FROM rds_aurora.limitless_distributed_sequence WHERE sequence_name='test_serial_b_seq'; schema_name | sequence_name | lastval | minvalue | maxvalue | start | inc | cache -------------+-------------------+---------+----------+------------+-------+-----+------- public | test_serial_b_seq | 1250000 | 1 | 2147483647 | 1 | 1 | 1 (1 row) - rds_aurora.limitless_sequence_metadata
-
此檢視會顯示分散式序列中繼資料,並從叢集節點彙總序列中繼資料。其會使用下列欄:
-
subcluster_id:擁有區塊的叢集節點 ID。 -
作用中區塊:使用中的序列區塊 (
active_minvalue、active_maxvalue)。 -
預留區塊:接下來將使用的本機區塊 (
reserved_minvalue、reserved_maxvalue)。 -
local_last_value:來自本機序列的最後一個觀察值。 -
chunk_size:區塊的大小 (如建立時所設定)。
postgres_limitless=> SELECT * FROM rds_aurora.limitless_sequence_metadata WHERE sequence_name='test_serial_b_seq' order by subcluster_id; subcluster_id | sequence_name | schema_name | active_minvalue | active_maxvalue | reserved_minvalue | reserved_maxvalue | chunk_size | chunk_state | local_last_value ---------------+-------------------+-------------+-----------------+-----------------+-------------------+-------------------+------------+-------------+------------------ 1 | test_serial_b_seq | public | 500001 | 750000 | 1000001 | 1250000 | 250000 | 1 | 550010 2 | test_serial_b_seq | public | 250001 | 500000 | 750001 | 1000000 | 250000 | 1 | (2 rows) -
針對序列問題進行疑難排解
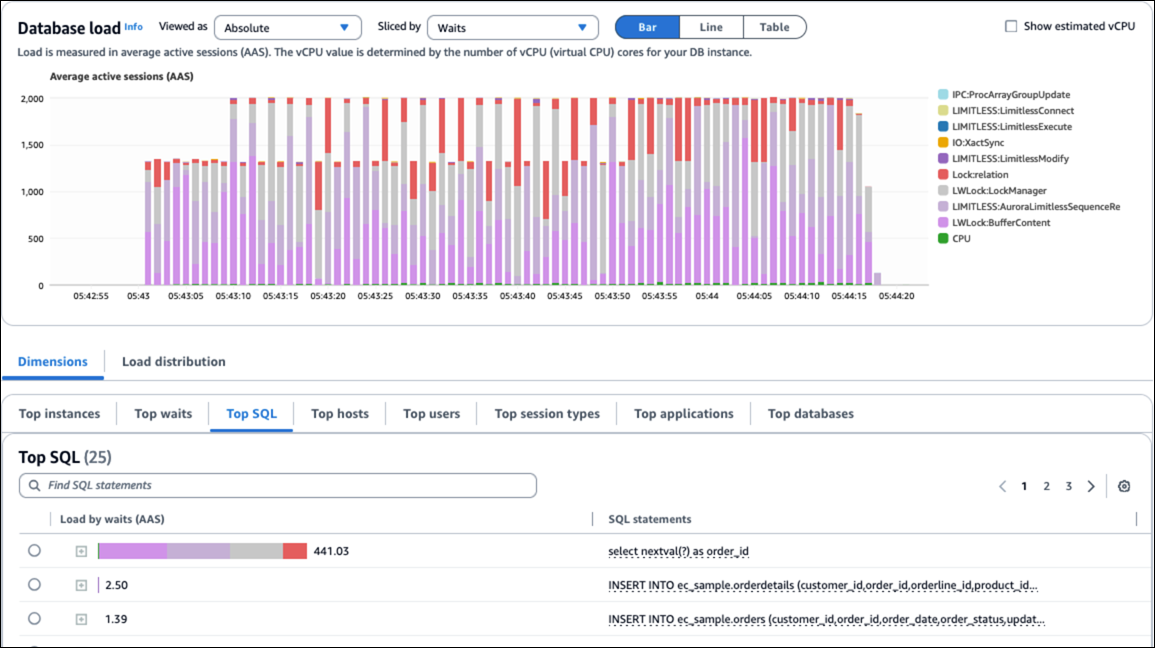
序列可能發生下列問題。
- 區塊大小不夠大
-
如果區塊大小設定不夠大且交易速率很高,背景工作者可能沒有足夠的時間,無法在作用中區塊用盡前請求新的區塊。這可能會導致爭用和等待事件,例如
LIMITLESS:AuroraLimitlessSequenceReplace、LWLock:LockManager、Lockrelation和LWlock:bufferscontent。增加
rds_aurora.limitless_sequence_chunk_size參數的值。 - 序列快取設定過高
-
在 PostgreSQL 中,序列快取會在工作階段層級發生。每個工作階段會在一次存取序列物件期間分配連續的序列值,並相應地增加序列物件的
last_value。然後,下次使用該工作階段中的nextval只會傳回預先分配的值 (而不會接觸序列物件)。當工作階段結束時,工作階段中分配但未使用的任何數字都會遺失,導致序列中出現「洞」。這可以快速使用 sequence_chunk,並導致爭用和等待事件,例如
LIMITLESS:AuroraLimitlessSequenceReplace、LWLock:LockManager、Lockrelation和LWlock:bufferscontent。減少序列快取設定。
下圖顯示序列問題引起的等待事件。