本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
数据准备步骤
Amazon Quick Sight 的数据准备体验提供了 11 种强大的步骤类型,使您能够系统地转换数据。在数据准备工作流程中,每个步骤都有特定的用途。
可以通过 “配置” 窗格中的直观界面配置步骤,在 “预览” 窗格中可以看到即时反馈。可以按顺序组合步骤来创建复杂的数据转换,而无需 SQL 专业知识。
每个步骤都可以接收来自物理表的输入或上一步的输出。大多数步骤都接受单个输入,但 Append 和 Join 步骤除外,它们只需要两个输入。
Input
“输入” 步骤允许您从多个来源选择和导入数据,以便在后续步骤中进行转换,从而在 Quick Sight 中启动数据准备工作流程。
输入选项
-
添加数据集
利用现有的 Quick Sight 数据集作为输入源,在团队已经准备好和优化的数据基础上再接再厉。
-
添加数据源
通过选择特定的数据库对象并提供连接参数,直接连接到 Amazon Redshift、Athena、RDS 等数据库或其他支持的来源。
-
添加文件上传
以 CSV、TSV、Excel 或 JSON 等格式直接从本地文件导入数据。
配置
“输入” 步骤无需配置。预览窗格显示您导入的数据以及源信息,包括连接详细信息、表名和列元数据。
使用说明
-
单个工作流程中可以存在多个输入步骤。
-
您可以在工作流程中的任何时候添加输入步骤。
添加计算列
“添加计算列” 步骤允许您使用对现有列执行计算的行级表达式创建新列。您可以使用标量(行级)函数和运算符创建新列,也可以应用引用现有列的行级计算。
配置
要配置 “添加计算列” 步骤,请在 “配置” 窗格中执行以下操作:
-
为您的新计算列命名。
-
保存您的计算结果。
-
预览表达式结果。
-
根据需要添加更多计算列。
使用说明
-
此步骤仅支持标量(行级)计算。
-
在 SPICE 中,计算的列是实现的,并在后续步骤中用作标准列。
更改数据类型
Quick Sight 通过支持四种抽象数据类型来简化数据类型管理:datedecimalinteger、、和string。这些抽象类型通过自动将各种源数据类型映射到其 Quick Sight 等效数据类型来消除复杂性。例如,、、tinyintsmallintinteger、和bigint都映射到integer、while date、datetime、和timestamp都映射到date。
这种抽象意味着您只需要了解 Quick Sight 的四种数据类型,因为在与不同的数据源交互时,Quick Sight 会自动处理所有底层数据类型的转换和计算。
配置
要配置 “更改数据类型” 步骤,请在 “配置” 窗格中执行以下操作:
-
选择要转换的列。
-
选择目标数据类型(
string、integerdecimal、或date)。 -
对于日期转换,请指定格式设置并根据输入格式预览结果。在 Quick Sight 中查看支持的日期格式。
-
根据需要添加其他列进行转换。
使用说明
-
为了提高效率,只需一个步骤即可转换多列的数据类型。
-
使用 SPICE 时,所有数据类型更改都将在导入的数据中实现。
重命名列
“重命名列” 步骤使您可以修改列名,使其更具描述性、用户友好性并与组织的命名惯例保持一致。
配置
要配置 “重命名列” 步骤,请在 “配置” 窗格中执行以下操作:
-
选择要命名的列。
-
为所选列输入新名称。
-
根据需要添加更多要重命名的列。
使用说明
-
所有列名在您的数据集中必须是唯一的。
选择列
“选择列” 步骤使您可以通过包含、排除列和重新排序列来简化数据集。这有助于通过删除不必要的列并按逻辑顺序组织剩余的列进行分析来优化数据结构。
配置
要配置 “选择列” 步骤,请在 “配置” 窗格中执行以下操作:
-
选择要包含在输出中的特定列。
-
按您的首选顺序选择列以建立顺序。
-
使用 “全选” 可按其原始顺序包括其余列。
-
取消选中不需要的列,将其排除在外。
主要特点
-
输出列按选择顺序显示。
-
“全选” 将保留原始列顺序。
使用说明
-
未选中的列将从后续步骤中删除。
-
通过删除不必要的列来优化数据集大小。
Append
追加步骤垂直合并两个表,类似于 SQL UNION ALL 操作。Quick Sight 会自动按名称而不是按顺序匹配列,即使表的列顺序不同或列数各不相同,也能实现高效的数据整合。
配置
要配置 “追加” 步骤,请在 “配置” 窗格中执行以下操作:
-
选择两个要追加的输入表。
-
查看输出列顺序。
-
检查两个表中存在哪些列与单个表中存在哪些列。
主要特征
-
按名称而不是按顺序匹配列。
-
保留两个表中的所有行,包括重复行。
-
支持具有不同列数的表。
-
按照表 1 的列顺序进行匹配列,然后添加表 2 中的唯一列。
-
显示所有列的清晰源指示符
使用说明
-
追加具有不同名称的列时,请先使用 “重命名” 步骤。
-
每个 Append 步骤恰好组合了两个表;使用附加步骤可以创建更多表。
联接
“联接” 步骤根据指定列中的匹配值水平合并来自两个表的数据。Quick Sight 支持 “左外”、“右外”、“全外” 和 “内连接” 类型,为您的分析需求提供了灵活的选项。该步骤包括智能列冲突解决方案,可自动处理重复的列名。虽然自联接不能作为特定的联接类型使用,但使用工作流程差异可以获得类似的结果。
配置
要配置 “加入” 步骤,请在 “配置” 窗格中执行以下操作:
-
选择两个要连接的输入表。
-
选择您的联接类型(左外、右外、全外或内部)。
-
指定每个表中的联接键。
-
查看自动解决的列名冲突。
主要特征
-
支持多种联接类型,以满足不同的分析需求。
-
自动解析重复的列名。
-
接受计算列作为联接键。
使用说明
-
联接键必须具有兼容的数据类型;如果需要,请使用 “更改数据类型” 步骤。
-
每个 Join 步骤恰好组合两个表;使用其他 Join 步骤可以创建更多表。
-
在 “加入” 之后创建 “重命名” 步骤,以自定义自动解析的列标题。
聚合
“聚合” 步骤允许您通过对列进行分组和应用聚合操作来汇总数据。这种强大的转换功能可根据您的指定维度将详细数据浓缩为有意义的摘要。Quick Sight 通过直观的界面简化了复杂的 SQL 操作,提供了全面的聚合功能,包括ListAgg和等高级字符串操作ListAgg distinct。
配置
要配置 “聚合” 步骤,请在 “配置” 窗格中执行以下操作:
-
选择要作为分组依据的列。
-
为度量列选择聚合函数。
-
自定义输出列名称。
-
针对
ListAgg和ListAgg distinct:-
选择要聚合的列。
-
选择分隔符(逗号、短划线、分号或垂直线)。
-
-
预览汇总数据。
每种数据类型支持的函数
| 数据类型 | 支持的函数 |
|---|---|
|
数值 |
|
|
日期 |
|
|
字符串 |
|
主要特征
-
对同一步骤中的列应用不同的聚合函数。
-
不使用聚合函数@@ 的分组方式充当 SQL SELECT DISTIN
-
ListAgg连接所有值;仅ListAgg distinct包括唯一值。 -
ListAgg默认情况下,函数保持升序排序顺序。
使用说明
-
聚合可显著减少数据集中的行数。
-
ListAgg还有ListAgg distinct支持date价值观,但不是datetime。 -
使用分隔符自定义字符串连接输出。
筛选条件
使用 “筛选” 步骤,您可以通过仅包括符合特定条件的行来缩小数据集的范围。您可以在一个步骤中应用多个筛选条件,所有这些条件都通过AND逻辑组合在一起,以帮助将分析重点放在相关数据上。
配置
要配置 “筛选器” 步骤,请在 “配置” 窗格中执行以下操作:
-
选择要筛选的列。
-
选择比较运算符。
-
根据列的数据类型指定筛选值。
-
如果需要,可以在不同的列中添加其他筛选条件。
注意
-
带有 “在” 或 “不在” 的字符串筛选器:输入多个值(每行一个)。
-
数字和日期筛选器:输入单个值(“介于” 除外,它需要两个值)。
每种数据类型支持的运算符
| 数据类型 | 支持的运算符 |
|---|---|
|
整数和十进制 |
等于,不等于 大于,小于 大于或等于,小于或等于 介于 |
|
日期 |
之后,之前 介于 大于或等于、等于、等于或等于 |
|
字符串 |
等于,不等于 开头为,结尾为 包含,不包含 在,不在 |
使用说明
-
在单个步骤中应用多个筛选条件。
-
混合不同数据类型的条件。
-
实时预览筛选结果。
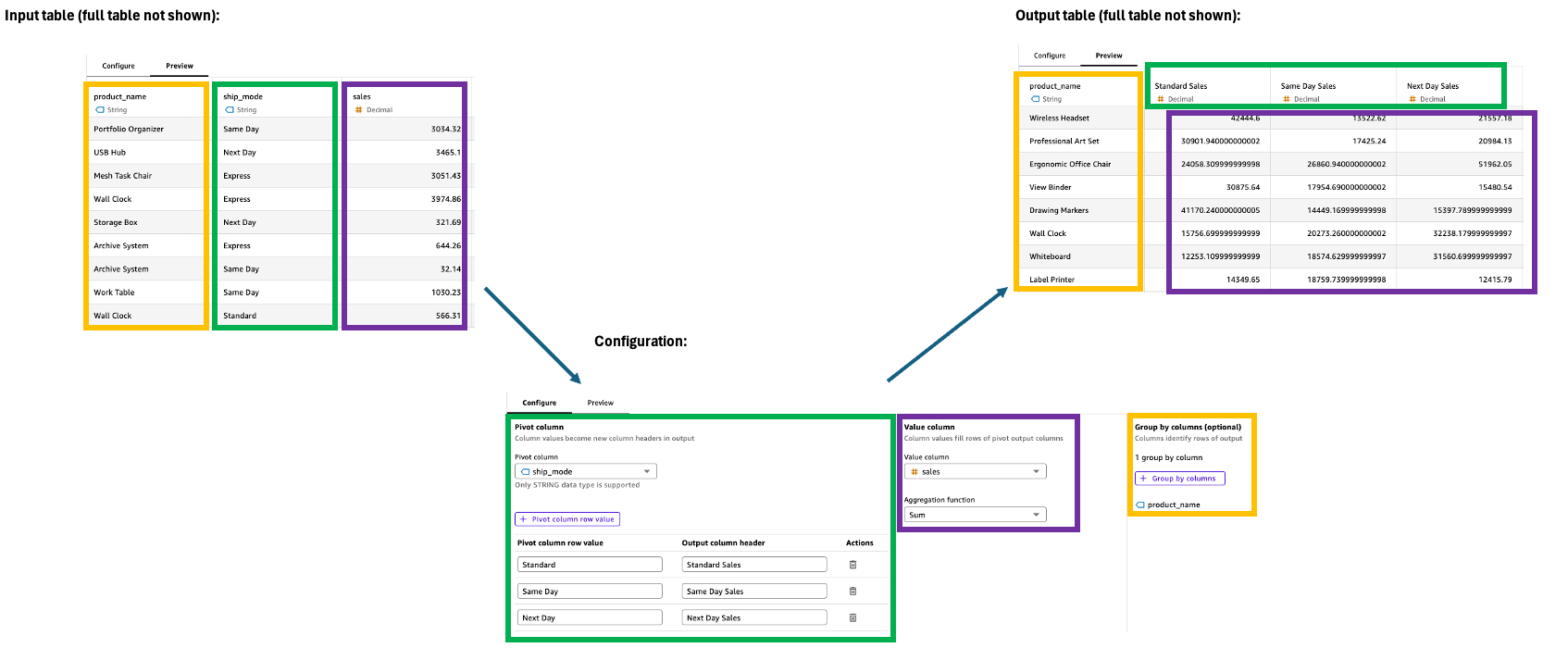
转置
Pivot 步骤将行值转换为唯一的列,将数据从长格式转换为宽格式,以便于比较和分析。这种转换需要对值过滤、聚合和分组进行规范,以便有效地管理输出列。
配置
要配置 Pivot 步骤,请在 “配置” 窗格中使用以下内容:
-
透视列:选择其值将成为列标题的列(例如,类别)。
-
透视列行值:筛选要包含的特定值(例如,技术、办公用品)。
-
输出列标题:自定义新的列标题(默认为透视列值)。
-
值列:选择要汇总的列(例如,销售额)。
-
聚合函数:选择聚合方法(例如,Sum)。
-
分组依据:指定组织列(例如,区段)。
每种数据类型支持的运算符
| 数据类型 | 支持的运算符 |
|---|---|
|
整数和十进制 |
|
|
日期 |
|
|
字符串 |
|
使用说明
-
每个转置的列都包含来自值列的聚合值。
-
为清晰起见,自定义列标题。
-
实时预览转换结果。
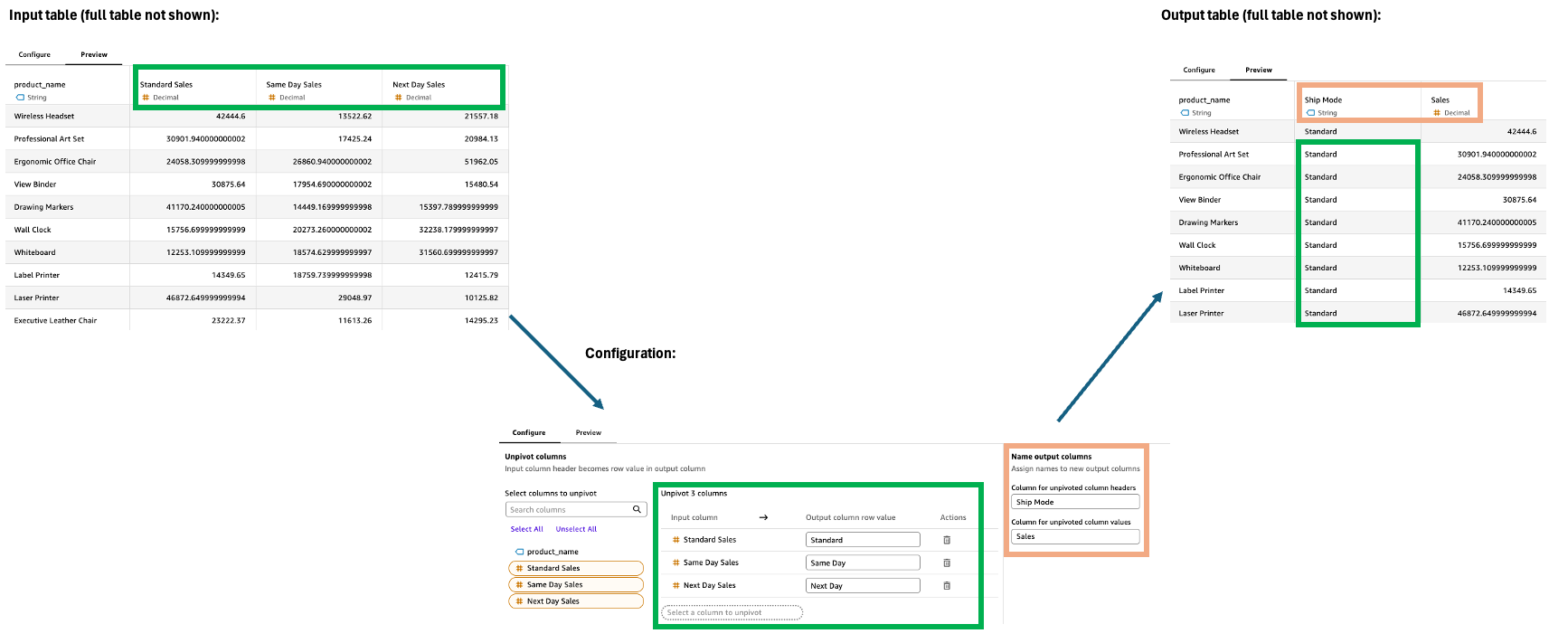
取消透视
Unpivot 步骤将列转换为行,将宽数据转换为更长、更窄的格式。这种转换有助于将分布在多列中的数据组织成更具结构性的格式,以便于分析和可视化。
配置
要配置 Unpivot 步骤,请在 “配置” 窗格中执行以下操作:
-
选择要取消透视成行的列。
-
定义输出列的行值。默认值为原始列名。一些例子包括技术、办公用品和家具。
-
命名两个新的输出列。
-
未转置的列标题:以前的列名(例如,类别)的名称
-
未旋转的列值:未旋转值的名称(例如,Sales)
-
主要特征
-
在输出中保留所有未旋转的列。
-
自动创建两个新列:一个用于以前的列名,另一个用于其对应的值。
-
将宽数据转换为长格式。
使用说明
-
所有未转置的列都必须具有兼容的数据类型。
-
取消旋转后,行数通常会增加。
-
在应用更改之前,请实时预览更改。
