本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
在数据库分解过程中解耦表关系
本节提供有关在整体数据库分解期间分解复杂的表关系和 JOIN 操作的指导。表联接基于两个或多个表中的相关列来合并两张或更多表中的行。分离这些关系的目的是减少表之间的高度耦合,同时保持微服务间的数据完整性。
非正规化策略
非规范化是一种数据库设计策略,它涉及通过跨表合并或复制数据来故意引入冗余。将大型数据库拆分为小型数据库时,跨服务复制一些数据可能是有意义的。例如,将基本的客户详细信息(例如姓名和电子邮件地址)存储在营销服务和订单服务中,无需持续进行跨服务查找。营销服务可能需要客户偏好和联系信息来进行广告活动定位,而订单服务则需要相同的数据来处理订单和发出通知。虽然这会产生一些数据冗余,但它可以显著提高服务绩效和独立性,使营销团队能够在不依赖实时客户服务查询的情况下开展活动。
在实施非规范化时,请重点关注通过仔细分析数据访问模式来识别的经常访问的字段。您可以使用诸如Oracle AWR报告或pg_stat_statements之类的工具来了解哪些数据通常是一起检索的。领域专家还可以提供有关自然数据分组的宝贵见解。请记住,非规范化不是一种 all-or-nothing方法,只能使用可明显提高系统性能或减少复杂依赖关系的重复数据。
Reference-by-key 策略
reference-by-key 策略是一种数据库设计模式,其中实体之间的关系通过唯一密钥维护,而不是存储实际的相关数据。现代微服务通常只存储相关数据的唯一标识符,而不是传统的外键关系。例如,订单服务不是将所有客户详细信息保留在订单表中,而是仅存储客户 ID,并在需要时通过 API 调用检索其他客户信息。这种方法保持了服务的独立性,同时确保了对相关数据的访问。
CQRS 模式
命令查询责任分离 (CQRS) 模式将数据存储的读取和写入操作分开。这种模式在具有高性能要求的复杂系统中特别有用,尤其是那些具有非对称 read/write 负载的系统。如果您的应用程序经常需要组合来自多个来源的数据,则可以创建专用的 CQRS 模型,而不是复杂的联接。例如,与其根据每个请求联接ProductPricing、和Inventory表,不如维护一个包含必要数据的合并Product Catalog表。这种方法的好处可能超过额外表格的成本。
考虑这样一个场景:ProductPrice、和Inventory服务经常需要产品信息。与其将这些服务配置为直接访问共享表,不如创建专用Product Catalog服务。该服务维护自己的数据库,其中包含统一的产品信息。它充当与产品相关的查询的单一事实来源。当产品详情、价格或库存水平发生变化时,相应的服务可以发布事件以更新Product Catalog服务。这样既能保持数据一致性,又能保持服务独立性。下图显示了此配置,其中 Amazon EventBridge
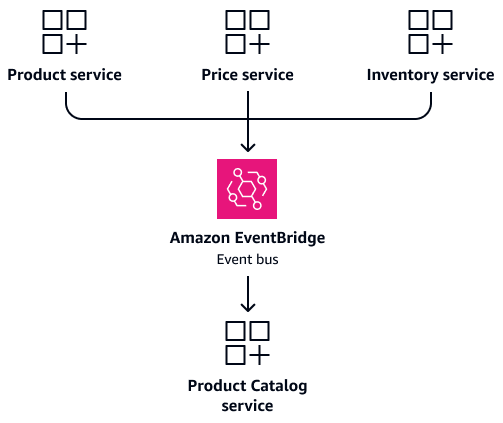
如下一节所基于事件的数据同步述,通过事件更新 CQRS 模型。当产品详情、价格或库存水平发生变化时,相应的服务会发布事件。该Product Catalog服务订阅这些事件并更新其合并视图。这无需复杂联接即可快速读取,并且可以保持服务独立性。
基于事件的数据同步
基于事件的数据同步是一种捕获数据更改并作为事件传播的模式,这使不同的系统或组件能够保持同步的数据状态。当数据发生变化时,与其立即更新所有相关数据库,不如发布一个事件来通知订阅的服务。例如,当客户在Customer服务中更改其送货地址时,一个CustomerUpdated事件会根据每项Order服务的计划启动对服务和服务的更新。Delivery这种方法用灵活、可扩展的事件驱动更新取代了僵化的表格联接。有些服务可能有短暂的过时数据,但需要权衡的是系统可扩展性和服务独立性的提高。
实现表格联接的替代方案
从读取操作开始数据库分解,因为读取操作通常更易于迁移和验证。在读取路径稳定之后,处理更复杂的写入操作。对于关键的高性能要求,可以考虑实施 CQRS 模式。使用单独的、经过优化的数据库进行读取,同时保留另一个数据库进行写入。
通过为跨服务调用添加重试逻辑并实现适当的缓存层,构建弹性系统。密切监控服务交互,并针对数据一致性问题设置警报。最终目标不是所有地方的完美一致性,而是创建性能良好的独立服务,同时保持可接受的数据准确性,以满足您的业务需求。
微服务的分离性质为数据管理带来了以下新的复杂性:
-
数据是分布式的。现在,数据存储在单独的数据库中,这些数据库由独立的服务管理。
-
跨服务的实时同步通常是不切实际的,因此需要一个最终的一致性模型。
-
以前在单个数据库事务中发生的操作现在跨越多个服务。
要应对这些挑战,请执行以下操作:
-
实施事件驱动架构-使用消息队列和事件发布在服务之间传播数据更改。有关更多信息,请参阅在 Serverless Land 上构建事件驱动架构
。 -
采用 saga 编排模式 — 这种模式可帮助您管理分布式事务并维护服务间的数据完整性。有关更多信息,请参阅博客上AWS 使用传奇编排模式构建无服务器分布式应用程序
。 -
失败设计 — 整合重试机制、断路器和补偿事务以处理网络问题或服务故障。
-
使用版本标记-跟踪数据版本以管理冲突并确保应用了最新的更新。
-
定期对账 — 实施定期的数据同步流程,以捕捉和纠正任何不一致之处。
基于场景的示例
以下架构示例有两个表,一个Customer表和一个Order表:
-- Customer table CREATE TABLE customer ( customer_id INT PRIMARY KEY, first_name VARCHAR(100), last_name VARCHAR(100), email VARCHAR(255), phone VARCHAR(20), address TEXT, created_at TIMESTAMP ); -- Order table CREATE TABLE order ( order_id INT PRIMARY KEY, customer_id INT, order_date TIMESTAMP, total_amount DECIMAL(10,2), status VARCHAR(50), FOREIGN KEY (customer_id) REFERENCES customers(id) );
以下是如何使用非规范化方法的示例:
CREATE TABLE order ( order_id INT PRIMARY KEY, customer_id INT, -- Reference only customer_first_name VARCHAR(100), -- Denormalized customer_last_name VARCHAR(100), -- Denormalized customer_email VARCHAR(255), -- Denormalized order_date TIMESTAMP, total_amount DECIMAL(10,2), status VARCHAR(50) );
新Order表中包含非标准化的客户姓名和电子邮件地址。customer_id被引用了,并且Customer表中没有外键约束。以下是这种非规范化方法的好处:
-
该
Order服务可以显示带有客户详细信息的订单历史记录,并且不需要对Customer微服务进行API调用。 -
如果
Customer服务已关闭,则该Order服务仍能完全正常运行。 -
订单处理和报告的查询运行速度更快。
下图显示了一个单体应用程序,该应用程序使用getOrder(customer_id)、getOrder(order_id)getCustomerOders(customer_id)、和 createOrder(Order
order) API 调用微服务来检索订单数据。Order
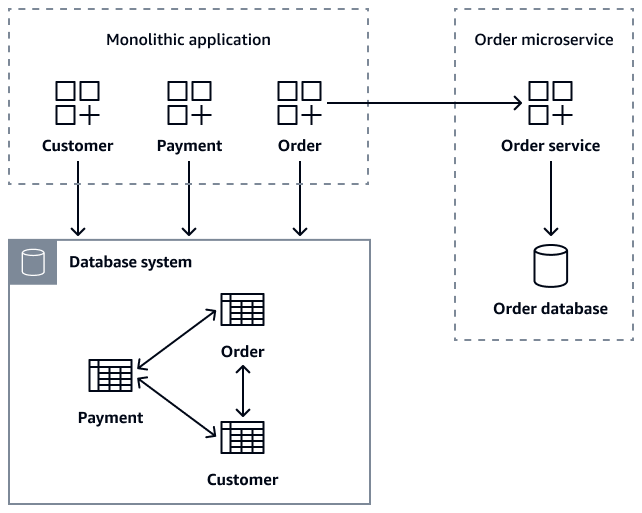
在微服务迁移期间,您可以将Order表保存在单体数据库中,以此作为过渡性安全措施,从而确保旧版应用程序保持正常运行。但是,所有与新订单相关的操作都必须通过微服务 API 进行路由,Order微服务 API 维护自己的数据库,同时写入旧数据库作为备份。这种双写模式提供了一个安全网。它允许在保持系统稳定性的同时逐步迁移。在所有客户成功迁移到新的微服务后,您可以弃用单体数据库中的旧Order表。在将整体应用程序及其数据库分解为单独Customer的Order微服务之后,保持数据一致性成为主要挑战。
