本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
# 优化读取性能
本节讨论了可以调整的表属性,这些属性可以独立于引擎来优化读取性能。
## 分区
与 Hive 表一样,Iceberg 使用分区作为索引的主要层,以避免读取不必要的元数据文件和数据文件。列统计数据也被视为索引的辅助层,以进一步改进查询计划,从而缩短总体执行时间。
### 对您的数据进行分区
要减少查询 Iceberg 表时扫描的数据量,请选择与预期读取模式一致的平衡分区策略:
+ 确定查询中经常使用的列。这些是理想的分区候选对象。例如,如果您通常查询特定日期的数据,则分区列的自然例子就是日期列。
+ 选择低基数分区列以避免创建过多的分区。分区过多会增加表中的文件数量,从而对查询性能产生负面影响。根据经验,“分区过多” 可以定义为大多数分区中的数据大小小于设定值的 2-5 倍的情况。`target-file-size-bytes`
**注意**
如果您通常通过对高基数列(例如,可以包含数千个值的列)使用过滤器进行查询,请使用带有存储桶转换的 Iceberg 隐藏分区功能,如下一节所述。`id`
### 使用隐藏分区
如果您的查询通常根据表列的派生项进行筛选,请使用隐藏分区,而不是显式创建新列来用作分区。有关此功能的更多信息,请参阅 [Iceberg 文档](https://iceberg.apache.org/docs/latest/partitioning/#icebergs-hidden-partitioning)。
例如,在具有时间戳列的数据集中(例如,`2023-01-01 09:00:00`),使用分区转换从时间戳中提取日期部分并即时创建这些分区,而不是使用解析后的日期创建新列(例如,`2023-01-01`)。
隐藏分区最常见的用例是:
+ 当数据包含@@ **时间戳列时,按日期或时间进行分区**。Iceberg 提供多种变换来提取时间戳的日期或时间部分。
+ 在@@ **列的哈希函数上进行分**区,此时分区列的基数很高,会导致分区过多。Iceberg 的存储桶转换通过在分区列上使用哈希函数,将多个分区值组合成更少的隐藏(存储桶)分区。
有关所有可用[分区转换](https://iceberg.apache.org/spec/#partition-transforms)的概述,请参阅 Iceberg 文档中的分区转换。
通过使用常规 SQL 函数(如`year()`和),用于隐藏分区的列可以成为查询谓词的一部分。`month()`谓词也可以与诸如`BETWEEN`和`AND`之类的运算符组合使用。
**注意**
Iceberg 无法对产生不同数据类型的函数执行分区修剪;例如,。`substring(event_time, 1, 10) = '2022-01-01'`
### 使用分区演变
当现有的[分区策略不是最佳时,请使用 Iceberg 的分区演变](https://iceberg.apache.org/docs/latest/evolution/#partition-evolution)。例如,如果您选择的每小时分区结果太小(每个分区只有几兆字节),请考虑切换到每日或每月分区。
当最初不清楚表的最佳分区策略,并且您想在获得更多见解时完善分区策略时,可以使用这种方法。分区演变的另一个有效用途是,当数据量发生变化并且当前的分区策略随着时间的推移而变得不那么有效时。
有关如何演变分区的说明,请参阅 Iceberg 文档中的 [ALTER TABLE SQL 扩展](https://iceberg.apache.org/docs/latest/spark-ddl/#alter-table-sql-extensions)。
## 调整文件大小
优化查询性能包括最大限度地减少表中的小文件数量。为了获得良好的查询性能,我们通常建议保留大于 100 MB 的 Parquet 和 ORC 文件。
文件大小也会影响 Iceberg 表的查询计划。随着表中文件数量的增加,元数据文件的大小也随之增加。较大的元数据文件可能会导致查询计划变慢。因此,当表大小增加时*,*请增加文件大小****以缓解元数据的指数级扩展。
使用以下最佳实践在 Iceberg 表中创建大小合适的文件。
### 设置目标文件和行组的大小
Iceberg 提供了以下用于调整数据文件布局的关键配置参数。我们建议您使用这些参数来设置目标文件大小和行组或行标大小。
| **参数** | **默认值** | **评论** |
| --- |--- |--- |
| `write.target-file-size-bytes` | 512MB | 此参数指定 Iceberg 将创建的最大文件大小。但是,写入某些文件的大小可能小于此限制。 |
| `write.parquet.row-group-size-bytes` | 128MB | Parquet 和 ORC 都将数据分块存储,因此引擎可以避免在某些操作中读取整个文件。 |
| `write.orc.stripe-size-bytes` | 64 MB |
| `write.distribution-mode` | 无,适用于 Iceberg 1.1 及更低版本
哈希,从 Iceberg 1.2 版本开始 | Iceberg 要求 Spark 在写入存储之前在其任务之间对数据进行排序。 |
+ 根据您的预期表格大小,请遵循以下一般准则:
+ **小表**(最多几千兆字节)-将目标文件大小减至 128 MB。还要减小行组或条带大小(例如,减至 8 或 16 MB)。
+ **中型到大型表**(从几千兆字节到几百千兆字节不等)-默认值是这些表的良好起点。如果您的查询选择性很强,请调整行组或条带大小(例如,调整到 16 MB)。
+ **非常大的表**(数百 GB 或 TB)-将目标文件大小增加到 1024 MB 或更多,如果您的查询通常会提取大量数据,请考虑增加行组或条带大小。
+ 为确保写入 Iceberg 表的 Spark 应用程序创建大小合适的文件,请将该`write.distribution-mode`属性设置为`hash`或`range`。有关这些模式之间差异的详细说明,请参阅 Iceberg 文档中的[编写分发模式](https://iceberg.apache.org/docs/latest/spark-writes/#writing-distribution-modes)。
这些是一般指导方针。我们建议您运行测试以确定最适合您的特定表和工作负载的值。
### 定期进行压实
上表中的配置设置了写入任务可以创建的最大文件大小,但不能保证文件会有该大小。为确保文件大小合适,请定期运行压缩,将小文件合并成较大的文件。有关运行压实的详细指导,请参阅本指南后面的[冰山压实](best-practices-compaction.md)。
## 优化列统计信息
Iceberg 使用列统计信息来执行文件修剪,从而通过减少查询扫描的数据量来提高查询性能。要从列统计数据中受益,请确保 Iceberg 收集查询过滤器中经常使用的所有列的统计信息。
默认情况下,根据表属性的`write.metadata.metrics.max-inferred-column-defaults`定义,Iceberg 仅收集[每个表中前 100 列](https://github.com/apache/iceberg/blob/ae15c7e36973501b40443e75816d3eac39eddc90/core/src/main/java/org/apache/iceberg/TableProperties.java#L276)的统计数据。如果您的表包含超过 100 列,并且您的查询经常引用前 100 列之外的列(例如,您可能有筛选第 132 列的查询),请确保 Iceberg 收集这些列的统计数据。有两种方法可以实现此目的:
+ 创建 Iceberg 表时,对列进行重新排序,使查询所需的列位于设置的列范围内`write.metadata.metrics.max-inferred-column-defaults`(默认为 100)。
注意:如果您不需要 100 列的统计数据,则可以将`write.metadata.metrics.max-inferred-column-defaults`配置调整为所需的值(例如 20),然后对这些列进行重新排序,使需要读取和写入查询的列位于数据集左侧的前 20 列之内。
+ 如果您在查询筛选器中仅使用几列,则可以禁用指标收集的整体属性,并有选择地选择要为其收集统计数据的各个列,如以下示例所示:
```
.tableProperty("write.metadata.metrics.default", "none")
.tableProperty("write.metadata.metrics.column.my_col_a", "full")
.tableProperty("write.metadata.metrics.column.my_col_b", "full")
```
注意:当对这些列上的数据进行排序时,列统计信息最为有效。有关更多信息,请参阅本指南后面[的 “设置排序顺序](#read-sort-order)” 部分。
## 选择正确的更新策略
如果您的用例可以接受较慢的写入操作,则使用 copy-on-write策略来优化读取性能。这是 Iceberg 使用的默认策略。
Copy-on-write 从而提高读取性能,因为文件是以读取优化的方式直接写入存储的。但是,与之相比 merge-on-read,每次写入操作花费的时间更长,消耗的计算资源也更多。这在读取和写入延迟之间进行了典型的权衡。通常, copy-on-write非常适合大多数更新并置在同一个表分区中的用例(例如,用于每日批量加载)。
Copy-on-write 配置(`write.update.mode``write.delete.mode`、和`write.merge.mode`)可以在表级别进行设置,也可以在应用程序端独立设置。
## 使用 ZSTD 压缩
您可以使用 table 属性修改 Iceberg 使用的压缩编解码器。`write..compression-codec`我们建议您使用 ZSTD 压缩编解码器来提高表的整体性能。
默认情况下,Iceberg 1.3 及更早版本使用 GZIP 压缩,与 ZSTD 相比,GZIP 压缩的 read/write 性能较慢。
注意:某些引擎可能使用不同的默认值。使用 At [hena 或 Amazon EMR 7.x 版本创建的 Iceberg 表就是这种](https://docs.aws.amazon.com/athena/latest/ug/compression-support-iceberg.html)情况。
## 设置排序顺序
为了提高 Iceberg 表的读取性能,我们建议您根据查询过滤器中经常使用的一列或多列对表进行排序。排序与 Iceberg 的列统计信息相结合,可以显著提高文件修剪的效率,从而加快读取操作的速度。排序还可以减少使用查询筛选器中排序列的 Amazon S3 查询请求的数量。
通过使用 Spark 运行数据定义语言 (DDL) 语句,可以在表级别设置分层排序顺序。有关可用选项,请参阅 [Iceberg 文档](https://iceberg.apache.org/docs/latest/spark-ddl/#alter-table--write-ordered-by)。设置排序顺序后,写入者会将此排序应用于 Iceberg 表中的后续数据写入操作。
例如,在大多数查询都按日期 (`yyyy-mm-dd`) 分区的表中`uuid`,您可以使用 DDL 选项`Write Distributed By Partition Locally Ordered`来确保 Spark 写入范围不重叠的文件。
下图说明了在对表进行排序时如何提高列统计数据的效率。在示例中,排序后的表只需要打开一个文件,并且可以最大限度地受益于 Iceberg 的分区和文件。在未排序的表中,任何数据文件中都`uuid`可能存在任何数据,因此查询必须打开所有数据文件。
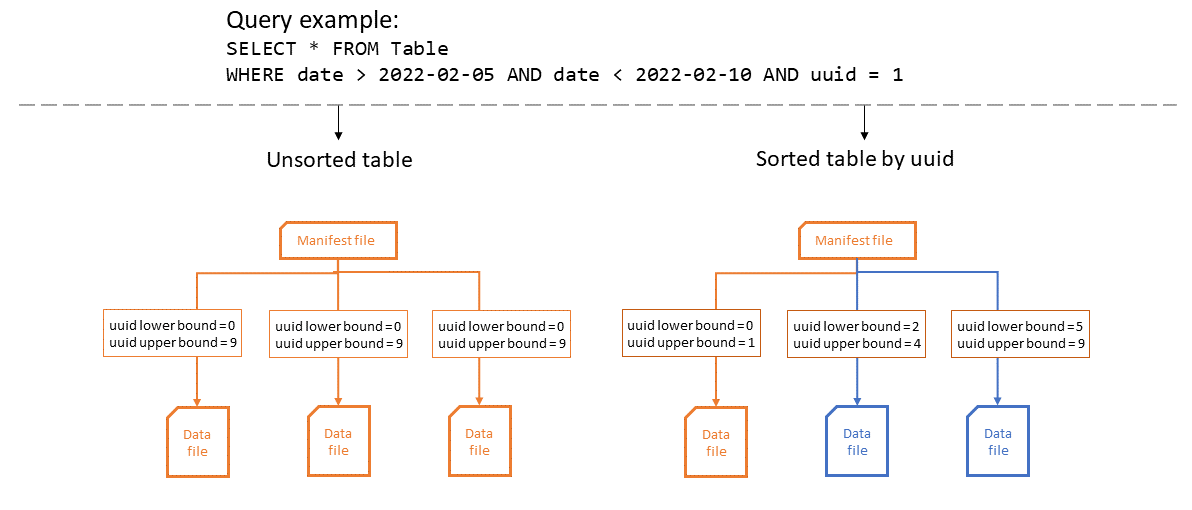
更改排序顺序不会影响现有的数据文件。你可以使用 Iceberg compaction 对它们应用排序顺序。
如下图所示,使用 Iceberg 排序的表格可能会降低工作负载成本。
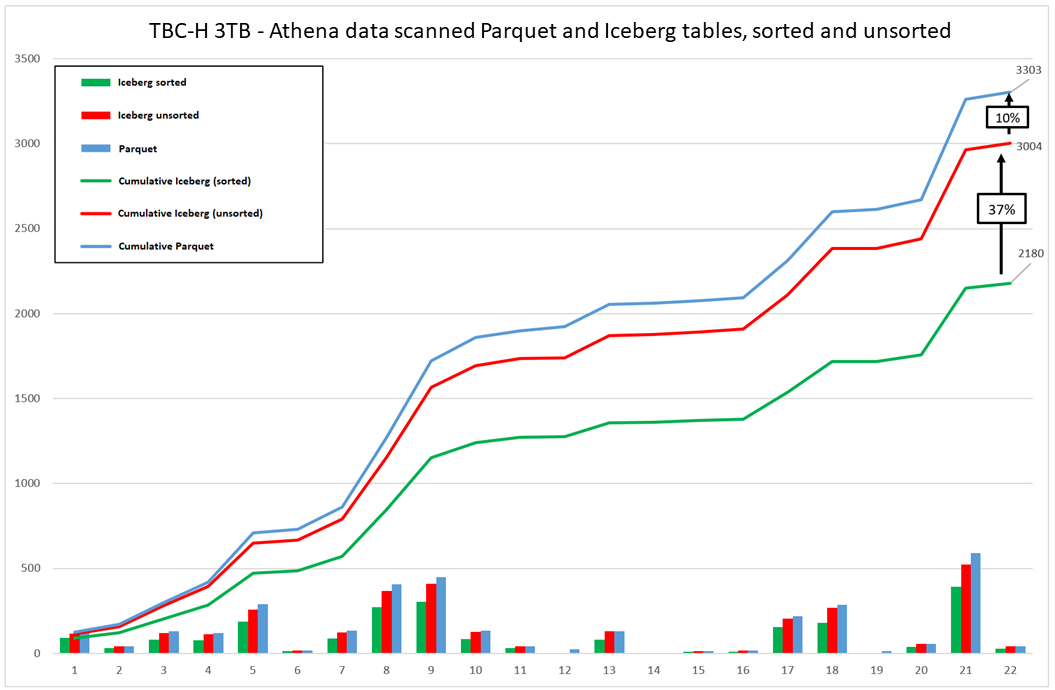
这些图表汇总了运行Hive(Parquet)表的TPC-H基准测试与Iceberg排序表的结果。但是,对于其他数据集或工作负载,结果可能会有所不同。
