本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用 Python 应用程序为 Amazon DynamoDB 自动生成 PynamoDB 模型和 CRUD 函数
Vijit Vashishtha、Dheeraj Alimchandani 和 Dhananjay Karanjkar,Amazon Web Services
Summary
通常需要实体以及创建、读取、更新和删除(CRUD)操作函数,以便高效地执行 Amazon DynamoDB 数据库操作。PynamoDB 是一种基于 Python 的接口,支持 Python 3。它还提供了一些其他特性,例如支持 Amazon DynamoDB 事务、自动属性值序列化和反序列化,以及与常见 Python 框架(例如 Flask 和 Django)的兼容性。此模式提供了一个简化 PynamoDB 模型和 CRUD 操作函数的自动创建的库,从而帮助使用 Python 和 DynamoDB 的开发人员。虽然它为数据库表生成基本的 CRUD 函数,但它也可以对 PynamoDB 模型和 Amazon DynamoDB 表中的 CRUD 函数进行逆向工程。此模式旨在通过使用基于 Python 的应用程序来简化数据库操作。
下面是此解决方案的主要功能:
PynamoDB 模型的 JSON 架构 ‒ 通过导入 JSON 架构文件在 Python 中自动生成 PynamoDB 模型。
CRUD 函数生成 ‒ 自动生成函数以在 DynamoDB 表上执行 CRUD 操作。
从 DynamoDB 逆向工程 ‒ 使用 PynamoDB 对象关系映射(ORM)对现有 Amazon DynamoDB 表的 PynamoDB 模型和 CRUD 函数进行逆向工程。
先决条件和限制
先决条件
架构
目标技术堆栈
JSON 脚本
Python 应用程序
PynamoDB 模型
Amazon DynamoDB 数据库实例
目标架构
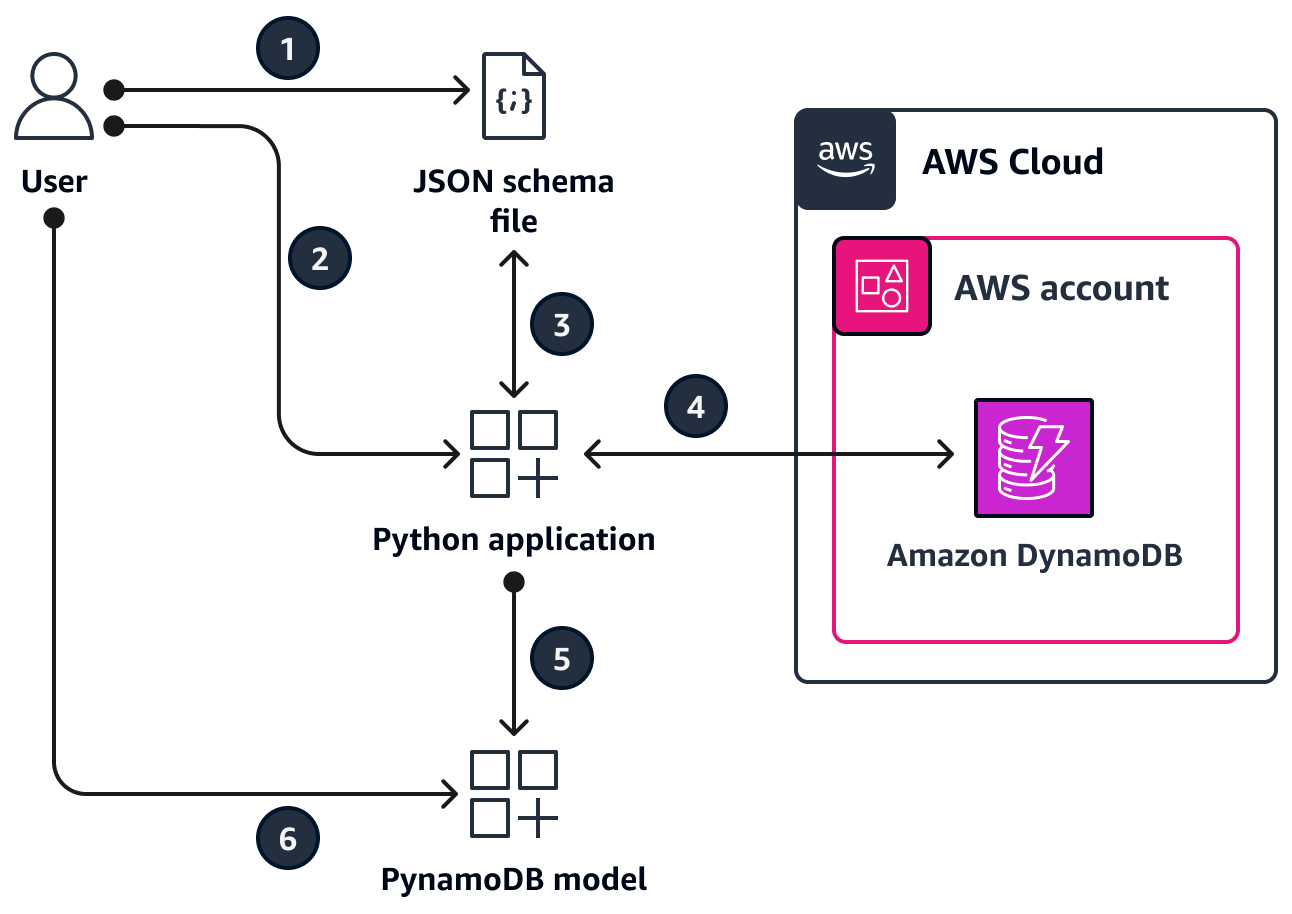
您创建了一个输入 JSON 架构文件。此 JSON 架构文件提供了相应的 DynamoDB 表的属性,您需要根据这些表创建 PynamoDB 模型并为这些表创建 CRUD 函数。它包含以下三个重要密钥:
运行 Python 应用程序并提供 JSON 架构文件作为输入。
Python 应用程序读取 JSON 架构文件。
Python 应用程序连接到 DynamoDB 表以派生架构和数据类型。该应用程序运行 describe_table
操作并获取表的键和索引属性。 Python 应用程序结合了 JSON 架构文件和 DynamoDB 表中的属性。它使用 Jinja 模板引擎生成 PynamoDB 模型和相应的 CRUD 函数。
您可访问 PynamoDB 模型以对 DynamoDB 表执行 CRUD 操作。
工具
AWS 服务
Amazon DynamoDB 是一项完全托管式 NoSQL 数据库服务,可提供快速、可预测、可扩展的性能。
其他工具
代码存储库
此模式的代码可在 GitHub 自动生成 PynamoDB
控制器包
控制器 Python 包中包含帮助生成 PynamoDB 模型和 CRUD 函数的主要应用程序逻辑。其中包含以下内容:
input_json_validator.py‒ 此 Python 脚本验证输入 JSON 架构文件并创建包含目标 DynamoDB 表列表及其各自必需属性的 Python 对象。dynamo_connection.py‒ 此脚本建立与 DynamoDB 表的连接,并使用describe_table操作提取创建 PynamoDB 模型所需的属性。generate_model.py‒ 此脚本包含一个 Python 类GenerateModel,该类基于输入 JSON 架构文件和describe_table操作创建 PynamoDB 模型。generate_crud.py‒ 对于 JSON 架构文件中定义的 DynamoDB 表,此脚本使用GenerateCrud操作创建 Python 类。
模板
Python 目录包含以下 Jinja 模板:
model.jinja‒ 此 Jinja 模板包含用于生成 Pynamodb 模型脚本的模板表达式。crud.jinja‒ 此 Jinja 模板包含用于生成 CRUD 函数脚本的模板表达式。
操作说明
| Task | 说明 | 所需技能 |
|---|---|---|
克隆存储库。 | 输入以下命令克隆自动生成 PynamoDB 模型和 CRUD 函数
| 应用程序开发人员 |
设置 Python 环境。 |
| 应用程序开发人员 |
| Task | 说明 | 所需技能 |
|---|---|---|
修改 JSON 架构文件。 |
| 应用程序开发人员 |
运行 Python 应用程序。 | 输入以下命令生成 Pynamodb 模型和 CRUD 函数,其中
| 应用程序开发人员 |
| Task | 说明 | 所需技能 |
|---|---|---|
验证生成的 PynamoDB 模型。 |
| 应用程序开发人员 |
验证生成的 CRUD 函数。 |
| 应用程序开发人员 |
相关资源
Amazon DynamoDB 的核心组件(DynamoDB 文档)
使用二级索引改进数据访问(DynamoDB 文档)
附加信息
JSON 架构文件的示例属性
[ { "name": "test_table", "region": "ap-south-1", "attributes": [ { "name": "id", "type": "UnicodeAttribute" }, { "name": "name", "type": "UnicodeAttribute" }, { "name": "age", "type": "NumberAttribute" } ] } ]
