本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
分析数据库分解的内聚力和耦合
本节帮助您分析整体数据库中的耦合和内聚模式,以指导其分解。了解数据库组件如何相互交互和相互依赖对于识别自然断点、评估复杂性和规划分阶段迁移方法至关重要。该分析揭示了隐藏的依赖关系,突出显示了适合立即分离的区域,并帮助您确定分解工作的优先顺序,同时最大限度地降低转换风险。通过检查耦合和内聚力,您可以就组件分离顺序做出明智的决定,以便在整个转换过程中保持系统稳定性。
关于内聚力和耦合
耦合度量数据库组件之间的相互依赖程度。在精心设计的系统中,您希望实现松耦合,即对一个组件的更改对其他组件的影响最小。凝聚力衡量数据库组件中的元素如何协同工作以达到单一的、明确的目的。高内聚力表示组件的元素紧密相关,并且侧重于特定的功能。分解整体数据库时,必须同时分析各个组件内部的内聚力以及它们之间的耦合。此分析可帮助您就如何在保持系统完整性和性能的同时分解数据库做出明智的决定。
下图显示了具有高内聚力的松散耦合。数据库中的组件协同工作以执行特定的功能,您可以最大限度地减少更改对单个组件的影响。这是理想的状态。

下图显示了高耦合和低内聚力。数据库组件已断开连接,更改极有可能影响其他组件。
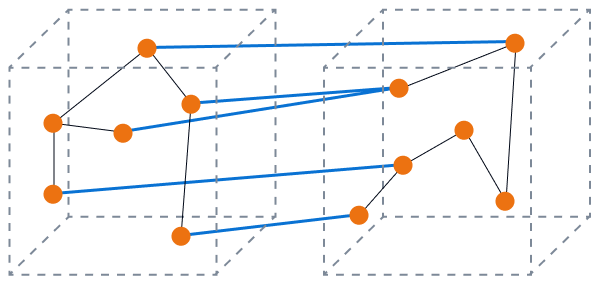
单片数据库中常见的耦合模式
将整体数据库分解为特定于微服务的数据库时,通常会发现几种耦合模式。了解这些模式对于成功的数据库现代化计划至关重要。本节介绍每种模式、其挑战以及减少耦合的最佳实践。
实现耦合模式
定义:组件在代码和架构级别紧密相连。例如,修改customer表的结构会影响orderinventory、和billing服务。
现代化的影响:每个微服务都需要自己的专用数据库架构和数据访问层。
挑战:
-
对共享表的更改会影响多项服务
-
出现意外副作用的风险很高
-
测试复杂性增加
-
难以修改单个组件
减少耦合的最佳实践:
-
定义组件之间的清晰接口
-
使用抽象层隐藏实现细节
-
实现特定于域的架构
时间耦合模式
定义:操作必须按特定顺序运行。例如,在库存更新完成之前,无法继续处理订单。
现代化的影响:每个微服务都需要自主的数据控制。
挑战:
-
打破服务之间的同步依赖关系
-
性能瓶颈
-
难以优化
-
并行处理有限
减少耦合的最佳实践:
-
尽可能实现异步处理
-
使用事件驱动架构
-
在适当时进行设计以实现最终一致性
部署耦合模式
定义:系统组件必须作为一个单元部署。例如,支付处理逻辑的微小更改需要重新部署整个数据库。
现代化影响:每项服务独立部署数据库
挑战:
-
高风险部署
-
部署频率有限
-
复杂的回滚程序
减少耦合的最佳实践:
-
分解为可独立部署的组件
-
实施数据库分片策略
-
使用蓝绿色部署模式
域耦合模式
定义:业务领域共享数据库结构和逻辑。例如,customerorder、和inventory域共享表和存储过程。
现代化的影响:特定领域的数据隔离
挑战:
-
复杂的域边界
-
难以扩展单个域
-
纠结的商业规则
减少耦合的最佳实践:
-
确定明确的域边界
-
按域上下文分隔数据
-
实施特定于域的服务
整体数据库中常见的内聚模式
在评估数据库组件的分解时,通常会发现几种内聚模式。了解这些模式对于识别结构良好的数据库组件至关重要。本节介绍每种模式、其特征以及增强凝聚力的最佳实践。
功能凝聚力模式
定义:所有元素都直接支持并有助于执行单一的、定义明确的功能。例如,付款处理模块中的所有存储过程和表格仅处理与支付相关的操作。
现代化的影响:微服务数据库设计的理想模式
挑战:
-
确定明确的功能边界
-
分离混合用途组件
-
保持单一责任
增强凝聚力的最佳实践:
-
将相关函数组合在一起
-
移除不相关的功能
-
定义清晰的组件边界
顺序凝聚力模式
定义:一个元素的输出变成另一个元素的输入。例如,订单输入到订单处理中的验证结果。
现代化的影响:需要仔细的工作流程分析和数据流映射
挑战:
-
管理步骤之间的依赖关系
-
处理故障场景
-
维护流程顺序
增强凝聚力的最佳实践:
-
记录清晰的数据流
-
实施正确的错误处理
-
在步骤之间设计清晰的接口
沟通凝聚力模式
定义:元素对相同的数据进行操作。例如,客户档案管理功能全部使用客户数据。
现代化的影响:帮助确定服务分离的数据边界,以减少模块之间的耦合
挑战:
-
确定数据所有权
-
管理共享数据访问权限
-
维护数据一致性
增强凝聚力的最佳实践:
-
定义明确的数据所有权
-
实施正确的数据访问模式
-
设计有效的数据分区
程序凝聚模式
定义:元素之所以组合在一起,是因为它们必须按特定的顺序执行,但它们在功能上可能不相关。例如,在订单处理中,处理订单验证和用户通知的存储过程被分组在一起,这仅仅是因为它们是按顺序进行的,尽管它们用于不同的目的并且可以由不同的服务来处理。
现代化的影响:需要在保持流程的同时仔细分离程序
挑战:
-
分解后保持正确的工艺流程
-
与程序依赖关系相比,识别真正的功能边界
增强凝聚力的最佳实践:
-
根据程序的功能目的而不是执行顺序来分开程序
-
使用编排模式来管理流程
-
为复杂序列实施工作流管理系统
-
设计事件驱动架构以独立处理流程步骤
时间凝聚力模式
定义:元素与时间要求相关。例如,下订单时,必须同时执行多项操作:库存检查、付款处理、订单确认和发货通知都必须在特定的时间窗口内进行,以保持一致的订单状态。
现代化影响:可能需要在分布式系统中进行特殊处理
挑战:
-
协调分布式服务之间的计时依赖关系
-
管理分布式事务
-
确认多个组件的流程完成
增强凝聚力的最佳实践:
-
实施适当的调度机制和超时
-
使用具有清晰序列处理的事件驱动架构
-
为最终与补偿模式保持一致而设计
-
为分布式事务实现传奇模式
合乎逻辑或巧合的内聚模式
定义:元素的逻辑分类是为了做同样的事情,即使它们之间的关系薄弱或没有有意义的关系。一个例子是将客户订单数据、仓库库存计数和营销电子邮件模板存储在同一个数据库架构中,因为尽管访问模式、生命周期管理和扩展要求不同,但它们都与销售运营有关。另一个例子是将订单支付处理和产品目录管理合并到同一个数据库组件中,因为它们都是电子商务系统的一部分,尽管它们具有不同的业务职能和不同的运营需求。
现代化的影响:应进行重构或重组
挑战:
-
确定更好的组织模式
-
打破不必要的依赖关系
-
重组任意分组的组件
增强凝聚力的最佳实践:
-
根据真正的职能界限和业务领域进行重组
-
删除基于肤浅关系的任意分组
-
根据业务能力对元素进行适当的分离
-
使数据库组件与其特定的操作要求保持一致
实现低耦合和高内聚力
最佳实践
以下最佳实践可以帮助您实现低耦合:
-
最大限度地减少数据库组件之间的依赖关系
-
使用定义明确的接口进行组件交互
-
避免共享状态和全局数据结构
以下最佳实践可以帮助您实现高凝聚力:
-
将相关数据和操作组合在一起
-
确保每个组成部分都有单一、明确的责任
-
在不同业务领域之间保持明确的界限
第 1 阶段:映射数据依赖关系
绘制数据关系并确定自然边界。您可以使用诸如SchemaSpy
您也可以将数据库架构导出到图形数据库或Jupiter笔记本中。然后,您可以应用聚类或互连组件算法来识别自然边界和依赖关系。其他 AWS Partner 工具(例如)CAST Imaging
第 2 阶段:分析交易边界和访问模式
分析事务模式以保持原子性、一致性、隔离性、持久性 (ACID) 属性,并了解如何访问和修改数据。您可以使用数据库分析和诊断工具,例如Oracle Automatic Workload Repository (AWR)
人工智能工具(例如 vFunction
第 3 阶段:识别独立表
寻找能说明两个关键特征的表格:
-
高内聚力 — 表格的内容彼此密切相关
-
低耦合 — 它们对其他表的依赖性最小。
以下耦合内聚矩阵可以帮助您确定解耦每个表的难度。出现在此矩阵右上方象限中的表格是初始解耦工作的理想候选表,因为它们最容易分开。在 ER 图中,这些表几乎没有外键关系或其他依赖关系。解除这些表的耦合后,可以转向关系更复杂的表。
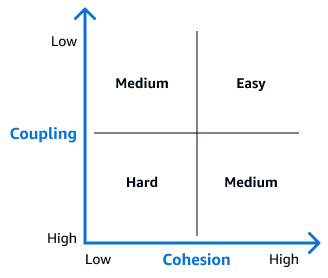
注意
数据库结构通常反映应用程序架构。在数据库级别更容易解耦的表通常对应于更容易在应用程序级别转换为微服务的组件。
