# 流式传输数据解决方案:示例
## 场景 1:基于位置的互联网服务
*InternetProvider* 公司为世界各地的用户提供具有各种带宽选项的互联网服务。当用户注册互联网时,*InternetProvider* 公司会根据用户的地理位置为用户提供不同的带宽选项。鉴于这些要求,*InternetProvider* 公司实施了 Amazon Kinesis Data Streams 来使用用户详细信息和位置。在将用户详细信息和位置发布回应用程序之前,用不同的带宽选项丰富这些信息。[AWS Lambda](https://aws.amazon.com/lambda/) 支持这种实时丰富措施。
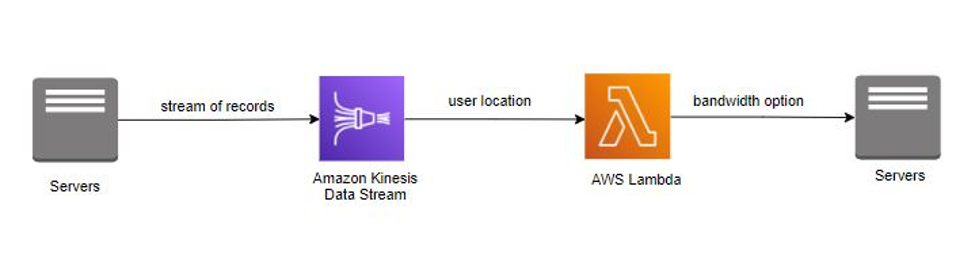
*使用 AWS Lambda 处理数据流*
### Amazon Kinesis Data Streams
借助 [Amazon Kinesis Data Streams](https://aws.amazon.com/kinesis/data-streams/),您可以使用常用的流式处理框架构建自定义的实时应用程序,并将流式传输数据加载到许多不同的数据存储中。一个 Kinesis 流可以配置为持续接收来自数十万个数据生成者的事件,这些数据生成者来自网站点击流、IoT 传感器、社交媒体源和应用程序日志等来源。几毫秒内,数据即可供应用程序进行读取和处理。
使用 Kinesis Data Streams 实施解决方案时,您可以创建称为 Kinesis Data Streams 应用程序的自定义数据处理应用程序。典型的 Kinesis Data Streams 应用程序将来自 Kinesis 流的数据作为数据记录读取。
确保放入 Kinesis Data Streams 的数据具有高可用性和弹性,几毫秒内即可使用。您可将来自数千个来源的点击流、应用程序日志和社交媒体等各种类型的数据持续添加到 Kinesis 流。在数秒内,[Kinesis 应用程序](https://www.amazonaws.cn/en/kinesis/data-streams/faqs/#kinesisapp)便可以从流中读取和处理数据。
Amazon Kinesis Data Streams 是一项完全托管的流式传输数据服务。它管理在数据吞吐量层面流式处理您的数据所需的基础设施、存储、联网和配置。
#### 将数据发送到 Amazon Kinesis Data Streams
可以通过多种方法将数据发送到 Kinesis Data Streams,从而为解决方案的设计提供灵活性。
+ 您可以利用多种常用语言支持的 [AWS 软件开发工具包](https://aws.amazon.com/tools/)之一来编写代码。
+ 您可以使用 [Amazon Kinesis 代理](https://docs.aws.amazon.com/streams/latest/dev/writing-with-agents.html),这是一款用于将数据发送到 Kinesis Data Streams 的工具。
[Amazon Kinesis Producer Library](https://docs.aws.amazon.com/streams/latest/dev/developing-producers-with-kpl.html) (KPL) 使开发人员能够对一个或多个 Kinesis 数据流实现较高的写入吞吐量,从而简化生成者应用程序的开发过程。
KPL 是一个易于使用、高度可配置的库,您可以将其安装在主机上。它在您的生成者应用程序代码和 Kinesis Streams API 操作之间充当中介。有关 KPL 及其以同步和异步方式生成事件的功能以及代码示例的更多信息,请参阅[使用 KPL 写入 Kinesis Data Streams](https://docs.aws.amazon.com/streams/latest/dev/kinesis-kpl-writing.html)
Kinesis Data Streams API 中有两个不同的操作可向流添加数据:`PutRecords` 和 `PutRecord`。`PutRecords` 操作对于每个 HTTP 请求向您的流发送多条记录,而 `PutRecord` 对于每个 HTTP 请求提交一条记录。要为大多数应用程序实现更高的吞吐量,请使用 `PutRecords`。
有关这些 API 的更多信息,请参阅[向流添加数据](https://docs.aws.amazon.com/streams/latest/dev/developing-producers-with-sdk.html#kinesis-using-sdk-java-add-data-to-stream)。每个 API 操作的详细信息可在 [Amazon Kinesis Data Streams API 参考](https://docs.aws.amazon.com/kinesis/latest/APIReference/Welcome.html)中找到。
#### 在 Amazon Kinesis Data Streams 中处理数据
要读取和处理来自 Kinesis 流的数据,您需要创建一个使用者应用程序。可以通过多种方法为 Kinesis Data Streams 创建使用者。其中一些方法包括使用 [Amazon Kinesis Data Analytics](https://aws.amazon.com/kinesis/data-analytics/),通过 KCL、[AWS Lambda](https://aws.amazon.com/lambda/)、[AWS Glue 流式处理 ETL 任务](https://docs.aws.amazon.com/glue/latest/dg/add-job-streaming.html)以及直接使用 Kinesis Data Streams API 来分析流数据。
可以使用 KCL 开发适用于 Kinesis Data Streams 的使用者应用程序,KCL 可以帮助您使用和处理来自 Kinesis Data Streams 的数据。KCL 负责许多与分布式计算相关的复杂任务,例如对多个实例实现负载均衡、对实例故障做出响应、对已处理的数据执行检查点操作以及对重新分片做出应对。KCL 可让您将精力放在编写记录处理逻辑方面。有关如何构建您自己的 KCL 应用程序的更多信息,请参阅[使用 Kinesis 客户端库](https://docs.aws.amazon.com/streams/latest/dev/shared-throughput-kcl-consumers.html)。
您可以订阅 Lambda 函数,以自动从您的 Kinesis 流中读取批量记录,并在流中检测到记录时对其进行处理。AWS Lambda 定期轮询流(每秒一次)以查找新记录,当它检测到新记录时,它会调用 Lambda 函数,同时将新记录作为参数传递。Lambda 函数仅在检测到新记录时才运行。您可以将 Lambda 函数映射到共享吞吐量使用者(标准迭代器)。
当您需要专用吞吐量而又不想与从流中接收数据的其他使用者争用时,可以构建使用[增强扇出](https://docs.aws.amazon.com/streams/latest/dev/enhanced-consumers.html)功能的使用者。利用此功能,使用者可以从流中接收记录,其数据吞吐量高达每分片 2 MB/秒。
在大多数情况下,应使用 Kinesis Data Analytics、KCL、AWS Glue 或 AWS Lambda 来处理流中的数据。但是,如果您愿意,可以使用 Kinesis Data Streams API 从头开始创建使用者应用程序。Kinesis Data Streams API 提供了用于从流检索数据的 `GetShardIterator` 和 `GetRecords` 方法。
在此拉取模型中,您的代码直接从流的分片中提取数据。有关使用 API 编写自己的使用者应用程序的更多信息,请参阅[使用适用于 Java 的 AWS 软件开发工具包开发具有共享吞吐量的自定义使用者](https://docs.aws.amazon.com/streams/latest/dev/developing-consumers-with-sdk.html)。有关此 API 的详细信息可在 [Amazon Kinesis Data Streams API 参考](https://docs.aws.amazon.com/kinesis/latest/APIReference/Welcome.html)中找到。
### 使用 AWS Lambda 处理数据流
[AWS Lambda](https://aws.amazon.com/lambda/faqs/) 使您无需预置或管理服务器即可运行代码。借助 Lambda,您可以为几乎任何类型的应用程序或后端服务运行代码,而且无需任何管理。您只需上载代码,Lambda 就会处理运行和扩展具有高度可用性的代码所需的一切工作。您可以将您的代码设置为自动从其他 AWS 服务触发,或者直接从任何 Web 或移动应用程序调用。
AWS Lambda 与 Amazon Kinesis Data Streams 原生集成。使用此原生集成时,将抽象化处理轮询操作、检查点操作以及错误处理的复杂性。这使得 Lambda 函数代码能够专注于业务逻辑处理。
您可以将 Lambda 函数映射到共享吞吐量使用者(标准迭代器)或具有增强扇出功能的专用吞吐量使用者。对于标准迭代器,Lambda 使用 HTTP 协议轮询 Kinesis 流中的每个分片以查找记录。为了最大限度地减少延迟并最大限度地提高读取吞吐量,您可以创建具有增强扇出功能的数据流使用者。此架构中的流使用者可以获得与每个分片的专用连接,而无需与从同一流中读取的其他应用程序竞争。Amazon Kinesis Data Streams 通过 HTTP/2 将记录推送到 Lambda。
原定设置情况下,只要流中有记录,AWS Lambda 就会调用您的函数。要为批处理场景缓冲记录,您可以在事件源处实施多达五分钟的批处理时段。如果您的函数返回一个错误,则 Lambda 将重试批处理,直到处理成功或数据过期。
### 总结
*InternetProvider* 公司已利用 Amazon Kinesis Data Streams 来流式传输用户详细信息和位置。AWS Lambda 使用记录流,通过存储在函数库中的带宽选项来丰富数据。丰富数据后,AWS Lambda 将带宽选项发布回应用程序。Amazon Kinesis Data Streams 和 AWS Lambda 负责服务器的预置和管理,使 *InternetProvider* 公司能够更加专注于业务应用程序开发。