本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
# 集中式目录
下图显示了集中式目录如何连接数据湖中的数据生产者和数据使用者。
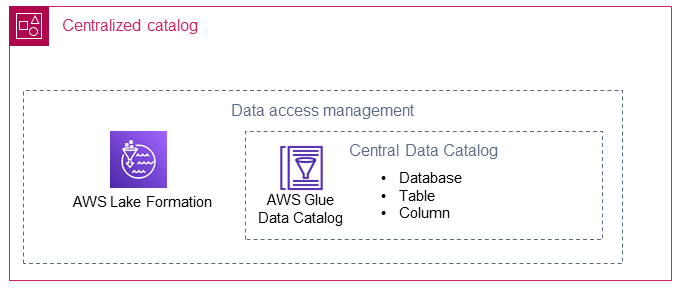
集中式目录存储和管理数据创建者账户的共享数据目录。集中式目录还托管共享数据的技术元数据(例如表名和架构),也是数据使用者访问数据的地方。
数据使用者可以在集中式目录中访问来自多个数据生产者的数据,然后可以将这些数据与自己的数据混合以进行进一步处理。使用集中式目录使数据使用者无需直接与不同的数据生产者建立联系,并减少了运营开销。
由于集中式目录可以查看数据创建者和使用者的数据共享和数据使用情况,因此它可能是应用集中式数据治理功能(例如访问审计)的理想位置。
以下各节介绍集中式目录如何使用 AWS Lake Formation 和 AWS Glue。
## AWS Lake Formation
[AWS Lake Formation](https://docs.aws.amazon.com//lake-formation/latest/dg/what-is-lake-formation.html)帮助在 AWS Glue 数据目录中创建指向数据湖中多个数据生产者位置的数据库。在集中式目录中为 Lake Formation 创建了一个 AWS Identity and Access Management (IAM) 角色。通过使用 Lake Formation,集中式目录可以有选择地与数据使用者共享数据资源(例如数据库、表或列)。使用以下两种方法之一与数据使用者共享 Lake Formation 托管资源:
+ [命名资源方法](https://docs.aws.amazon.com//lake-formation/latest/dg/granting-cat-perms-named-resource.html)-此方法跨账户共享托管资源。必须指定数据库、表或列名,并且可以将资源共享给组织、组织单位 (OU) 或 AWS 账户。为了减少共享和管理开销,我们建议您尽可能在更高级别上共享资源(例如,在组织或 OU 中而不是 AWS 账户)。但是,您必须确保这种方法符合贵组织的数据安全控制要求。
+ **注意**:此方法适用于具有应用程序类型的数据使用者,其中 AWS 服务使用来自数据创建器的数据。这类数据使用者的数据访问要求是应用程序驱动的、规范性的,而且相对静态。
+ La@@ [ke Formation 基于标签的访问控制 (LF-TBAC) 方法](https://docs.aws.amazon.com//lake-formation/latest/dg/granting-catalog-perms-TBAC.html) — LF-TBAC 对于具有数据服务类型的数据使用者特别有用。但是,带有 Lake Formation 标签的资源目前只能在 AWS 账户 级别共享,不能在组织或 OU 级别共享。
## AWS Glue
您必须在中 AWS Glue 为集中式目录中的每个数据创建者创建数据库。由于集中式目录用于 AWS Glue 托管来自所有数据生产者的数据库,因此必须确保数据库名称在所有数据生产者中都是唯一的,并且它反映了数据创建者及其数据类型。例如,您可以使用以下数据库命名结构:` ––`
+ ``— 数据生产者的姓名。
+ ``— 数据湖环境,`dev`例如开发环境、`sit`系统集成测试环境或`prod`生产环境。
+ ``— 用于将数据来自数据创建者的数据分成逻辑组的数据组的名称。您可以使用源系统的名称、ID 或缩写作为名称。数据库描述还有助于描述数据库的内容和用途。
您可以对数据创建者的数据使用 AWS Glue 爬虫,以便在集中式目录的数据库中维护其架构。如果数据创建者定期以相同的频率创建数据,则可以使用单个 AWS Glue 抓取器。在所有其他情况下,您应该使用多个 AWS Glue 爬虫来适应不同的抓取频率。根据您的业务用例,可以将爬网程序安排为预定义的频率,也可以由事件启动。
您还可以 AWS Glue 通过调用 AWS Glue API 来创建或更新架构来维护中的表架构。尽管这可以提供灵活性,但在代码开发和维护方面还需要付出额外的努力。请务必评估用例和业务价值,然后选择符合您的要求且开销最少的选项。