本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
 存储
存储
AWS提供广泛的存储服务组合,具有用于存储、访问、保护和分析数据的深层功能。
示意图后面有每项服务的描述。为了帮助您决定哪种服务最能满足您的需求,请参阅选择AWS存储服务。有关一般信息,请参阅上的 “云存储” AWS
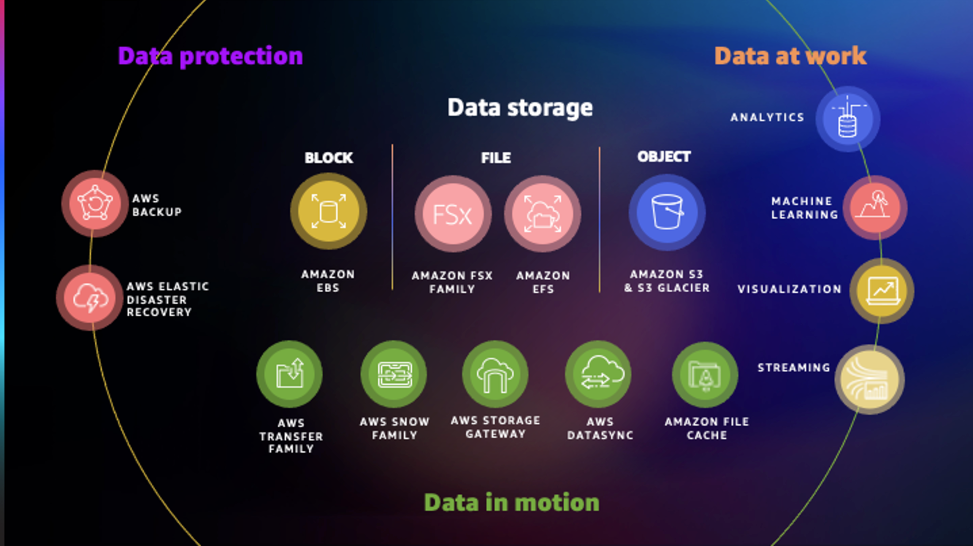
Services
返回 AWS 服务。
AWS Backup
AWS Backup
Amazon Elastic Block Store
Amazon Elastic Block Stor
AWS 弹性灾难恢复
AWS 弹性灾难恢复
在源服务器上设置弹性灾难恢复以启动安全的数据复制。您的数据将复制到您AWS 账户选择的中转区域子网AWS 区域中。您可以执行无中断测试以确认实施已完成。在正常操作期间,通过监控复制并定期执行无中断恢复和失效自动恢复演练,保持就绪状态。
如果您必须复制到AWS中国区域或执行复制和恢复AWS Outposts操作,请CloudEndure 使用中AWS Marketplace提供的灾难
Amazon Elastic File System
Amazon Elastic File System (Amazon EFS)
Amazon EFS 非常适合支持各种使用案例,从需要尽可能高的吞吐量的高度并行化、横向扩展的工作负载,到对延迟敏感的单线程工作负载,都包括在内。 lift-and-shift企业应用程序、大数据分析、Web 服务和内容管理、应用程序开发和测试、媒体和娱乐工作流程、数据库备份和容器存储等用例。
对于每年仅访问几次或次数更少的长期数据,可以考虑使用 Amazon EFS Archive 存储类,这是一种经济实惠的方式,能够保留甚至是最冷的数据,确保其始终可用,从而为新的业务见解提供支持。Amazon EFS Archive 存储类支持与现有 EFS 存储类相同的智能分层体验。这意味着,您可以同时拥有:频繁访问的活跃数据的 Amazon EFS 标准亚毫秒级 SSD 延迟,与较冷数据的 Amazon EFS IA 和 Amazon EFS Archive 存储类的较低成本。
Amazon File Cache
Amazon File
亚马逊 f FSx or Lustre
Amazon FSx for Lustre
Amazon for Lustre 与 Amazon S3 无缝集成,可以轻松地将您的长期数据集与高性能文件系统关联起来,从而运行计算密集型 FSx 工作负载。您可以自动将数据从 S3 复制到 Amazon f FSx or Lustre,运行您的工作负载,然后将结果写回 S3。Amazon FSx for Lustre 还允许您通过 Amazon Direct Connect 或 V AWS PN 访问 FSx 文件系统,从而将计算密集型工作负载从本地突发到本地。Amazon FSx for Lustre 可帮助您优化计算密集型工作负载的存储成本:它为处理数据提供廉价且高性能的非复制存储,并将您的长期数据持久存储在 Amazon S3 或其他低成本数据存储中。在 Amazon 上 FSx,您只需为使用的资源付费。没有最低承诺、预付硬件或软件费用或额外费用。
FSx 适用于 NetApp ONTAP 的亚马逊
Amazon FSx for NetApp ONTAP
Amazon FSx fo NetApp r ONTAP 提供高性能文件存储,可通过行业标准的 NFS、SMB 和 iSCSI 协议从 Linux、Windows 和 macOS 计算实例进行广泛访问。借助 Amazon FSx for NetApp ONTAP,您可以获得低成本、完全弹性的存储容量,并支持压缩和重复数据删除,从而帮助您进一步降低存储成本。可以使用AWS 管理控制台或 NetApp 云管理器部署和管理 Amazon FSx for NetApp ONTAP 文件系统,以实现无缝设置和管理。
FSx 适用于 OpenZFS 的亚马逊
Amazon FSx for OpenZFS
Amazon FSx for OpenZFS 提供了 OpenZFS 文件系统熟悉的特性、性能和功能,并具有完全托管服务的敏捷性、可扩展性和简单性。AWS
FSx 适用于 Windows 文件服务器的亚马逊
Amazon FSx for Windows File Server
借助 Amazon FSx,您可以启动高度耐用且可用的 Windows 文件系统,使用行业标准的 SMB 协议,可以从多达数千个计算实例访问这些系统。亚马逊 FSx 消除了管理 Windows 文件服务器的典型管理开销。您只需为使用的资源付费即可,没有预付费用、最低承诺或额外费用。
Amazon Simple Storage Service
Amazon Simple Storage Service
Amazon S3 存储类
S3 存储类包括:
-
S3 Intelligent-Tiering,可自动为未知或不断变化的访问模式的数据节省成本
-
S3 Standard,适用于经常访问的数据
-
S3 Express One Zone,适用于您最常访问的数据
-
S3 Standard-Infrequent Access(S3 Standard-IA)和 S3 One Zone-Infrequent Access(S3 One Zone-IA),适用于访问频率较低的数据
-
S3 Glacier Instant Retrieval,适用于需要立即访问的存档数据
-
S3 Glacier Flexible Retrieval(前身为 Amazon Glacier),适用于很少访问且不需要立即访问的长期数据
-
Amazon Glacier Deep Archive(Amazon Glacier Deep Archive),适用于长期存档和数字保留,可在数小时内完成检索,且云中存储成本极低
如果现有数据驻留要求无法满足AWS 区域,则可以使用 S3 Outpost s 存储类在本地存储 S3 数据。Amazon S3 还提供在整个生命周期中管理您数据的功能。设置好 S3 生命周期策略后,您的数据将自动传输到其他存储类,而无需对应用程序进行任何更改。有关更多信息,请参阅 Amazon S3 存储类概述信息图
您可以使用 S3 对象锁定,帮助您防止在固定的时间段内或无限期地删除或覆盖 S3 对象。Object Lock 可以帮助您满足需要 WORM (write-once-read-many) 存储的监管要求,或者干脆添加另一层保护,防止对象更改或删除。
AWS Storage Gateway
AWS Storage Gateway
返回 AWS 服务。
