本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
就地迁移
就地迁移无需重写所有数据文件。取而代之的是生成 Iceberg 元数据文件并将其链接到您的现有数据文件。这种方法通常更快、更具成本效益,特别是对于具有兼容文件格式(例如 Parquet、Avro 和 ORC)的大型数据集或表。
注意
迁移到 Amazon S3 表时,不能使用就地迁移。
Iceberg 为实现就地迁移提供了两个主要选项:
使用snapshot或执行就地迁移后migrate,某些数据文件可能仍处于未迁移状态。当写入者在迁移期间或迁移之后继续写入源表时,通常会发生这种情况。要将这些剩余文件合并到 Iceberg 表中,可以使用 add_f
假设你有一个基于 Parquet 的桌子,该products表是在 Athena 中创建和填充的,如下所示:
CREATE EXTERNAL TABLE mydb.products ( product_id INT, product_name STRING ) PARTITIONED BY (category STRING) STORED AS PARQUET LOCATION 's3://amzn-s3-demo-bucket/products/'; INSERT INTO mydb.products VALUES (1001, 'Smartphone', 'electronics'), (1002, 'Laptop', 'electronics'), (2001, 'T-Shirt', 'clothing'), (2002, 'Jeans', 'clothing');
以下各节说明如何在此表中使用snapshot和migrate过程。
选项 1:快照过程
该snapshot过程创建一个新的 Iceberg 表,该表具有不同的名称,但会复制源表的架构和分区。此操作使源表在操作期间和操作之后都完全不变。它可以有效地创建表的轻量级副本,这对于测试场景或数据探索特别有用,而不会冒修改原始数据源的风险。这种方法可以实现一个过渡期,在这个过渡期,原始表和 Iceberg 表都保持可用(参见本节末尾的注释)。测试完成后,您可以通过将所有写入者和读者过渡到新表来将新 Iceberg 表移至生产环境。
你可以在任何亚马逊 EMR 部署模式中使用 Spark 来运行该snapshot过程(例如,EC2 上的 Amazon EMR、EKS 上的 Amazon EMR、EMR Serverless)和。 AWS Glue
要使用 snapshot Spark 程序测试就地迁移,请执行以下步骤:
-
启动 Spark 应用程序并使用以下设置配置 Spark 会话:
-
"spark.sql.extensions":"org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" -
"spark.sql.catalog.spark_catalog":"org.apache.iceberg.spark.SparkSessionCatalog" -
"spark.sql.catalog.spark_catalog.type":"glue" -
"spark.hadoop.hive.metastore.client.factory.class":"com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory"
-
-
运行以下
snapshot过程创建指向原始表数据文件的新 Iceberg 表:spark.sql(f""" CALL system.snapshot( source_table => 'mydb.products', table => 'mydb.products_iceberg', location => 's3://amzn-s3-demo-bucket/products_iceberg/' ) """ ).show(truncate=False)输出 dataFrame 包含
imported_files_count(已添加的文件数)。 -
通过查询来验证新表:
spark.sql(f""" SELECT * FROM mydb.products_iceberg LIMIT 10 """ ).show(truncate=False)
注意
-
运行该过程后,对源表的任何数据文件修改都将使生成的表失去同步。您添加的新文件将在 Iceberg 表中不可见,而您删除的文件将影响 Iceberg 表中的查询功能。要避免同步问题,请执行以下操作:
-
如果新的 Iceberg 表用于生产用途,请停止所有写入原始表的进程,并将它们重定向到新表。
-
如果您需要过渡期,或者如果新的 Iceberg 表用于测试目的,请参阅本节后面的就地迁移后保持 Iceberg 表同步,以获取有关维护表同步的指导。
-
-
使用该
snapshot过程时,该gc.enabled属性将在创建的 Iceberg 表的表属性false中设置为。此设置禁止诸如expire_snapshotsremove_orphan_files、或PURGE选项之类DROP TABLE的操作,这些操作会以物理方式删除数据文件。仍然允许不直接影响源文件的 Iceberg 删除或合并操作。 -
要使您的新 Iceberg 表完全正常运行,并且对物理删除数据文件的操作没有限制,您可以将
gc.enabled表属性更改为true。但是,此设置将允许影响源数据文件的操作,这可能会破坏对原始表的访问。因此,只有在不再需要维护原始表的功能时才更改该gc.enabled属性。例如:spark.sql(f""" ALTER TABLE mydb.products_iceberg SET TBLPROPERTIES ('gc.enabled' = 'true'); """)
选项 2:迁移程序
该migrate过程创建一个新的 Iceberg 表,该表的名称、架构和分区与源表相同。当此过程运行时,它会锁定源表并将其重命名为<table_name>_BACKUP_(或由backup_table_name过程参数指定的自定义名称)。
注意
如果将drop_backup过程参数设置为true,则原始表将不会保留为备份。
因此,migrate表过程要求在执行操作之前停止所有影响源表的修改。在运行该migrate过程之前:
-
停止所有与源表交互的写入器。
-
修改原生不支持 Iceberg 的读者和作者以启用 Iceberg 支持。
例如:
-
Athena 继续工作,无需任何修改。
-
Spark 需要:
-
要包含在类路径中的 Iceberg Java 存档 (JAR) 文件(参见本指南前面章节中的 “在 Amazon EMR 中使用 Iceb erg” 和 “使用 Iceberg”)。 AWS Glue
-
SparkSessionCatalog以下 Spark 会话目录配置(用于添加 Iceberg 支持,同时维护非 Iceberg 表的内置目录功能):-
"spark.sql.extensions":"org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" -
"spark.sql.catalog.spark_catalog":"org.apache.iceberg.spark.SparkSessionCatalog" -
"spark.sql.catalog.spark_catalog.type":"glue" -
"spark.hadoop.hive.metastore.client.factory.class":"com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory"
-
-
运行该过程后,您可以使用新的 Iceberg 配置重新启动写入器。
目前,该migrate过程与不兼容 AWS Glue Data Catalog,因为数据目录不支持该RENAME操作。因此,我们建议您仅在使用 Hive Metastore 时使用此过程。如果您使用的是数据目录,请参阅下一节以了解替代方法。
你可以在所有亚马逊 EMR 部署模型(EC2 上的 Amazon EMR、EKS 上的 Amazon EMR、EMR Serverless)上运行该migrate过程,但它需要配置与 Hive Metast AWS Glue ore 的连接。建议选择 EC2 上的 Amazon EMR,因为它提供了内置的 Hive Metastore 配置,可以最大限度地降低设置复杂性。
要使用 migrate Spark 程序从配置了 Hive Metastore 的 EC2 集群上的 Amazon EMR 进行就地迁移,请执行以下步骤:
-
启动 Spark 应用程序并将 Spark 会话配置为使用 Iceberg Hive 目录实现。例如,如果你使用的是
pysparkCLI:pyspark --conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions --conf spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog --conf spark.sql.catalog.spark_catalog.type=hive -
在 Hive 元数据仓中创建
products表。这是源表,它已经存在于典型的迁移中。-
在 Hive Metastore 中创建
products外部 Hive 表以指向 Amazon S3 中的现有数据:spark.sql(f""" CREATE EXTERNAL TABLE products ( product_id INT, product_name STRING ) PARTITIONED BY (category STRING) STORED AS PARQUET LOCATION 's3://amzn-s3-demo-bucket/products/'; """ ) -
使用
MSCK REPAIR TABLE以下命令添加现有分区:spark.sql(f""" MSCK REPAIR TABLE products """ ) -
通过运行
SELECT查询来确认表中是否包含数据:spark.sql(f""" SELECT * FROM products """ ).show(truncate=False)示例输出:

-
-
使用 Iceberg
migrate程序:df_res=spark.sql(f""" CALL system.migrate( table => 'default.products' ) """ ) df_res.show()输出 dataFrame 包含
migrated_files_count(添加到 Iceberg 表中的文件数量):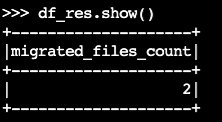
-
确认备份表已创建:
spark.sql("show tables").show()示例输出:
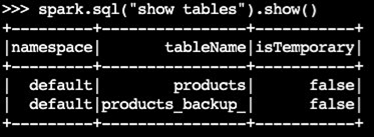
-
通过查询 Iceberg 表来验证操作:
spark.sql(f""" SELECT * FROM products """ ).show(truncate=False)
注意
-
运行该过程后,如果当前所有查询或写入源表的进程未正确配置 Iceberg 支持,则这些进程都将受到影响。因此,我们建议您按照以下步骤操作:
-
迁移前使用源表停止所有进程。
-
执行迁移。
-
使用正确的 Iceberg 设置重新激活进程。
-
-
如果在迁移过程中修改了数据文件(添加了新文件或删除了文件),则生成的表将不同步。有关同步选项,请参阅本节后面的就地迁移后使 Iceberg 表保持同步。
在中复制表迁移过程 AWS Glue Data Catalog
您可以按照以下步骤在中复制迁移过程的结果 AWS Glue Data Catalog (备份原始表并将其替换为 Iceberg 表):
-
使用快照过程创建新的 Iceberg 表,该表指向原始表的数据文件。
-
备份数据目录中的原始表元数据:
-
使用 GetTableAPI 检索源表定义。
-
使用 GetPartitionsAPI 检索源表分区定义。
-
使用 CreateTableAPI 在数据目录中创建备份表。
-
使用CreatePartition或 BatchCreatePartitionAPI 将分区注册到数据目录中的备份表。
-
-
将
gc.enabledIceberg 表属性更改为false,以启用全表操作。 -
删除原始表。
-
在表根位置的元数据文件夹中找到 Iceberg 表元数据 JSON 文件。
-
使用 regi ster_table 过程在数据目录中注册新表
,并使用该过程创建的原始表名和 metadata.json文件的位置:snapshotspark.sql(f""" CALL system.register_table( table => 'mydb.products', metadata_file => '{iceberg_metadata_file}' ) """ ).show(truncate=False)
就地迁移后保持 Iceberg 表同步
该add_files过程提供了一种灵活的方法来将现有数据合并到 Iceberg 表中。具体而言,它通过在 Iceberg 的元数据层中引用现有数据文件(例如 Parquet 文件)的绝对路径来注册它们。默认情况下,该过程会将所有表分区中的文件添加到 Iceberg 表,但您可以有选择地添加来自特定分区的文件。这种选择性方法在以下几种情况下特别有用:
-
在初始迁移后向源表中添加新分区时。
-
在初始迁移后向现有分区中添加或删除数据文件时。但是,重新添加修改后的分区需要先删除分区。本节稍后将提供有关此内容的更多信息。
以下是在执行就地迁移(snapshot或migrate)后使用该add_file过程以使新的 Iceberg 表与源数据文件保持同步的一些注意事项:
-
将新数据添加到源表中的新分区时,请使用带有
partition_filter选项的add_files过程有选择地将这些新增数据合并到 Iceberg 表中:spark.sql(f""" CALL system.add_files( source_table => 'mydb.products', table => 'mydb.products_iceberg', partition_filter => map('category', 'electronics') ).show(truncate=False)或者:
spark.sql(f""" CALL system.add_files( source_table => '`parquet`.`s3://amzn-s3-demo-bucket/products/`', table => 'mydb.products_iceberg', partition_filter => map('category', 'electronics') ).show(truncate=False) -
当您指定
partition_filter选项时,该add_files过程会扫描整个源表或特定分区中的文件,并尝试将其找到的所有文件添加到 Iceberg 表中。默认情况下,check_duplicate_files过程属性设置为true,如果文件已存在于 Iceberg 表中,则程序将无法运行。这很重要,因为没有内置选项可以跳过先前添加的文件,禁用check_duplicate_files会导致文件被添加两次,从而创建重复的文件。将新文件添加到源表时,请按照以下步骤操作:-
对于新分区,
add_files与一起使用partition_filter,仅从新分区导入文件。 -
对于现有分区,请先从 Iceberg 表中删除该分区,然后对该分区重新运行
add_files,指定。partition_filter例如:# We initially perform in-place migration with snapshot spark.sql(f""" CALL system.snapshot( source_table => 'mydb.products', table => 'mydb.products_iceberg', location => 's3://amzn-s3-demo-bucket/products_iceberg/' ) """ ).show(truncate=False) # Then on the source table, some new files were generated under the category='electronics' partition. Example: spark.sql(""" INSERT INTO mydb.products VALUES (1003, 'Tablet', 'electronics') """) # We delete the modified partition from the Iceberg table. Note this is a metadata operation only spark.sql(""" DELETE FROM mydb.products_iceberg WHERE category = 'electronics' """) # We add_files from the modified partition spark.sql(""" CALL system.add_files( source_table => 'mydb.products', table => 'mydb.products_iceberg', partition_filter => map('category', 'electronics') ) """).show(truncate=False)
-
注意
每个add_files操作都会生成一个包含附加数据的新的 Iceberg 表快照。
选择正确的就地迁移策略
要选择最佳的就地迁移策略,请考虑下表中的问题。
问题 |
建议 |
说明 |
|---|---|---|
您是否想在不重写数据的情况下快速迁移,同时保持 Hive 和 Iceberg 表可供测试或逐步过渡使用? |
|
使用该 |
你是否在使用 Hive Metastore,是否想在不重写数据的情况下立即用 Iceberg 表替换 Hive 表? |
|
使用该 注意:此选项与 Hive Metastore 兼容,但不兼容。 AWS Glue Data Catalog 使用此 |
您是否正在使用 AWS Glue Data Catalog Hive 表,是否要立即用 Iceberg 表替换 Hive 表,而不必重写数据? |
调整 |
复制
注意:此选项需要手动处理元数据备份 AWS Glue 的 API 调用。 使用此 |
