本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用生成 Db2 z/OS 数据见解 AWS Mainframe Modernization 和 Quick Sight 中的 Amazon Q
Shubham Roy、Roshna Razack 和 Santosh Kumar Singh,Amazon Web Services
Summary
注意: AWS Mainframe Modernization 服务(托管运行时环境体验)不再向新客户开放。要获得与 AWS Mainframe Modernization 服务(托管运行时环境体验)相似的功能,请浏览 AWS Mainframe Modernization 服务(Self-Managed 体验)。现有客户可以继续正常使用该服务。有关更多信息,请参阅 AWS Mainframe Modernization 可用性变更。
如果组织在 IBM Db2 大型机环境中托管关键业务数据,那么从这些数据中获取见解对于推动增长和创新至关重要。通过解锁大型机数据,您可以构建更快、更安全的可扩展商业智能,从而加快 Amazon Web Services(AWS)云中数据驱动的决策、增长和创新。
这种模式提供了一种解决方案,用于生成业务见解,并根据 IBM Db2 中的大型机数据为表格创建可共享的叙述。 z/OS 通过采用 Precisely 的AWS Mainframe Modernization 数据复制功能,将大型机数据更改流式传输到 Amazon Managed Streaming for Apache Kafka(Amazon MSK)主题。使用 Amazon Redshift 串流摄取,Amazon MSK 主题数据可以存储在 Amazon Redshift Serverless 数据仓库表中,以便在 Amazon Quick Sight 中进行分析。
在 Quick Sight 中提供数据后,您可以使用自然语言提示和 Amazon Q in Quick Sight 创建数据摘要、提问并生成数据故事。您不必编写 SQL 查询或学习商业智能(BI)工具。
商业背景
此模式提供了一种解决方案,可用于大型机数据分析和数据见解使用案例。使用此模式,您可以为公司的数据构建可视化控制面板。为了演示解决方案,此模式以一家为美国成员提供医疗、牙科和视力计划的医疗保健公司为例。在此示例中,成员人口统计和计划信息存储在 z/OS 数据表的 IBM Db2 中。可视化控制面板显示以下信息:
按区域划分的成员分布
按性别划分的成员分布
按年龄划分的成员分布
按计划类型划分的成员分布
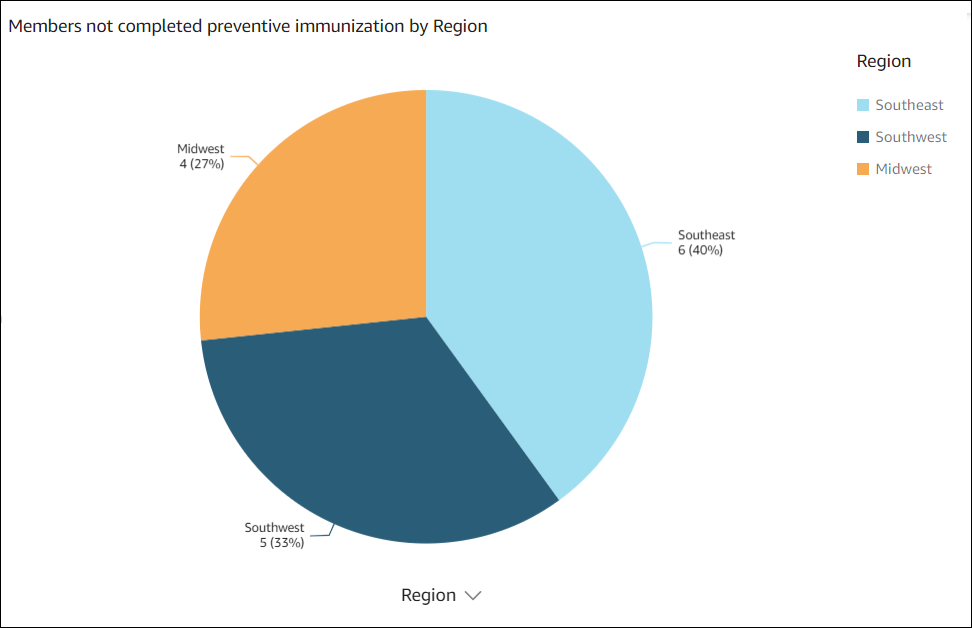
尚未完成预防性免疫接种的成员
有关按区域划分的成员分布和尚未完成预防性免疫接种的成员的示例,请参阅“其他信息”部分。
创建控制面板后,即可生成一个数据故事,其中会解释从先前分析得出的见解。数据故事就如何增加完成预防性免疫接种的成员人数提供了建议。
先决条件和限制
先决条件
活跃 AWS 账户的. 此解决方案在 Amazon Elastic Compute Cloud(Amazon EC2)的 Amazon Linux 2 上构建和测试。
一个虚拟私有云(VPC),其中具有可供大型机系统访问的子网。
一个包含业务数据的大型机数据库。有关用于构建和测试此解决方案的示例数据,请参阅附件部分。
在 Db2 z/OS 表上启用了更改数据捕获 (CDC)。要在 Db2 上启用 CDC z/OS,请参阅 IBM 文档。
Precission Connect CDC,用于 z/OS 安装在托管源数据库的 z/OS 系统上。用于 z/OS 映像的 Precission Connect CDC 在 IBM z/OS Amazon 机器映像的数据复制 (AMI) 中以 zip 文件形式提供。AWS Mainframe Modernization 要在大型机上安装 Precissi z/OS on Connect CDC,请参阅 Prec ist 安装文档。
限制
您的大型机 Db2 数据应采用 Precisely Connect CDC 支持的数据类型。有关支持的数据类型的列表,请参阅 Precisely Connect CDC 文档。
您在 Amazon MSK 上的数据应采用 Amazon Redshift 支持的数据类型。有关支持的数据类型的列表,请参阅 Amazon Redshift 文档。
Amazon Redshift 针对不同的数据类型有不同的行为和大小限制。有关更多信息,请参阅 Amazon Redshift 文档。
Quick Sight 中的近乎实时的数据取决于为 Amazon Redshift 数据库设置的刷新间隔。
有些 AWS 服务 并非全部可用 AWS 区域。有关区域可用性,请参阅按区域划分的AWS 服务。Amazon Q in Quick Sight 目前并非在每个支持 Quick Sight 的区域都可用。有关特定端点,请参阅服务端点和配额页面,然后选择相应服务的链接。
产品版本
架构
目标架构
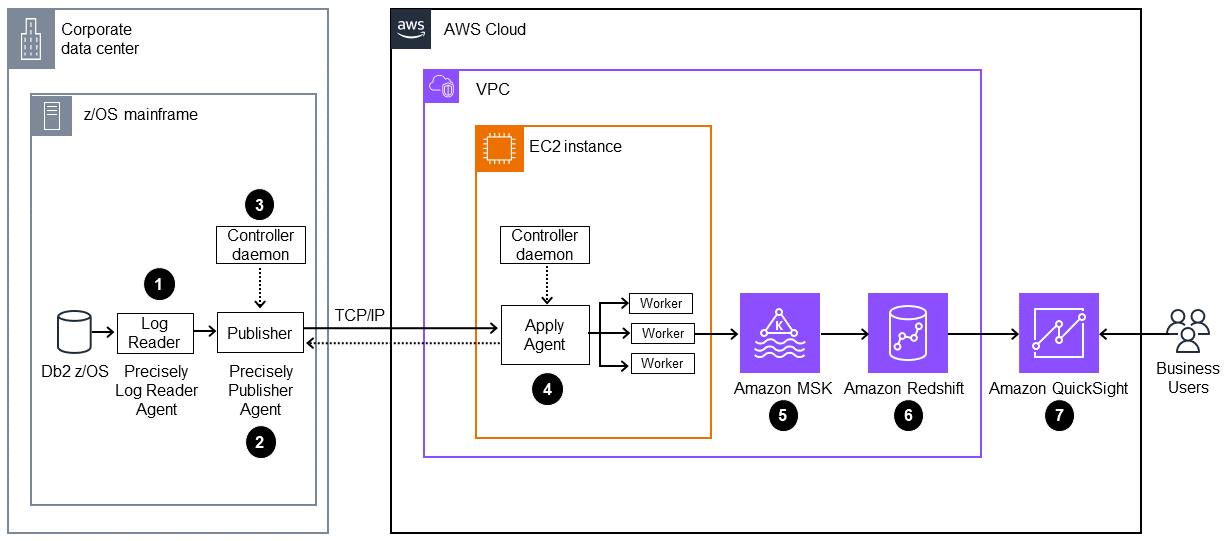
下图显示了一种架构,该架构可使用采用 Precisely 的AWS Mainframe Modernization 数据复制功能和 Amazon Q in Quick Sight,从大型机数据中生成业务见解。
下图显示了如下工作流:
Precisely Log Reader Agent 可从 Db2 日志中读取数据,并将数据写入大型机上的 OMVS 文件系统的临时存储中。
Publisher Agent 可从临时存储中读取原始 Db2 日志。
本地控制器进程守护程序可对操作进行身份验证、授权、监控和管理。
Apply Agent 可通过预配置的 AMI 部署在 Amazon EC2。它使用 TCP/IP控制器守护程序与发布者代理连接。Apply Agent 使用多个工作程序将数据推送至 Amazon MSK,以实现高吞吐量。
这些工作程序会以 JSON 格式将数据写入 Amazon MSK 主题。作为复制消息的中间目标,Amazon MSK 可提供高度可用的自动失效转移功能。
Amazon Redshift 串流摄取功能以低延迟、高速度的方式完成从 Amazon MSK 到 Amazon Redshift Serverless 的数据摄取。Amazon Redshift 中的存储过程将大型机更改数据(insert/update/删除)协调到亚马逊 Redshift 表中。这些 Amazon Redshift 表可充当 Quick Sight 的数据分析来源。
用户在 Quick Sight 中访问数据,以获得分析和见解。您可以使用 Amazon Q in Quick Sight 通过自然语言提示与数据进行交互。
工具
AWS 服务
其他工具
代码存储库
此模式的代码可在 GitHub Mainframe_DataInsights_change_data_reconciliation存储库中找到。此代码是 Amazon Redshift 中的存储过程。此存储过程将大型机数据更改(插入、更新和删除)从 Amazon MSK 调整至 Amazon Redshift 表中。这些 Amazon Redshift 表可充当 Quick Sight 的数据分析来源。
最佳实践
操作说明
| Task | 说明 | 所需技能 |
|---|
设置安全组。 | 要连接到控制器进程守护程序和 Amazon MSK 集群,请为 EC2 实例创建安全组。添加以下入站和出站规则: 入站规则 1: 入站规则 2: 对于类型,选择自定义 TCP。 对于协议,选择 SSH。 对于端口范围,选择 22。 对于源,选择 IP 地址或前缀列表。
入站规则 3: 对于类型,选择自定义 TCP。 对于协议,选择 TCP。 对于端口范围,选择 9092-9098。 对于源,选择 CIDR 数据块。
出站规则 1: 对于类型,选择自定义 TCP。 对于协议,选择 TCP。 对于端口范围,选择 9092-9098。 对于源,选择 CIDR 数据块。
出站规则 2:
记下安全组的名称。启动 EC2 实例并配置 Amazon MSK 集群时,您需要引用该名称。 | DevOps 工程师,AWS DevOps |
创建 IAM 策略和 IAM 角色。 | 要创建 IAM 策略和IAM 角色,请按照 AWS 文档中的说明进行操作。 创建 IAM 策略可授予在 Amazon MSK 集群上创建主题以及向这些主题发送数据的访问权限。 创建 IAM 角色后,将此策略与其关联。记下 IAM 角色名称。您启动 EC2 实例时,此角色将用作 IAM 实例配置文件。
| DevOps 工程师,AWS 系统管理员 |
预调配 EC2 实例。 | 要预调配 EC2 实例以运行 Preclist CDC 并连接到 Amazon MSK,请执行以下操作: | AWS 管理员、 DevOps 工程师 |
| Task | 说明 | 所需技能 |
|---|
创建 Amazon MSK 集群。 | 要创建 Amazon MSK 集群,请执行以下操作: 登录并导航至 Amazon MSK。 AWS 管理控制台 选择创建集群。 对于集群创建方法,选择自定义创建;对于集群类型,选择已预调配。 为群集提供一个名称。 根据需要更新集群设置,对于其他设置,则保留默认值。 记下 <Kafka 版本>。 您在 Kafka 客户端设置过程中需要用到它。 选择下一步。 选择您与用于 Precisely EC2 实例相同的 VPC 和子网,然后选择您之前创建的安全组。 在 “安全设置” 部分中,同时启用SASL/SCRAM和基于 IAM 角色的身份验证。Precissift Connect CDC 使用 SASL/SCRAM (简单身份验证和安全层/加盐质询响应机制),连接亚马逊 Redshift 需要 IAM。 选择下一步。 要进行查看,请选择监控和代理日志传输方法。 选择下一步,然后选择创建集群。
创建典型的预调配集群耗时最多 15 分钟。创建集群后,其状态将由正在创建更改为活跃。 | AWS DevOps,云管理员 |
设置 SASL/SCRAM 身份验证。 | 要为 Amazon MSK 集群设置 SASL/SCRAM 身份验证,请执行以下操作: 要在 Secrets Manager 中设置密钥,请按照 AWS 文档中的说明进行操作。 打开 Amazon MSK 控制台,然后选择您之前创建的 Amazon MSK 集群。 选择属性选项卡。 选择关联密钥、选择密钥,选择您创建的密钥,然后选择关联密钥。 您将看到与以下内容类似的成功消息: Successfully associated 1 secret for cluster <chosen cluster name>
选择集群名称。 在集群摘要部分,选择查看客户端信息。 记下身份验证类型的私有端点连接字符串 SASL/SCRAM。
| 云架构师 |
创建 Amazon MSK 主题。 | 要创建 Amazon MSK 主题,请执行以下操作: 连接到您之前创建的 EC2 实例,然后运行以下命令安装最新更新: sudo yum update -y
运行以下命令,安装 Java 和 Kafka 库: sudo yum install -y java-11 librdkafka librdkafka-devel
要在 /home/ec2-user 中创建名为 kafka 的文件夹,请导航至该文件夹,然后运行以下命令: mkdir kafka;cd kafka
将 kafka 客户端库下载到 kafka 文件夹,并将 <YOUR MSK VERSION> 替换为您在创建 Amazon MSK 集群过程中记下的 Kafka 版本: wget https://archive.apache.org/dist/kafka//kafka_2.13-<YOUR MSK VERSION>.tgz
要提取下载的文件,请运行以下命令,替换 YOUR MSK VERSION>: tar -xzf kafka_2.13-<YOUR MSK VERSION>.tgz
要导航到 kafka libs 目录并下载 Java IAM 身份验证 Java 存档(JAR)文件,请运行以下命令,替换 <YOUR MSK VERSION>: cd kafka_2.13-<YOUR MSK VERSION>/libs
wget https://github.com/aws/aws-msk-iam-auth/releases/download/v1.1.1/aws-msk-iam-auth-1.1.1-all.jarkafka
要导航到 Kafka bin 目录并创建 client.properties 文件,请运行以下命令: cd /home/ec2-user/kafka/kafka_2.13-<YOUR MSK VERSION>/bin
cat >client.properties
使用以下内容更新 client.properties 文件: security.protocol=SASL_SSL
sasl.mechanism=AWS_MSK_IAM
sasl.jaas.config=software.amazon.msk.auth.iam.IAMLoginModule required;
sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandler
要创建 Kafka 主题,请导航到 Kafka bin 并运行以下命令,将 <kafka broker> 替换为创建 Amazon MSK 集群时记下的 IAM 引导服务器私有端点: ./kafka-topics.sh --bootstrap-server <kafka broker> --command-config client.properties --create --replication-factor 3 —partitions 6 --topic <topic name>
当显示消息 Created topic <topic name> 时,记下主题名称。
| 云管理员 |
| Task | 说明 | 所需技能 |
|---|
设置 Precisely 脚本以复制数据更改。 | 要设置 Precisely Connect CDC 脚本以将更改后的数据从大型机复制到 Amazon MSK 主题,请执行以下操作: 要精确创建文件夹名称,请导航至该文件夹,然后运行以下命令: mkdir /home/ec2-user/precisely;cd /home/ec2-user/precisely
要在其中精确创建两个分别名为 scripts 和 ddls 的文件夹,然后更改为 scripts 文件夹,请运行以下命令: mkdir scripts;mkdir ddls;cd scripts
要在 scripts 文件夹中创建名为 sqdata_kafka_producer.conf 的文件,请运行以下命令: cat >sqdata_kafka_producer.conf
使用以下内容更新 sqdata_kafka_producer.conf 文件: builtin.features=SASL_SCRAM
security.protocol=SASL_SSL
sasl.mechanism=SCRAM-SHA-512
sasl.username=<User Name>
sasl.password=<Password>
metadata.broker.list=<SASL/SCRAM Bootstrap servers>
<SASL/SCRAM Bootstrap servers>使用您之前配置的 Amazon MSK SASL/SCRAM 代理列表进行更新。使用您之前在 Secrets Manager 中设置的用户名和密码更新 <User Name> 和 <Password>。
在 scripts 文件夹中创建 script.sqd 文件。 cat >script.sqd
Apply Engine 使用 script.sqd 来处理源数据并将源数据复制到目标。有关 Apply Engine 脚本的示例,请参阅其他信息部分。 要更改为 ddls 文件夹并为每个 Db2 表创建一个 .ddl 文件,请运行以下命令: cd /home/ec2-user/precisely/ddls
cat >mem_details.ddl
cat >mem_plans.ddl
有关 .ddl 文件的示例,请参阅其他信息部分。 | 应用程序开发人员、云架构师 |
生成网络 ACL 密钥。 | 要生成网络访问控制列表密钥,请执行以下操作: 要导出 sqdata 安装路径,请运行以下命令: export PATH=$PATH:/usr/sbin:/opt/precisely/di/sqdata/bin
要更改为 /home/ec2-user 目录并生成网络 ACL 密钥,请运行以下命令: cd /home/ec2-user
sqdutil keygen --force
生成公有和私有密钥后,将显示以下消息: SQDUT04I Generating a private key in file /home/ec2-user/.nacl/id_nacl
SQDC017I sqdutil(pid=27344) terminated successfully
记下存储在 .nacl 文件夹中的生成的公有密钥。
| AWS 云架构师 DevOps |
| Task | 说明 | 所需技能 |
|---|
在 ISPF 屏幕中配置默认值。 | 要在 Interactive System Productivity Facility(ISPF)中配置默认设置,请按照 Precisely 文档中的说明进行操作。 | 大型机系统管理员 |
配置控制器进程守护程序。 | 要配置控制器进程守护程序,请执行以下操作: 在 SQData z/OS 主菜单屏幕上,选择选项 2。 在将进程守护程序添加到列表屏幕上的进程守护程序名称字段中,输入进程守护程序的名称,然后按 Enter 键。
| 大型机系统管理员 |
配置发布者。 | 要配置发布者,请执行以下操作: 在 SQData z/OS 主菜单屏幕上,选择选项 3。这会将您带到 “Capture/Publisher 摘要” 屏幕。 选择该选项以添加 CAB 文件。这会将您引导至 将 CAB 文件添加到列表屏幕。 在名称字段中,输入 CAB 文件的名称。对于 Db2,将类型字段输入为 D。 按 Enter 键。这会将您引导至创建新的 Db2 Capture CAB 文件屏幕。 在 zFS 目录字段中,指定存储挂载点。 按 Enter 保存并继续。
| 大型机系统管理员 |
更新进程守护程序配置文件。 | 要更新控制器进程守护程序配置文件中的发布者详细信息,请执行以下操作: 在 SQData z/OS 主菜单屏幕上,选择选项 2。 在您创建的进程守护程序附近输入 S,以查看进程守护程序的详细信息。 输入 1,然后按 Enter 键编辑代理文件。 添加 CAB 文件详细信息。以下示例显示了名为 DB2ZTOMSK 的 CAB 文件的详细信息。使用您的大型机用户 ID 而不是 <userid>。 ÝDB2ZTOMSK¨
type=capture
cab=/u/<userid>/sqdata/DB2ZTOMSK.cab
按 F3。 输入 2 以编辑 ACL 文件。将 userid 添加到 acl 配置文件,如以下示例所示: Ýacls¨
prod=admin,<userid>
按 F3 保存并退出。
| 大型机系统管理员 |
创建启动控制器进程守护程序的任务。 | 要创建任务,请执行以下操作: 在选项中,输入 G。 输入任务卡、任务和程序库以及 Db2 load 库详细信息。 输入网络 ACL 文件详细信息,然后输入选项 2,以在指定的任务库中生成任务控制语言(JCL)文件。
| 大型机系统管理员 |
生成捕获发布者 JCL 文件。 | 要生成捕获发布者 JCL 文件,请执行以下操作: 在 SQData z/OS 主菜单屏幕上,选择选项 3。这会将您带到 “Capture/Publisher 摘要” 屏幕。 在 CAB 文件旁边输入 S 以将其选中。这将带您进入 Db2 Capture/Publisher 详细信息屏幕。 在选项中,输入 G 以生成 capture/publisher 任务。 输入任务卡、任务和程序库以及 Db2 负载库详细信息。 要创建任务,选择选项 4。该任务是在任务库中指定的任务库中创建的。
| 大型机系统管理员 |
检查并更新 CDC。 | 运行以下查询,检查 Db2 表的 DATACAPTURE 标志,并将 <table name> 更改为您的 Db2 表名称: SELECT DATACAPTURE FROM SYSIBM.SYSTABLES WHERE NAME='<table name>';
确认结果显示 DATACAPTURE 为 Y。 如果 DATACAPTURE 不是 Y,请运行以下查询,以在 Db2 表上启用 CDC,并将 <table name> 更改为您的 Db2 表名称: ALTER TABLE <table name> DATA CAPTURE CHANGES;
| 大型机系统管理员 |
提交 JCL 文件。 | 提交在先前步骤中配置的以下 JCL 文件: 启动控制器进程守护程序的 JCL 文件 启动捕获和发布的 JCL 文件
提交 JCL 文件后,您可以在 EC2 实例上启动 Apply Engine in Precisely。 | 大型机系统管理员 |
| Task | 说明 | 所需技能 |
|---|
启动 Apply Engine 并验证 CDC。 | 要在 EC2 实例上启动 Apply Engine 并验证 CDC,请执行以下操作: 要连接到 EC2 实例,请按照 AWS 文档中的说明进行操作。 更改为包含 script.sqd 文件的目录: cd /home/ec2-user/precisely/scripts
要启动 Apply Engine,请运行以下 sqdeng 启动命令: sqdeng -s script.sqd --identity=/home/ec2-user/.nacl/id_nacl
Apply Engine 将开始等待来自大型机源的更新。 要测试 CDC,请在 Db2 表中进行一些记录插入或更新操作。 验证 Apply Engine 日志是否显示已捕获并写入目标的记录数。
| 云架构师、应用程序开发人员 |
验证 Amazon MSK 主题上的记录。 | 要读取 Kafka 主题中的消息,请执行以下操作: 要更改到 EC2 实例上 Kafka 客户端安装路径的 bin 目录,请运行以下命令,将 <Kafka version> 替换为您的版本: cd /home/ec2-user/kafka/kafka_2.13-<Kafka version>/bin
要验证 Kafka 主题中以消息形式写入的 Db2 CDC,请运行以下命令,将 <kafka broker> 和 <Topic Name> 替换为之前创建的主题: ./kafka-console-consumer.sh --bootstrap-server <kafka broker>:9098 --topic <Topic Name> --from-beginning --consumer.config client.properties
验证消息数是否与 Db2 表中更新的记录数匹配。
| 应用程序开发人员、云架构师 |
| Task | 说明 | 所需技能 |
|---|
设置 Amazon Redshift Serverless。 | 要创建 Amazon Redshift Serverless 数据仓库,请按照 AWS 文档中的说明进行操作。 在 Amazon Redshift Serverless 控制面板上,验证命名空间和工作组是否已创建并可用。对于此示例模式,该过程可能需要耗费 2‒5 分钟的时间。 | 数据工程师 |
设置串流摄取所需的 IAM 角色和信任策略。 | 要设置来自 Amazon MSK 的 Amazon Redshift Serverless 串流摄取,请执行以下操作: 为 Amazon Redshift 创建访问 Amazon MSK 的 IAM 策略。 [region]使用 AWS 区域 适用于 Amazon MSK 的、[account-id]您的 AWS 账户 ID 和 [msk-cluster-name] Amazon MSK 集群名称替换,运行以下代码:
{"Version": "2012-10-17", "Statement": [{"Sid": "MSKIAMpolicy","Effect": "Allow","Action": ["kafka-cluster:ReadData","kafka-cluster:DescribeTopic","kafka-cluster:Connect"],"Resource": ["arn:aws:kafka:[region]:[account-id]:cluster/[msk-cluster-name]/*","arn:aws:kafka:[region]:[account-id]:topic/[msk-cluster-name]/*"]},{"Effect": "Allow","Action": ["kafka-cluster:AlterGroup","kafka-cluster:DescribeGroup"],"Resource": ["arn:aws:kafka:[region]:[account-id]:group/[msk-cluster-name]/*"]}]}
您可以在 Amazon MSK 控制台上找到集群名称和 Amazon 资源名称(ARN)。在控制台上,选择集群摘要,然后选择 ARN。 要创建 IAM 角色并附加策略,请按照 AWS 文档中的说明进行操作。 要将 IAM 角色附加到 Amazon Redshift Serverless 命名空间,请执行以下操作: 在您的 Amazon Redshift Serverless 安全组中,创建一条包含以下详细信息的入站规则: 对于类型,选择自定义 TCP。 对于协议,选择 TCP。 对于端口范围,选择 9098、9198。 对于源,选择 Amazon MSK 安全组。
在您的 Amazon MSK 安全组中,创建一条包含以下详细信息的入站规则: 此模式使用的端口适用于 Amazon Redshift 和 Amazon MSK 配置的 IAM 身份验证。有关更多信息,请参阅 AWS 文档(步骤 2)。 为 Amazon Redshift Serverless 工作组开启增强型 VPC 路由。有关详情,请参阅 AWS 文档。
| 数据工程师 |
将 Amazon Redshift Serverless 连接到 Amazon MSK。 | 要连接到 Amazon MSK 主题,请在 Amazon Redshift Serverless 中创建一个外部架构。在 Amazon Redshift 查询编辑器 v2 中,运行以下 SQL 命令,将 'iam_role_arn' 替换为您之前创建的角色,将 'MSK_cluster_arn' 替换为集群的 ARN。 CREATE EXTERNAL SCHEMA member_schema
FROM MSK
IAM_ROLE 'iam_role_arn'
AUTHENTICATION iam
URI 'MSK_cluster_arn';
| 迁移工程师 |
创建实体化视图。 | 要在 Amazon Redshift Serverless 中使用来自 Amazon MSK 主题的数据,请创建实体化视图。在 Amazon Redshift 查询编辑器 v2 中,运行以下 SQL 命令,将 <MSK_Topic_name> 替换为您的 Amazon MSK 主题的名称。 CREATE MATERIALIZED VIEW member_view
AUTO REFRESH YES
AS SELECT
kafka_partition,
kafka_offset,
refresh_time,
json_parse(kafka_value) AS Data
FROM member_schema.<MSK_Topic_name>
WHERE CAN_JSON_PARSE(kafka_value);
| 迁移工程师 |
在 Amazon Redshift 中创建目标表。 | Amazon Redshift 表为 Quick Sight 提供了输入。此模式使用表 member_dtls 和 member_plans,这两个表可与大型机上的源 Db2 表匹配。 要在 Amazon Redshift 中创建这两个表,请在 Amazon Redshift 查询编辑器 V2 中运行以下 SQL 命令: -- Table 1: members_dtls
CREATE TABLE members_dtls (
memberid INT ENCODE AZ64,
member_name VARCHAR(100) ENCODE ZSTD,
member_type VARCHAR(50) ENCODE ZSTD,
age INT ENCODE AZ64,
gender CHAR(1) ENCODE BYTEDICT,
email VARCHAR(100) ENCODE ZSTD,
region VARCHAR(50) ENCODE ZSTD
) DISTSTYLE AUTO;
-- Table 2: member_plans
CREATE TABLE member_plans (
memberid INT ENCODE AZ64,
medical_plan CHAR(1) ENCODE BYTEDICT,
dental_plan CHAR(1) ENCODE BYTEDICT,
vision_plan CHAR(1) ENCODE BYTEDICT,
preventive_immunization VARCHAR(50) ENCODE ZSTD
) DISTSTYLE AUTO;
| 迁移工程师 |
在 Amazon Redshift 中创建存储过程。 | 此模式使用存储过程将源大型机的更改数据(INSERT、UPDATE、DELETE)同步到目标 Amazon Redshift 数据仓库表,以便在 Quick Sight 中进行分析。 要在 Amazon Redshift 中创建存储过程,请使用查询编辑器 v2 运行存储库中的存储过程代码。 GitHub | 迁移工程师 |
从流式实体化视图中读取,并加载到目标表中。 | 存储过程会从流式实体化视图中读取数据更改,并将数据更改加载到目标表中。要运行存储过程,您可以使用以下命令: call SP_Members_Load();
您可以使用 Amazon EventBridge 在 Amazon Redshift 数据仓库中安排任务,以便根据您的数据延迟要求调用此存储过程。 EventBridge 以固定的间隔运行作业。要监控先前对该过程的调用是否已完成,您可能需要使用诸如 AWS Step Functions 状态机之类的机制。有关更多信息,请参阅以下资源: 另一个选项是使用 Amazon Redshift 查询编辑器 v2 安排刷新。有关更多信息,请参阅使用查询编辑器 v2 计划查询。 | 迁移工程师 |
| Task | 说明 | 所需技能 |
|---|
设置 Quick Sight。 | 要设置 Quick Sight,请按照 AWS 文档中的说明进行操作。 | 迁移工程师 |
在 Quick Sight 和 Amazon Redshift 之间建立安全连接。 | 要在 Quick Sight 和 Amazon Redshift 之间建立安全连接,请执行以下操作 要授权从 Quick Sight 到 Amazon Redshift 的连接,请打开 Amazon Redshift 控制台,然后在 Amazon Redshift 安全组中添加入站规则。该规则应允许来自您设置 Quick Sight 的 CIDR 范围的流量进入端口 5439(默认的 Redshift 端口)。有关 AWS 区域 及其的 IP 地址的列表,请参阅 Quick AWS 区域 Sight 支持。 在 Amazon Redshift 控制台上,选择工作组、数据访问、网络和安全,然后启用可公开访问。
| 迁移工程师 |
为 Quick Sight 创建数据集。 | 要通过 Amazon Redshift 为 Quick Sight 创建数据集,请执行以下操作: 在 Quick Sight 控制台的导航窗格中,选择数据集。 在数据集页面上,选择新数据集。 选择 Redshift 手动连接。 在新的 Redshift 数据来源窗口中,输入连接信息: 对于数据来源名称,输入 Amazon Redshift 数据来源的名称。 对于数据库服务器,请输入 Amazon Redshift 集群的端点。从 Amazon Redshift Serverless 控制面板上集群工作组的一般信息部分的端点字段中,您可以获取端点值。服务器地址是端点中冒号之前的第一部分,如以下示例所示: mfdata-insights.NNNNNNNNN.us-east-1.redshift-serverless.amazonaws.com:5439/dev
对于端口,输入 5439(Amazon Redshift 的默认端口)。 输入数据库的名称(端点中的斜杠之后)。在这种情况下,数据库名称为 dev。 在用户名和密码,输入 Amazon Redshift 数据库的用户名和密码。
选择验证连接。如果成功,您应该会看到一个绿色复选标记,表示已验证。如果验证失败,请参阅问题排查部分。 选择创建数据来源。
| 迁移工程师 |
联接数据集。 | 要在 Quick Sight 中创建分析,请按照 AWS 文档中的说明将这两个表联接起来。 在联接配置窗格中,对于联接类型,选择左。在联接子句下,使用 memberid from member_plans = memberid from members_details。 | 迁移工程师 |
| Task | 说明 | 所需技能 |
|---|
设置 Amazon Q in Quick Sight。 | 要设置 Amazon Q in Quick Sight 生成式商业智能功能,请按照 AWS 文档中的说明进行操作。 | 迁移工程师 |
分析大型机数据并构建可视化控制面板。 | 要在 Quick Sight 中对数据进行分析和可视化,请执行以下操作: 要创建大型机数据分析,请按照 AWS 文档中的说明进行操作。对于数据集,选择您创建的数据集。 在分析页面上,选择构建视觉对象。 在创建分析主题窗口中,选择更新现有主题。 在选择主题下拉列表中,选择您之前创建的主题。 选择主题链接。 链接主题后,选择构建视觉对象,以打开 Amazon Q 构建视觉对象窗口。 在提示栏中,写下您的分析问题。此模式使用的示例问题如下: 显示按区域划分的成员分布 显示按年龄划分的成员分布 显示按性别划分的成员分布 显示按计划类型划分的成员分布 显示尚未完成预防性免疫接种的成员
输入问题后,选择构建。Amazon Q in Quick Sight 可创建视觉对象。 要将视觉对象添加到可视化控制面板,请选择添加到分析。
完成后,您可以发布自己的控制面板,以便与组织中的其他人共享。有关示例,请参阅其他信息部分中的大型机可视化控制面板。 | 迁移工程师 |
| Task | 说明 | 所需技能 |
|---|
创建数据故事。 | 创建数据故事以解释先前分析的见解,并就增加完成预防性免疫接种的成员人数生成建议: 要创建数据故事,请按照 AWS 文档中的说明进行操作。 对于数据故事提示,请使用以下操作: Build a data story about Region with most numbers of members. Also show the member distribution by medical plan, vision plan, dental plan. Recommend how to motivate members to complete immunization. Include 4 points of supporting data for this pattern.
您还可以构建自己的提示,以为其他业务见解生成数据故事。 选择添加视觉对象,然后添加与数据故事相关的视觉对象。对于此模式,请使用您之前创建的视觉对象。 选择构建。 有关数据故事输出的示例,请参阅其他信息部分中的数据故事输出。
| 迁移工程师 |
查看生成的数据故事。 | 要查看生成的数据故事,请在数据故事页面上选择该故事。 | 迁移工程师 |
编辑生成的数据故事。 | 要更改数据故事中的格式、布局或视觉对象,请按照 AWS 文档中的说明进行操作。 | 迁移工程师 |
共享数据故事。 | 要共享数据故事,请按照 AWS 文档中的说明进行操作。 | 迁移工程师 |
问题排查
| 问题 | 解决方案 |
|---|
对于从 Quick Sight 到 Amazon Redshift 的数据集创建,Validate Connection 已经失败了。 | 确认附加到 Amazon Redshift Serverless 实例的安全组允许来自与您设置 Quick Sight 的区域关联的 IP 地址范围的入站流量。 确认已部署 Amazon Redshift Serverless 的 VPC 公开可用。 确认您使用了正确的 Amazon Redshift 用户名和密码。您可以在 Amazon Redshift 控制台上重置用户名和密码。
|
尝试在 EC2 实例上启动 Apply Engine 时会返回以下错误: -bash: sqdeng: command not found
| 运行以下命令,导出 sqdata 安装路径: export PATH=$PATH:/usr/sbin:/opt/precisely/di/sqdata/bin
|
尝试启动 Apply Engine 时会返回以下连接错误之一: SQDD018E Cannot connect to transfer socket(rc==0x18468). Agent:<Agent Name > Socket:/u/./sqdata/.DB2ZTOMSK.cab.data
SQDUR06E Error opening url cdc://<VPC end point name>:2626/DB2ZTOMSK/DB2ZTOMSK : errno:1128 (Unknown error 1128)
| 检查大型机假脱机,以确认控制器进程守护程序任务正在运行。 |
相关资源
附加信息
示例 .ddl 文件
成员_details.ddl
CREATE TABLE MEMBER_DTLS (
memberid INTEGER NOT NULL,
member_name VARCHAR(50),
member_type VARCHAR(20),
age INTEGER,
gender CHAR(1),
email VARCHAR(100),
region VARCHAR(20)
);
member_plans.ddl
CREATE TABLE MEMBER_PLANS (
memberid INTEGER NOT NULL,
medical_plan CHAR(1),
dental_plan CHAR(1),
vision_plan CHAR(1),
preventive_immunization VARCHAR(20)
);
示例 .sqd 文件
将 <kafka topic name> 替换为您的 Amazon MSK 主题名称。
script.sqd
-- Name: DB2ZTOMSK: DB2z To MSK JOBNAME DB2ZTOMSK;REPORT EVERY 1;OPTIONS CDCOP('I','U','D');-- Source Descriptions
JOBNAME DB2ZTOMSK;
REPORT EVERY 1;
OPTIONS CDCOP('I','U','D');
-- Source Descriptions
BEGIN GROUP DB2_SOURCE;
DESCRIPTION DB2SQL /var/precisely/di/sqdata/apply/DB2ZTOMSK/ddl/mem_details.ddl AS MEMBER_DTLS;
DESCRIPTION DB2SQL /var/precisely/di/sqdata/apply/DB2ZTOMSK/ddl/mem_plans.ddl AS MEMBER_PLANS;
END GROUP;
-- Source Datastore
DATASTORE cdc://<zos_host_name>/DB2ZTOMSK/DB2ZTOMSK
OF UTSCDC
AS CDCIN
DESCRIBED BY GROUP DB2_SOURCE ;
-- Target Datastore(s)
DATASTORE 'kafka:///<kafka topic name>/key'
OF JSON
AS TARGET
DESCRIBED BY GROUP DB2_SOURCE;
PROCESS INTO TARGET
SELECT
{
REPLICATE(TARGET)
}
FROM CDCIN;
大型机可视化控制面板
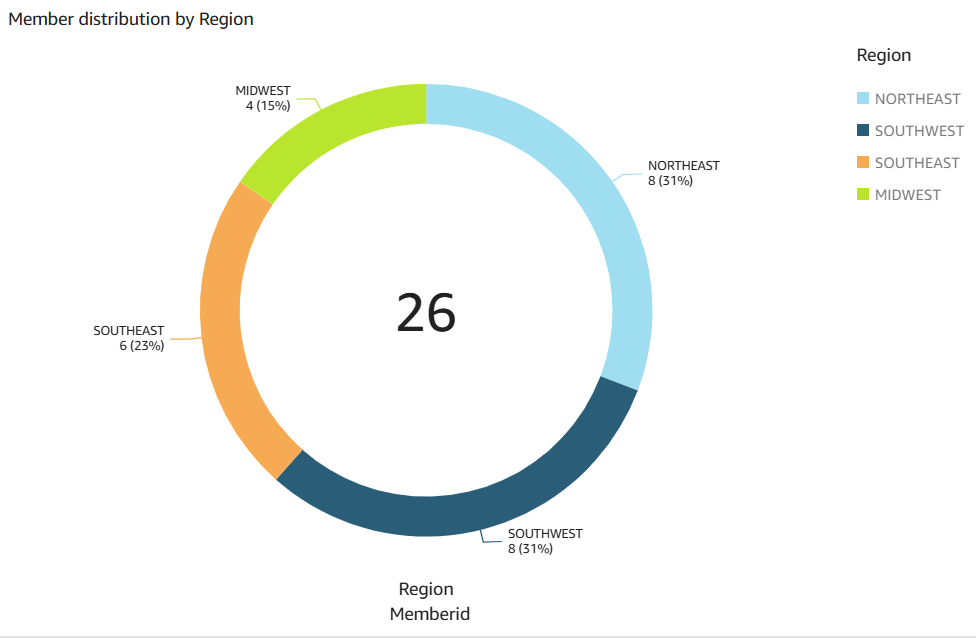
以下数据视觉对象由 Amazon Q in Quick Sight 创建,可用于分析问题 show member distribution by region。
以下数据视觉对象由 Amazon Q in Quick Sight 创建,可用于分析问题 show member distribution by Region who have not completed preventive immunization, in pie chart。
数据故事输出
以下屏幕截图显示了 Amazon Q in Quick Sight 为提示 Build a data story about Region with most numbers of members. Also show the member distribution by age, member distribution by gender. Recommend how to motivate members to complete immunization. Include 4 points of supporting data for this pattern 创建的数据故事的部分。
在简介中,数据故事建议选择成员人数最多的区域,以便免疫接种工作取得最大成效。
该数据故事分析了这四个区域的成员人数。东北、西南和东南地区的成员最多。
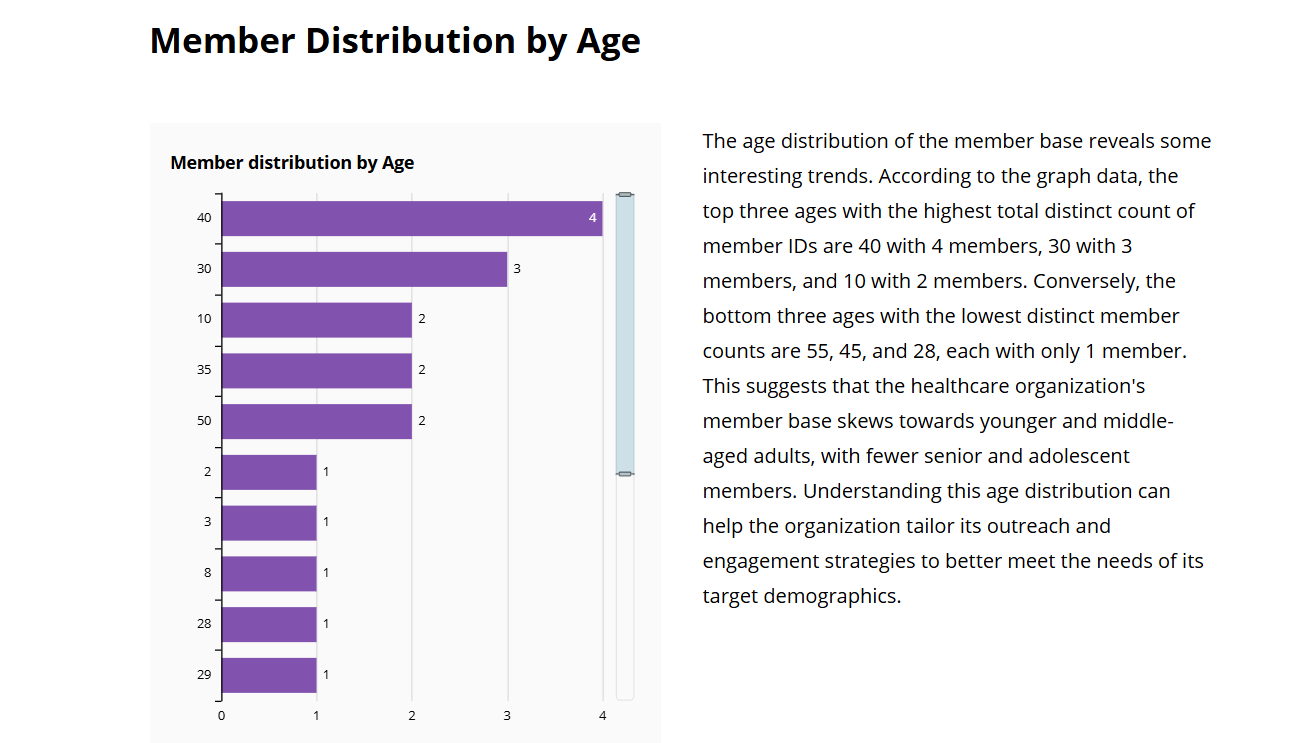
该数据故事提供了按年龄划分的成员的分析情况。
该数据故事重点关注中西部的免疫接种工作。
附件
要访问与此文档关联的其他内容,请下载并解压缩以下文件:attachment.zip