本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用 AWS Glue 导出数据
您可以使用 AWS Glue 将 MySQL 数据归档在 Amazon S3 中,AWS Glue 是一项适用于大数据场景的无服务器分析服务。AWS Glue 由 Apache Spark 提供支持,Apache Spark 是一种广泛使用的分布式集群计算框架,支持许多数据库源。
只需在 AWS Glue 作业中使用几行代码即可将归档数据从数据库卸载到 Amazon S3。AWS Glue 提供的最大优势是横向可扩展性和 pay-as-you-go模型,可提供运营效率和成本优化。
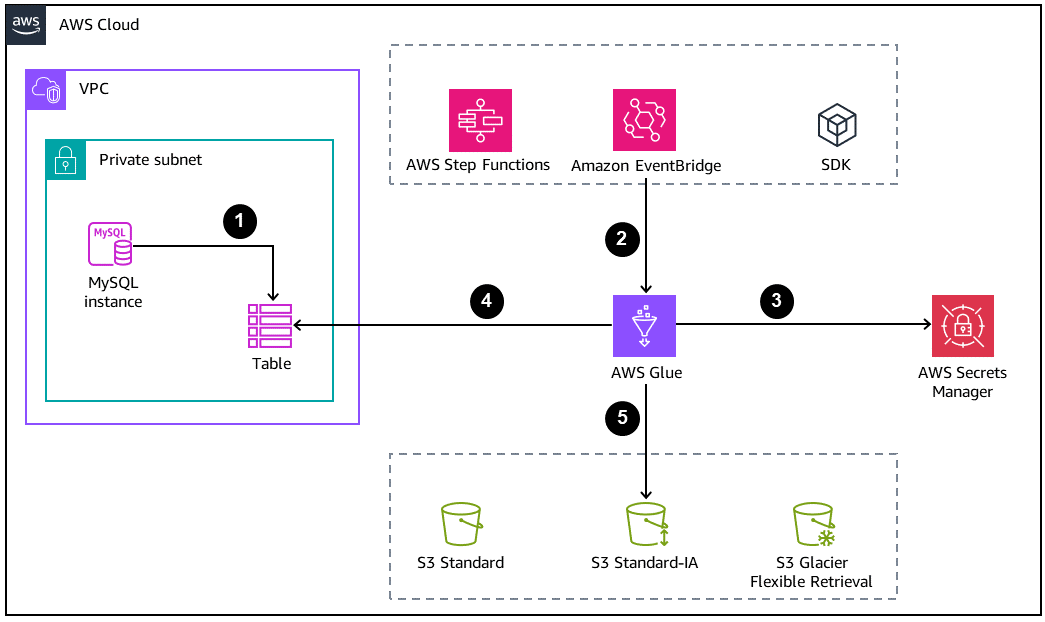
下图展示了数据库归档的基本架构。
-
MySQL 数据库创建要在 Amazon S3 中卸载的归档或备份表。
-
AWS Glue 作业通过以下方法之一启动:
-
作为 AWS Step Functions 状态机内的一个步骤同步进行
-
通过 Amazon EventBridge 事件异步进行
-
通过使用 AWS CLI 或 AWS SDK 进行手动请求
-
-
数据库凭证是从 AWS Secrets Manager 中检索的。
-
AWS Glue 作业使用 Java 数据库连接(JDBC)连接来访问数据库和读取表。
-
AWS Glue 以 Parquet 格式在 Amazon S3 中写入数据,这是一种开放的、列式的、节省空间的数据格式。
配置 AWS Glue 作业
要按预期运行,AWS Glue 作业需要以下组件和配置:
-
AWS Glue 连接:这是 AWS Glue Data Catalog 对象,您可以将其附加到作业以访问数据库。一个作业可以有多个连接,用于调用多个数据库。这些连接包含安全存储的数据库凭证。
-
GlueContext— 这是对类的自定义封装。SparkContext
该 GlueContext 类提供更高阶的 API 操作来与 Amazon S3 和数据库源进行交互。它支持与 Data Catalog 集成。它还消除了对数据库连接驱动程序的依赖,数据库连接在 Glue 连接内处理。此外,该 GlueContext 类还提供了处理 Amazon S3 API 操作的方法,而原始 SparkContext 类无法做到这一点。 -
IAM 策略和角色:由于 AWS Glue 与其他 AWS 服务交互,因此您必须设置具有所需最低权限的适当角色。需要适当权限才能与 AWS Glue 交互的服务包括:
-
Amazon S3
-
AWS Secrets Manager
-
AWS Key Management Service(AWS KMS)
-
最佳实践
-
对于需要卸载大量行的整个表,我们建议使用只读副本端点来提高读取吞吐量,而不会降低主写入器实例的性能。
-
要提高用于处理作业的节点数量的效率,请在 AWS Glue 3.0 中开启自动扩缩。
-
如果 S3 存储桶是数据湖架构的一部分,我们建议通过将数据组织到物理分区来卸载数据。分区方案应基于访问模式。根据日期值进行分区是最推荐的做法之一。
-
将数据保存为开放格式 [例如 Parquet 或优化的行列式(ORC)] 有助于将数据提供给其他分析服务,例如 Amazon Athena 和 Amazon Redshift。
-
要使其他分布式服务对卸载的数据进行读取优化,必须控制输出文件的数量。使用少量的大文件几乎总是比使用大量小文件更有利。Spark 内置了配置文件和方法来控制部件文件的生成。
-
顾名思义,归档数据是经常访问的数据集。为了提高存储成本效益,Amazon S3 应该过渡到价格更低的层级。可以使用以下两种方法完成:
-
在卸载时同步过渡层 — 如果您事先知道卸载的数据必须作为流程的一部分进行过渡,则可以在将数据写入 Amazon S3 的同一 AWS Glue 任务中使用 tran sition_s3_path GlueContext 机制。
-
使用 S3 生命周期进行异步转换:设置 S3 生命周期规则,并设置适当的参数,以实现 Amazon S3 存储类别转换和到期。在存储桶上配置后,该配置将永久保留。
-
-
在部署数据库的虚拟私有云(VPC)内创建和配置具有足够 IP 地址范围
的子网。这将避免在配置大量数据处理单元 (DPUs) 时由于网络地址不足而导致 AWS Glue 任务失败。
