本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
向量概述
向量是帮助机器理解和处理数据的数值表示。在生成式人工智能中,它们有两个关键用途:
-
表示以压缩形式捕获数据结构的潜在空间
-
为单词、句子和图像等数据创建嵌入式
诸如 Word2Vec GloVe
-
从上下文中学习,将单词表示为向量
-
在向量空间中将相似的单词放得更近
-
使机器能够在连续的空间中处理数据
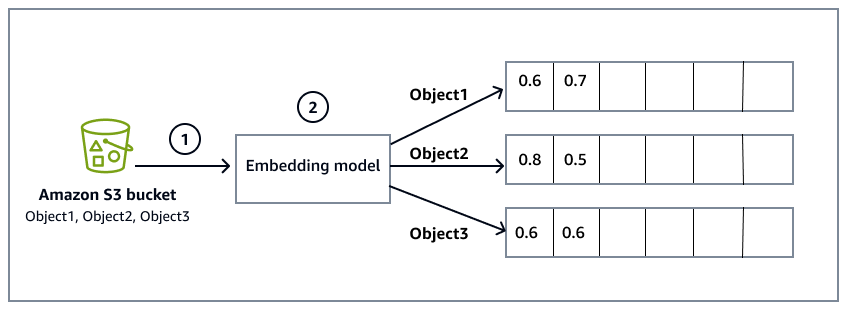
下图简要概述了嵌入过程:
-
A mazon Simple Storage Service (Amazon S3) 存储桶包含文件,这些文件是系统从中读取和处理信息的数据源。Amazon S3 存储桶是在配置 Amazon Bedrock 知识库时指定的,其中还包括将数据与知识库同步。
-
嵌入模型将 Amazon S3 存储桶中对象文件中的原始数据转换为矢量嵌入。例如,
Object1被转换为[0.6, 0.7, ...]表示其在多维空间中的内容的向量。
单词嵌入对于自然语言处理 (NLP) 至关重要,因为它们具有以下作用:
-
捕捉单词之间的语义关系
-
启用生成与上下文相关的文本
-
支持大型语言模型 (LLMs) 以生成类似人类的响应
