本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
在 AWS Lambda 函数中使用 Python 并行读取 S3 对象
Eduardo Bortoluzzi,Amazon Web Services
Summary
您可以使用此模式从 Amazon Simple Storage Service(Amazon S3)存储桶中实时检索和汇总文档列表。此模式提供了在 Amazon Web Services(AWS)上并行读取 S3 存储桶中的对象的示例代码。该模式展示了如何使用 Python 通过 AWS Lambda 函数高效运行 I/O 绑定任务。
某金融公司在交互式解决方案中使用此模式,以实时通过手动方式批准或拒绝相关的金融交易。金融交易相关文档存储在与该市场相关的 S3 存储桶中。操作人员从 S3 存储桶中选择文档列表,分析解决方案计算出的交易总价值,并决定是批准还是拒绝所选批次。
I/O 绑定任务支持多个线程。在此示例代码中,并行.futu res。 ThreadPoolExecutorbotocore 中的最大池连接数,确保所有线程都能同时执行 S3 对象下载操作。
该示例代码使用的是 S3 存储桶中一个包含 JSON 数据的 8.3 KB 对象,并对该对象进行了多次读取。Lambda 函数读取该对象后,会将 JSON 数据解码为 Python 对象。2024 年 12 月,运行此示例后的结果是,使用配置了 2,304 MB 内存的 Lambda 函数在 2.3 秒内处理了 1,000 次读取,在 27 秒内处理了 10,000 次读取。 AWS Lambda 支持从 128 MB 到 10,240 MB (10 GB) 的内存配置,但将 Lambdamemory 增加到 2,304 MB 以上无助于缩短运行此特定 I/O 绑定任务的时间。
AWS Lambda 电源调整
先决条件和限制
先决条件
活跃的 AWS 账户
熟练掌握 Python 开发能力
限制
一个 Lambda 函数最多可拥有 1,024 个执行进程或线程。
新 AWS 账户 的 Lambda 内存限制为 3,008 MB。相应地调整 AWS Lambda 电源调整工具。有关更多信息,请参阅问题排查部分。
Amazon S3 对每个分区前缀的 GET/HEAD 请求限制为每秒 5,500 个。
产品版本
Python 3.9 或更高版本
AWS Cloud Development Kit (AWS CDK) v2
AWS Command Line Interface (AWS CLI) 版本 2
AWS Lambda 功率调整 4.3.6(可选)
架构
目标技术堆栈
AWS Lambda
Amazon S3
AWS Step Functions (如果部署了 AWS Lambda 电源调节)
目标架构
下图展示了从 S3 存储桶并行读取对象的 Lambda 函数。该图还具有用于 AWS Lambda 功率调整工具的 Step Functions 工作流程,用于微调 Lambda 函数内存。这种微调有助于在成本与性能之间实现良好平衡。

自动化和扩展
Lambda 函数可根据需要快速扩展。为了避免在需求量较高的场景下 Amazon S3 出现 503 Slow Down 错误,建议对扩展设置一些限制。
工具
AWS 服务
AWS Cloud Development Kit (AWS CDK) v2 是一个软件开发框架,可帮助您在代码中定义和配置 AWS Cloud 基础架构。示例基础设施是为部署而创建的 AWS CDK。
AWS Command Line InterfaceAWS CLI是一款开源工具,可帮助您 AWS 服务 通过命令行 shell 中的命令进行交互。在此模式中, AWS CLI 版本 2 用于上传示例 JSON 文件。
AWS Lambda 是一项计算服务,可帮助您运行代码,无需预调配或管理服务器。它只在需要时运行您的代码,并自动进行扩展,因此您只需为使用的计算时间付费。
Amazon Simple Storage Service Amazon S3 是一项基于云的对象存储服务,可帮助您存储、保护和检索任意数量的数据。
AWS Step Functions是一项无服务器编排服务,可帮助您组合 AWS Lambda 功能和其他 AWS 服务来构建业务关键型应用程序。
其他工具
Python
是通用的计算机编程语言。Python 3.8 版本中引入了空闲工作线程复用功能 ,此模式中的 Lambda 函数代码适用于 Python 3.9 及更高版本。
代码存储库
此模式的代码可在aws-lambda-parallel-download
最佳实践
此 AWS CDK 构造依赖于您的 AWS 账户用户权限来部署基础架构。如果您计划使用 Pipelin AWS CDK es 或跨账户部署,请参阅堆栈合成器。
此示例应用程序未在 S3 存储桶中启用访问日志。最佳实践是在生产环境代码中启用访问日志。
操作说明
| Task | 说明 | 所需技能 |
|---|---|---|
检查已安装的 Python 版本。 | 此代码已在 Python 3.9 和 Python 3.13 版本上专门测试过,且应能在这两个版本之间的所有版本上正常运行。要检查您的 Python 版本,请在终端中运行 要验证所需模块是否已安装,请运行 | 云架构师 |
安装 AWS CDK。 | 要安装( AWS CDK 如果尚未安装),请按照入门中的说明进行操作 AWS CDK。要确认安装的 AWS CDK 版本是否为 2.0 或更高版本,请运行 | 云架构师 |
引导您的 环境。 | 要引导您的环境(如果尚未完成),请按照引导您的环境以使用 AWS CDK 中的说明进行操作。 | 云架构师 |
| Task | 说明 | 所需技能 |
|---|---|---|
克隆存储库。 | 要克隆最新版本的存储库,请运行以下命令:
| 云架构师 |
将工作目录更改为克隆的存储库。 | 运行如下命令:
| 云架构师 |
创建 Python 虚拟环境。 | 要创建 Python 虚拟环境,请运行以下命令:
| 云架构师 |
激活虚拟环境。 | 要激活虚拟环境,请运行以下命令:
| 云架构师 |
安装依赖项。 | 要安装 Python依赖项,请运行
| 云架构师 |
浏览代码。 | (可选)从 S3 存储桶下载对象的示例代码位于 基础设施代码位于 | 云架构师 |
| Task | 说明 | 所需技能 |
|---|---|---|
部署应用程序。 | 运行 写下 AWS CDK 输出:
| 云架构师 |
上传示例 JSON 文件。 | 该存储库包含一个约 9 KB 的示例 JSON 文件。要将该文件上传到已创建堆栈的 S3 存储桶,请运行以下命令:
| 云架构师 |
运行该应用程序。 | 要运行该应用程序,请执行以下操作:
| 云架构师 |
添加下载次数。 | (可选)要运行 1,500 次获取对象调用,请在
| 云架构师 |
| Task | 说明 | 所需技能 |
|---|---|---|
运行 AWS Lambda 电源调整工具。 |
运行结束时,结果将显示在执行输入和输出选项卡上。 | 云架构师 |
在图表中查看 AWS Lambda 功率调整结果。 | 在执行输入和输出选项卡上,复制 | 云架构师 |
| Task | 说明 | 所需技能 |
|---|---|---|
从 S3 存储桶中移除对象。 | 在销毁已部署的资源之前,请先从 S3 存储桶中移除所有对象:
记得 | 云架构师 |
销毁资源 | 要销毁为此试点创建的所有资源,请运行以下命令:
| 云架构师 |
故障排除
| 问题 | 解决方案 |
|---|---|
| 对于新账户,您的 Lambda 函数可能无法配置超过 3,008 MB 的内存。要使用 AWS Lambda Power Tuning 进行测试,请在开始执行 Step Functions 时在输入 JSON 处添加以下属性:
|
相关资源
附加信息
代码
以下代码片段执行并行 I/O 处理:
with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor: for result in executor.map(a_function, (the_arguments)): ...
当线程变为可用状态时,ThreadPoolExecutor 会重复使用这些线程。
测试和结果
这些测试是在 2024 年 12 月进行的。
第一次测试处理了 2,500 次对象读取操作,结果如下。
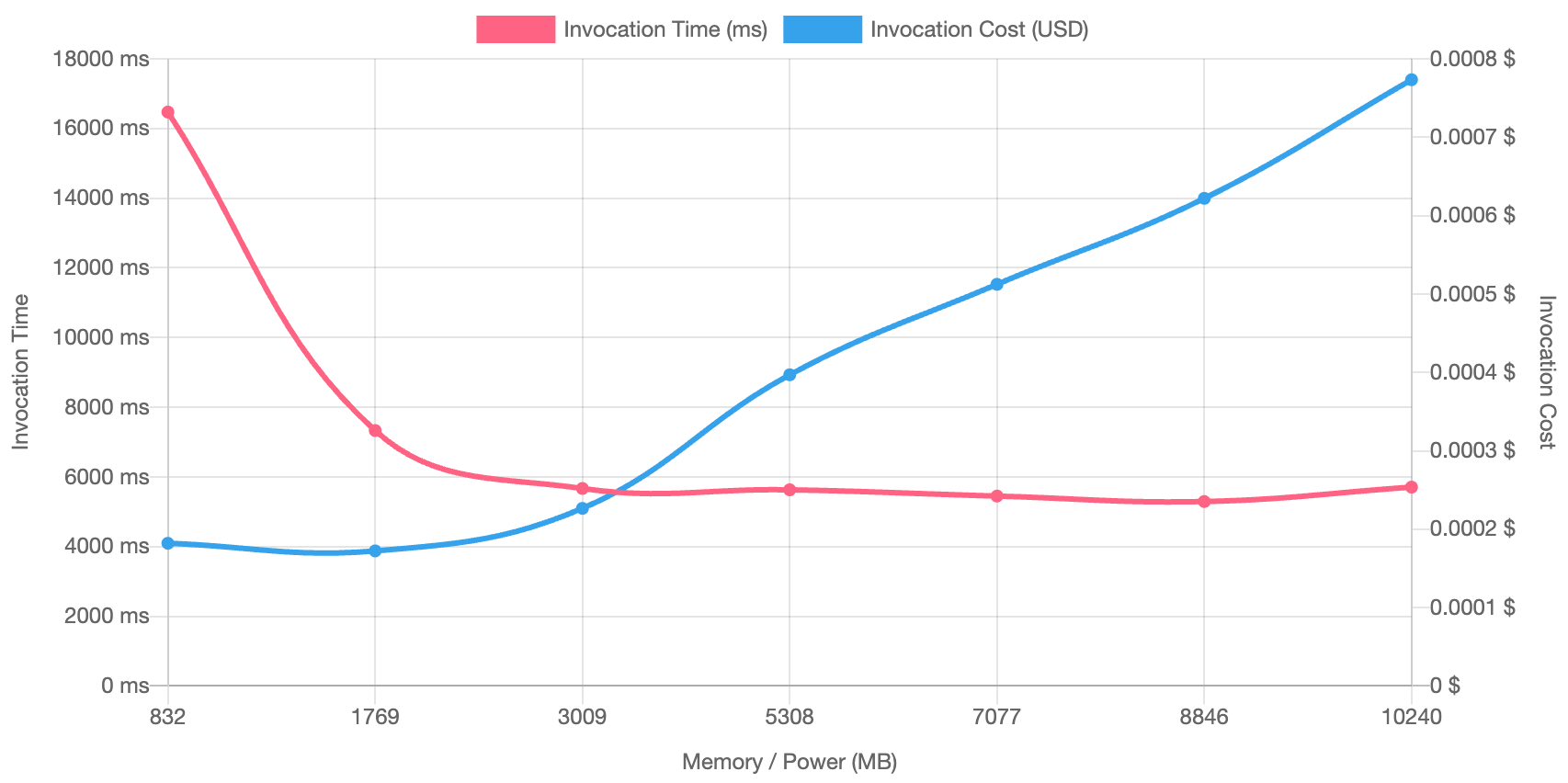
从 3,009 MB 开始,无论内存如何增加,处理时间基本保持不变,但成本会随着内存大小的增加而上升。
另一项测试调查 1,536 MB 至 3,072 MB 的内存范围,使用 256 MB 的倍数作为测试内存值,处理了 10,000 次对象读取操作,结果如下。

最佳 performance-to-cost比例是 2,304 MB 内存 Lambda 配置。
相比之下,2,500 次对象读取操作的串行处理耗时 47 秒。而使用 2,304 MB Lambda 配置的并行处理仅耗时 7 秒,时间缩短了 85%。

