本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
服務水準目標 (SLO)
可以使用 Application Signals,為關鍵業務營運或相依項服務建立服務水準目標。透過針對這些服務建立 SLO,您將能夠在 SLO 儀表板中追蹤它們,從而可以一目了然地查看最重要的操作。
除了建立操作員可用來查看關鍵操作目前狀態的快速檢視之外,您還可以使用 SLO 來追蹤服務的長期效能,以確保它們符合您的期望。如果您與客戶達成服務水準協議,SLO 是確保滿足客戶的絕佳工具。
使用 SLO 評估服務的運作狀態首先要根據關鍵效能指標 (服務水準指標 (SLI)) 來設定明確、可衡量的目標。SLO 會根據您設定的閾值和目標來追蹤 SLI 效能,並報告應用程式效能與閾值之間的距離。
Application Signals 可協助您在關鍵效能指標上設定 SLO。Application Signals 會自動收集它發現的每個服務和操作的 Latency 和 Availability 指標,而且這些指標通常非常適合用作 SLI。透過 SLO 建立精靈,您可以將這些指標用於 SLO。然後,您可以使用 Application Signals 儀表板來追蹤所有 SLO 的狀態。
可以針對服務呼叫或使用的特定操作或相依項設定 SLO。除了使用 Latency 和 Availability 指標之外,您還可以將任何 CloudWatch 指標或指標運算式用作 SLI。
建立 SLO 對於從 CloudWatch Application Signals 中獲得最大收益非常重要。建立 SLO 之後,可以在 Application Signals 主控台中檢視其狀態,以快速查看哪些重要服務和操作執行良好以及哪些運作狀態不佳。使用 SLO 進行追蹤具有下列主要好處:
您的服務營運商可以更輕鬆地查看根據 SLI 所測量的關鍵服務的當前運行狀況。然後,他們可以快速分類和識別運作狀態不佳的服務和操作。
您可以在較長時間內針對可衡量的業務目標來追蹤服務績效。
透過選擇要設定 SLO 的內容,可以優先考慮對您重要的內容。Application Signals 儀表板會自動顯示您優先選擇的內容資訊。
當您建立 SLO 時,也可以選擇同時建立 CloudWatch 警示來監控 SLO。可以設定警示來監控閾值違規情況以及警告等級。如果 SLO 指標超出您設定的閾值,或者如果它們接近警告閾值,這些警示會自動通知您。例如,接近其警告閾值的 SLO 會通知您,您的團隊可能需要減慢應用程式中的流失速度,以確保實現長期效能目標。
主題
SLO 概念
SLO 包含下列要素:
服務水準指標 (SLI),這是您指定的主要效能指標。它表示應用程式所需的效能水準。Application Signals 會自動收集它發現的服務和操作的關鍵指標
Latency和Availability,而且這些指標通常非常適合用作 SLO。可以選擇用於 SLI 的閾值。例如,200 毫秒的延遲。
目標或達成率目標,也就是 SLI 預期在每個時間間隔內達到閾值的時間或請求數百分比。時間間隔可以短至幾小時或長達一年。
間隔可以是行事曆間隔或滾動間隔。
行事曆間隔會與行事曆一致,例如每月追蹤的 SLO。CloudWatch 會根據一個月中的天數,自動調整運作狀態、預算和達標數。行事曆間隔更適合按行事曆進行衡量的商業目標。
滾動間隔是在滾動基礎上計算。滾動間隔更適合追蹤應用程式的最新使用者體驗。
該時段長度較短,許多時段構成一個間隔。將應用程式的效能與間隔內每個時段的 SLI 進行比較。在每個時段,確定應用程式是否已達到必要效能。
例如,行事曆間隔為一天且週期為 1 分鐘的 99% 目標,表示應用程式必須在一天的 1 分鐘週期的 99% 內達到或實現成功閾值。如果是這樣,則當天實現 SLO。第二天是新的評估間隔,而且應用程式必須在第二天 1 分鐘週期的 99% 內達到或實現成功閾值,才能實現第二天的 SLO。
SLI 可以基於 Application Signals 收集的新標準應用程式指標之一。或者,它可以是任何 CloudWatch 指標或指標運算式。可用於 SLI 的標準應用程式指標為 Latency 和 Availability。Availability 表示成功回應除以請求總數。它的計算方式為 (1 - 故障率)*100,其中故障回應為 5xx 錯誤。成功回應是沒有 5XX 錯誤的回應。4XX 回應會被視為成功。
除了在單一操作或服務的所有操作上建立 SLOs 之外,您還可以建立複合 SLOs以監控服務的操作子集。複合 SLOs Availability 會跨多個操作彙總指標,讓您統一檢視一組相關操作的可靠性。您可以選擇要包含在複合 SLO 中的 2 到 20 個操作。如需詳細資訊,請參閱在多個操作上建立複合 SLO。
計算期間型 SLO 的錯誤預算和達成率
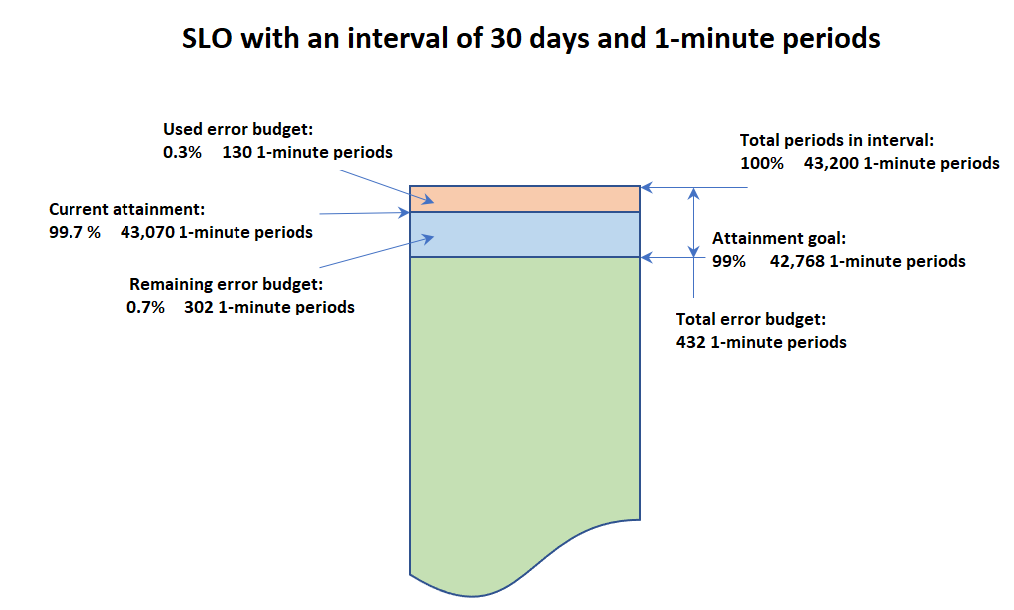
當您檢視 SLO 的相關資訊時,會看到其目前運作狀態及其錯誤預算。錯誤預算是突破閾值但仍可滿足 SLO 的間隔內的時間量。總錯誤預算是在整個間隔內可以容忍的違規時間總量。剩餘錯誤預算是目前間隔期間可以容忍的剩餘違規時間量。這是在從總錯誤預算中減去已經發生的違規時間量之後。
下圖說明間隔為 30 天、週期為 1 分鐘且達成目標為 99% 的目標的達成與錯誤預算概念。30 天包括 43,200 個 1 分鐘。43,200 的 99% 是 42,768,因此該月中的 42,768 分鐘必須運作正常,才能實現 SLO。到目前為止,在目前的間隔中,有 130 個 1 分鐘運作不佳。
確定每個週期內的成功
在每個週期內,SLI 資料會根據用於 SLI 的統計資料彙總為單一資料點。此資料點表示週期的整個長度。系統會將該單一資料點與 SLI 閾值進行比較,以判斷週期是否正常。在儀表板上查看目前時間範圍內的運作不佳週期,可能會提醒您的服務營運商需要對服務進行分類。
如果確定週期運作狀態不佳,則整個週期長度將根據錯誤預算計算為失敗。追蹤錯誤預算可讓您了解服務是否在較長時間內達到您想要的效能。
時間範圍排除
時間範圍排除是定義開始和結束日期的一段時間。此時間段將從 SLO 的效能指標中排除,您可以排定一次性或定期的時間排除時段。例如,排定的維護。
注意
對於期間型 SLO,排除時段中的 SLI 資料會被視為非違規。
對於請求型 SLO,排除時段中的所有有效與無效請求皆被排除。
完全排除請求型 SLO 的間隔時,系統將發布預設達成率指標 100%。
只能指定起始日期在未來的時段。
計算請求型 SLO 的錯誤預算和達成率
建立 SLO 之後,可以擷取其錯誤預算報告。錯誤預算是指應用程式在不符合 SLO 目標的情況下,仍能達成目標的請求數量上限。對於請求型 SLO,剩餘的錯誤預算具有動態特性,會根據有效請求與總請求數的比例而增減
下表說明請求型 SLO 的計算方式,間隔為 5 天,達成率目標為 85%。在此範例中,我們假設第 1 天之前沒有流量。SLO 在第 10 天未達成目標。
注意
對於請求型 SLOs, TotalRequestCountPerMinute和 BadRequestCountPerMinute會發出為與期間型 SLO 指標相比的額外指標。這些指標用於可觀測性目的,不會用作達成率計算的輸入。
由於這些指標是從定期評估的指標資料產生,因此由於指標發佈時間或延遲,其值偶爾可能會與預期的請求計數不同。此類差異不會影響 SLO 達成計算,這些計算與每分鐘發出的指標無關。
| 時間 | 請求總數 | 無效請求 | 過去 5 天的累計請求總數 | 過去 5 天的累計有效請求總數 | 以請求為基礎的達成率 | 預算請求總數 | 剩餘預算請求數 |
|---|---|---|---|---|---|---|---|
|
第 1 天 |
10 | 1 |
10 |
9 |
9/10=90% |
1.5 |
0.5 |
|
第 2 天 |
5 |
1 |
15 |
13 |
13/15=86% |
2.3 |
0.3 |
|
第 3 天 |
1 |
1 |
16 |
13 |
13/16=81% |
2.4 |
-0.6 |
|
第 4 天 |
24 |
0 |
40 |
37 |
37/40=92% |
6.0 |
3.0 |
|
第 5 天 |
20 |
5 |
60 |
52 |
52/60=87% |
9.0 |
1.0 |
|
第 6 天 |
6 |
2 |
56 |
47 |
47/56=84% |
8.4 |
-0.6 |
|
第 7 天 |
10 |
3 |
61 |
50 |
50/61=82% |
9.2 |
-1.8 |
|
第 8 天 |
15 |
6 |
75 |
59 |
59/75=79% |
11.3 |
-4.7 |
| 第 9 天 |
12 |
1 |
63 |
46 |
46/63=73% |
9.5 |
-7.5 |
|
第 10 天 |
5 |
57 |
40 |
40/57=70% |
8.5 |
-8.5 | |
|
過去 5 天的最終達成率 |
|
70% |
計算消耗率並選擇性地設定消耗率警示
可以使用 Application Signals 計算服務水準目標的消耗率。消耗率是一種指標,指出相對於 SLO 的達成率目標,服務耗用錯誤預算的速度。以基準錯誤率的倍數因子表示。
消耗率根據基準錯誤率計算,而基準錯誤率取決於達成率目標。達成率目標是為實現 SLO 目標必須達到的正常運作時段或成功請求百分比。基準錯誤率為 (100% - 達成率目標百分比),此數字會在 SLO 時間間隔結束時,精確耗盡完整的錯誤預算。因此,達成率目標為 99% 的 SLO 的基準錯誤率為 1%。
監控消耗率能讓我們了解,我們距離基準錯誤率有多遠。再次以 99% 的達成率目標為例,以下陳述成立:
消耗率 = 1:若消耗率始終與基準錯誤率保持相等,我們就能精確達成 SLO 目標。
消耗率 < 1:若消耗率低於基準錯誤率,我們將有望超越 SLO 目標。
消耗率 > 1:若消耗率高於基準錯誤率,我們可能無法達成 SLO 目標。
當您建立 SLO 的消耗率時,也可以選擇同時建立 CloudWatch 警示,以監控消耗率。可以設定消耗率的閾值,如果消耗率指標超過設定的閾值,系統會自動向您傳送警示。例如,當消耗率逼近閾值時,這可能意味著 SLO 消耗錯誤預算的速度已超出團隊可承受的範圍,此時團隊可能需要減緩應用程式中的流失速度,以確保達成長期效能目標。
建立警示會產生費用。如需 CloudWatch 定價的詳細資訊,請參閱 Amazon CloudWatch 定價
計算消耗率
若要計算消耗率,必須指定回溯時段。回溯時段指用於測量錯誤率的持續時間。
burn rate = error rate over the look-back window / (100% - attainment goal)
注意
當沒有消耗率期間的資料時,Application Signals 會根據達成率計算消耗率。
錯誤率等於消耗率時段內,無效事件數目與事件總數的比率:
對於期間型 SLO,錯誤率等於無效期間數目除以期間總數。期間總數表示回溯時段內的期間數總和。
對於請求型 SLO,此為無效請求數除以請求總數量值。請求總數表示回溯時段內的請求數量。
回溯時段必須為 SLO 期間時間的倍數,且必須小於 SLO 間隔時間。
確定消耗率警示的適當閾值
當您設定消耗率警示時,需要為消耗率選擇一個值作為警示閾值。此閾值的值取決於 SLO 間隔時長和回溯時段,同時取決於您的團隊想要採用的方法或心理模型。確定閾值的方法主要有兩種。
方法 1:判斷您的團隊願意在回溯時段內消耗的預估總錯誤預算百分比。
若您想要在最後的消耗率回溯時段內,當預估錯誤預算的 X% 被消耗時觸發警報,則消耗率閾值如下:
burn rate threshold = X% * SLO interval length / look-back window size
例如,若在一個小時內消耗完 30 天 (720 小時) 錯誤預算的 5%,則消耗率需要達到 5% * 720 / 1 = 36。因此,如果消耗率回溯時段為 1 小時,我們會將消耗率閾值設定為 36。
可以在 CloudWatch 主控台中使用此方法建立消耗率警示。可以指定數字 X,並使用上述公式確定閾值。
SLO 間隔時長應根據 SLO 間隔類型判斷:
對於具有滾動間隔的 SLOs,它是間隔的長度,以小時為單位。
對於採用行事曆型間隔的 SLO:
如果單位為天或週,則為間隔的長度,以小時為單位。
若單位為月,則取 30 天作為預估時長,並將其轉換為小時。
方法 2:判斷下個間隔內預算耗盡所需的時間
如果在最近的回溯時段內,當前的錯誤率顯示預算耗盡前剩餘時間少於 X 小時 (假設目前剩餘預算為 100%),要觸發警報通知您,您可以使用下列公式來確定消耗率閾值。
burn rate threshold = SLO interval length / X
我們強調,上述公式中預算耗盡前剩餘時間 (X) 的計算,是基於目前剩餘總預算為 100% 的假設,因此未計入該間隔內已消耗的預算額度。我們也可以將其視為下一個間隔內預算耗盡所需的時間。
消耗率警示演練
舉例來說,我們來看一個具有 28 天滾動間隔的 SLO。要為此 SLO 設定消耗率警示,需要完成兩個步驟:
設定消耗率和回溯時段。
建立監控消耗率的 CloudWatch 警示。
若要開始使用,請確定在特定時間範圍內,服務願意消耗多少總錯誤預算。換句話說,請使用以下句子描述您的目標:「當我的總錯誤預算在 M 分鐘內消耗 X% 時,我希望收到警示通知。」
例如,您可能想要將目標設定為,總錯誤預算在 60 分鐘內消耗 2% 時收到提醒。
若要設定消耗率,請先定義回溯時段。回溯時段為 M,而在此範例中為 60 分鐘。
接著,建立 CloudWatch 警示。執行此操作時,必須指定消耗率的閾值。如果消耗率超過此閾值,警示會通知您。若要確定閾值,請使用下列公式:
burn rate threshold = X% * SLO interval length/ look-back window size
在此範例中,X 為 2,因為我們想要在錯誤預算 60 分鐘內消耗 2% 時收到提醒。間隔時長為 40,320 分鐘 (28 天),回溯時段是 60 分鐘,因此答案為:
burn rate threshold = 2% * 40,320 / 60 = 13.44.
在此範例中,您應將 13.44 設定為警示閾值。
多個涵蓋不同時段的警示
透過針對多個回溯時段設定警示,您不僅可以快速偵測到短時段內錯誤率突發性急遽攀升的狀況,也能察覺若未被及時發現便會逐漸耗盡錯誤預算的錯誤率小幅增長情形。
此外,您可以針對長時段的消耗率和短時段 (長時段的 1/12) 的消耗率設定複合警示,並且僅在兩個消耗率都超出閾值時收到通知。如此一來,就能確保僅在事件仍處於發生狀態時收到通知。如需 CloudWatch 複合警示的詳細資訊,請參閱建立複合警示。
注意
可以在建立消耗率時,為其設定指標警示。若要針對多個消耗率警示設定複合警示,必須依循 建立複合警示 中的說明執行。
Google 網站可靠性工程工作手冊
第一個複合警示:監控一對警示,一個時段涵蓋一小時,另一個時段涵蓋五分鐘。
第二個複合警示:監看一對警示,一個時段涵蓋六小時,另一個時段涵蓋 30 分鐘。
第三個複合警示:監看一對警示,一個時段涵蓋三天,另一個時段涵蓋六小時。
以下是設定步驟:
-
建立 5 個消耗率,時段分別為 5 分鐘、30 分鐘、1 小時、6 小時和 3 天。
建立以下三對 CloudWatch 警示。每對警示涵蓋一個長時段和一個短時段 (為長時段的 1/12),閾值依循 確定消耗率警示的適當閾值 中的步驟判斷。當您計算警示對中每個警示的閾值時,請使用警示對較長的回溯時段。
針對 1 小時和 5 分鐘消耗率的警示 (閾值為總預算的 2%)
針對 6 小時和 30 分鐘消耗率的警示 (閾值為總預算的 5%)
針對 3 天和 6 小時消耗率的警示 (閾值為總預算的 10%)
對於這些警示對,可建立複合警示,以便在兩個個別警報同時進入「警示」狀態時觸發通知。如需有關建立複合警示的詳細資訊,請參閱建立複合警示。
例如,如果第一個警示對的警示 (一小時時段和五分鐘時段) 命名為
OneHourBurnRate和FiveMinuteBurnRate,則 CloudWatch 複合警示規則為ALARM(OneHourBurnRate) AND ALARM(FiveMinuteBurnRate)
先前的策略可能僅適用於間隔時長至少為三小時的 SLO。對於間隔時長較短的 SLO,我們建議您從一對消耗率警示開始,其中一個警示的回溯時段為另一個警示回溯時段的 1/12。然後針對這個警示對設定複合警示。
建立 SLO
建議在關鍵應用程式中同時設定延遲和可用性 SLO。Application Signals 收集的這些指標符合共同的業務目標。
也可以在任何 CloudWatch 指標或產生單一時間序列的任何指標數學運算式中設定 SLO。
第一次在帳戶中建立 SLO 時,CloudWatch 會自動在帳戶中建立 AWSServiceRoleForCloudWatchApplicationSignals 服務連結角色 (若該角色尚不存在)。此服務連結角色可讓 CloudWatch 從您帳戶中的應用程式收集 CloudWatch 日誌資料、X-Ray 追蹤資料、CloudWatch 指標資料以及標記資料。如需有關建立 CloudWatch 服務連結角色的詳細資訊,請參閱對 CloudWatch 使用服務連結角色。
當您建立 SLO 時,可以指定是期間型 SLO 還是請求型 SLO。每種 SLO 有不同的方式來評估應用程式的效能是否實現其達成率目標。
期間型 SLO 使用指定總時間間隔內的定義時段。Application Signals 會針對每個時段,判斷應用程式是否達成其目標。達成率的計算方式為:
number of good periods/number of total periods。例如,對於期間型 SLO,實現 99.9% 的達成率目標表示在間隔內,應用程式必須在至少 99.9% 的時段內達成效能目標。
請求型 SLO 不使用預先定義的時段。相反,間隔內 SLO 的計算方式為:
number of good requests/number of total requests。在任何時刻,您都能找到截至指定時間戳記的間隔內,有效請求數與總請求數的比率,並將該比率與您在 SLO 中設定的目標值進行比對。
建立期間型 SLO
依循下列程序建立期間型 SLO。
建立期間型 SLO
透過 https://console.aws.amazon.com/cloudwatch/
開啟 CloudWatch 主控台。 在導覽窗格中,選擇服務水準目標 (SLO)。
選擇建立 SLO。
對於設定服務水準指標 (SLI),執行下列其中一項操作:
若要在服務操作、所有操作或服務相依性上設定 SLO,請使用標準應用程式指標
Latency或Availability:針對類型,選擇服務。
選取此 SLO 將監控的帳戶。
選取此 SLO 將監控的服務。
針對類型,選擇下列其中一項:
服務操作 — 在服務操作、所有操作或操作子集上建立 SLO。
服務相依性 — 在服務的相依性上建立 SLO。
如果您選擇服務操作,請選取此 SLO 將監控的操作。若要建立監控所有操作中服務整體運作狀態的服務層級 SLO,請選取所有操作。否則,選取要監控的特定操作。
若要建立監控操作子集的 SLO,請參閱 在多個操作上建立複合 SLO。
如果您選擇服務相依性,請執行下列動作:
在選取操作下,選取一個特定操作,或選取所有操作,以使用此服務呼叫相依性的所有操作中的指標。
在選取相依性下,搜尋並選取您要測量可靠性的必要相依性。
選取相依項之後,可以根據相依項檢視更新的圖形和歷史資料。
針對選取計算方法,選擇期間。
選取服務與選取操作下拉式清單由過去 24 小時內的作用中服務與操作所填入。
選擇可用性或延遲,然後設定閾值。
若要在任何 CloudWatch 指標或 CloudWatch 指標數學運算式中設定 SLO:
針對類型,選擇 CloudWatch 指標。
選擇選取 CloudWatch 指標。
選取指標畫面會出現。使用瀏覽或查詢索引標籤來查找所需的指標,或建立指標數學運算式。
選取想要的指標之後,請選擇圖形化指標索引標籤,然後選取要用於 SLO 的統計資料和週期。然後選擇 Select metric (選取指標)。
如需這些畫面的詳細資訊,請參閱 將指標圖形化 和 將數學運算式新增至 CloudWatch 圖形。
對於選取計算方法,選擇期間。
對於設定條件,請選取 SLO 的比較運算子和閾值,以用作成功指標。
如果您在步驟 4 中選取服務,請設定此 SLO 的期間長度。
輸入 SLO 的名稱。包括服務或操作的名稱,以及適當的關鍵字 (例如延遲或可用性),可協助您快速識別分類期間 SLO 狀態所指示的內容。
設定 SLO 的間隔和達成目標。如需有關間隔與達成目標及其如何同時運作的相關資訊,請參閱 SLO 概念。
(選用) 對於設定 SLO 消耗率,請執行下列動作:
設定消耗率的回溯時段時長 (以分鐘為單位)。有關如何選擇此時長的資訊,請參閱消耗率警示演練。
若要為此 SLO 建立更多消耗率,請選擇新增更多消耗率,並設定額外消耗率的回溯時段。
(選用) 執行下列動作來建立消耗率警示:
在設定消耗率警示下,選取要為其建立警示之各個消耗率的核取方塊。針對各個警示,執行下列動作:
指定警示進入「警示」狀態時用於通知的 Amazon SNS 主題。
可以設定消耗率閾值,或指定您在最後回溯時段內保持低於預估總預算消耗百分比的值。若您設定預估總預算消耗百分比,系統將自動計算消耗率閾值並將其用於警報。若要決定要設定的閾值,或了解此選項如何用於計算消耗率閾值,請參閱確定消耗率警示的適當閾值。
(選用) 為 SLO 設定一個或多個 CloudWatch 警示或警告閾值。
如果應用程式基於其 SLI 效能判定為運作狀態不佳,CloudWatch 警示會使用 Amazon SNS 主動通知您。
若要建立警示,請選取其中一個警示核取方塊,然後輸入或建立 Amazon SNS 主題,以便在警示進入
ALARM狀態時用於通知。如需 CloudWatch 警示的詳細資訊,請參閱 使用 Amazon CloudWatch 警示。建立警示會產生費用。如需 CloudWatch 定價的詳細資訊,請參閱 Amazon CloudWatch 定價。 如果設定警告閾值,它會出現在 Application Signals 畫面中,以協助您識別尚未實現的 SLO,即使它們目前運作良好。
若要設定警告閾值,請在警告閾值中輸入閾值。當 SLO 的錯誤預算低於警告閾值時,SLO 會在多個 Application Signals 畫面中標記為警告。警告閾值也會出現在錯誤預算圖表中。也可以建立基於警告閾值的 SLO 警告警示。
(選用) 對於設定 SLO 時段排除,請執行下列動作:
在排除時段下,設定要從 SLO 效能指標中排除的時段。
可以選擇設定時段並輸入每小時或每月的開始時段,亦可選擇使用 CRON 設定時段並輸入 CRON 表達式。
在重複選項下,設定此時段排除是否為週期性。
(選用) 在新增原因下,可以選擇輸入排除時段的原因。例如,排定的維護。
選取新增時段可新增最多 10 個排除時段。
若要將標籤新增至此 SLO,請選擇標籤索引標籤,然後選擇新增新標籤。標籤可協助您管理、識別、組織、搜尋及篩選資源。如需有關標記的詳細資訊,請參閱標記 AWS 資源。
注意
如果此 SLO 相關的應用程式已註冊 AWS Service Catalog AppRegistry,您可以使用
awsApplication標籤將此 SLO 與該 AppRegistry 中的應用程式建立關聯。如需詳細資訊,請參閱 AppRegistry 是什麼?選擇建立 SLO。如果也選擇建立一個或多個警示,按鈕名稱會變更以進行反映。
建立請求型 SLO
依循下列程序建立請求型 SLO。
建立請求型 SLO
透過 https://console.aws.amazon.com/cloudwatch/
開啟 CloudWatch 主控台。 在導覽窗格中,選擇服務水準目標 (SLO)。
選擇建立 SLO。
對於設定服務水準指標 (SLI),執行下列其中一項操作:
若要在服務操作、所有操作或服務相依性上設定 SLO,請使用標準應用程式指標
Latency或Availability:針對類型,選擇服務。
選取此 SLO 將監控的服務。
針對類型,選擇下列其中一項:
服務操作 — 在服務操作、所有操作或操作子集上建立 SLO。
服務相依性 — 在服務的相依性上建立 SLO。
如果您選擇服務操作,請選取此 SLO 將監控的操作。若要建立監控所有操作中服務整體運作狀態的服務層級 SLO,請選取所有操作。否則,選取要監控的特定操作。
若要建立監控操作子集的 SLO,請參閱 在多個操作上建立複合 SLO。
如果您選擇服務相依性,請執行下列動作:
在選取操作下,選取一個特定操作,或選取所有操作,以使用此服務呼叫相依性的所有操作中的指標。
在選取相依性下,搜尋並選取您要測量可靠性的必要相依性。
選取相依項之後,可以根據相依項檢視更新的圖形和歷史資料。
對於選取計算方法,選擇請求。
-
選取服務與選取操作下拉式清單由過去 24 小時內的作用中服務與操作所填入。
選擇可用性或延遲。如果選擇延遲,請設定閾值。
若要在任何 CloudWatch 指標或 CloudWatch 指標數學運算式中設定 SLO:
針對類型,選擇 CloudWatch 指標。
-
對於定義目標請求,請執行下列動作:
選擇您要衡量有效請求還是無效請求。
-
選擇選取 CloudWatch 指標。此指標將是目標請求數與請求總數之比值的分子。如果您使用延遲指標,請使用裁剪計數 (TC) 統計資料。如果閾值為 9 毫秒,並且您使用小於 (<) 比較運算子,則使用閾值 TC (:threshold - 1)。如需 CRR 的詳細資訊,請參閱語法。
選取指標畫面會出現。使用瀏覽或查詢索引標籤來查找所需的指標,或建立指標數學運算式。
-
對於定義請求總數,選擇您要用於來源的 CloudWatch 指標。此指標將是目標請求數與請求總數之比值的分母。
選取指標畫面會出現。使用瀏覽或查詢索引標籤來查找所需的指標,或建立指標數學運算式。
選取想要的指標之後,請選擇圖形化指標索引標籤,然後選取要用於 SLO 的統計資料和週期。然後選擇 Select metric (選取指標)。
如果您使用每個請求發出一個資料點的延遲指標,請使用計數統計資料範例來計算請求總數。
如需這些畫面的詳細資訊,請參閱 將指標圖形化 和 將數學運算式新增至 CloudWatch 圖形。
輸入 SLO 的名稱。包括服務或操作的名稱,以及適當的關鍵字 (例如延遲或可用性),可協助您快速識別分類期間 SLO 狀態所指示的內容。
設定 SLO 的間隔和達成目標。如需有關間隔與達成目標及其如何同時運作的相關資訊,請參閱 SLO 概念。
(選用) 對於設定 SLO 消耗率,請執行下列動作:
設定消耗率的回溯時段時長 (以分鐘為單位)。有關如何選擇此時長的資訊,請參閱消耗率警示演練。
若要為此 SLO 建立更多消耗率,請選擇新增更多消耗率,並設定額外消耗率的回溯時段。
(選用) 執行下列動作來建立消耗率警示:
在設定消耗率警示下,選取要為其建立警示之各個消耗率的核取方塊。針對各個警示,執行下列動作:
指定警示進入「警示」狀態時用於通知的 Amazon SNS 主題。
可以設定消耗率閾值,或指定您在最後回溯時段內保持低於預估總預算消耗百分比的值。若您設定預估總預算消耗百分比,系統將自動計算消耗率閾值並將其用於警報。若要決定要設定的閾值,或了解此選項如何用於計算消耗率閾值,請參閱確定消耗率警示的適當閾值。
(選用) 為 SLO 設定一個或多個 CloudWatch 警示或警告閾值。
如果應用程式基於其 SLI 效能判定為運作狀態不佳,CloudWatch 警示會使用 Amazon SNS 主動通知您。
若要建立警示,請選取其中一個警示核取方塊,然後輸入或建立 Amazon SNS 主題,以便在警示進入
ALARM狀態時用於通知。如需 CloudWatch 警示的詳細資訊,請參閱 使用 Amazon CloudWatch 警示。建立警示會產生費用。如需 CloudWatch 定價的詳細資訊,請參閱 Amazon CloudWatch 定價。 如果設定警告閾值,它會出現在 Application Signals 畫面中,以協助您識別尚未實現的 SLO,即使它們目前運作良好。
若要設定警告閾值,請在警告閾值中輸入閾值。當 SLO 的錯誤預算低於警告閾值時,SLO 會在多個 Application Signals 畫面中標記為警告。警告閾值也會出現在錯誤預算圖表中。也可以建立基於警告閾值的 SLO 警告警示。
(選用) 對於設定 SLO 時段排除,請執行下列動作:
在排除時段下,設定要從 SLO 效能指標中排除的時段。
可以選擇設定時段並輸入每小時或每月的開始時段,亦可選擇使用 CRON 設定時段並輸入 CRON 表達式。
在重複選項下,設定此時段排除是否為週期性。
(選用) 在新增原因下,可以選擇輸入排除時段的原因。例如,排定的維護。
選取新增時段可新增最多 10 個排除時段。
若要將標籤新增至此 SLO,請選擇標籤索引標籤,然後選擇新增新標籤。標籤可協助您管理、識別、組織、搜尋及篩選資源。如需有關標記的詳細資訊,請參閱標記 AWS 資源。
注意
如果此 SLO 相關的應用程式已註冊 AWS Service Catalog AppRegistry,您可以使用
awsApplication標籤將此 SLO 與該 AppRegistry 中的應用程式建立關聯。如需詳細資訊,請參閱 AppRegistry 是什麼?選擇建立 SLO。如果也選擇建立一個或多個警示,按鈕名稱會變更以進行反映。
在應用程式監視器上建立 SLO
您可以建立 SLOs來監控 CloudWatch RUM 應用程式監視器的效能。這可讓您追蹤實際使用者體驗指標,並確保您的 Web 和行動應用程式符合效能目標。應用程式監控SLOs 使用以請求為基礎的評估,測量良好請求與總請求的比率。
在應用程式監視器上建立 SLO
透過 https://console.aws.amazon.com/cloudwatch/
開啟 CloudWatch 主控台。 在導覽窗格中,選擇服務水準目標 (SLO)。
選擇建立 SLO。
針對設定服務層級指示器 (SLI),選擇 RUM AppMonitor。
從下拉式清單中選取此 SLO 將監控的應用程式監視器。此清單會顯示應用程式監控名稱以及支援的平台 (Web、iOS 或 Android)。
(選用) 選取要監控的特定頁面或畫面。如果您未選取頁面,SLO 會監控應用程式監視器的所有頁面。
針對選取指標,選擇要用於 SLI 的指標。可用的指標取決於平台:
對於 Web 應用程式:
PerformanceNavigationDuration、Http4xxCount、JSErrorCount和Http5xxCount對於行動應用程式 (iOS 和 Android):
ScreenLoadTime、Http4xxCount、CrashCount和Http5xxCount
對於設定條件,請選取 SLO 的比較運算子和閾值,以用作成功指標。
輸入 SLO 的名稱。包含應用程式監控名稱和適當的關鍵字,可協助您快速識別分類期間 SLO 狀態所指示的內容。
設定 SLO 的間隔和達成目標。如需詳細資訊,請參閱SLO 概念。
(選用) 視需要設定燒錄率和警示。如需詳細資訊,請參閱計算消耗率並選擇性地設定消耗率警示。
(選用) 視需要設定時間範圍排除。
(選用) 新增標籤以協助組織和識別此 SLO。
選擇建立 SLO。
在 Canary 上建立 SLO
您可以建立 SLOs來監控 CloudWatch Synthetics Canary 的效能。這可讓您追蹤合成監控結果,並確保您的端點和 APIs符合可用性和效能目標。Canary SLOs 使用以期間為基礎的評估,其中每個 Canary 執行都會視為離散評估期間。
在 Canary 上建立 SLO
透過 https://console.aws.amazon.com/cloudwatch/
開啟 CloudWatch 主控台。 在導覽窗格中,選擇服務水準目標 (SLO)。
選擇建立 SLO。
針對設定服務層級指示器 (SLI),選擇 Synthetics Canary。
從下拉式清單中選取此 SLO 將監控的 Canary。
針對選取指標,選擇
SuccessPercent或Duration:SuccessPercent會測量 Canary 成功執行的百分比Duration會測量每個 Canary 執行完成所需的時間
對於設定條件,請選取 SLO 的比較運算子和閾值,以用作成功指標。
輸入 SLO 的名稱。包含 Canary 名稱和適當的關鍵字可協助您快速識別分類期間 SLO 狀態所指示的內容。
設定 SLO 的間隔和達成目標。如需詳細資訊,請參閱SLO 概念。
(選用) 視需要設定燒錄率和警示。如需詳細資訊,請參閱計算消耗率並選擇性地設定消耗率警示。
(選用) 視需要設定時間範圍排除。
(選用) 新增標籤以協助組織和識別此 SLO。
選擇建立 SLO。
在多個操作上建立複合 SLO
您可以建立複合 SLO,以監控服務操作子集的Availability指標。當您想要一起追蹤一組相關操作的可靠性,而不是監控單一操作或所有操作時,這會很有用。
複合 SLOs支援以期間為基礎和以請求為基礎的評估。您可以選擇要包含的 2 到 20 個操作。選取操作的方式有兩種:
明確選擇 — 從下拉式清單中手動挑選個別操作。
模式比對 — 使用字首或規則表達式,依名稱自動比對操作。
注意
複合 SLOs僅支援 Availability 指標。Latency 指標不適用於複合 SLOs。
建立複合 SLO
透過 https://console.aws.amazon.com/cloudwatch/
開啟 CloudWatch 主控台。 在導覽窗格中,選擇服務水準目標 (SLO)。
選擇建立 SLO。
針對設定服務層級指示器 (SLI),針對類型,選擇服務。
選取此 SLO 將監控的服務。
針對類型,選擇服務操作。
選取要在此複合 SLO 中包含的操作。執行以下任意一項:
若要手動選取操作,請從操作下拉式清單中選擇多個操作。您可以選擇 2 到 20 個操作。
選取的操作會在下拉式清單下方顯示為字符。您可以透過選擇其字符上的關閉圖示來移除操作。
若要依模式選取操作,請選取使用模式比對核取方塊。然後執行下列動作:
針對模式類型,選擇字首或規則表達式。
字首會比對名稱開頭為您所輸入文字的所有操作。例如,輸入
Invoke符合名為InvokeFunction、InvokeAsync等的操作。規則表達式符合名稱符合您輸入的 regex 模式的所有操作。例如,輸入
^Invoke.*符合與字首範例相同的操作。
在模式欄位中輸入模式。主控台會在 欄位下方將相符的操作顯示為字符,以便您可以驗證結果。
選取操作之後,指標會自動設定為可用性。
針對選取計算方法,選擇期間或請求。
如果您選取期間,請設定此 SLO 的期間長度和可用性閾值。
輸入 SLO 的名稱,或使用自動產生的名稱。自動產生的名稱包含服務名稱和「複合」一詞,以協助您識別它。
設定 SLO 的間隔和達成目標。如需有關間隔與達成目標及其如何同時運作的相關資訊,請參閱 SLO 概念。
(選用) 視需要設定燒錄率和警示。如需詳細資訊,請參閱計算消耗率並選擇性地設定消耗率警示。
(選用) 為 SLO 設定一個或多個 CloudWatch 警示或警告閾值。
(選用) 視需要設定時間範圍排除。
(選用) 新增標籤以協助組織和識別此 SLO。
選擇建立 SLO。
使用 SLO 建議
Application Signals 可以根據過去 30 天的歷史指標資料,為您的 SLO 組態提供建議。當您提供有關服務和您要建立的 SLO 類型的基本資訊時,Application Signals 會分析指標資料,並建議指標閾值、SLO 目標和燒錄率時段的最佳值。
若要接收 SLO 建議,您必須提供下列資訊:
選擇服務操作或服務相依性:
針對服務操作,指定服務和操作
針對服務相依性,指定服務、操作 (或所有操作) 和相依性
SLO 評估類型:以期間為基礎或以請求為基礎
標準應用程式指標的類型:
Latency或Availability
根據此資訊和服務的歷史效能資料,Application Signals 建議下列 SLO 組態參數:
指標閾值 - SLI 的效能閾值,根據過去 30 天內服務的實際效能計算。
SLO 目標 - 符合您服務歷史可靠性的建議達成目標百分比。
燒錄速率時段 - 建議的回顧時段持續時間,用於監控您的服務使用其錯誤預算的速度。
您可以接受建議值,或根據您的特定業務需求進行調整。這些建議提供資料驅動的起點,用於設定反映服務實際效能特性的 SLOs。
檢視和分類 SLO 狀態
可以使用 CloudWatch 主控台中的服務水準目標或服務選項,快速查看 SLO 的運作狀態。服務檢視可一目了然地了解運作狀態不佳的服務比率,根據您所設定的 SLO 進行計算。如需有關使用服務選項的詳細資訊,請參閱 使用 Application Signals 監控應用程式的運作狀態。
服務水準目標檢視可宏觀了解您的組織。可總體上查看已實現和未實現的 SLO。根據您選擇的 SLI,這可讓您了解在較長時間內,有多少服務和操作符合您的期望。
若要使用「服務水準目標」檢視來檢視所有 SLO
-
透過 https://console.aws.amazon.com/cloudwatch/
開啟 CloudWatch 主控台。 在導覽窗格中,選擇服務水準目標 (SLO)。
服務水準目標 (SLO) 清單隨即出現。
可以在 SLI 狀態欄中快速查看 SLO 的目前狀態。若要排序 SLO,讓所有狀況不佳的 SLO 都位於清單頂端,請選擇 SLI 狀態欄,直到狀態不佳的 SLO 全部位於最上方。
SLO 資料表包含以下預設資料欄。可以選擇清單上方的齒輪圖示來調整要顯示的資料欄。如需有關目標、SLI、達成目標及間隔的詳細資訊,請參閱 SLO 概念。
SLO 的名稱。
目標資料欄會顯示每個間隔內必須順利達到 SLI 閾值才能實現 SLI 目標的週期百分比。它也會顯示 SLO 的間隔長度。
SLI 狀態會顯示應用程式目前的操作狀態是否正常。如果目前所選時間範圍內的任何週期對於 SLO 而言狀況不佳,則 SLI 狀態會顯示狀況不佳。
如果此 SLO 設定為監控相依項,相依項和遠端操作欄位會顯示該相依項關係的詳細資訊。
最終成就是指截至所選時間範圍結束時達到的成就水準。依此資料欄排序,查看最有可能無法實現的 SLO。
成就差異是所選時間範圍的開始與結束之間的成就水準差異。負差值表示指標呈下降趨勢。依此資料欄排序,查看 SLO 的最新趨勢。
結束錯誤預算 (%) 是指週期內可能有狀態不佳週期但仍可順利實現 SLO 的總時間百分比。如果將此值設定為 5%,且間隔中剩餘週期的 5% 或更少的 SLI 狀況不佳,則仍會成功實現 SLO。
錯誤預算差異是指所選時間範圍開始與結束之間的錯誤預算差異。負差值表示指標呈下降趨勢。
結束錯誤預算 (時間) 是指運作狀態不佳但仍可成功實現 SLO 的間隔中的實際時間量。例如,如果為 14 分鐘,則若 SLI 在剩餘間隔期間運作不佳的時間少於 14 分鐘,仍然可以成功實現 SLO。
-
結束錯誤預算 (請求) 是指運作狀態不佳但仍可成功實現 SLO 的間隔中的請求數。對於請求型 SLO,此值具有動態特性,會隨著累計請求總數隨時間變化而波動。
服務、操作和類型資料欄會顯示設定為此 SLO 之服務與操作的相關資訊。
若要查看 SLO 的達成與錯誤預算圖,請選擇 SLO 名稱旁的選項按鈕。
頁面頂端的圖形會顯示 SLO 達成與錯誤預算狀態。也會顯示與此 SLO 相關聯之 SLI 指標的圖形。
若要對未達成目標的 SLO 進一步分類,請選擇與該 SLO 關聯的服務名稱、操作名稱或相依項名稱。將轉至詳細資訊頁面,可以在其中進一步分類。如需詳細資訊,請參閱透過服務詳細資訊頁面檢視詳細的服務活動和操作狀態。
若要變更頁面中圖表和資料表的時間範圍,請選擇靠近畫面頂端的新時間範圍。
編輯現有 SLO
請依照下列步驟編輯現有 SLO。編輯 SLO 時,只能變更閾值、間隔、達成目標和標籤。若要變更其他方面 (例如服務、操作或指標),請建立新的 SLO,而非編輯現有 SLO。
變更 SLO 部分核心組態 (例如週期或閾值) 會使先前所有資料點以及有關達成效果與運作狀態的評估失效。它可有效刪除並重新建立 SLO。
注意
如果編輯 SLO,與該 SLO 相關聯的警示不會自動更新。可能需要更新警示,以使與 SLO 保持同步。
編輯現有 SLO
-
透過 https://console.aws.amazon.com/cloudwatch/
開啟 CloudWatch 主控台。 在導覽窗格中,選擇服務水準目標 (SLO)。
選擇您要編輯之 SLO 旁的選項按鈕,然後選擇動作 > 編輯 SLO。
進行變更,然後選擇儲存變更。
刪除 SLO
請依照下列步驟刪除現有 SLO。
注意
刪除 SLO 時,與該 SLO 相關聯的警示不會自動刪除。您需要自行將其刪除。如需詳細資訊,請參閱管理警示。
刪除 SLO
-
透過 https://console.aws.amazon.com/cloudwatch/
開啟 CloudWatch 主控台。 在導覽窗格中,選擇服務水準目標 (SLO)。
選擇您要編輯之 SLO 旁的選項按鈕,然後選擇動作 > 刪除 SLO。
選擇確認。
