本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
设计 Amazon Redshift 表的最佳实践
本节概述设计数据库表的最佳实践。我们建议您遵循以下最佳实践,以实现最佳查询性能和效率。
了解排序键的工作原理
Amazon Redshift 根据排序键将您的数据按照排序顺序存储在磁盘中。Amazon Redshift 查询优化程序在确定最佳查询计划时会使用排序顺序。为了有效使用排序键,我们建议您执行以下操作:
-
尽可能保持表的排序状态。
-
使用
VACUUM排序以恢复最佳性能。 -
避免压缩排序键列。
-
如果排序键已压缩,且
sortkey1_skew比率非常高,则在不对排序键启用压缩功能的情况下重新创建表。 -
避免对排序键列应用函数。例如,在以下查询中,如果将
trans_dt : TIMESTAMPTZ排序键列转换为DATE,则不使用该列:select order_id, order_amt from sales where trans_dt::date = '2021-01-08'::date -
按排序键顺序执行
INSERT操作。 -
尽可能在
GROUP BY子句中使用排序键。
查询调优提示
我们建议您执行以下操作以调优查询:
-
始终按从最低基数到最高基数的顺序对复合排序键进行排序以获得最佳效果。
-
如果复合排序键中的前导键相对唯一(即具有较高的基数),则应避免向排序键中添加额外的列。添加额外的列对查询性能影响不大,但会增加维护成本。
评估排序键有效性
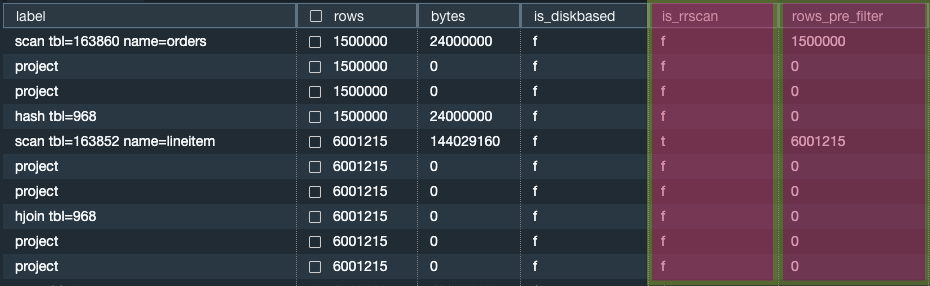
要优化查询,您必须能够评估查询的有效性。我们建议您使用 SVL_QUERY_SUMMARY 视图查找有关查询执行的一般信息。在此视图中,您可以使用属性 IS_RRSCAN 来确定 EXPLAIN 计划步骤是否使用范围受限的扫描。您也可以使用属性 rows_pre_filter 来确定排序键的选择性。
您还可以使用 GitHub 中名为 v_my_last_query_summary
以下语句显示如何查找关于查询执行的一般信息。
select lpad(' ',stm+seg+step) || label as label, rows, bytes, is_diskbased, is_rrscan, rows_pre_filter from svl_query_summary where query = pg_last_query_id() order by stm, seg, step;
上述查询返回以下示例输出。
了解您的表
了解表的关键属性很重要。要了解关于表的更多信息,请执行以下操作:
-
使用 PG_TABLE_DEF 查看关于表列的信息。
-
使用 SVV_TABLE_INFO 查看关于表的更全面的信息,包括数据分配偏斜、密钥分配偏斜、表大小和统计数据。
选择正确的表分配方式
在运行查询时,查询优化程序根据执行任何联接和聚合的需要将行重新分配到计算节点。选择表分配方式的目的是通过在运行查询前将数据放在需要的位置以最大程度地减小重新分配步骤的影响。
我们建议使用以下方法来选择正确的表分配方式:
-
通过将行并置在同一个节点内,避免在查询执行计划中进行广播和重新分配。例如,通过选择
DISTKEY,可在其共用列上分配事实数据表和一维表。根据筛选的数据集的大小选择最大的维度。只有用于联接的行才必须分配,因此需要考虑筛选后数据集的大小,而不是表的大小。 -
确保创建分配键的列没有偏度。否则,某个计算节点可能会比其他计算节点执行更多繁重的工作。如果发现偏度,请考虑更改分配键列。如果列值分布均匀或基数值较高,则可以将其视为分配键的候选列。
-
如果联接条件中使用的表较小(小于 1 GB),则考虑分配方式
ALL。 -
您可以压缩分配键,但必须避免压缩排序键列(尤其是排序键的第一列)。
注意
如果使用自动表优化,则不需要选择表的分配方式。有关更多信息,请参阅 Amazon Redshift 文档中的使用自动表优化。要让 Amazon Redshift 选择适当的分配方式,请指定 AUTO 作为分配方式。
