本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
并行化工作流程
此工作流程包括将任务分解为独立的子任务,这些子任务可以由多个 LLM 呼叫或代理同时处理。然后以编程方式汇总输出并合成结果。
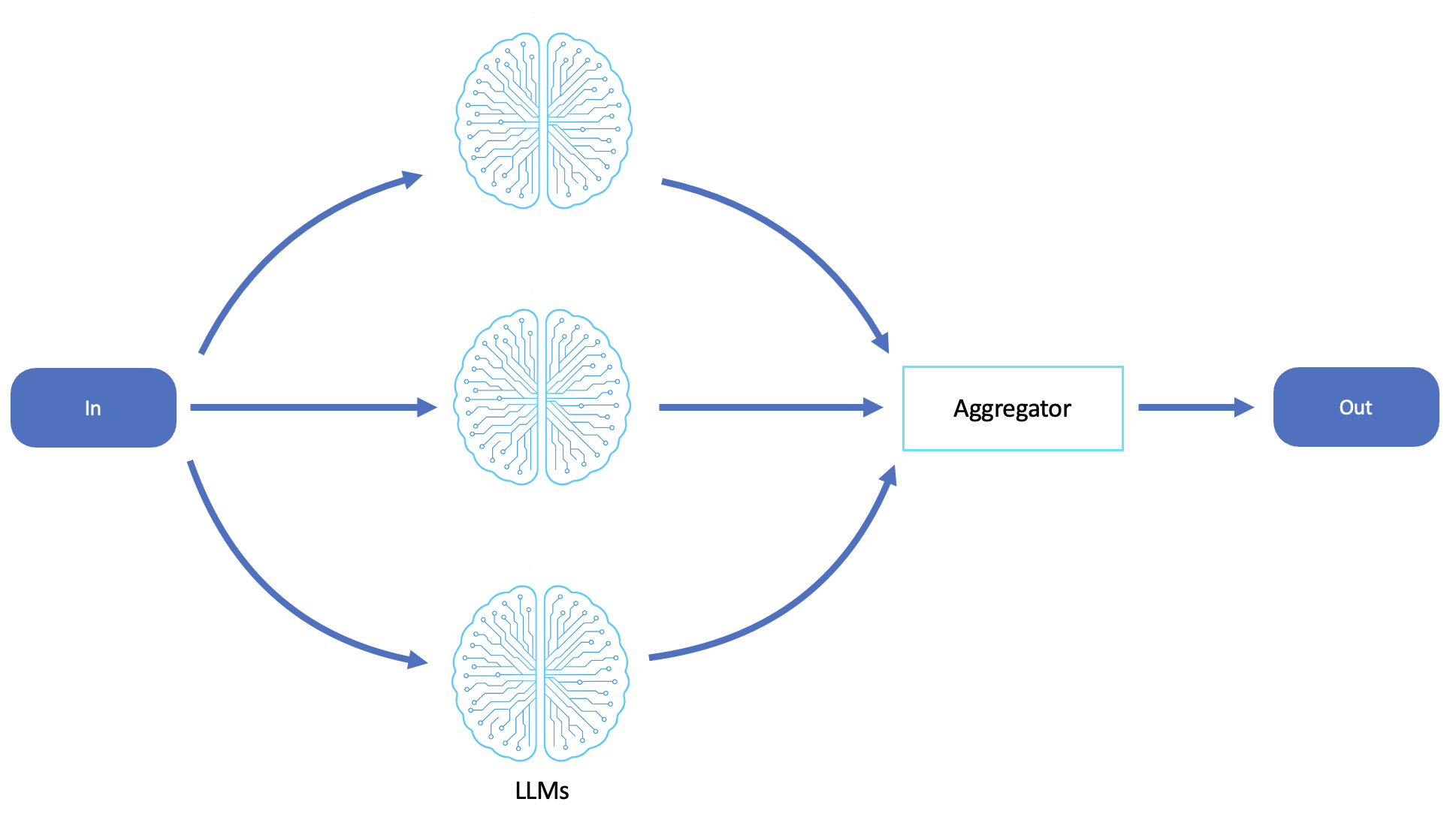
Parallelization 工作流程用于将任务划分为可以同时处理的独立、非顺序的子任务,从而显著提高效率、吞吐量和可扩展性。它在数据密集、批处理导向或多视角问题空间中特别强大,在这些空间中,代理必须通过多个输入分析或生成内容。
在以下情况下,并行化特别有效:
-
子任务不依赖彼此的中间结果,允许它们在没有协调的情况下并行运行。
-
一项任务涉及对许多项目重复相同的推理过程(例如,总结多个文档或评估选项列表)。
-
并行探索多种假设或观点,以促进多样性、创造力或稳健性。
-
您需要通过并发 LLM 执行来减少大容量或高频请求的延迟。
-
此工作流程通常用于文档处理代理、调查或比较引擎、批量汇总器、多代理头脑风暴以及可扩展的分类或标签任务,尤其是在快速、并行推理具有性能优势的情况下。
功能
-
并行执行 LLM 任务(通过使用 AWS Lambda AWS Fargate、或 AWS Step Functions 映射状态)
-
需要在综合阶段对结果进行校准、验证或重复数据删除
-
非常适合无状态代理循环
常见使用案例
-
并行分析多个文档或视角
-
生成不同的草稿、摘要或计划
-
加快批处理作业的吞吐量
