本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
在 Amazon A SageMaker I Studio Lab 中使用 Deepar 计算时间序列构建冷启动预测模型
Ivan Cui 和 Eyal Shacham,Amazon Web Services
Summary
无论您是为了更有效地为网络流量分配资源,预测患者对人员配备需求的需求,还是预测公司产品的销售,预测都是必不可少的工具。冷启动预测可以对几乎没有历史数据的时间序列进行预测,例如刚进入零售市场的新产品。这种模式使用 Amazon SageMaker AI Deepar 预测算法来训练冷启动预测模型,并演示如何对冷启动项目进行预测。
DeepAR 是一种有监督学习算法,可使用递归神经网络(RNN)来预测标量(一维)时间序列。DeepAR 采用的方法是在相关产品的所有时间序列上,联合训练单个模型。
传统的时间序列预测方法,如自回归积分滑动平均模型(ARIMA)或指数平滑法(ETS),在很大程度上依赖单个产品各自的历史时间序列。因此,这些方法对冷启动预测无效。当您的数据集包含数百个相关的时间序列时,DeepAR 要优于标准 ARIMA 和 ETS 方法。您还可以使用训练过的模型来生成与已训练过的时间序列相似的新时间序列的预测。
先决条件和限制
先决条件
活跃 AWS 账户的.
亚马逊 A SageMaker I 域名。
亚马逊 A SageMaker I Studio 实验室或 Jupiter 实验室应用程序。
一个拥有读写权限的 Amazon Simple Storage Service(Amazon S3)存储桶。
在 Python 编程的知识。
使用 Jupyter Notebook 的知识。
限制
在没有任何历史数据点的情况下调用预测模型将会返回错误。使用最少的历史数据点调用模型将返回高置信度但不准确的预测。此模式为解决冷启动预测的这些已知局限性提供了一种方法。
有些 AWS 服务 并非全部可用 AWS 区域。有关区域可用性,请参阅按区域划分的 AWS 服务
。有关特定端点,请参阅服务端点和配额,然后选择相应服务的链接。
产品版本
Python 版本 3.10 或更高版本。
该模式的笔记本在 Amazon A SageMaker I Studio 中使用带有 Python 3(数据科学)内核的 ml.t3.medium 实例进行了测试。
架构
下图显示了此模式的工作流和架构组件。
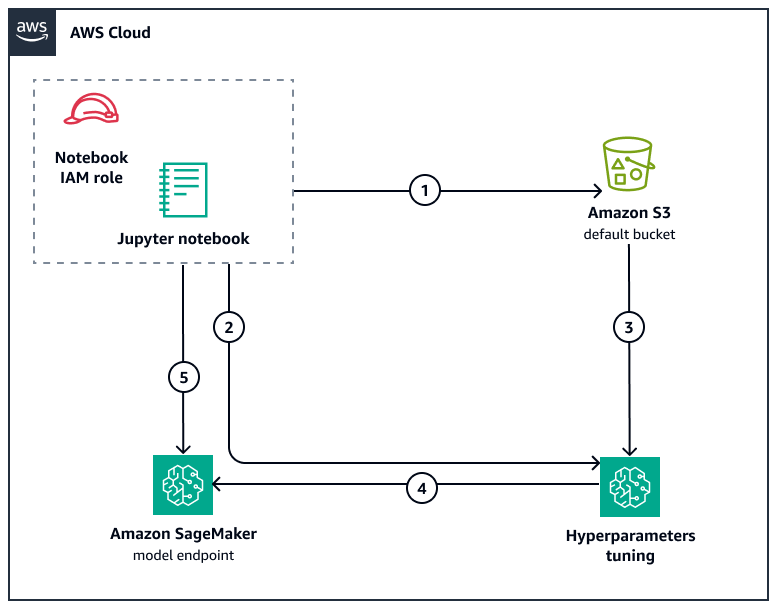
该工作流执行以下任务:
合成训练和测试数据的输入文件,然后将其上传到 Amazon S3 存储桶。这些数据包括具有分类和动态特征的多个时间序列以及目标值(待预测)。Jupyter Notebook 可视化数据,以更好地了解训练数据的要求和预期的预测值。
创建了超参数调谐器作业,用于训练模型并根据预定义的指标找到最佳模型。
输入文件将从 Amazon S3 存储桶下载到超参数调整任务的每个实例。
在调谐器作业根据调谐器的预定义阈值选择最佳模型后,该模型将部署为 A SageMaker I 端点。
然后,可以调用已部署的模型,并根据测试数据验证其预测。
笔记本演示了当有足够数量的历史数据点可用时,模型预测目标值的效果如何。但是,当我们使用较少的历史数据点(代表冷产品)调用模型时,即使在模型的置信度范围内,模型预测也与原始测试数据不匹配。在该模式中,为冷产品构建了一个新模型,其初始上下文长度(预测点)定义为可用历史点的数量,并在获取新数据点时迭代训练新模型。笔记本显示,只要历史数据点的数量接近其上下文长度,模型就会产生准确的预测。
工具
AWS 服务
AWS Identity and Access Management (IAM) 通过控制谁经过身份验证并有权使用 AWS 资源,从而帮助您安全地管理对资源的访问权限。
Amazon SageMaker AI 是一项托管机器学习 (ML) 服务,可帮助您构建和训练机器学习模型,然后将其部署到生产就绪的托管环境中。
Amazon SageMaker AI Studio 是一个基于 Web 的机器学习集成开发环境 (IDE),允许您构建、训练、调试、部署和监控您的机器学习模型。
Amazon Simple Storage Service(Amazon S3)是一项基于云的对象存储服务,可帮助您存储、保护和检索任意数量的数据。
其他工具
Python
是通用的计算机编程语言。
代码存储库
此模式的代码可在 GitHub Deepar ColdProduct-
最佳实践
在虚拟环境中训练模型,并始终使用版本控制来实现最高的可重复性。
尽可能多地包含高质量的分类特征,以获得预测能力更强的模型。
确保元数据包含相似的分类项目,以使模型能够充分推理出冷启动产品预测。
运行超参数调整作业以获得预测能力最强的模型。
在此模式中,您构建的模型的上下文长度为 24 小时,这意味着它将对接下来的 24 小时进行预测。如果您在历史数据少于 24 小时时尝试预测未来 24 小时,则模型的预测精度会根据历史数据点的数量线性下降。为了缓解此问题,请为每组历史数据点创建一个新模型,直到该数字达到所需的预测(上下文)长度。例如,从 2 小时的上下文长度模型开始,然后将模型逐渐增加到 4 小时、8 小时、16 小时和 24 小时。
操作说明
| Task | 说明 | 所需技能 |
|---|---|---|
启动笔记本环境。 |
有关更多信息,请参阅 AI 文档中的启动 Amazon SageMaker A SageMaker I Studio。 | 数据科学家 |
| Task | 说明 | 所需技能 |
|---|---|---|
设置模型训练的虚拟环境。 | 要设置模型训练的虚拟环境,请执行以下操作:
有关更多信息,请参阅 AI 文档中的将文件上传到 SageMaker AI Studio Classic。 SageMaker | 数据科学家 |
创建并验证预测模型。 |
| 数据科学家 |
相关资源
