本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
启用生成式通话摘要
注意
由 Amazon Bedrock 提供支持: AWS 实现自动滥用检测。由于生成式人工智能支持的通话后摘要是基于 Amazon Bedrock 构建的,因此,用户可以充分利用 Amazon Bedrock 中实施的控制措施以安全且负责任地使用人工智能 (AI)。
要在通话后分析作业中使用生成式通话摘要,请参阅以下示例:
在“摘要”面板中,启用生成式通话摘要以在输出中收到摘要。
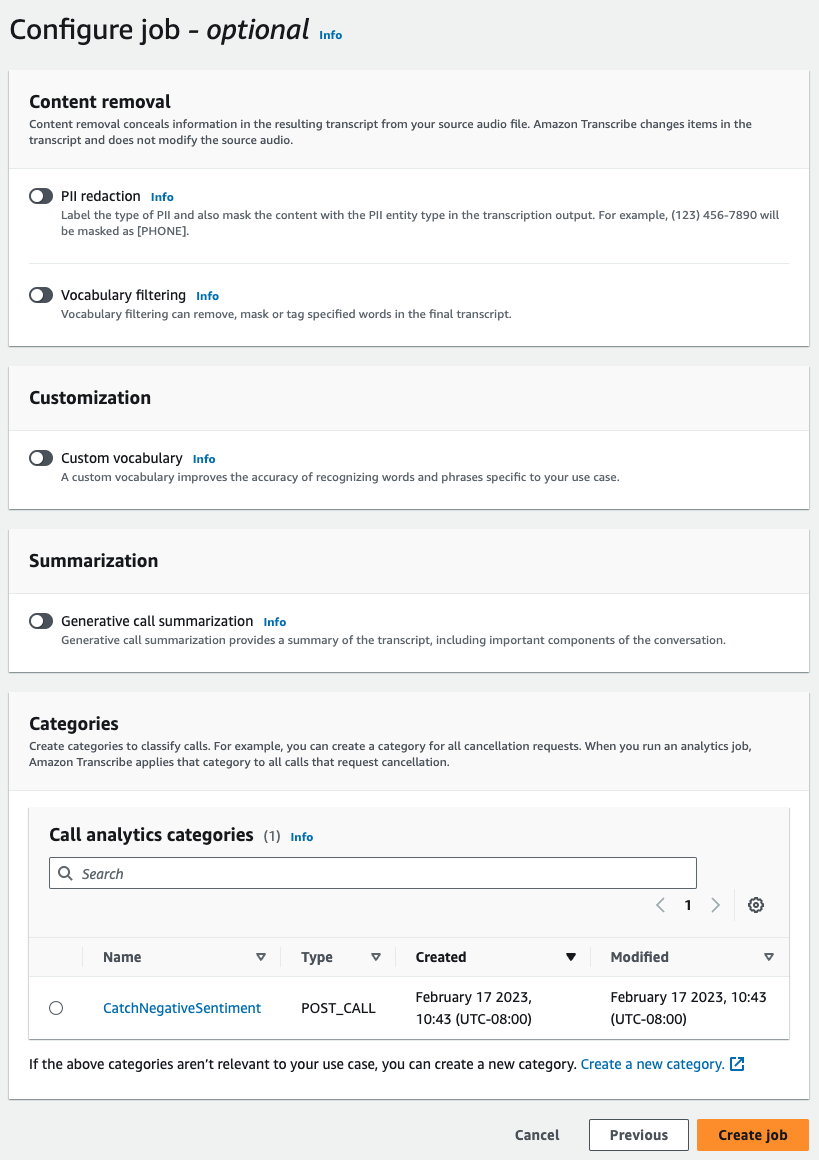
该示例使用 start-call-analytics-jobSettings 参数和 Summarization 子参数。有关更多信息,请参阅 StartCallAnalyticsJob。
aws transcribe start-call-analytics-job \ --regionus-west-2\ --call-analytics-job-namemy-first-call-analytics-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-locations3://amzn-s3-demo-bucket/my-output-files/\ --data-access-role-arnarn:aws:iam::111122223333:role/ExampleRole\ --channel-definitions ChannelId=0,ParticipantRole=AGENT ChannelId=1,ParticipantRole=CUSTOMER --settings '{"Summarization":{"GenerateAbstractiveSummary":true}}'
以下是另一个使用 start-call-analytics-job
aws transcribe start-call-analytics-job \ --regionus-west-2\ --cli-input-jsonfile://filepath/my-call-analytics-job.json
my-call-analytics-job.json 文件包含以下请求正文。
{ "CallAnalyticsJobName":"my-first-call-analytics-job", "DataAccessRoleArn":"arn:aws:iam::111122223333:role/ExampleRole", "Media": { "MediaFileUri":"s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac"}, "OutputLocation":"s3://amzn-s3-demo-bucket/my-output-files/", "ChannelDefinitions": [ { "ChannelId": 0, "ParticipantRole": "AGENT" }, { "ChannelId": 1, "ParticipantRole": "CUSTOMER" } ], "Settings": { "Summarization":{ "GenerateAbstractiveSummary": true } } }
此示例使用 start_call_analytics _job 方法启动StartCallAnalyticsJob。
有关使用 AWS 软件开发工具包的其他示例,包括特定功能、场景和跨服务示例,请参阅本章。使用 Amazon Transcribe 的代码示例 AWS 软件开发工具包
from __future__ import print_function from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe','us-west-2') job_name ="my-first-call-analytics-job"job_uri ="s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac"output_location ="s3://amzn-s3-demo-bucket/my-output-files/"data_access_role ="arn:aws:iam::111122223333:role/ExampleRole"transcribe.start_call_analytics_job( CallAnalyticsJobName = job_name, Media = { 'MediaFileUri': job_uri }, DataAccessRoleArn = data_access_role, OutputLocation = output_location, ChannelDefinitions = [ { 'ChannelId': 0, 'ParticipantRole': 'AGENT' }, { 'ChannelId': 1, 'ParticipantRole': 'CUSTOMER' } ], Settings = { "Summarization": { "GenerateAbstractiveSummary": true } } ) while True: status = transcribe.get_call_analytics_job(CallAnalyticsJobName = job_name) if status['CallAnalyticsJob']['CallAnalyticsJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
