要获得与亚马逊 Timestream 类似的功能 LiveAnalytics,可以考虑适用于 InfluxDB 的亚马逊 Timestream。适用于 InfluxDB 的 Amazon Timestream 提供简化的数据摄取和个位数毫秒级的查询响应时间,以实现实时分析。点击[此处](https://docs.aws.amazon.com//timestream/latest/developerguide/timestream-for-influxdb.html)了解更多信息。
本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
# UNLOAD 概念
## 语法
```
UNLOAD (SELECT statement)
TO 's3://bucket-name/folder'
WITH ( option = expression [, ...] )
```
其中 `option` 为
```
{ partitioned_by = ARRAY[ col_name[,…] ]
| format = [ '{ CSV | PARQUET }' ]
| compression = [ '{ GZIP | NONE }' ]
| encryption = [ '{ SSE_KMS | SSE_S3 }' ]
| kms_key = ''
| field_delimiter =''
| escaped_by = ''
| include_header = ['{true, false}']
| max_file_size = ''
| }
```
## 参数
SELECT 语句
用于从一个或多个 Timestream 中为 LiveAnalytics 表选择和检索数据的查询语句。
```
(SELECT column 1, column 2, column 3 from database.table
where measure_name = "ABC" and timestamp between ago (1d) and now() )
```
TO 子句
```
TO 's3://bucket-name/folder'
```
或者
```
TO 's3://access-point-alias/folder'
```
`UNLOAD` 语句中的 `TO` 子句指定查询结果输出的目的地。您需要提供完整路径,包括 Amazon S3 存储桶名称或 Amazon S3,以及在 Amazon S3 access-point-alias 上 LiveAnalytics写入输出文件对象的 Timestream 上的文件夹位置。S3 存储桶应由同一账户拥有,且位于同一区域。除了查询结果集之外,Timestream 还会将清单和元数据文件 LiveAnalytics 写入指定的目标文件夹。
PARTITIONED\_BY 子句
```
partitioned_by = ARRAY [col_name[,…] , (default: none)
```
`partitioned_by` 子句用于在查询中按粒度级别对数据进行分组与分析。将查询结果导出至 S3 存储桶时,可以选择根据选择查询中的一个或多个列对数据进行分区。在对数据进行分区时,导出的数据会根据分区列划分为多个子集,每个子集存储在独立的文件夹中。在包含导出数据的结果文件夹中,将自动创建子文件夹 `folder/results/partition column = partition value/`。但请注意,分区列不会包含在输出文件中。
`partitioned_by` 不是语法中的必选子句。如果选择不进行分区直接导出数据,可在语法中排除该子句。
**Example**
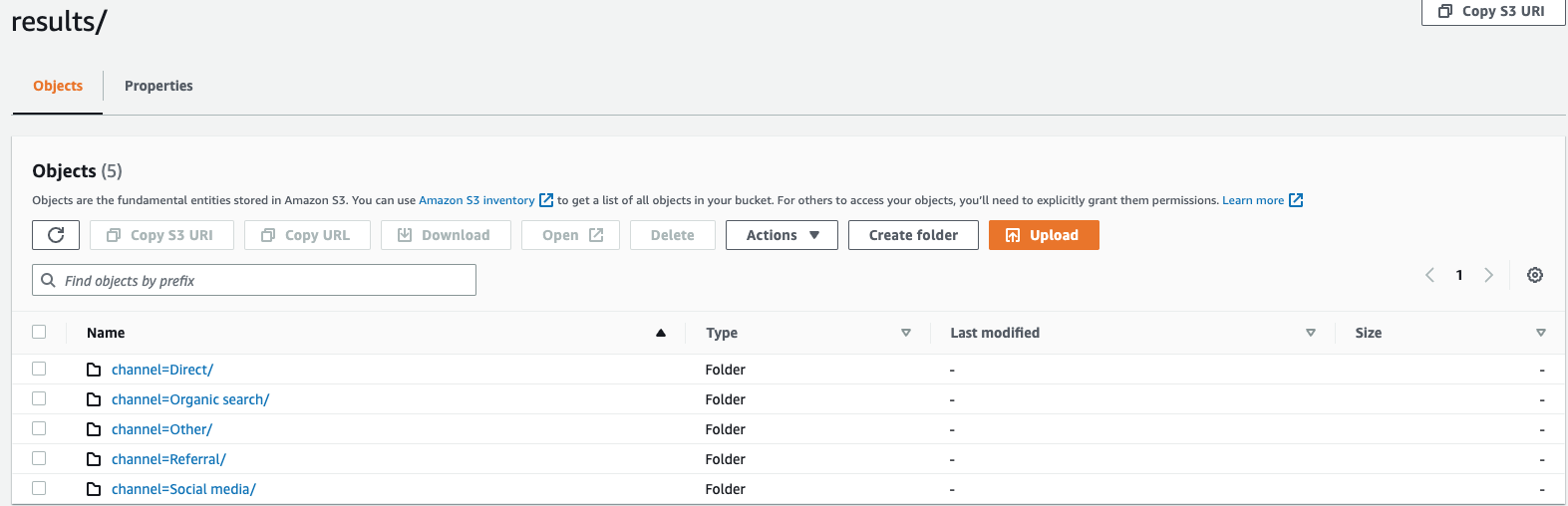
假设您正在监控网站的点击流数据,且有 5 个流量通道,即 `direct`、`Social Media`、`Organic Search`、`Other` 和 `Referral`。导出数据时,可选择使用列 `Channel` 对数据进行分区。在数据文件夹 `s3://bucketname/results` 中,您将包含五个分别以对应通道名称命名的文件夹,例如 `s3://bucketname/results/channel=Social Media/.`。在此文件夹中,您将找到所有通过 `Social Media` 通道访问您网站的客户数据。同样,您可为其余通道创建其他文件夹。
按通道列分区的导出数据
FORMAT
```
format = [ '{ CSV | PARQUET }' , default: CSV
```
用于指定写入 S3 存储桶的查询结果格式的关键字。您可以使用逗号(,)作为默认分隔符,将数据导出为逗号分隔值(CSV)格式,也可以导出为 Apache Parquet 格式(一种用于分析的高效开放列式存储格式)。
COMPRESSION
```
compression = [ '{ GZIP | NONE }' ], default: GZIP
```
您可以使用压缩算法 GZIP 对导出的数据进行压缩,也可以通过指定 `NONE` 选项将其解压缩。
ENCRYPTION
```
encryption = [ '{ SSE_KMS | SSE_S3 }' ], default: SSE_S3
```
Amazon S3 上的输出文件会使用您选择的加密选项进行加密。除数据以外,清单文件和元数据文件也会根据您选择的加密选项进行加密。我们目前支持 SSE\_S3 和 SSE\_KMS 加密。SSE\_S3 是一种服务器端加密,由 Amazon S3 使用 256 位高级加密标准(AES)加密对数据进行加密。SSE\_KMS 是一种服务器端加密,用于使用客户托管的密钥对数据进行加密。
KMS\_KEY
```
kms_key = ''
```
KMS 密钥是由客户定义的密钥,用于加密导出的查询结果。KMS 密钥由 AWS 密钥管理服务 (AWS KMS) 安全管理,用于加密 Amazon S3 上的数据文件。
FIELD\_DELIMITER
```
field_delimiter ='' , default: (,)
```
以 CSV 格式导出数据时,此字段指定用于在输出文件中分隔字段的单个 ASCII 字符,如管道字符(\|)、逗号(,)或制表符(/t)。CSV 文件的默认分隔符是逗号字符。如果数据中的某个值包含所选分隔符,则该分隔符将用引号字符进行引号处理。例如,如果数据中的值包含 `Time,stream`,则在导出数据中,该值将添加引号成为 `"Time,stream"`。Timestream 使用的引号字符 LiveAnalytics 是双引号 (“)。
如果要在 CSV 中包含标题,请避免将回车符(ASCII 13、十六进制 `0D`、文本 '\\r')或换行符(ASCII 10、十六进制 0A、文本 '\\n')指定为 `FIELD_DELIMITER`,否则将导致多数解析器无法正确解析最终 CSV 输出中的标题。
ESCAPED\_BY
```
escaped_by = '', default: (\)
```
以 CSV 格式导出数据时,此字段指定应在写入 S3 存储桶的数据文件中作为转义字符处理的字符。如果存在以下情形,可能会发生转义:
1. 如果值本身包含引号字符("),则将使用转义字符进行转义。例如,如果值为 `Time"stream`,其中(\\)是已配置的转义字符,则将其转义为 `Time\"stream`。
1. 如果该值包含已配置的转义字符,则将对其进行转义。例如,如果值为 `Time\stream`,则将其转义为 `Time\\stream`。
如果导出的输出包含数组、行或时间序列等复杂数据类型,则会将其序列化为 JSON 字符串。以下为示例。
[See the AWS documentation website for more details](http://docs.aws.amazon.com/zh_cn/timestream/latest/developerguide/export-unload-concepts.html)
INCLUDE\_HEADER
```
include_header = 'true' , default: 'false'
```
以 CSV 格式导出数据时,此字段允许您将列名作为导出 CSV 数据文件的首行。
可接受的值为“true”和“false”,默认值为“false”。`escaped_by` 和 `field_delimiter` 等文本转换选项同样适用于标题。
包含标题时,请避免使用回车符(ASCII 13、十六进制 0D、文本 '\\r')或换行符(ASCII 10、十六进制 0A、文本 '\\n')作为 `FIELD_DELIMITER`,否则将导致多数解析器无法正确解析最终 CSV 输出中的标题。
MAX\_FILE\_SIZE
```
max_file_size = 'X[MB|GB]' , default: '78GB'
```
此字段指定 `UNLOAD` 语句在 Amazon S3 中创建的文件最大大小。`UNLOAD` 语句可创建多个文件,但写入 Amazon S3 的每个文件最大大小将大致等于此字段中指定的值。
该字段的值必须在 16MB(含)和 78GB(含)之间。可以用整数(例如 `12GB`)或小数(例如 `0.5GB` 或 `24.7MB`)进行指定。默认值为 78 GB。
写入文件时,实际文件大小是近似值,因此实际最大大小可能不完全等于您指定的数字。
## 写入 S3 存储桶的内容是什么?
对于每个成功执行的 UNLOAD 查询,Timestream for 都会将您的查询结果、元数据文件和清单文件 LiveAnalytics 写入 S3 存储桶。如果已对数据进行分区,则结果文件夹中包含所有分区文件夹。清单文件包含由 UNLOAD 命令写入的文件列表。元数据文件包含描述写入数据特征、属性和特性的信息。
## 导出的文件名是什么?
导出的文件名包含两个组成部分,第一部分是 queryID,第二部分是唯一标识符。
CSV 文件
```
S3://bucket_name/results/_.csv
S3://bucket_name/results/=/_.csv
```
压缩的 CSV 文件
```
S3://bucket_name/results/=/_.gz
```
Parquet 文件
```
S3://bucket_name/results/=/_.parquet
```
元数据和清单文件
```
S3://bucket_name/__manifest.json
S3://bucket_name/__metadata.json
```
由于 CSV 格式的数据存储在文件级别,因此在导出至 S3 时压缩数据,该文件将带有“.gz”扩展名。然而,Parquet 中的数据在列级别进行压缩,因此即使在导出时对数据进行压缩,该文件仍会保留 .parquet 扩展名。
## 每个文件包含哪些信息?
### 清单文件
清单文件提供有关执行 UNLOAD 时导出的文件列表信息。清单文件可在提供的 S3 存储桶中找到,文件名为:`s3:///__manifest.json`。清单文件将包含结果文件夹中文件的 URL、相应文件的记录数和大小,以及查询元数据(即该查询导出至 S3 的总字节数和总行数)。
```
{
"result_files": [
{
"url":"s3://my_timestream_unloads/ec2_metrics/AEDAGANLHLBH4OLISD3CVOZZRWPX5GV2XCXRBKCVD554N6GWPWWXBP7LSG74V2Q_1448466917_szCL4YgVYzGXj2lS.gz",
"file_metadata":
{
"content_length_in_bytes": 32295,
"row_count": 10
}
},
{
"url":"s3://my_timestream_unloads/ec2_metrics/AEDAGANLHLBH4OLISD3CVOZZRWPX5GV2XCXRBKCVD554N6GWPWWXBP7LSG74V2Q_1448466917_szCL4YgVYzGXj2lS.gz",
"file_metadata":
{
"content_length_in_bytes": 62295,
"row_count": 20
}
},
],
"query_metadata":
{
"content_length_in_bytes": 94590,
"total_row_count": 30,
"result_format": "CSV",
"result_version": "Amazon Timestream version 1.0.0"
},
"author": {
"name": "Amazon Timestream",
"manifest_file_version": "1.0"
}
}
```
### 元数据
元数据文件提供有关数据集的其他信息,例如列名、列类型及架构。元数据文件位于提供的 S3 存储桶中,文件名为:S3://bucket\_name/\_\_metadata.json
以下是元数据文件的示例。
```
{
"ColumnInfo": [
{
"Name": "hostname",
"Type": {
"ScalarType": "VARCHAR"
}
},
{
"Name": "region",
"Type": {
"ScalarType": "VARCHAR"
}
},
{
"Name": "measure_name",
"Type": {
"ScalarType": "VARCHAR"
}
},
{
"Name": "cpu_utilization",
"Type": {
"TimeSeriesMeasureValueColumnInfo": {
"Type": {
"ScalarType": "DOUBLE"
}
}
}
}
],
"Author": {
"Name": "Amazon Timestream",
"MetadataFileVersion": "1.0"
}
}
```
元数据文件中共享的列信息与查询 API 响应中针对 `SELECT` 查询发送的 `ColumnInfo` 具有相同结构。
### 结果
结果文件夹包含以 Apache Parquet 或 CSV 格式导出的数据。
## 示例
当通过查询 API 提交如下所示的 `UNLOAD` 查询时,
```
UNLOAD(SELECT user_id, ip_address, event, session_id, measure_name, time, query, quantity, product_id, channel
FROM sample_clickstream.sample_shopping WHERE time BETWEEN ago(2d) AND now())
TO 's3://my_timestream_unloads/withoutpartition/' WITH ( format='CSV', compression='GZIP')
```
`UNLOAD` 查询响应将包含 1 行 \* 3 列。这 3 列包括:
+ BIGINT 类型的行:表示导出的行数
+ VARCHAR 类型的 metadataFile:所导出元数据文件的 S3 URI
+ VARCHAR 类型的 manifestFile:所导出清单文件的 S3 URI
您将从查询 API 获得以下响应:
```
{
"Rows": [
{
"Data": [
{
"ScalarValue": "20" # No of rows in output across all files
},
{
"ScalarValue": "s3://my_timestream_unloads/withoutpartition/AEDAAANGH3D7FYHOBQGQQMEAISCJ45B42OWWJMOT4N6RRJICZUA7R25VYVOHJIY__metadata.json" #Metadata file
},
{
"ScalarValue": "s3://my_timestream_unloads/withoutpartition/AEDAAANGH3D7FYHOBQGQQMEAISCJ45B42OWWJMOT4N6RRJICZUA7R25VYVOHJIY__manifest.json" #Manifest file
}
]
}
],
"ColumnInfo": [
{
"Name": "rows",
"Type": {
"ScalarType": "BIGINT"
}
},
{
"Name": "metadataFile",
"Type": {
"ScalarType": "VARCHAR"
}
},
{
"Name": "manifestFile",
"Type": {
"ScalarType": "VARCHAR"
}
}
],
"QueryId": "AEDAAANGH3D7FYHOBQGQQMEAISCJ45B42OWWJMOT4N6RRJICZUA7R25VYVOHJIY",
"QueryStatus": {
"ProgressPercentage": 100.0,
"CumulativeBytesScanned": 1000,
"CumulativeBytesMetered": 10000000
}
}
```
## 数据类型
该`UNLOAD`语句支持[支持的数据类型](supported-data-types.md)除和之外所述 LiveAnalytics的 Timestream 查询语言的所有数据类型`time`。`unknown`