本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
问题 RunBooks
下一节包含可能出现的问题、如何检测这些问题以及如何解决问题的建议。
安装问题
主题
........................
AWS CloudFormation 堆栈创建失败,并显示消息 “” WaitCondition 已收到失败消息。错误:状态。 TaskFailed”
要确定问题,请检查名为的 Amazon CloudWatch 日志组<stack-name>-InstallerTasksCreateTaskDefCreateContainerLogGroup<nonce>-<nonce>。如果有多个同名的日志组,请检查第一个可用的日志组。日志中的错误消息将提供有关该问题的更多信息。
注意
确认参数值中没有空格。
........................
成功创建 AWS CloudFormation 堆栈后未收到电子邮件通知
如果成功创建 AWS CloudFormation 堆栈后仍未收到电子邮件邀请,请验证以下内容:
-
确认电子邮件地址参数输入正确。
如果电子邮件地址不正确或无法访问,请删除并重新部署 Research and Engineering Studio 环境。
-
请查看 Amazon EC2 控制台以获取循环实例的证据。
如果有
<envname>前缀显示为已终止的 Amazon EC2 实例,然后被新实例替换,则网络或 Active Directory 配置可能存在问题。 -
如果您部署了 AWS 高性能计算配方来创建外部资源,请确认 VPC、私有子网和公有子网以及其他选定的参数是由堆栈创建的。
如果任何参数不正确,则可能需要删除并重新部署 RES 环境。有关更多信息,请参阅 卸载产品。
-
如果您使用自己的外部资源部署产品,请确认网络和 Active Directory 与预期配置相匹配。
确认基础设施实例成功加入 Active Directory 至关重要。请尝试中的步骤实例正在循环或 vdc 控制器处于故障状态来解决问题。
........................
实例正在循环或 vdc 控制器处于故障状态
此问题最可能的原因是资源无法连接或加入 Active Directory。
要验证问题,请执行以下操作:
-
在命令行中,在 vdc 控制器的运行实例上启动与 SSM 的会话。
-
运行
sudo su -。 -
运行
systemctl status sssd。
如果状态为非活动、失败或您在日志中看到错误,则说明该实例无法加入 Active Directory。
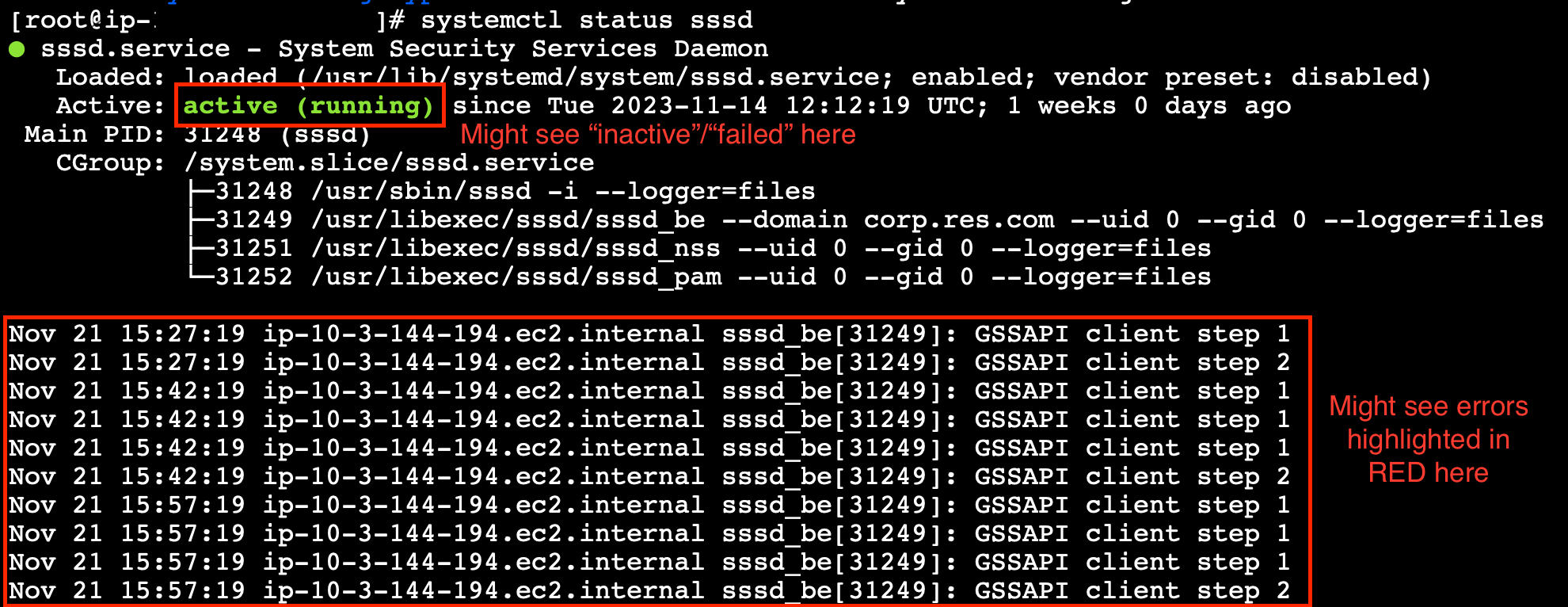
SSM 错误日志
要解决这个问题,请执行以下操作:
-
在同一个命令行实例中,运行
cat /root/bootstrap/logs/userdata.log以调查日志。
该问题可能有三个可能的根本原因之一。
查看日志。如果您多次看到以下内容重复,则说明该实例无法加入 Active Directory。
+ local AD_AUTHORIZATION_ENTRY= + [[ -z '' ]] + [[ 0 -le 180 ]] + local SLEEP_TIME=34 + log_info '(0 of 180) waiting for AD authorization, retrying in 34 seconds ...' ++ date '+%Y-%m-%d %H:%M:%S,%3N' + echo '[2024-01-16 22:02:19,802] [INFO] (0 of 180) waiting for AD authorization, retrying in 34 seconds ...' [2024-01-16 22:02:19,802] [INFO] (0 of 180) waiting for AD authorization, retrying in 34 seconds ... + sleep 34 + (( ATTEMPT_COUNT++ ))
-
验证在创建 RES 堆栈期间是否正确输入了以下各项的参数值。
-
directoryservice.ldap_connecti
-
目录服务.ldap_base
-
目录服务.users.ou
-
目录 service.groups.ou
-
directoryservice.sudoers
-
directoryservice.com
-
目录服务.name
-
-
更新 DynamoDB 表中的所有错误值。该表位于 DynamoDB 控制台的 “表” 下方。表名应为
<stack name>.cluster-settings -
更新表后,删除当前运行环境实例的集群管理器和 vdc-Controller。自动扩展将使用 DynamoDB 表中的最新值启动新实例。
如果返回日志Insufficient permissions to modify computer account,则堆栈创建期间输入的 ServiceAccount 名称可能不正确。
-
在 AWS 控制台中打开 Secrets Manager。
-
搜索
directoryserviceServiceAccountUsername。秘诀应该是<stack name>-directoryservice-ServiceAccountUsername -
打开密钥以查看详细信息页面。在 “机密值” 下,选择 “检索机密值”,然后选择 “纯文本”。
-
如果该值已更新,请删除环境中当前正在运行的集群管理器和 vdc-controller 实例。自动缩放将使用 Secrets Manager 中的最新值启动新实例。
如果显示日志Invalid credentials,则在创建堆栈时输入的 ServiceAccount 密码可能不正确。
-
在 AWS 控制台中打开 Secrets Manager。
-
搜索
directoryserviceServiceAccountPassword。秘诀应该是<stack name>-directoryservice-ServiceAccountPassword -
打开密钥以查看详细信息页面。在 “机密值” 下,选择 “检索机密值”,然后选择 “纯文本”。
-
如果您忘记了密码或者不确定输入的密码是否正确,则可以在 Active Directory 和 Secrets Manager 中重置密码。
-
要在中重置密码,请执行 AWS Managed Microsoft AD以下操作:
-
打开 AWS 控制台并转至 AWS Directory Service。
-
选择您的 RES 目录的目录 ID,然后选择操作。
-
选择重置用户密码。
-
输入 ServiceAccount 用户名。
-
输入新密码,然后选择重置密码。
-
-
要在 Secrets Manager 中重置密码,请执行以下操作:
-
打开 AWS 控制台并前往 Secrets Manager。
-
搜索
directoryserviceServiceAccountPassword。秘诀应该是<stack name>-directoryservice-ServiceAccountPassword -
打开密钥以查看详细信息页面。在 “机密值” 下,选择 “检索密钥值”,然后选择 “纯文本”。
-
选择编辑。
-
为 ServiceAccount 用户设置新密码,然后选择保存。
-
-
-
如果您更新了该值,请删除环境中当前正在运行的集群管理器和 vdc-controller 实例。Auto Scaling 将使用最新值启动新实例。
........................
由于依赖对象错误,无法删除环境 CloudFormation 堆栈
如果由于依赖对象错误(例如)而导致<env-name>-vdcvdcdcvhostsecuritygroup,则可能是由于使用控制台在 RES 创建的子网或安全组中启动了 Amazon EC2 实例。 AWS
要解决此问题,请查找并终止所有以这种方式启动的 Amazon EC2 实例。然后,您可以继续删除环境。
........................
创建环境时遇到 CIDR 块参数错误
创建环境时,CIDR 块参数会出现错误,响应状态为 [FAILED]。
错误示例:
Failed to update cluster prefix list: An error occurred (InvalidParameterValue) when calling the ModifyManagedPrefixList operation: The specified CIDR (52.94.133.132/24) is not valid. For example, specify a CIDR in the following form: 10.0.0.0/16.
为了解决这个问题,预期的格式是 x.x.0/24 或 x.x.0/32。
........................
CloudFormation 创建环境期间堆栈创建失败
创建环境涉及一系列资源创建操作。在某些区域,可能会出现容量问题,从而导致 CloudFormation 堆栈创建失败。
如果出现这种情况,请删除环境并重试创建。或者,您可以在其他区域重试创建。
........................
创建外部资源(演示)堆栈失败,并显示 AdDomainAdminNode CREATE_FAILED
如果演示环境堆栈创建失败并出现以下错误,则可能是由于 Amazon 在实例启动后的配置过程中意外进行了 EC2 修补。
AdDomainAdminNode CREATE_FAILED Failed to receive 1 resource signal(s) within the specified duration
要确定失败原因,请执行以下操作:
-
在 SSM 状态管理器中,检查是否已配置修补以及是否为所有实例配置了修补程序。
-
在 SSM RunCommand/Automation 执行历史记录中,检查与补丁相关的 SSM 文档的执行是否与实例启动相吻合。
-
在环境的 Amazon EC2 实例的日志文件中,查看本地实例日志以确定实例在配置期间是否重新启动。
如果问题是由修补引起的,请在启动后至少 15 分钟延迟 RES 实例的修补。
........................
身份管理问题
单点登录 (SSO) 和身份管理方面的大多数问题都是由于配置错误造成的。有关设置 SSO 配置的信息,请参阅:
要解决与身份管理相关的其他问题,请参阅以下疑难解答主题:
主题
........................
我无权执行 iam:PassRole
如果您收到错误消息,提示您无权执行 iam: PassRole 操作,则必须更新您的策略以允许您将角色传递给 RES。
某些 AWS 服务允许您将现有角色传递给该服务,而不是创建新的服务角色或服务相关角色。为此,您必须具有将角色传递到服务的权限。
当名为 marymajor 的 IAM 用户尝试使用控制台在 RES 中执行操作时,会出现以下示例错误。但是,服务必须具有服务角色所授予的权限才可执行此操作。Mary 不具有将角色传递到服务的权限。
User: arn:aws:iam::123456789012:user/marymajor is not authorized to perform: iam:PassRole
在这种情况下,必须更新 Mary 的政策以允许她执行 iam: PassRole 操作。如果您需要帮助,请联系您的 AWS 管理员。您的管理员是提供登录凭证的人。
........................
我想允许 AWS 账户以外的人通过 AWS 资源访问我的研究与工程工作室
您可以创建一个角色,以便其他账户中的用户或您组织外的人员可以使用该角色来访问您的资源。您可以指定谁值得信赖,可以代入角色。对于支持基于资源的策略或访问控制列表 (ACLs) 的服务,您可以使用这些策略向人们授予访问您的资源的权限。
要了解更多信息,请参阅以下内容:
-
要了解如何通过您拥有的 AWS 账户提供对资源的访问权限,请参阅 IAM 用户指南中的向您拥有的另一个 AWS 账户中的 IAM 用户提供访问权限。
-
要了解如何向第三方 AWS 账户提供对您的资源的访问权限,请参阅 IAM 用户指南中的向第三方 AWS 账户提供访问权限。
-
要了解如何通过联合身份验证提供访问权限,请参阅 IAM 用户指南中的向经过外部身份验证的用户提供访问权限(联合身份验证)。
-
要了解使用角色和基于资源的策略进行跨账户访问的区别,请参阅 IAM 用户指南中的 IAM 角色与基于资源的策略有何不同。
........................
登录环境后,我会立即返回登录页面
当您的 SSO 集成配置错误时,就会出现此问题。要确定问题所在,请检查控制器实例日志并查看配置设置中是否存在错误。
要查看日志,请执行以下操作:
-
打开 CloudWatch 管理控制台
。 -
在日志组中,找到名为的组
/。<environment-name>/cluster-manager -
打开日志组以搜索日志流中的任何错误。
要检查配置设置,请执行以下操作:
-
打开 DynamoDB 控制台
-
在表中,找到名为的表
<environment-name>.cluster-settings -
打开表格并选择 “浏览表格项目”。
-
展开筛选器部分,然后输入以下变量:
-
属性名称-关键
-
状况-包含
-
价值 — sso
-
-
选择运行。
-
在返回的字符串中,验证 SSO 配置值是否正确。如果它们不正确,请将 sso_enabled 密钥的值更改为 False。
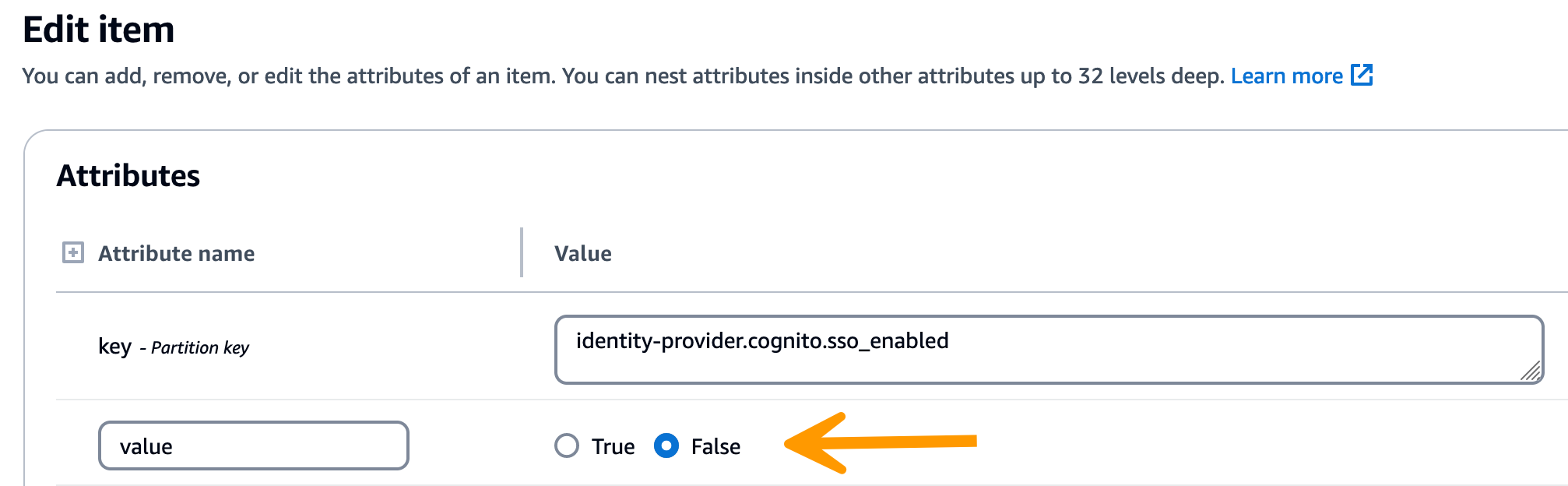
-
返回 RES 用户界面重新配置 SSO。
........................
尝试登录时出现 “未找到用户” 错误
如果用户在尝试登录 RES 界面时收到 “未找到用户” 错误,并且该用户出现在 Active Directory 中:
-
如果 RES 中没有该用户,而您最近已将该用户添加到 AD
-
用户可能尚未同步到 RES。RES 每小时同步一次,因此您可能需要等待并检查用户是否已在下次同步后添加。要立即同步,请按照中的步骤操作已将用户添加到 Active Directory 中,但在。
-
-
如果用户出现在 RES 中:
-
确保属性映射配置正确。有关更多信息,请参阅 为单点登录 (SSO) 配置您的身份提供商。
-
确保 SAML 主题和 SAML 电子邮件都映射到用户的电子邮件地址。
-
........................
已将用户添加到 Active Directory 中,但在
如果您已将用户添加到 Active Directory,但在 RES 中却缺少该用户,则需要触发广告同步。AD 同步由 Lambda 函数每小时执行一次,该函数将 AD 条目导入 RES 环境。有时,在添加新用户或群组后,下一个同步过程会有延迟。您可以通过 Amazon 简单队列服务手动启动同步。
手动启动同步过程:
-
打开 Amazon SQS 控制台
。 -
从 “队列” 中选择
<environment-name>-cluster-manager-tasks.fifo。 -
选择 “发送和接收消息”。
-
在邮件正文中,输入:
{ "name": "adsync.sync-from-ad", "payload": {} } -
在消息组 ID 中,输入:
adsync.sync-from-ad -
在消息重复数据删除 ID 中,输入一个随机的字母数字字符串。此条目必须不同于前五分钟内拨打的所有电话,否则该请求将被忽略。
........................
创建会话时用户不可用
如果您是管理员,正在创建会话,但在创建会话时发现 Active Directory 中的用户不可用,则该用户可能需要首次登录。只能为活跃用户创建会话。活跃用户必须至少登录环境一次。
........................
CloudWatch 集群管理器日志中出现超出大小限制错误
2023-10-31T18:03:12.942-07:00 ldap.SIZELIMIT_EXCEEDED: {'msgtype': 100, 'msgid': 11, 'result': 4, 'desc': 'Size limit exceeded', 'ctrls': []}
如果您在 CloudWatch 集群管理器日志中收到此错误,那么 ldap 搜索可能返回了太多的用户记录。要解决此问题,请提高您的 IDP 的 ldap 搜索结果限制。
........................
存储
主题
........................
我通过 RES 创建了文件系统,但它没有挂载到 VDI 主机上
文件系统必须处于 “可用” 状态,然后才能由 VDI 主机装载。按照以下步骤验证文件系统是否处于所需状态。
Amazon EFS
-
前往 Amazon EFS 控制台
。 -
检查文件系统状态是否为 “可用”。
-
如果文件系统状态为 “不可用”,请等待,然后再启动 VDI 主机。
-
前往 Amazon FSx 控制台
。 -
检查状态是否为可用。
-
如果 “状态” 为 “不可用”,请等待,然后再启动 VDI 主机。
........................
我通过 RES 加载了一个文件系统,但它没有安装到 VDI 主机上
RES 上载入的文件系统应配置所需的安全组规则,以允许 VDI 主机挂载文件系统。由于这些文件系统是在 RES 外部创建的,因此 RES 不管理相关的安全组规则。
与已载入文件系统关联的安全组应允许以下入站流量:
来自 linux VDC 主机的 NFS 流量(端口:2049)
来自 Windows VDC 主机的中小型企业流量(端口:445)
........................
我无法从 VDI 主机 read/write 上打开
ONTAP 支持卷的 UNIX、NTFS 和混合安全风格。安全风格决定了 ONTAP 用于控制数据访问的权限类型以及可以修改这些权限的客户端类型。
例如,如果卷使用 UNIX 安全风格,则由于 ONTAP 的多协议性质,SMB 客户端仍然可以访问数据(前提是它们必须正确进行身份验证和授权)。但是,ONTAP 使用 UNIX 权限,只有 UNIX 客户端才能使用本机工具修改这些权限。
权限处理用例示例
对 Linux 工作负载使用 UNIX 风格的
sudoer 可以为其他用户配置权限。例如,以下内容将授予所有成员对该/<project-name>目录的<group-ID>完全 read/write 权限:
sudo chown root:<group-ID>/<project-name>sudo chmod 770 /<project-name>
在 Linux 和 Windows 工作负载中使用 NTFS 风格的音量
可以使用特定文件夹的共享属性来配置共享权限。例如,给定一个用户user_01和一个文件夹myfolder,你可以将Full ControlChange、或的权限设置Read为Allow或Deny:
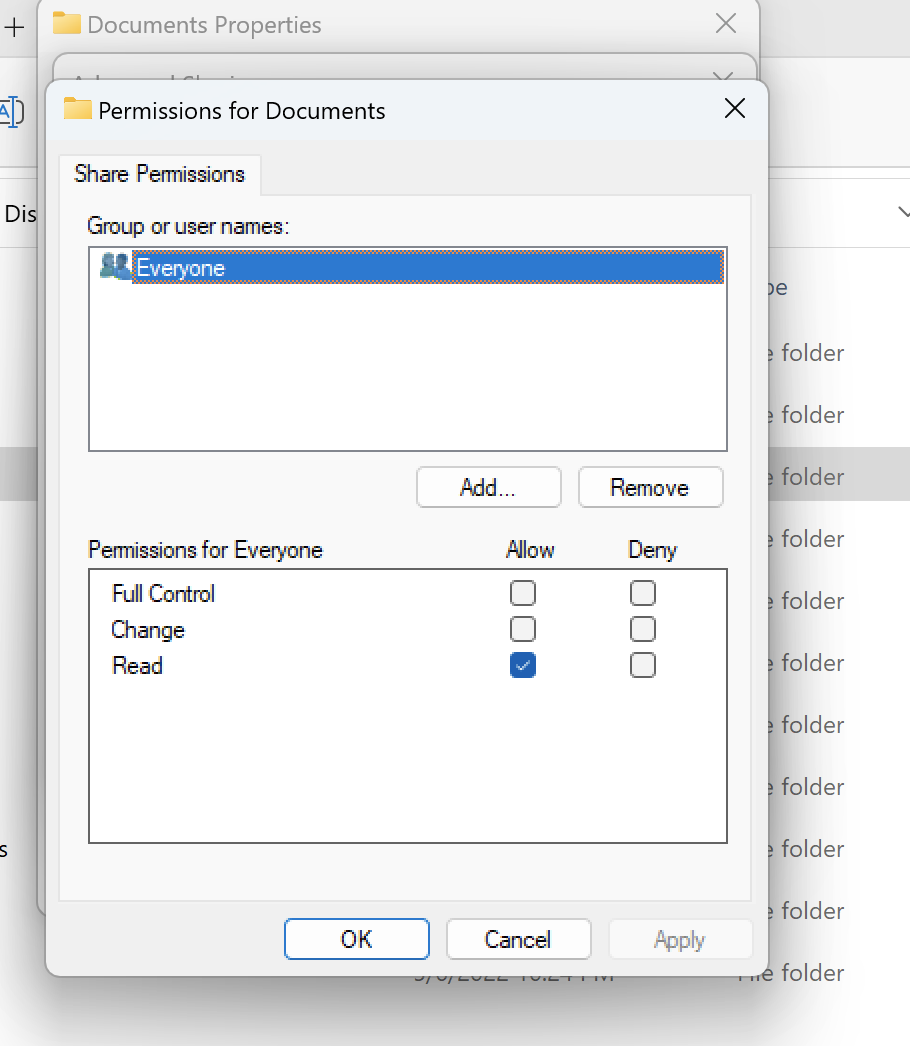
如果 Linux 和 Windows 客户端都要使用该卷,我们需要在 SVM 上设置名称映射,将任何 Linux 用户名与相同用户名与域\ 用户名的 NetBIOS 域名格式相关联。这是在 Linux 和 Windows 用户之间进行转换所必需的。有关参考,请参阅使用 Amazon for NetApp ONTAP 启用多协议工作负载 FSx 。
........................
我从 RES 创建了 Amazon FSx for NetApp ONTAP 但它没有加入我的域名
当前,当您从 RES 控制台创建 Amazon FSx for NetApp ONTAP 时,文件系统已配置但不会加入域。要将创建的 ONTAP 文件系统 SVM 加入您的域,请参阅加入 SVMs Microsoft Active Directory 并按照亚马逊 FSx
加入域后,在集群设置 DynamoDB 表中编辑 SMB DNS 配置密钥:
-
选择 “表”,然后选择
<stack-name>-cluster-settings。 -
在 “浏览表格项目” 下,展开 “筛选器”,然后输入以下筛选器:
属性名称-密钥
条件-等于
-
价值-
shared-storage.<file-system-name>.fsx_netapp_ontap.svm.smb_dns
-
选择退回的商品,然后选择操作、编辑项目。
-
使用您之前复制的 SMB DNS 名称更新该值。
-
选择 “保存并关闭”。
此外,确保与文件系统关联的安全组按照 Amazon VPC 的文件系统访问控制中的建议允许流量。使用文件系统的新 VDI 主机现在可以挂载已加入的 SVM 和文件系统的域。
或者,您可以使用 RES Onboard File System 功能加载已加入域的现有文件系统——从 “环境管理” 中选择 “文件系统”、“板载文件系统”。
........................
快照
........................
快照的状态为 “失败”
在 RES 快照页面上,如果快照的状态为 “失败”,则可以通过前往集群管理器的 Amazon CloudWatch 日志组中查看错误发生时间来确定原因。
[2023-11-19 03:39:20,208] [INFO] [snapshots-service] creating snapshot in S3 Bucket: asdf at path s31 [2023-11-19 03:39:20,381] [ERROR] [snapshots-service] An error occurred while creating the snapshot: An error occurred (TableNotFoundException) when calling the UpdateContinuousBackups operation: Table not found: res-demo.accounts.sequence-config
........................
快照应用失败,日志显示无法导入表。
如果从先前环境中拍摄的快照无法应用于新环境,请查看集群管理器的 CloudWatch 日志以确定问题。如果问题提到无法导入所需的表,请验证快照是否处于有效状态。
-
下载 metadata.json 文件并验证各个表的状态是否 ExportStatus 为 “已完成”。确保各个表都设置了
ExportManifest字段。如果未找到上述字段集,则快照处于无效状态,无法与应用快照功能一起使用。 -
启动快照创建后,请确保快照状态在 RES 中变为 “已完成”。快照创建过程最多需要 5 到 10 分钟。重新加载或重新访问 “快照管理” 页面,以确保成功创建快照。这将确保创建的快照处于有效状态。
........................
基础设施
........................
负载均衡器目标群组没有运行正常的实例
如果用户界面中出现服务器错误消息或桌面会话无法连接等问题,则可能表示基础设施 Amazon EC2 实例存在问题。
确定问题根源的方法是,首先检查亚马逊 EC2 控制台中是否存在任何似乎反复终止并被新 EC2 实例取代的亚马逊实例。如果是这样的话,查看 Amazon CloudWatch 日志可能会确定原因。
另一种方法是检查系统中的负载均衡器。如果在 Amazon EC2 控制台上找到的任何负载均衡器未显示任何已注册的运行正常的实例,则表明可能存在系统问题。
此处显示了正常外观的示例:
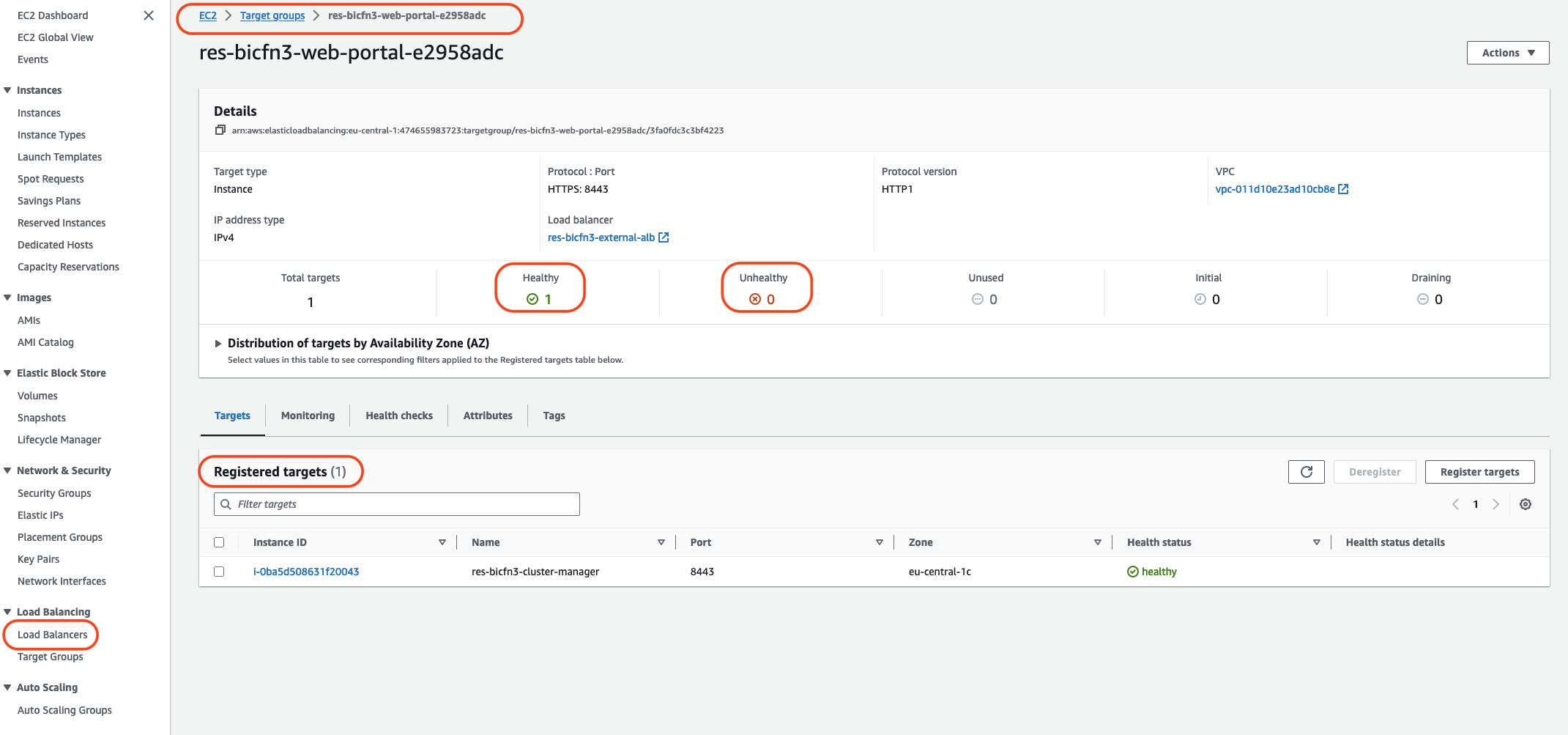
如果 “正常” 条目为 0,则表示没有 Amazon EC2 实例可用于处理请求。
如果 Unhealthy 条目不是 0,则表示 Amazon EC2 实例可能正在循环。这可能是由于安装的应用程序软件未通过运行状况检查所致。
如果 “正常” 和 “不健康” 条目均为 0,则表示可能存在网络配置错误。例如,公有子网和私有子网可能没有对应 AZs的子网。如果出现这种情况,则控制台上可能会有其他文本表明存在网络状态。
........................
启动虚拟桌面
........................
以前运行的虚拟桌面无法再成功连接
如果桌面连接关闭或您无法再连接到该连接,则问题可能是由于底层 Amazon EC2 实例出现故障,或者 Amazon EC2 实例可能已在 RES 环境之外终止或停止。管理界面状态可能会继续显示就绪状态,但尝试连接失败。
应使用 Amazon EC2 控制台来确定实例是否已终止或停止。如果已停止,请尝试重新启动。如果状态终止,则必须创建另一个桌面。当新实例启动时,存储在用户主目录中的任何数据都应该仍然可用。
如果之前失败的实例仍显示在管理界面上,则可能需要使用管理界面将其终止。
........................
我只能启动 5 个虚拟桌面
用户可以启动的虚拟桌面数量的默认限制为 5。管理员可以使用管理界面进行更改,如下所示:
前往 “桌面设置”。
选择 “服务器” 选项卡。
在 DCV 会话面板中,单击右侧的编辑图标。
将 “每位用户允许的会话数” 中的值更改为所需的新值。
选择提交。
刷新页面以确认新设置已到位。
........................
桌面 Windows 连接尝试失败,并显示 “连接已关闭”。传输错误”
如果 Windows 桌面连接失败并显示界面错误 “连接已关闭。传输错误”,原因可能是由于在 Windows 实例上创建证书的 DCV 服务器软件存在问题。
Amazon CloudWatch 日志组<envname>/vdc/dcv-connection-gateway可能会使用类似以下内容的消息记录连接尝试错误:
Nov 24 20:24:27.631 DEBUG HTTP:Splicer Connection{id=9}: Websocket{session_id="1291e75f-7816-48d9-bbb2-7371b3b911cd"}: Resolver lookup{client_ip=Some(52.94.36.19) session_id="1291e75f-7816-48d9-bbb2-7371b3b911cd" protocol_type=WebSocket extension_data=None}:NoStrictCertVerification: Additional stack certificate (0): [s/n: 0E9E9C4DE7194B37687DC4D2C0F5E94AF0DD57E] Nov 24 20:25:15.384 INFO HTTP:Splicer Connection{id=21}:Websocket{ session_id="d1d35954-f29d-4b3f-8c23-6a53303ebc3f"}: Connection initiated error: unreachable, server io error Custom { kind: InvalidData, error: General("Invalid certificate: certificate has expired (code: 10)") } Nov 24 20:25:15.384 WARN HTTP:Splicer Connection{id=21}: Websocket{session_id="d1d35954-f29d-4b3f-8c23-6a53303ebc3f"}: Error in websocket connection: Server unreachable: Server error: IO error: unexpected error: Invalid certificate: certificate has expired (code: 10)
如果发生这种情况,解决方案可能是使用 SSM 会话管理器打开与 Windows 实例的连接并删除以下 2 个与证书相关的文件:
PS C:\Windows\system32\config\systemprofile\AppData\Local\NICE\dcv> dir Directory: C:\Windows\system32\config\systemprofile\AppData\Local\NICE\dcv Mode LastWriteTime Length Name ---- ------------- ------ ---- -a---- 8/4/2022 12:59 PM 1704 dcv.key -a---- 8/4/2022 12:59 PM 1265 dcv.pem
应自动重新创建这些文件,后续的连接尝试可能会成功。
如果此方法解决了问题,并且新启动的 Windows 桌面产生相同的错误,请使用创建软件堆栈功能使用重新生成的证书文件创建固定实例的新 Windows 软件堆栈。这可能会生成可用于成功启动和连接的 Windows 软件堆栈。
........................
VDIs 停留在置备状态
如果桌面启动在管理界面中仍处于预配状态,则可能是由于多种原因造成的。
要确定原因,请检查桌面实例上的日志文件并查找可能导致问题的错误。本文档在标有 “有用的日志和事件信息源” 部分中包含相关信息的日志文件和 Amazon CloudWatch 日志组列表。
以下是此问题的潜在原因。
-
所使用的 AMI ID 已注册为软件堆栈,但 RES 不支持。
由于 AMI 没有所需的预期配置或工具,引导程序配置脚本未能完成。实例(例如 Linux 实例)
/root/bootstrap/logs/上的日志文件可能包含与此相关的有用信息。 AMIs 从 AWS Marketplace 中获取的 ID 可能不适用于 RES 桌面实例。它们需要测试以确认它们是否得到支持。 -
从自定义 AMI 启动 Windows 虚拟桌面实例时,不会执行用户数据脚本。
默认情况下,用户数据脚本在 Amazon EC2 实例启动时运行一次。如果您从现有虚拟桌面实例创建 AMI,然后向 AMI 注册软件堆栈并尝试使用此软件堆栈启动另一个虚拟桌面,则用户数据脚本将无法在新虚拟桌面实例上运行。
要修复此问题,请以管理员身份在用于创建 AMI 的原始虚拟桌面实例上打开 PowerShell 命令窗口,然后运行以下命令:
C:\ProgramData\Amazon\EC2-Windows\Launch\Scripts\InitializeInstance.ps1 –Schedule然后从该实例创建一个新的 AMI。您可以使用新的 AMI 注册软件堆栈,然后启动新的虚拟桌面。请注意,您也可以在仍处于配置状态的实例上运行相同的命令,然后重启该实例以修复虚拟桌面会话,但是从配置错误的 AMI 启动另一个虚拟桌面时,您将再次遇到相同的问题。
........................
VDIs 启动后进入错误状态
- 可能的问题 1:主文件系统为具有不同 POSIX 权限的用户提供了目录。
-
如果以下情况属实,这可能是你面临的问题:
-
部署的 RES 版本为 2024.01 或更高版本。
-
在部署 RES 堆栈期间,的属性设置
EnableLdapIDMapping为True。 -
在 RES 堆栈部署期间指定的主文件系统曾在 RES 2024.01 之前的版本中使用,或者在设置为的先前环境中使用。
EnableLdapIDMappingFalse
解决步骤:删除文件系统中的用户目录。
-
SSM 到集群管理器主机。
-
cd /home. -
ls-应列出目录名与用户名匹配的目录,例如admin1、admin2... 等。 -
删除目录,
sudo rm -r 'dir_name'。不要删除 ssm-user 和 ec2-user 目录。 -
如果用户已经同步到新环境,请从用户的 DDB 表(clusteradmin 除外)中删除该用户的环境。
-
启动 AD 同步-
sudo /opt/idea/python/3.9.16/bin/resctl ldap sync-from-ad在集群管理器 Amazon 中运行。 EC2 -
从 RES 网页重启
Error处于状态的 VDI 实例。验证 VDI 是否在大约 20 分钟后转换到Ready状态。
-
........................
虚拟桌面组件
主题
........................
Amazon EC2 实例在控制台中反复显示已终止
如果基础设施实例在 Amazon EC2 控制台中反复显示为已终止,则原因可能与其配置有关,并取决于基础设施实例的类型。以下是确定原因的方法。
如果 vdc-controller 实例在 Amazon EC2 控制台中显示重复的终止状态,则可能是由于密钥标签不正确所致。由 RES 维护的密钥具有标签,这些标签可用作附加到基础设施 Amazon EC2 实例的 IAM 访问控制策略的一部分。如果 vdc-controller 正在循环并且 CloudWatch 日志组中出现以下错误,则原因可能是未正确标记密钥。请注意,需要使用以下内容标记密钥:
{ "res:EnvironmentName": "<envname>" # e.g. "res-demo" "res:ModuleName": "virtual-desktop-controller" }
此错误的 Amazon CloudWatch 日志消息将如下所示:
An error occurred (AccessDeniedException) when calling the GetSecretValue operation: User: arn:aws:sts::160215750999:assumed-role/<envname>-vdc-gateway-role-us-east-1/i-043f76a2677f373d0 is not authorized to perform: secretsmanager:GetSecretValue on resource: arn:aws:secretsmanager:us-east-1:160215750999:secret:Certificate-res-bi-Certs-5W9SPUXF08IB-F1sNRv because no identity-based policy allows the secretsmanager:GetSecretValue action
检查 Amazon EC2 实例上的标签并确认它们与上面的列表相匹配。
........................
由于无法加入 AD/eVDi 模块显示 API Health Check 失败,vdc-controller 实例正在循环
如果 eVDi 模块的运行状况检查失败,它将在环境状态部分显示以下内容。
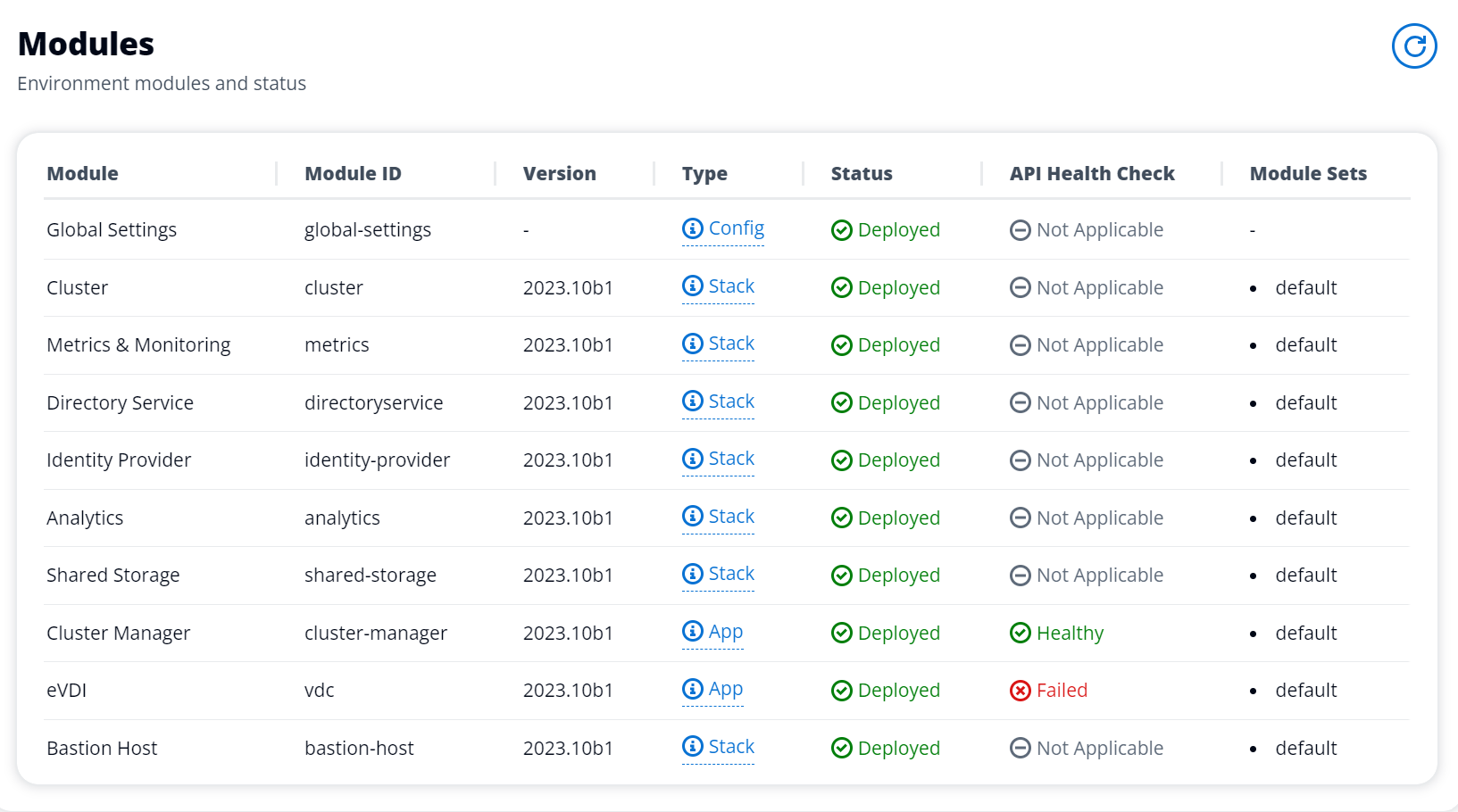
在这种情况下,调试的一般路径是查看集群管理器CloudWatch<env-name>/cluster-manager。)
可能的问题:
-
如果日志包含文本
Insufficient permissions,请确保创建 res 堆栈时给出的 ServiceAccount 用户名拼写正确。日志行示例:
Insufficient permissions to modify computer account: CN=IDEA-586BD25043,OU=Computers,OU=RES,OU=CORP,DC=corp,DC=res,DC=com: 000020E7: AtrErr: DSID-03153943, #1: 0: 000020E7: DSID-03153943, problem 1005 (CONSTRAINT_ATT_TYPE), data 0, Att 90008 (userAccountControl):len 4 >> 432 ms - request will be retried in 30 seconds-
您可以从 SecretsManager 控制台
访问 RES 部署期间提供的 ServiceAccount 用户名。在 Secrets 管理器中找到相应的密钥,然后选择 “检索纯文本”。如果用户名不正确,请选择编辑以更新密码值。终止当前的集群管理器和 vdc-Controller 实例。新实例将处于稳定状态。 -
如果您正在使用由提供的外部资源堆栈创建的资源,则用户名必须ServiceAccount为 “”。如果在部署 RES 期间将该
DisableADJoin参数设置为 False,请确保 ServiceAccount “” 用户有权在 AD 中创建计算机对象。
-
-
如果使用的用户名正确,但日志中包含文本
Invalid credentials,则您输入的密码可能错误或已过期。日志行示例:
{'msgtype': 97, 'msgid': 1, 'result': 49, 'desc': 'Invalid credentials', 'ctrls': [], 'info': '80090308: LdapErr: DSID-0C090569, comment: AcceptSecurityContext error, data 532, v4563'}-
通过在 Secr ets Manager 控制台
中访问存储密码的密钥,您可以读取您在创建环境时输入的密码。选择密钥(例如 <env_name>directoryserviceServiceAccountPassword),然后选择 “检索纯文本”。 -
如果密钥中的密码不正确,请选择编辑以更新其在密钥中的值。终止当前的集群管理器和 vdc-Controller 实例。新实例将使用更新的密码并处于稳定状态。
-
如果密码正确,则可能是连接的 Active Directory 中的密码已过期。你必须先在 Active Directory 中重置密码,然后更新密码。您可以通过 Directory Ser vice 控制台在 Active Direc
tory 中重置用户的密码: -
选择相应的目录 ID
-
选择 “操作”、“重置用户密码”,然后在表单中填写用户名(例如 ServiceAccount “”)和新密码。
-
如果新设置的密码与之前的密码不同,请更新相应的 Secret Manager 密钥中的密码(例如,
<env_name>directoryserviceServiceAccountPassword. -
终止当前的集群管理器和 vdc-Controller 实例。新实例将处于稳定状态。
-
-
........................
编辑软件堆栈以添加项目时,项目不会出现在下拉列表中
此问题可能与以下与将用户帐户与 AD 同步相关的问题有关。如果出现此问题,请检查集群管理器 Amazon CloudWatch 日志组中是否存在错误 <user-home-init> account not available yet. waiting for user to be synced “”,以确定原因是相同还是相关。
........................
cluster-manager Amazon CloudWatch 日志显示 “< user-home-init > 账户还不可用。正在等待用户同步”(其中账户是用户名)
SQS 订阅者由于无法访问用户帐户而忙碌并陷入无限循环。在用户同步期间尝试为用户创建主文件系统时,会触发此代码。
它无法访问用户帐户的原因可能是没有为正在使用的 AD 正确配置 RES。例如,创建 BI/RES 环境时使用的ServiceAccountUsername参数值不正确,例如使用 “” 而不是 ServiceAccount “Admin”。
........................
尝试登录时的 Windows 桌面显示 “您的帐户已被禁用。请咨询您的管理员”
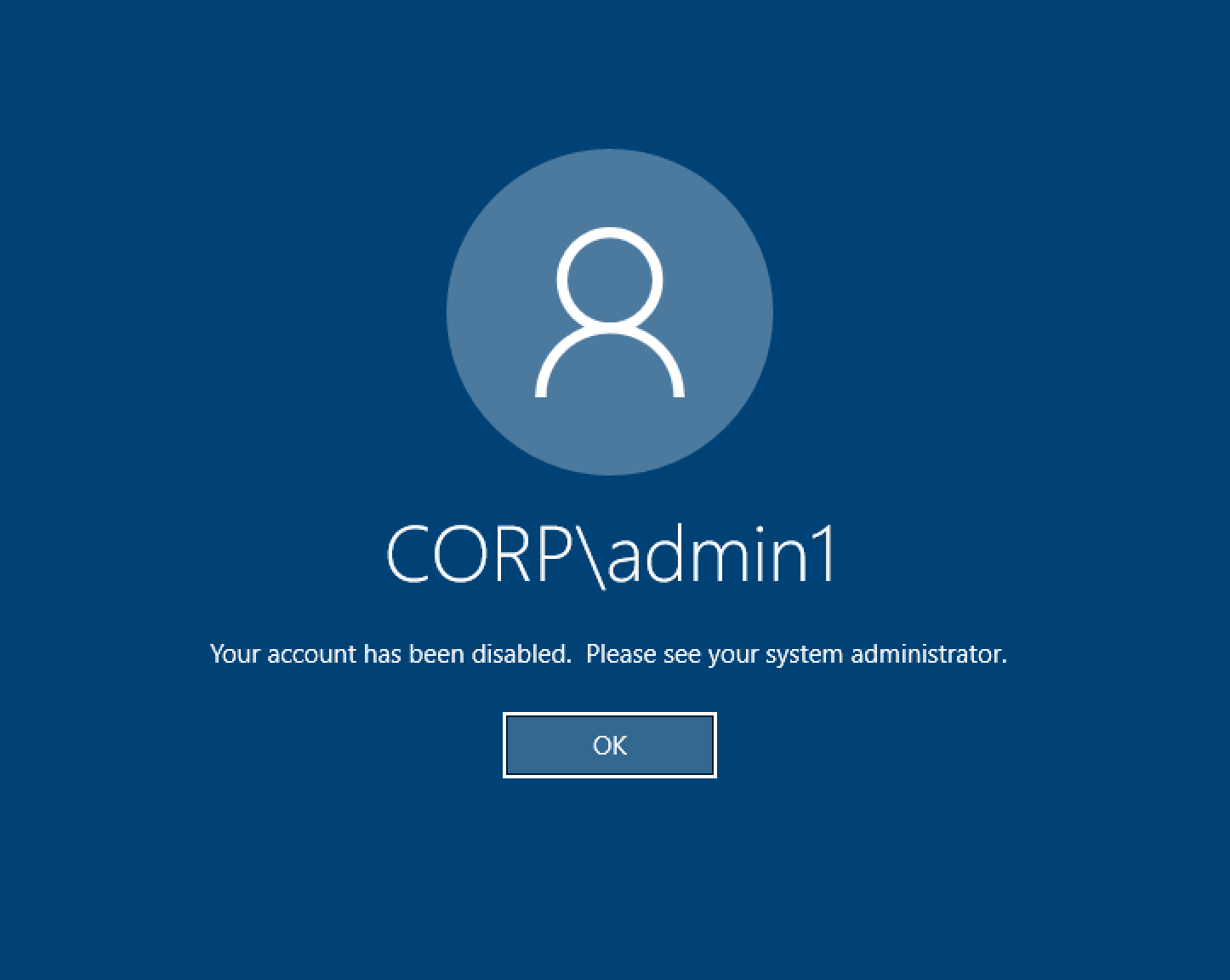
如果用户无法重新登录锁定屏幕,则可能表示该用户在通过 SSO 成功登录后,已在为 RES 配置的 AD 中被禁用。
如果在 AD 中禁用了用户帐户,SSO 登录应该会失败。
........................
external/customer AD 配置的 DHCP 选项问题
如果您在自己的 Active D "The connection has been closed. Transport
error" irectory 中使用 RES 时遇到错误说明 Windows 虚拟桌面,请查看 dcv-connection-gateway Amazon CloudWatch 日志中是否有类似以下内容的内容:
Oct 28 00:12:30.626 INFO HTTP:Splicer Connection{id=263}: Websocket{session_id="96cffa6e-cf2e-410f-9eea-6ae8478dc08a"}: Connection initiated error: unreachable, server io error Custom { kind: Uncategorized, error: "failed to lookup address information: Name or service not known" } Oct 28 00:12:30.626 WARN HTTP:Splicer Connection{id=263}: Websocket{session_id="96cffa6e-cf2e-410f-9eea-6ae8478dc08a"}: Error in websocket connection: Server unreachable: Server error: IO error: failed to lookup address information: Name or service not known Oct 28 00:12:30.627 DEBUG HTTP:Splicer Connection{id=263}: ConnectionGuard dropped
如果您将 AD 域控制器用于自己的 VPC 的 DHCP 选项,则需要:
-
将 AmazonProvided DNS 添加到两个域控制器 IPs。
-
将域名设置为 ec2.internal。
此处显示了一个示例。如果没有此配置,Windows 桌面将显示传输错误,因为正在查 RES/DCV 找 ip-10-0-xx.ec2.internal 主机名。

........................
Firefox 错误 MOZILLA_PKIX_ERROR_REQUIRED_TLS_FEATURE_MISSING
当你使用 Firefox 网络浏览器时,当你尝试连接到虚拟桌面时,你可能会遇到错误消息类型 MOZILLA_PKIX_ERROR_REQUIRED_TLS_FEATURE_MISSING。
你可以按照以下地址的说明解决这个问题: https://really-simple-ssl.com/mozilla
........................
环境删除
主题
........................
res-xxx-cluster 堆栈处于 “DELETE_FAILED” 状态,由于 “角色无效或无法假设” 错误,无法手动删除
如果您注意到 “” res-xxx-cluster 堆栈处于 “DELETE_FAILED” 状态且无法手动删除,则可以执行以下步骤将其删除。
如果您看到堆栈处于 “DELETE_FAILED” 状态,请先尝试手动将其删除。它可能会弹出一个确认删除堆栈的对话框。选择删除。
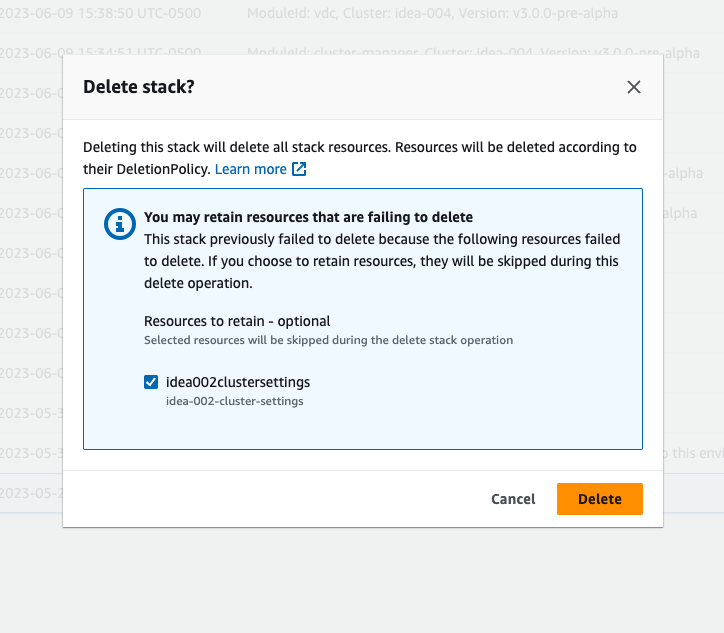
有时,即使您删除了所有必需的堆栈资源,您仍可能会看到选择要保留的资源的消息。在这种情况下,请选择所有资源作为 “要保留的资源”,然后选择删除。
你可能会看到一个如下所示的错误 Role: arn:aws:iam::... is Invalid or cannot
be assumed
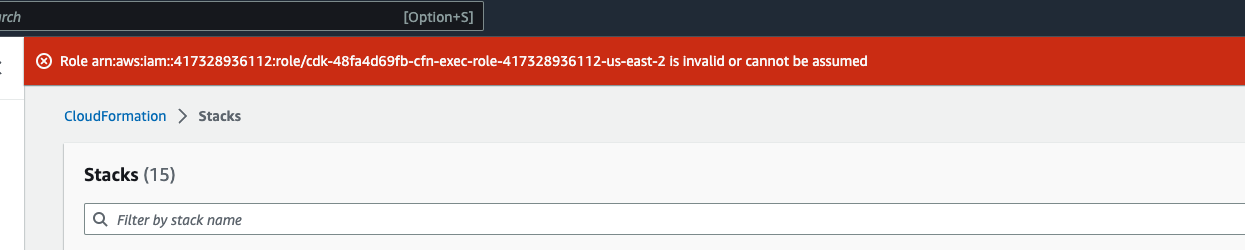
这意味着删除堆栈所需的角色在堆栈之前先被删除。要解决这个问题,请复制角色的名称。前往 IAM 控制台,使用此处所示的参数创建具有该名称的角色,这些参数是:
-
对于可信实体类型,请选择AWS 服务。
-
对于用例,请在
Use cases for other AWS services“选择” 下方CloudFormation。
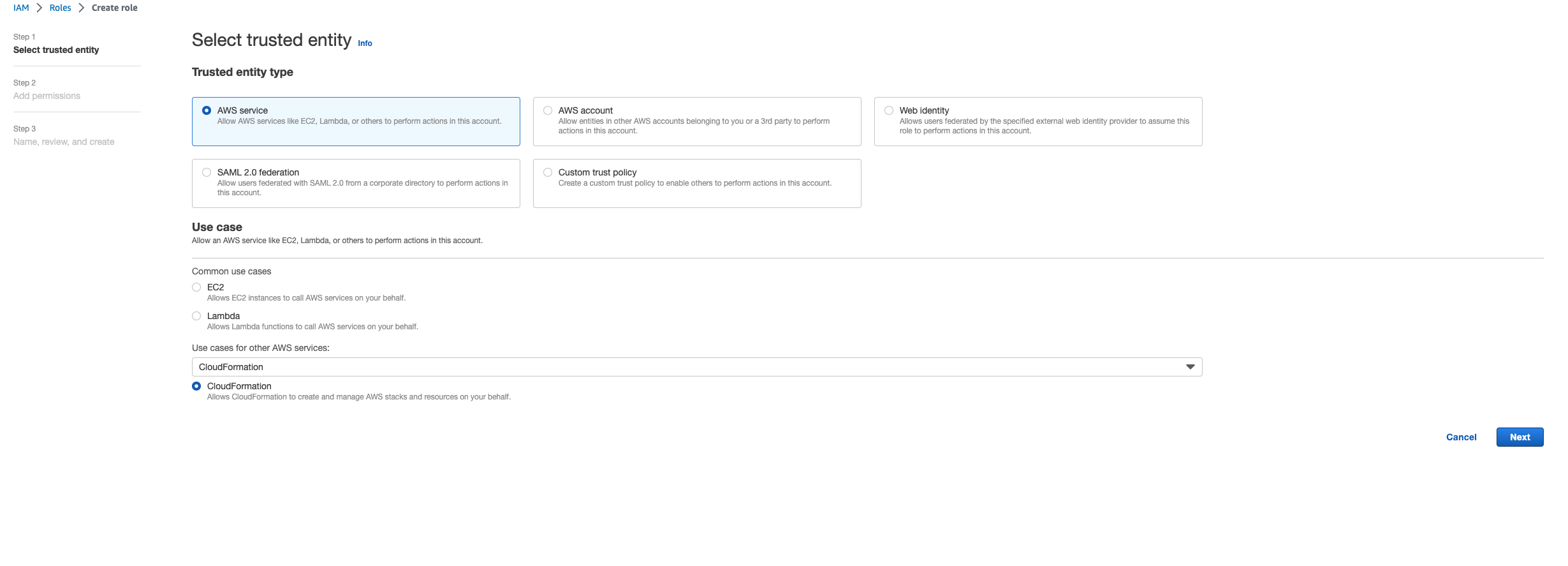
选择下一步。确保为角色授予 “AWSCloudFormationFullAccess” 和 “AdministratorAccess” 权限。您的评论页面应如下所示:
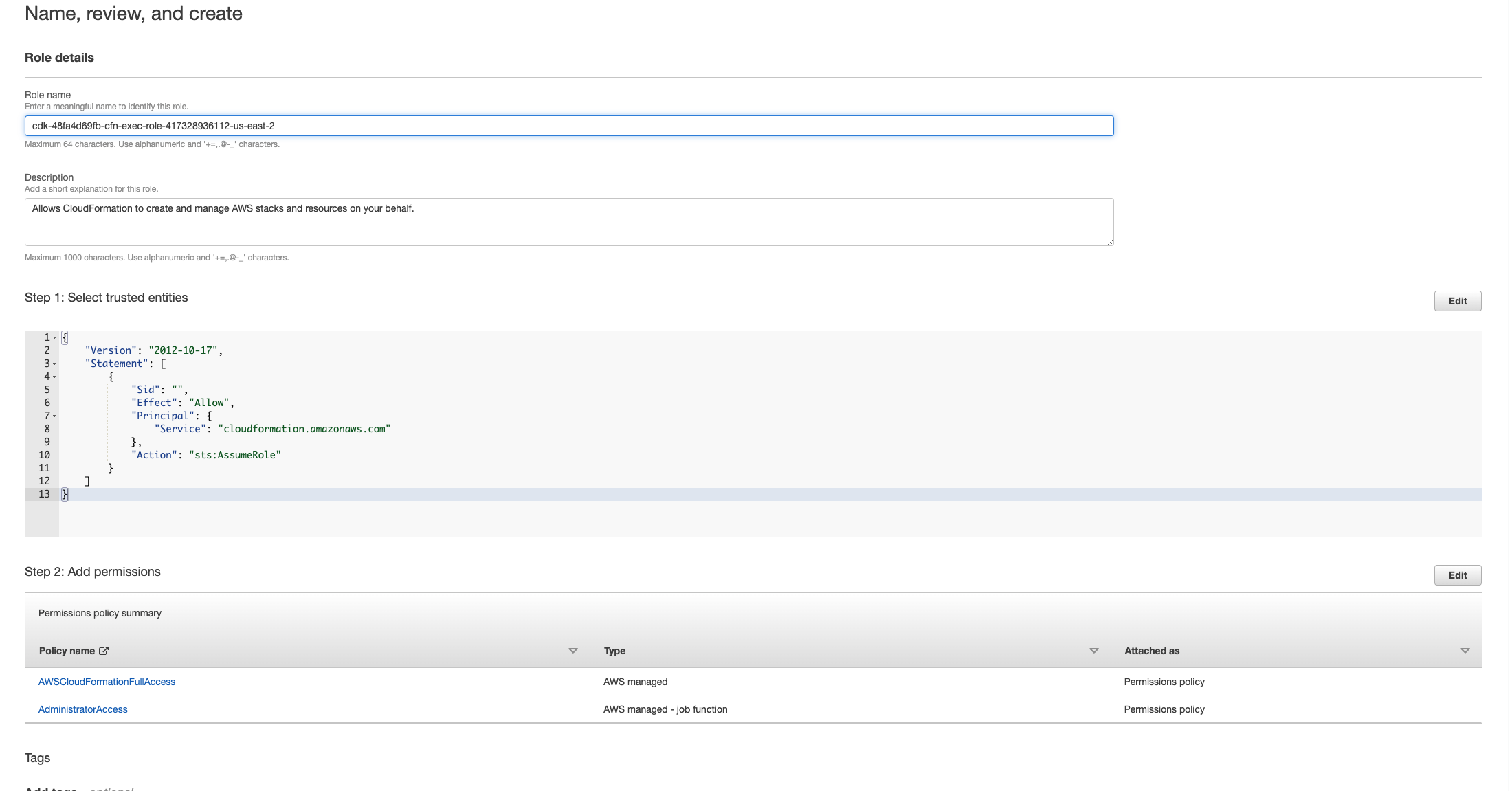
然后返回 CloudFormation 控制台并删除堆栈。自创建角色以来,您现在应该可以将其删除。最后,前往 IAM 控制台并删除您创建的角色。
........................
收集日志
从 EC2 控制台登录 EC2 实例
收集基础架构主机日志
-
Cluster-Manager:从以下位置获取集群管理器的日志,并将其附加到票证中。
-
日志组中的所有 CloudWatch 日志
<env-name>/cluster-manager。 -
<env-name>-cluster-managerEC2 实例上/root/bootstrap/logs目录下的所有日志。按照本节开头的 “从 EC2 控制台登录 EC2 实例” 中链接到的说明登录您的实例。
-
-
VDC-Controller:从以下位置获取 vdc-Controller 的日志,并将其附加到票证中。
-
日志组中的所有 CloudWatch 日志
<env-name>/vdc-controller。 -
<env-name>-vdc-controllerEC2 实例上/root/bootstrap/logs目录下的所有日志。按照本节开头的 “从 EC2 控制台登录 EC2 实例” 中链接到的说明登录您的实例。
-
轻松获取日志的方法之一是按照从 Linux EC2 实例下载日志本节中的说明进行操作。模块名称将是实例名称。
收集 VDI 日志
- 识别相应的 Amazon EC2 实例
-
如果用户启动了带有会话名称的 VDI
VDI1,则 Amazon EC2 控制台上的相应实例名称将是。<env-name>-VDI1-<user name> - 收集 Linux VDI 日志
-
按照本节开头 “从 EC2 控制台登录 EC2 实例” 中链接的说明,从 Amazon EC2 控制台登录相应的 Amazon EC2 实例。获取 VDI Amazon EC2 实例上
/root/bootstrap/logs和/var/log/dcv/目录下的所有日志。获取日志的方法之一是将它们上传到 s3,然后从那里下载。为此,您可以按照以下步骤从一个目录中获取所有日志,然后将其上传:
-
按照以下步骤在
/root/bootstrap/logs目录下复制 dcv 日志:sudo su - cd /root/bootstrap mkdir -p logs/dcv_logs cp -r /var/log/dcv/* logs/dcv_logs/ -
现在,按照下一节中列出的步骤下载日志。正在下载 VDI 日志
-
- 收集 Windows VDI 日志
-
按照本节开头 “从 EC2 控制台登录 EC2 实例” 中链接的说明,从 Amazon EC2 控制台登录相应的 Amazon EC2 实例。获取 VDI EC2 实例上
$env:SystemDrive\Users\Administrator\RES\Bootstrap\Log\目录下的所有日志。获取日志的方法之一是将它们上传到 S3,然后从那里下载。为此,请按照下一节中列出的步骤进行操作-正在下载 VDI 日志。
........................
正在下载 VDI 日志
更新 VDI EC2 实例 IAM 角色以允许 S3 访问。
转到 EC2 控制台并选择您的 VDI 实例。
选择它正在使用的 IAM 角色。
-
在 “添加权限” 下拉菜单的 “权限策略” 部分,选择 “附加策略”,然后选择 AmazonS3 FullAccess 策略。
选择添加权限以附加该策略。
-
之后,根据您的 VDI 类型,按照下面列出的步骤下载日志。模块名称将是实例名称。
-
从 Linux EC2 实例下载日志适用于 Linux。
-
从 Windows EC2 实例下载日志适用于 Windows。
-
-
最后,编辑角色以删除
AmazonS3FullAccess策略。
注意
所有角色都 VDIs 使用相同的 IAM 角色,即 <env-name>-vdc-host-role-<region>
........................
从 Linux EC2 实例下载日志
登录您要从中下载日志的 EC2 实例,然后运行以下命令将所有日志上传到 s3 存储桶:
sudo su - ENV_NAME=<environment_name>REGION=<region>ACCOUNT=<aws_account_number>MODULE=<module_name>cd /root/bootstrap tar -czvf ${MODULE}_logs.tar.gz logs/ --overwrite aws s3 cp ${MODULE}_logs.tar.gz s3://${ENV_NAME}-cluster-${REGION}-${ACCOUNT}/${MODULE}_logs.tar.gz
之后,转到 S3 控制台,选择带有名称的存储桶,<environment_name>-cluster-<region>-<aws_account_number>然后下载之前上传的<module_name>_logs.tar.gz文件。
........................
从 Windows EC2 实例下载日志
登录您要从中下载日志的 EC2 实例,然后运行以下命令将所有日志上传到 S3 存储桶:
$ENV_NAME="<environment_name>" $REGION="<region>" $ACCOUNT="<aws_account_number>" $MODULE="<module_name>" $logDirPath = Join-Path -Path $env:SystemDrive -ChildPath "Users\Administrator\RES\Bootstrap\Log" $zipFilePath = Join-Path -Path $env:TEMP -ChildPath "logs.zip" Remove-Item $zipFilePath Compress-Archive -Path $logDirPath -DestinationPath $zipFilePath $bucketName = "${ENV_NAME}-cluster-${REGION}-${ACCOUNT}" $keyName = "${MODULE}_logs.zip" Write-S3Object -BucketName $bucketName -Key $keyName -File $zipFilePath
之后,转到 S3 控制台,选择带有名称的存储桶,<environment_name>-cluster-<region>-<aws_account_number>然后下载之前上传的<module_name>_logs.zip文件。
........................
正在收集 WaitCondition 错误的 ECS 日志
-
转到已部署的堆栈并选择 “资源” 选项卡。
-
展开部署 ResearchAndEngineeringStudio→ 安装程序 → 任务 CreateTaskDef→ CreateContainer→ LogGroup,然后选择要打开日志的 CloudWatch 日志组。
-
从该日志组中获取最新的日志。
........................
演示环境
........................
处理对身份提供商的身份验证请求时出现演示环境登录错误
问题
如果您尝试登录并收到 “处理身份提供商的身份验证请求时出现意外错误”,则您的密码可能已过期。这可能是你尝试登录的用户的密码,也可以是你的 Active Directory Service 账户。
缓解方法
-
在目录服务控制台中重置用户和服务
帐户密码。 -
更新 S ecrets Manager
中的服务帐户密码,使其与您在上面输入的新密码相匹配: -
对于 Keycloak 堆栈:PasswordSecret-... -RESExternal-... -DirectoryService-... 附带描述:微软 Active Directory 的密码
-
对于 RES:res-ServiceAccountPassword-... 带描述:Active Directory Service 账户密码
-
-
转到EC2 控制台
并终止集群管理器实例。Auto Scaling 规则将自动触发新实例的部署。
........................
