本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
现代数据湖
现代数据湖中的高级用例
数据存储的演变已从数据库发展到数据仓库和数据湖,每种技术都能满足独特的业务和数据需求。传统数据库擅长处理结构化数据和事务性工作负载,但随着数据量的增加,它们面临着性能挑战。数据仓库的出现是为了解决性能和可扩展性问题,但与数据库一样,它们依赖垂直集成系统中的专有格式。
就成本、可扩展性和灵活性而言,数据湖是存储数据的最佳选择之一。您可以使用数据湖以低成本保留大量结构化和非结构化数据,并将这些数据用于不同类型的分析工作负载,从商业智能报告到大数据处理、实时分析、机器学习和生成式人工智能 (AI),以帮助指导更好的决策。
尽管有这些好处,但最初设计的数据湖并不是具有类似数据库的功能。数据湖不支持原子性、一致性、隔离性和耐久性 (ACID) 处理语义,您可能需要这些语义才能使用多种不同的技术在成百上千的用户中有效地优化和管理数据。数据湖不为以下功能提供原生支持:
-
随着业务中数据的变化,执行高效的记录级别更新和删除
-
在表增长到数百万个文件和数十万个分区时管理查询性能
-
确保多个并发写入器和读取器之间的数据一致性
-
防止写入操作在操作中途失败时数据损坏
-
在没有(部分)重写数据集的情况下,随着时间的推移不断演变表架构
这些挑战在处理变更数据捕获 (CDC) 等用例中变得特别普遍,或者与隐私、数据删除和流数据摄取相关的用例,这可能会导致表格不理想。
使用传统 Hive 格式表的数据湖仅支持对整个文件的写入操作。这使得更新和删除难以实现、耗时且成本高昂。此外,还需要在符合 ACID 的系统中提供并发控制和保证,以确保数据的完整性和一致性。
这些挑战给用户带来了两难境地:在完全集成但专有的平台之间做出选择,或者选择供应商中立但资源密集型的自建数据湖,需要持续的维护和迁移才能实现其潜在价值。
为了帮助克服这些挑战,Iceberg 提供了其他类似数据库的功能,简化了数据湖的优化和管理开销,同时仍支持在 Amazon S3 等经济实惠的系统上进行存储。
Apache Iceberg 简介
Apache Iceberg 是一种开源表格式,它在数据湖表中提供以前只能在数据库或数据仓库中使用的功能。它专为扩展和性能而设计,非常适合管理超过数百 GB 的表。Iceberg 桌子的一些主要特点是:
-
删除、更新和合并。Iceberg 支持用于数据仓库的标准 SQL 命令,用于数据湖表。
-
快速扫描计划和高级筛选。Iceberg 存储诸如分区和列级统计数据之类的元数据,引擎可以使用这些元数据来加快规划和运行查询的速度。
-
完整的架构演变。Iceberg 支持添加、删除、更新或重命名列,而不会产生副作用。
-
分区的演变。随着数据量或查询模式的变化,您可以更新表的分区布局。Iceberg 支持更改对表进行分区的列,也支持在复合分区中添加列或从复合分区中删除列。
-
隐藏分区。此功能可防止自动读取不必要的分区。这样用户就不必了解表的分区细节或在查询中添加额外的过滤器。
-
版本回滚。用户可以通过恢复到交易前状态来快速纠正问题。
-
时空旅行。用户可以查询表的特定先前版本。
-
可序列化的隔离。表更改是原子性的,因此读者永远不会看到部分或未提交的更改。
-
并发作家。Iceberg 使用乐观并发来允许多笔交易成功。如果发生冲突,其中一位作者必须重试交易。
-
打开文件格式。Iceberg 支持多种开源文件格式,包括 Apache Par quet、Apache
Avro 和 Apache ORC。
总而言之,使用 Iceberg 格式的数据湖受益于事务一致性、速度、规模和架构演变。有关这些功能和其他 Iceberg 功能的更多信息,请参阅 Apache Iceb
AWS 支持 Apache Iceberg
Apache Iceberg 由亚马逊 EMR AWS 服务 、亚马逊 Athena、亚马逊
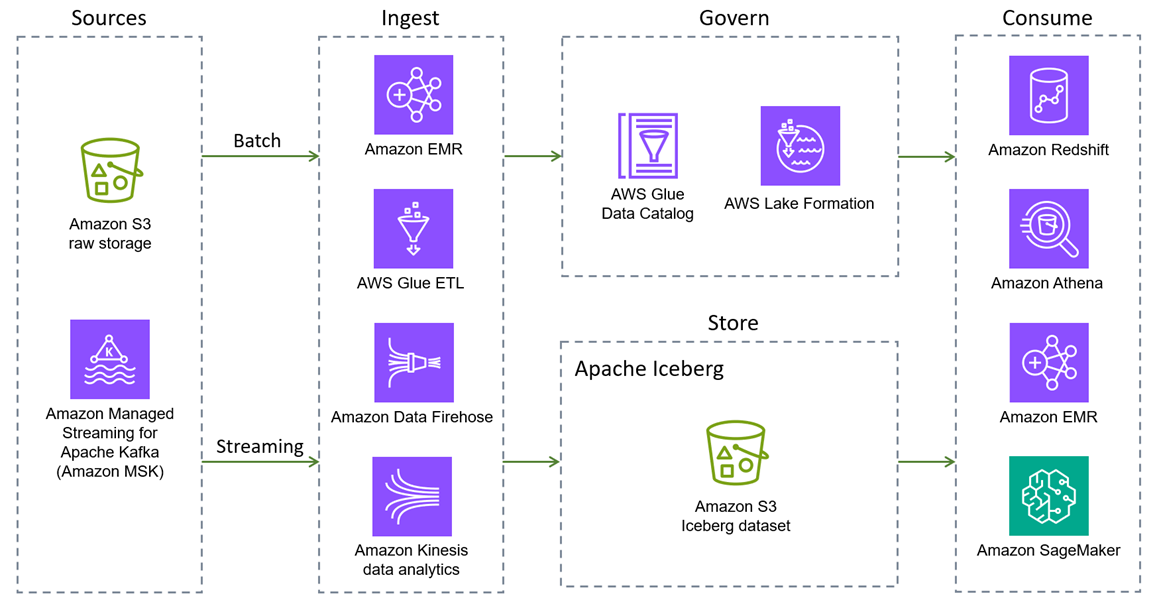
以下内容 AWS 服务 提供原生 Iceberg 集成。还有一些 AWS 服务 可以与Iceberg进行间接交互或通过打包Iceberg库进行交互。
-
Amazon S3 凭借其持久性、可用性、可扩展性、安全性、合规性和审计能力,是构建数据湖的最佳场所。Iceberg 的设计和构建旨在与亚马逊 S3 无缝交互,并为 Iceberg
文档中列出的许多 Amazon S3 功能提供支持。此外,Amazon S3 Table s 还提供了第一个具有内置 Iceberg 支持的云对象存储,并简化了大规模表格数据的存储。借助对 Iceberg 的 S3 Tables 支持,您可以使用流行 AWS 的第三方查询引擎轻松查询表格数据。 -
下一代基于开放的 SageMaker湖库架构,该
架构统一了 Amazon S3 数据湖、Amazon Redshift 数据仓库以及第三方和联合数据源之间的数据访问。这些功能可帮助您在单个数据副本上构建强大的分析和 AI/ML 应用程序。湖屋与 Iceberg 完全兼容,因此您可以使用 Iceberg REST API 灵活地访问和查询现有数据。 -
Amazon EMR 是一款大数据解决方案,使用 Apache Spark、Flink、Trino 和 Hive 等开源框架,用于千兆字节规模的数据处理、交互式分析和机器学习。亚马逊 EMR 可以在自定义的亚马逊弹性计算云 (亚马逊 EC2) 集群、亚马逊弹性 Kubernetes Service (Amazon EKS) AWS Outposts或亚马逊 EMR Serverless 上运行。
-
Amazon Athena 是一项建立在开源框架之上的无服务器交互式分析服务。它支持开放表和文件格式,并提供了一种简化、灵活的方式来分析存放的 PB 级数据。Athena 为 Iceberg 的读取、时空旅行、写入和 DDL 查询提供原生支持,并将其用 AWS Glue Data Catalog 于 Iceberg 元数据库。
-
Amazon Redshift 是一个 PB 级的云数据仓库,支持基于集群和无服务器的部署选项。Amazon Redshift Spectrum 可以查询注册并存储 AWS Glue Data Catalog 在亚马逊 S3 上的外部表。Redshift Spectrum 还支持 Iceberg 存储格式。
-
AWS Glue是一项无服务器数据集成服务,可以更轻松地发现、准备、移动和集成来自多个来源的数据,用于分析、机器学习 (ML) 和应用程序开发。它与 Iceberg 完全集成。具体而言,您可以使用 AWS Glue 作业对 Iceberg 表执行读写操作,通过 AWS Glue Data Catalog(与 Hive 元存储兼容)管理表,使用 AWS Glue 爬虫自动发现和注册表,以及通过数据质量功能评估 Iceberg 表中的数据质量。 AWS Glue AWS Glue Data Catalog 还支持收集列统计信息、计算和更新 Iceberg 表中每列的不同值的数量 (NDVs),以及自动表优化(压缩、快照保留、孤立文件删除)。 AWS Glue 还支持将第三方应用程序列表中的零 ETL 集成到 Iceb AWS 服务 erg 表中。
-
Amazon Data Firehose 是一项完全托管的服务,用于向亚马逊 S3、亚马逊 Redshift、亚马逊服务、亚马逊无服务器、Splunk、 OpenSearch Apache Iceberg 表以及支持的第三方服务提供商拥有的任何自定义 HTTP 或 HTTP 终端节点(包括 Datadog、Dynatrace、MongoDB、New R LogicMonitor elic、Coralogix 和 Elastic)等目的地提供实时流数据。 OpenSearch 使用 Firehose,您无需编写应用程序或管理资源。您可以配置数据生成工具向 Firehose 发送数据,然后 Firehose 会将数据自动传输到您指定的目标。还可以配置 Firehose 在传输数据之前转换数据。
-
适用于 Apache Flink 的亚马逊托管服务 Flink 是一项完全托管的亚马逊服务,允许您使用 Apache Flink 应用程序来处理流数据。它支持读取和写入 Iceberg 表,并支持实时数据处理和分析。
-
Amazon SageMaker AI 支持使用 Iceberg 格式在亚马逊 SageMaker AI 功能商店中存储功能集。
-
AWS Lake Formation提供粗略而精细的访问控制权限来访问数据,包括 Athena 或 Amazon Redshift 使用的 Iceberg 表。要详细了解对 Iceberg 表的权限支持,请参阅 Lake Formation 文档。
AWS 提供多种支持 Iceberg 的服务,但涵盖所有这些服务超出了本指南的范围。以下各节介绍了 Amazon EMR 和 Athena SQL 上的 Spark(批量和 AWS Glue结构化直播)。以下部分简要介绍了 Athena SQL 中对 Iceberg 的支持。
