本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
第 1 步:确定使用案例和逻辑数据模型
某汽车公司想要构建一个事务性组件管理系统,用于存储和搜索所有可用的汽车零件,并在不同的组件和零件之间建立关系。例如,一辆汽车包含多个电池,每个电池包含多个高级模块,每个模块包含多个单元,每个单元包含多个低级组件。
通常,对于构建层次关系模型,Amazon Neptune 之类的图形数据库是更好的选择。但在某些情况下,Amazon DynamoDB 因其灵活性、安全性、性能和可扩展性而成为分层数据建模的更好选择。
例如,您可以构建一个系统,其中 80-90% 的查询是事务性的,那么 DynamoDB 就非常适合。在本例中,另外 10-20% 的查询是关系型的,诸如 Neptune 之类的图形数据库更适合。这种情况下,在架构中增加一个额外的数据库,只完成 10-20% 的查询,可能导致成本增加。这还增加了维护多个系统并同步数据的运营负担。您可以在 DynamoDB 中对 10-20% 的关系查询进行建模。
绘制汽车组件的示例树有助于映射它们之间的关系。下图显示了一个包含四个级别的依赖关系图。 CM1 是示例汽车本身的顶级组件。它有两个子组件,用于两个示例电池, CM2 和。 CM3每个电池都有两个子组件,即模块。 CM2 有模块 CM4和 CM5, CM3 有模块 CM6 和 CM7。每个模块有几个子组件,即单元。该 CM4 模块有两个单元, CM8 和 CM9。 CM5 有一个细胞, CM10。 CM6 而且还 CM7没有任何关联的细胞。
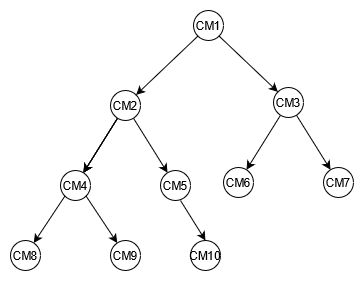
本指南将使用此树及其组件标识符作为参考。顶部组件称为父级,子组件称为子级。例如,顶部组件 CM1 是 CM2 和的父组件 CM3。 CM2 是 CM4 和的父项 CM5。这描绘了父子关系图。
从树状图中,您可以看到组件的完整依赖关系图。例如,依赖 CM8 于 CM4,依赖于 CM2,依赖于 CM1。树将完整的依赖关系图定义为路径。路径描述了两点:
-
依赖关系图
-
树中的位置
填写业务需求模板:
提供有关您的用户的信息:
User |
描述 |
Employee |
需要汽车及其组件信息的汽车公司内部员工 |
提供有关数据来源和数据摄取方式的信息:
源 |
描述 |
User |
管理系统 |
此系统将存储与可用汽车零件及其与其他组件和零件的关系有关的所有数据。 |
Employee |
提供有关如何使用数据的信息:
使用者 |
描述 |
User |
管理系统 |
检索父组件 ID 的所有直接子组件。 |
Employee |
管理系统 |
检索组件 ID 的所有子组件的递归列表。 |
Employee |
管理系统 |
请参阅组件的原级。 |
Employee |
